基于迁移学习仿真SAR图像的目标识别研究
2021-10-28崔亚楠吴建平朱辰龙闫相如
崔亚楠,吴建平,2,3,朱辰龙,闫相如
(1.云南大学 信息学院,云南 昆明 650504; 2.云南省电子计算中心,云南 昆明 650223; 3.云南省高校数字媒体技术重点实验室,云南 昆明 650223)
0 引 言
合成孔径雷达(synthetic aperture radar,SAR)是一种多平台协同工作的主动微波成像雷达系统。相较于可见光、红外等光学成像方式,SAR具有全天候,全天时且不受天气、光照等外界条件限制的独特优势。近年来,已经被广泛运用到军事、工业、农业等诸多领域。随着SAR系统与成像技术的发展与完善,SAR图像的应用得到广泛关注,从而大量SAR图像目标的自动识别(automatic target recognition,ATR)成为学者们研究的热点问题。
国内外对SAR图像目标的自动识别进行了研究并提出了一些方法。早期对SAR图像目标识别的研究主要基于特征提取,如文献[1]运用非负矩阵分解特征进行SAR图像目标识别;文献[2]通过提取图像局部判别嵌入特征进行目标识别;文献[3]基于电磁散射特征提取方法识别SAR图像目标。以上特征提取方法均会忽略掉图像的细节信息,从而无法充分提取目标的特征,导致目标识别效果不佳。深度学习[4]的出现为SAR图像目标识别提供更多的可能。AlexNet[5]、VGG[6]、GoogleNet[7]、ResNet[8]等深度学习网络模型在ImageNet大赛中表现优越,这些神经网络模型也逐渐引入到SAR图像目标识别研究中。
卷积神经网络(CNN)模型训练时往往需要大量的数据,对于数据较少的SAR图像数据集在训练过程中大概率会出现过拟合,从而导致模型鲁棒性差,识别效果不佳。在以往的研究中,文献[9]通过增强数据集获取更多SAR图像,再对CNN模型进行训练,最终达到了96.42%的识别率。文献[10]基于模型迁移,引入超限学习机(ELM)对目标进行学习,最终取得了97.23%的识别率。文献[11]提出一种CMNet网络模型,通过增加卷积层个数减少图像相干斑噪声的影响,并利用Softmax损失与中心损失共同监督网络训练提高模型的泛化能力,最终获得了99.30%的识别率。
为了更有效地解决SAR图像样本不足的问题,一些学者提出仿真SAR图像的概念,如文献[12]基于一种射线追踪技术的SAR信号级仿真方法构建地面车辆目标SAR仿真场景物理模型,得到相应的SAR仿真图像,扩充了SAR图像数据。一定程度上能够解决SAR图像数据缺乏的问题。在此基础上,文中提出基于卷积网络神经仿真SAR图像迁移学习的方法,利用SAR仿真数据集[13]预训练卷积神经网络至网络收敛,得到相应的网络参数。再将预训练得到的网络参数迁移到目标网络对SAR图像数据进行训练。实验结果表明,该算法优于传统机器学习方法,获得了更好的识别效果,进一步提高了SAR识别的实用价值。
1 相关理论和技术描述
1.1 卷积神经网络
卷积神经网络主要由卷积层、池化层、全连接层构成。卷积层和池化层在卷积神经网络中交替叠加出现,组成了提取特征的部分。卷积神经网络相比其他神经网络,其独特优势在于具有权值共享和局部感知的特性,很大程度上减少了网络参数,降低了计算量。
(1)卷积层。
卷积层中包含多种尺寸的卷积核,作用是对图像的深层特征进行提取。其次利用激活函数对其进行非线性激活得到新的特征。具体计算过程如下:
(1)
其中,Yi,j是第i行,第j列的特征输出值;N为卷积核的大小;wl,k为第l行,第k列的权重;Wb为偏置项;f为激活函数。ReLU函数相较于其他激活函数有更快的收敛速度且能够缓解梯度消失的问题,因此文中选用ReLU函数作为非线性激活函数。其函数表达式为:
ReLU(x)=max(x,0)
(2)
(2)池化层。
池化层分为平均池化(average pooling)和最大池化(max pooling)两种形式,作用在于减少网络参数量,防止过拟合,使网络优化更加容易。
(3)全连接层。
全连接层作为卷积神经网络的“分类器”,其每个节点与上一层所有节点完全连接,将经过卷积层和池化层所得到的全部特征汇总,最终输出的节点数即为目标识别的类别数。
1.2 迁移学习
迁移学习是在两个领域具有一定相关性的条件下,用其中一个领域学习到的知识解决另一个领域存在的问题的方法[14]。迁移学习分为基于实例迁移学习、基于特征迁移学习、基于模型迁移学习和基于关系迁移学习四大类别。传统机器学习在训练一个好的网络模型时需要训练大量数据进行学习,对于一些数据较少的样本往往训练效果不佳。迁移学习能有效解决小样本数据的学习问题,提升卷积神经网络对小样本数据目标分类识别的准确率。
在迁移学习中,被学习的领域称为源域(source domain),待解决问题的领域称为目标域(target domain),公式如下:
D(s)={xs,P(xs)}
(3)
D(t)={xt,P(xt)}
(4)
其中,D(s)为源域;D(t)为目标域;xs为源域的特征空间;xt为目标域的特征空间;P(xs)是与xs对应的边际概率分布;P(xt)是与xt对应的边际概率分布。
1.3 仿真SAR图像模型介绍
生成仿真SAR目标图像过程:首先,利用Ulaby方法结合粗糙面散射理论建立SAR车辆目标仿真场景模型,再利用蒙特卡罗(Monte Carlo)方法获取雷达与目标以及地面环境的空间几何关系,进一步通过随机散射法等技术获取地面的粗糙特性。随后,利用射线弹跳法、等效边缘流法等建立目标、地面场景的电磁散射模型。最后,基于电磁散射模型与场景模型计算SAR目标的扫频数据,通过时频变换与成像算法得到仿真SAR目标图像。不同方位角的部分仿真SAR图像如图1所示。

图1 部分仿真SAR图像
2 基于迁移学习的SAR目标图像识别方法
2.1 图像预处理
遥感雷达图像具有较大的相干斑点噪声,一定程度上影响了网络性能的提升。文中采用一种增强的Lee滤波算法[15]先对MSTAR数据集中的图像进行滤波去噪,减少噪声在神经网络模型训练中产生的影响,有效提高了网络性能。
2.2 Inception-ResNet-v2
随着卷积神经网络在图像识别领域的深入发展,对网络性能有更高的要求。前期扩充网络的深度与高度的作法,出现了网络过拟合、计算量大等问题。而Inception网络模型有效缓解了该问题。Inception v1网络[7]通过稀疏矩阵类聚成相对密集的子矩阵的方法提高网络计算性能。Inception v2网络[16]在输入时增加了batch_normal,使网络训练收敛得更快。Inception v3网络[16]利用多个小卷积核串联取代较大卷积核的方式,改善了网络的非线性,减小了网络过拟合的概率。Inception v4网络与Inception v3网络相比具有更统一的简化架构。Inception v4网络与Inception-ResNet-v2网络结构相似,不同点在于Inception-ResNet-v2网络结合了残差网络的思想可以将网络深度增加[17]。
Inception-ResNet-v2网络结合了残差网络思想,在增加神经网络深度的同时降低了梯度消失的问题,该网络性能最佳。因此,文中采用Inception-ResNet-v2网络作为训练模型,将原始模型的Dropout rate改为0.5,最后利用Adam算法对模型进行优化,其采用的网络架构如图2所示。
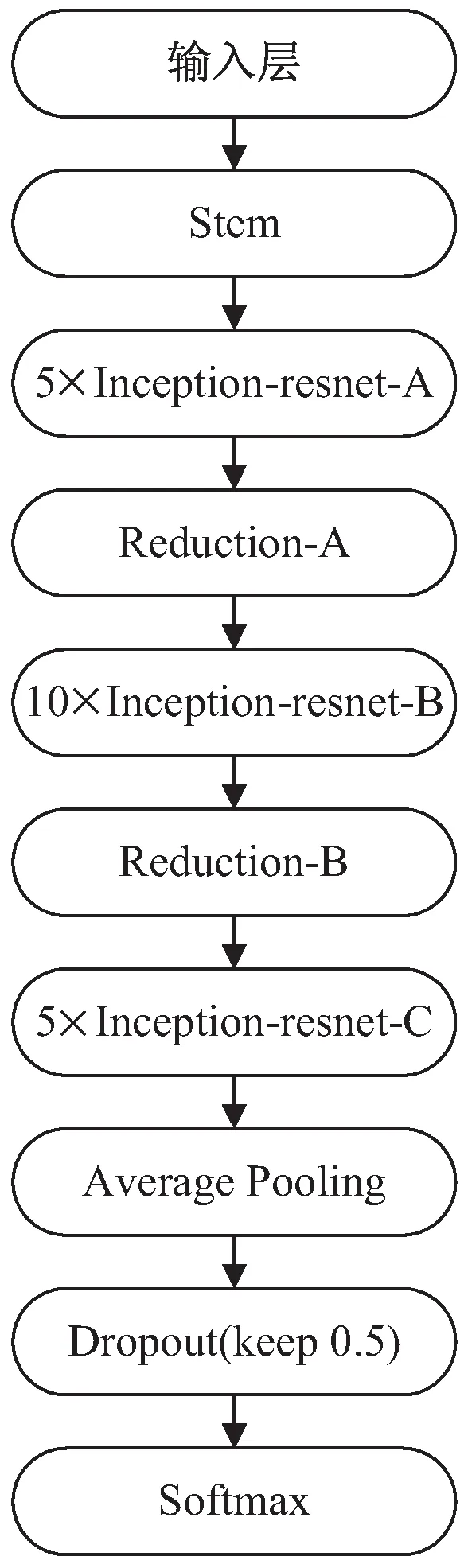
图2 Inception-ResNet-v2网络总体架构
其中,Inception-ResNet-v2网络结构又由Stem模块、Inception-ResNet-A模块、Reduction-A模块、Inception-ResNet-B模块、Reduction-B模块、Inception-ResNet-C模块等组成。
2.2.1 Dropout的设计
对于参数量大,训练样本少的神经网络训练时很容易产生过拟合,Dropout的提出有效解决了这一问题。Dropout在训练网络时会随机丢弃部分神经元,从而达到减少网络参数、提升模型鲁棒性的目的,同时,有效缓解过拟合对网络的影响。文中模型中Dropout rate设置为0.5。
2.2.2 Softmax分类器设计
Softmax函数是基于多项逻辑损失的组合,常用于图像等多分类问题来表示类别之间的概率分布,其基本原理是将输入映射为0到1之间的实数,实现分类向量的归一化。Softmax分类器的目的是实现估计分类概率和真实分布之间交叉熵的最小化。
交叉熵函数表达式为:
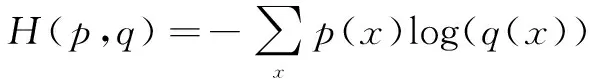
(5)
其中,p表示真实分布,q表示估计分布。
Softmax函数表达式为:
(6)
其中,i表示第i类别,k表示总的类别数,H(zi)表示第i类别的概率。
2.3 迁移学习算法设计与实现
文中基于迁移学习实现Inception-ResNet-v2网络模型的预训练、训练以及优化等,迁移模型如图3所示。算法的具体实现过程如下:
(1)将仿真SAR数据集中的七类图像作为源域识别任务,仿真SAR数据集作为源域训练样本。对Inception-ResNet-v2模型进行预训练,得到预训练模型参数。
(2)构建与源域模型相同的目标域模型。
(3)将MSTAR数据集中的十类图像作为目标域识别任务,MSTAR数据集作为目标域的训练样本。将上述预训练模型中的参数作为目标域模型的初始化参数对目标域模型进行训练。
(4)采用Adam算法优化网络。
(5)最终通过Softmax分类器实现目标的分类。
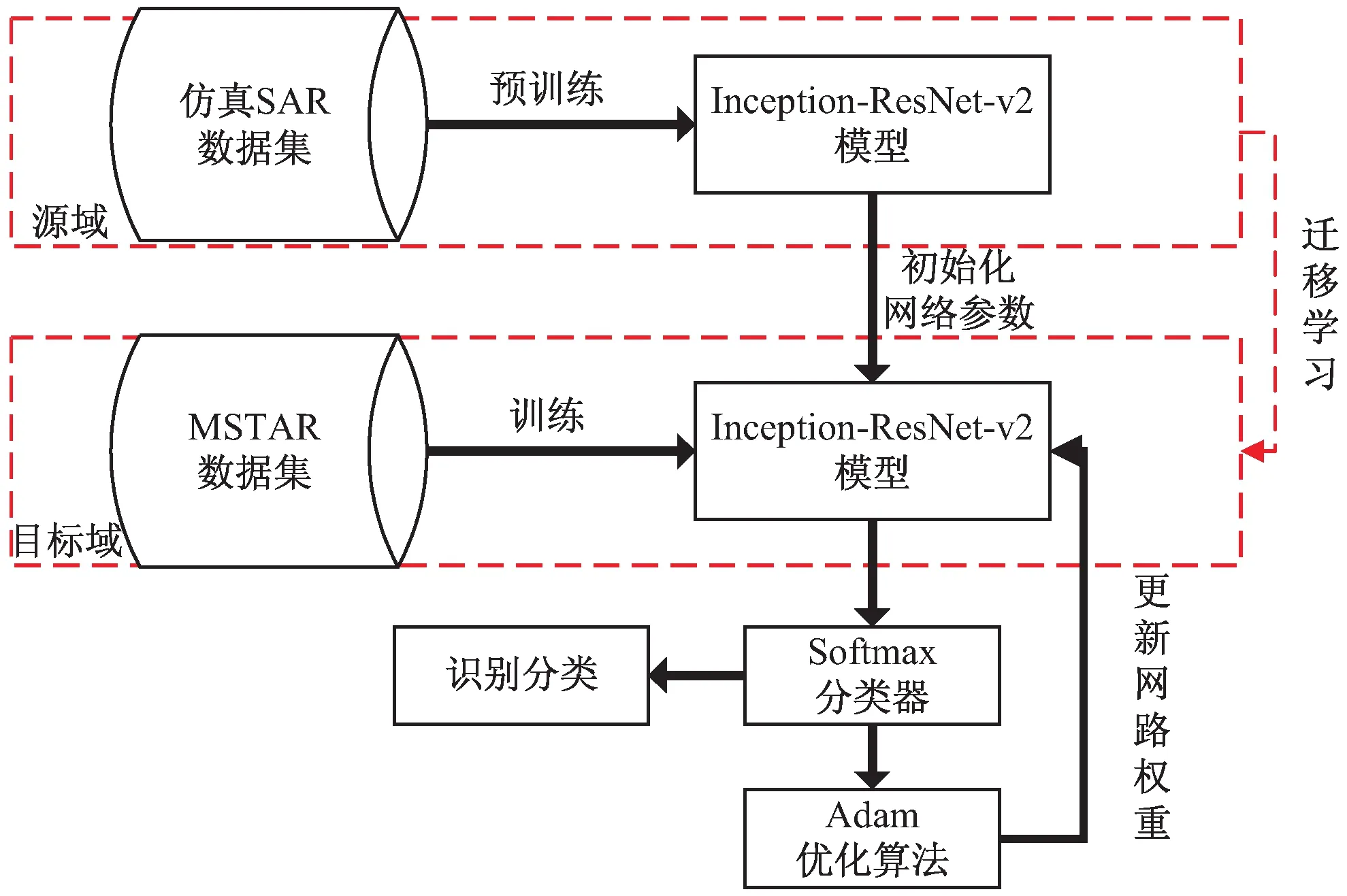
图3 SAR迁移学习的模型
3 实验结果与分析
实验在tensorflow1.10+keras2.2.2框架下实现神经网络的搭建。实验环境配置:win10操作系统、i7-8750h处理器、GTX1060显卡、16 G内存。
3.1 实验数据集
文中选用SAR仿真数据集作为预训练模型的数据集。该数据集包含三种不同场景下的七类SAR仿真图像,每类图像由七个不同方向角下仿真获取,总计21 168张仿真图像。
为验证文中算法的有效性,实验选用MSTAR数据集作为实测数据集。MSTAR数据集包含了2S1、BMP2、BRDM2、BTR60等十类目标图像,其中十类目标的光学图像与其对应的SAR图像如图4所示。文中选用常用的17°方位角下的2 746张SAR图像与15°方位角下的2 426张SAR图像作为训练及测试样本。将两个方位角下的同类目标图像混合,并按照6∶4的比例随机在每类中抽取60%作为训练集,剩余的40%作为测试集,具体如表1所示。

图4 十类目标光学图像与其对应的SAR图像

表1 实测SAR数据
3.2 实验结果
输入图片的大小为224×224;学习率值为0.000 1;batchsize值为12;dropout值为0.5;迭代7 770次,通过实验结果数据分析,在迭代到6 475次时准确率达到最高。
十类SAR目标图像的识别结果如表2的混淆矩阵所示,其中BTR70装甲车、D7推土机、T72坦克、ZIL131卡车识别率达到100%。BMP2坦克识别率最低,但准确率也达到了98.84%。最终在测试集上的平均识别率为99.57%。

表2 十类SAR目标图像识别结果
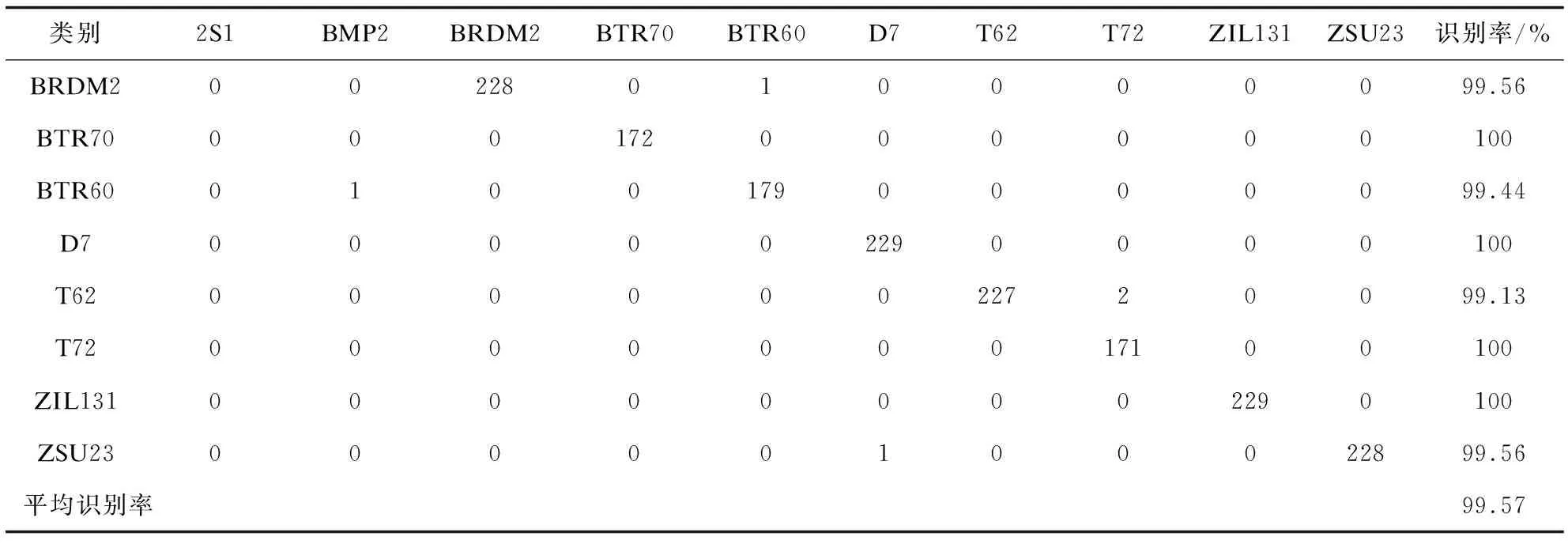
续表2
3.3 对比实验分析
对比实验一:
在该实验中,不对网络进行预训练。直接用17°方位角下SAR目标的训练集对网络进行训练,网络参数随机初始化,学习率、batchsize、dropout等值与文中实验保持不变。最终在15°方位角下SAR目标的测试集识别率仅达到91.64%。
用小样本数据集直接对神经网络进行训练,得到局部最优解的概率较大,训练出来的网络鲁棒性较差,不能充分提取图像更多的细节特征,所以识别的准确率较低。
对比实验二:
选用ImageNet数据集取代SAR仿真数据集对网络预训练,并保留预训练网络的相关参数。将预训练得到的参数作为目标模型的初始化参数,再用17°方位角下SAR目标的训练集对网络进一步训练至收敛。学习率、batchsize、dropout等值保持不变。最终在15°方位角下SAR目标的测试集识别率达到了97.47%,仍低于文中提出的方法。
与ImageNet数据集图像相比,仿真SAR图像的特征与目标SAR图像特征相似度更高,所以仿真SAR图像训练的模型具有更好的泛化能力。

图5 准确率对比
文中方法与两个对比实验的SAR识别准确率以及训练误差对比如图5和图6所示。总共训练30轮,其中每轮训练大约为259次,共计训练7 770次。
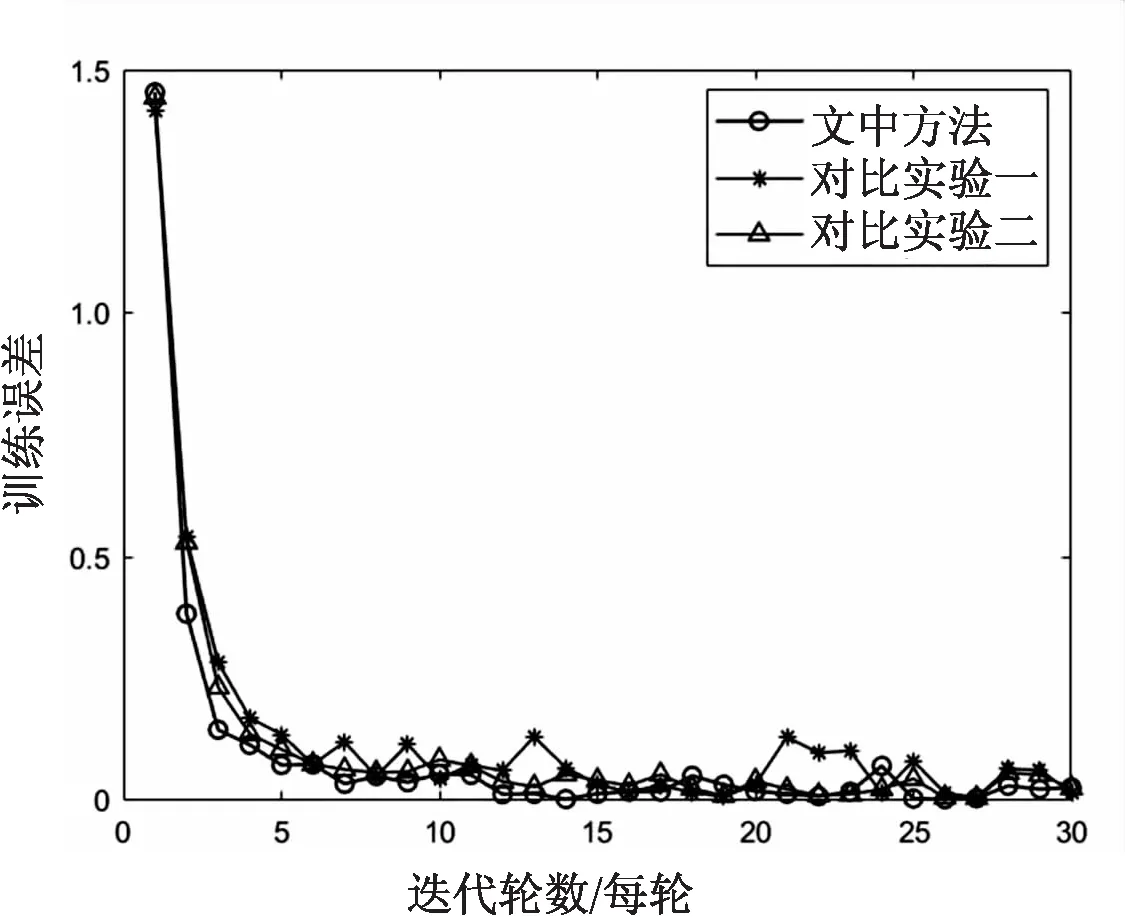
图6 训练误差对比
不同的SAR图像目标识别研究方法与文中识别方法的对比结果如表3所示。

表3 不同方法的网络模型性能对比
4 结束语
提出了一种基于卷积神经网络仿真SAR图像迁移学习的目标识别方法,能有效缓解现存SAR数据集较小带来的问题:使用Inception-ResNet-v2网络并融合Inception-v4网络的特征与残差网络的思路,在提高识别准确率的同时能够缓解梯度消失问题。还通过仿真SAR目标图像对Inception-ResNet-v2网络预训练,得到网络参数。将预训练获得的网络参数作为目标网络的初始化参数进行迁移学习,并利用SAR目标图像对网络进一步训练并更新权重等参数直至网络收敛。最终在测试集上获得了99.57%的识别率。该方法一定程度上避免了小样本数据集在网络训练过程中容易陷入局部最优解的问题,在实测SAR图像集上对其有效性进行了验证。
在现代太空立体化战争中,高效、准确地识别出对方地面投入战场的或后方的军备SAR图像极为重要。文中方法可为SAR图像目标的识别研究和进一步应用提供参考。
