基于Bagging集成学习的多集类不平衡学习
2021-10-28魏鹏飞郑鑫浩
肖 梁,韩 璐,魏鹏飞,郑鑫浩,张 上,吴 飞
(1.南京邮电大学 自动化学院、人工智能学院,江苏 南京 210003; 2.南京邮电大学 现代邮政学院,江苏 南京 210003)
0 引 言
传统机器学习中研究的分类算法假定数据集是平衡的,即数据集中各类别样本数大致相等[1]。但在如软件缺陷预测、医疗诊断、目标检测等相当多的应用场景下,数据的类别分布是不平衡的[2]。以提高总体分类准确率为目标的传统机器学习分类算法在平衡数据集上取得了较好的分类效果,但在不平衡数据集上,这些算法的决策倾向于多数类[3],使得少数类样本的分类准确率远低于多数类样本的分类准确率。而在软件缺陷预测或医疗诊断等类不平衡场景下,准确预测出属于少数类的有缺陷或患病样本恰恰是分类算法的目标。
为解决上述问题,提出基于Bagging集成学习的多集类不平衡学习算法。该算法主要由基于Bagging的多集构建和特征提取与多集融合两个模块构成。基于Bagging的多集构建通过重采样构建多个多数类与少数类样本数大致相等的平衡训练集并有效去除多数类样本中的噪声样本;特征提取与多集融合部分提高样本分离度并融合多个训练集所训练的分类器的预测结果,提升算法分类性能。
1 相关工作
近年来,针对类不平衡分类问题,国内外学者提出了很多创新性的方法,大致可归于重采样法(resampling technique)[4-6]、代价敏感学习(cost-sensitive learning)[7]和集成学习(ensemble learning)[8-9]。
基于重采样的方法可以分为欠采样(undersampling)[4]方法和过采样(oversampling)[5-6]方法。欠采样方法通过减少多数类样本来平衡少数类和多数类的分布,如Kubat等[4]提出单边选择算法去除多数类中的边界和冗余样本。过采样方法向不平衡的数据集中添加采样或生成的少数类样本来平衡数据集。例如,Chawla等人[5]提出一种合成少数类样本过采样技术(SMOTE),该方法随机选择一个少数类样本及它的近邻,并在两者连线上随机选取一点作为新生成的少数类样本。带多数类权重的少数类样本过采样技术(MWMOTE)[6]则根据少数类样本近邻中属于多数类或少数类样本的数量比例及距离计算信息权重,并依权重抽取样本进行SMOTE式插值样本生成。
基于代价敏感学习[7]的方法关注与错分样本有关的代价。这些方法通常构建一个代价矩阵,这个矩阵可以被认为是对于将某类样本错分为另一类的惩罚的数值表示。传统分类算法中不同类别的样本错分的代价(损失)是相同的,但代价矩阵对少数类样本错分为多数类赋予更大的代价,使得少数类样本的权重提高,从而缓解算法决策倾向于多数类的问题。
集成学习可以分为Boosting[8]和Bagging[9]两类。Boosting算法一般在迭代的过程中通过提高在前一轮被分类器错分的样本(一般为少数类样本)的权值,减小前一轮正确分类的样本的权值,使得分类器更加关注被错误分类的少数类样本。但选择适当的权重非常困难。Bagging算法从原始数据集中多次有放回地抽取样本构成多个训练集,并用这些训练集分别训练得到多个分类模型,最后将每个模型得到的预测结果投票得到最终的分类结果,其结构如图1所示。该算法有效提升了弱分类器的分类性能。
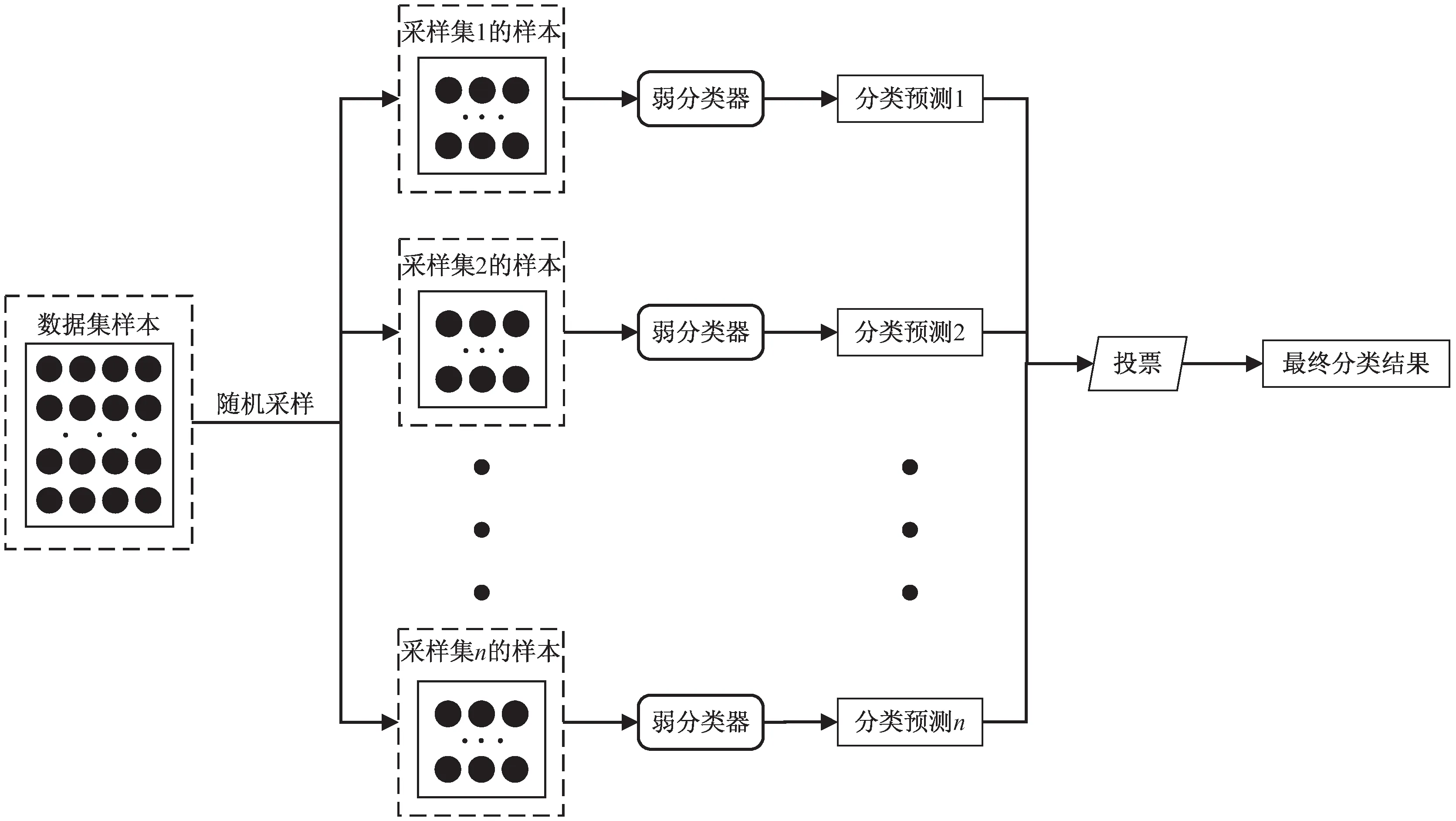
图1 Bagging结构
很多文献提出了基于Bagging思想的改进算法。如文献[10]提出了一种随机平衡采样Bagging 算法,该方法通过随机平衡采样算法,在不改变数据集大小的前提下平衡了数据集,但该方法随机舍弃大量多数类样本,导致多数类分布信息损失。文献[11]则提出了一种基于概率阈值Bagging算法的不平衡数据分类方法,该方法首先利用Bagging集成算法得到一个良好的后验概率估计,然后根据最大化性能测量值来选取恰当的阈值。但在实际操作过程中选择适当的概率阈值非常困难,且该方法只以提升平均准确率或F1-score这一单一评价指标为优化目标,在相当多的场景下,仅这一个指标并不能有效地评价算法的类不平衡分类性能。文献[12]利用SMOTE算法生成少数类样本并在Bagging集成中提高少数类样本的权重来处理不平衡数据集的分类问题,但该方法易出现过拟合的问题。
2 基于Bagging的多集类不平衡学习算法
基于Bagging集成学习的多集类不平衡学习算法由两部分构成:基于Bagging的多集构建部分、特征提取与多集融合部分,其结构如图2所示。基于Bagging的多集构建部分通过基于K-means[13]的欠采样算法和SMOTE过采样算法[5]构建多个平衡训练集;特征提取与多集融合部分利用线性判别分析(LDA)[14]对数据投影后用近邻分类器分类,并通过投票融合多个训练集的分类预测结果。
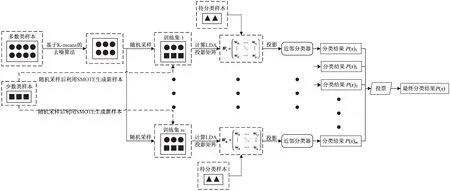
图2 算法结构
2.1 基于Bagging的多集构建
为减少多数类样本数量并去除其中的噪声样本,文中提出一种基于K-means[13]的欠采样算法。首先对多数类样本进行K-means聚类[13],聚类数k取一个大于1的值。选取聚类后样本数大于0.25nN的聚类中的样本,将其余样本视为噪声样本舍弃。与文献[15]中选取聚类中心点作为欠采样后的样本的方法相比,文中方法保留了多数类样本的分布信息并去除了其中的噪声样本,有利于后续的分类操作。同时,为减小训练集样本之间的相似度,每个训练集中的多数类样本从去噪后的多数类样本中以λ的采样率随机采样得到。
对于少数类样本,文中以μ的采样率从原始数据集中的少数类样本中随机采样,并依据这些样本使用SMOTE算法[5]进行过采样,直至少数类样本数量与多数类样本数量大致相等。新样本生成公式如下:
(1)
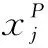
2.2 特征提取与多集融合
经过上述步骤可以得到多个平衡训练集,但此时训练集中多数类与少数类样本的分离度不高,直接进行分类效果不佳。线性判别分析(LDA)[14]能将高维的样本投影到一个最佳的判别矢量空间,在此空间中同一类的样本间距近,不同类的样本间距远,使得样本在该空间中有最佳的可分离性。故文中使用线性判别分析(LDA)对样本进行特征提取,将样本投影到一个分离度高的特征空间中。线性判别分析的损失函数如下:
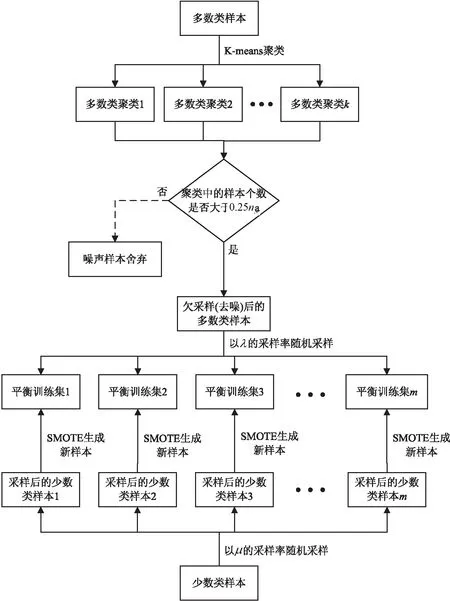
图3 基于Bagging的多集构建流程
(2)
其中,Sb为类间散度矩阵,Sw为类内散度矩阵,计算公式如下:
(3)
(4)
其中,C为数据集中样本类别数,ni为第i类样本的个数,xij为第i类样本中的第j个样本,μi为第i类样本的均值。而对于文中所解决的二分类问题,投影矩阵可以由下式快速求得:
(5)
其中,μP和μN分别是少数类与多数类样本的均值。
样本经过投影矩阵W投影后,可利用近邻分类器给出待分类样本的分类预测。对于每一个平衡训练集,都可由上述步骤得到待分类样本的一个分类预测。最后通过多数投票融合多个训练集的分类预测,得到待分类样本的最终分类结果。
基于Bagging集成学习的多集类不平衡学习算法如下所示。
算法1:基于Bagging集成学习的多集类不平衡学习算法。
输出:待分类样本的分类预测P(x)。

2:forj=1→mdo
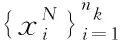
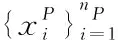


7:利用多数投票得到待分类样本x最终的分类预测P(x)
3 实 验
3.1 数据集
为了验证该方法的有效性,在PC1,Abalone19,Glass5,Page-blocks0和Shuttle0vs4数据集[16]上进行了对比实验。
PC1数据集为软件缺陷预测数据集,不平衡比为13.4∶1。Abalone19是一个生物信息预测数据集,不平衡比为129.4∶1。Glass5和Shuttle0vs4都是物品分类数据集,不平衡比分别为22.8∶1和13.9∶1。Page-blocks0数据集的每个样本为一个文件分类的特征表示,不平衡比为8.6∶1。各个数据集的相关属性如表1和图4所示。
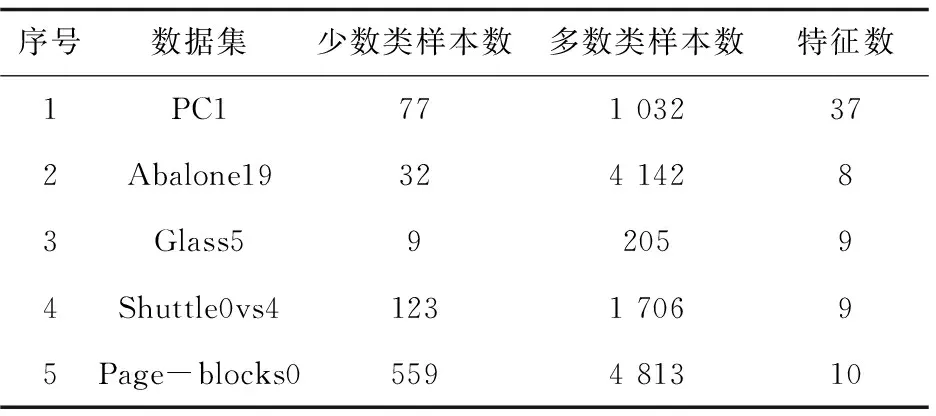
表1 数据集相关属性
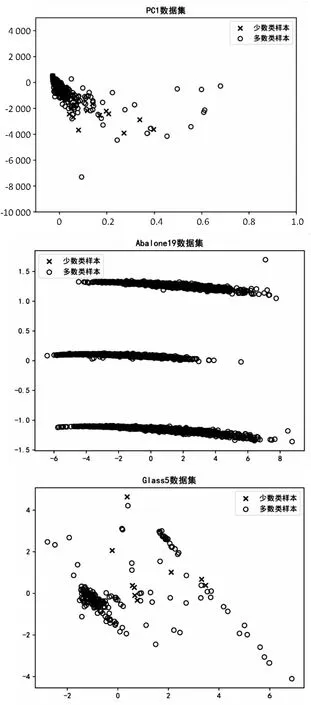
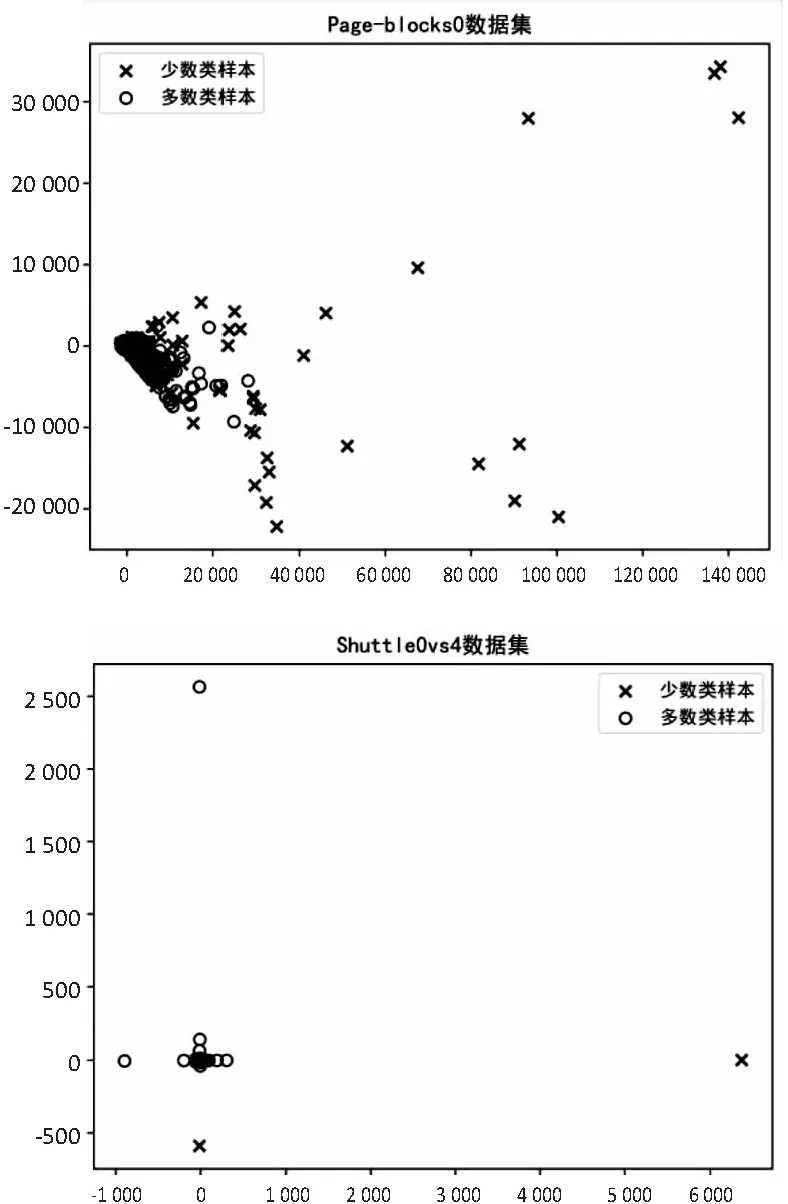
图4 数据集可视化
3.2 评价指标
采用类不平衡学习常用指标G-mean和AUC评估模型的预测效果。对于二分类问题,有如表2的混淆矩阵。

表2 二分类混淆矩阵
G-mean的定义如下:
(6)
对分类模型给出的样本的分类预测概率,遍历[0,1]上的所有截断点(阈值),以式(7)计算的假阳性率(FPR)为横坐标,式(8)计算的真阳性率(TPR)为纵坐标,可绘制出受试者操作特征曲线(ROC)。ROC曲线下的面积即为AUC,如图5所示。
(7)
(8)
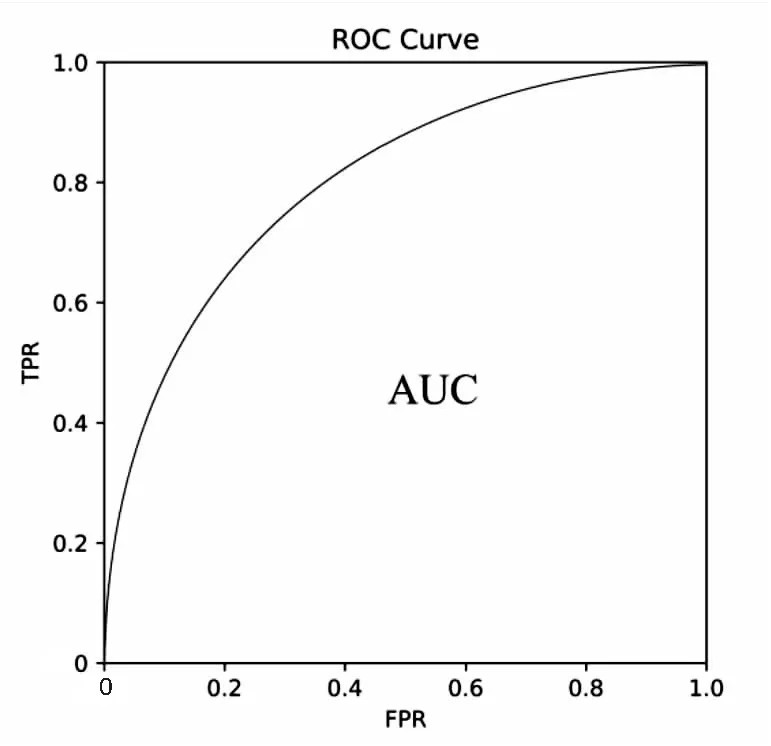
图5 AUC示意图
通常认为,G-mean和AUC越高,则算法能在不影响多数类分类准确率的前提下提高少数类样本的分类准确率,即算法对于不平衡数据集的分类效果越好。
3.3 算法参数设置
在实验时,文中方法中的参数─多数类采样率λ、少数类采样率μ和多集数m分别取0.80、0.95和20,对于PC1和Page-blocks0数据集,聚类数k取9,对于Abalone19和Shuttle0vs4数据集,聚类数k取4,对于Glass5数据集,聚类数k则取2。
3.4 实验设置及实验结果
选择基础分类算法k最近邻分类器(kNN)和线性判别分析加kNN(LDA-kNN),以及文献[6,17-19]中提出的类不平衡分类算法MWMOTE、EUSBoost、DBSMOTE和UCML作为对比方法。从数据集中多数类和少数类样本中各随机选取70%的样本作为训练样本,其余样本作为测试样本,对各方法进行100次实验,取实验结果的平均值。各个算法在五个数据集上的G-mean和AUC如表3和表4所示。
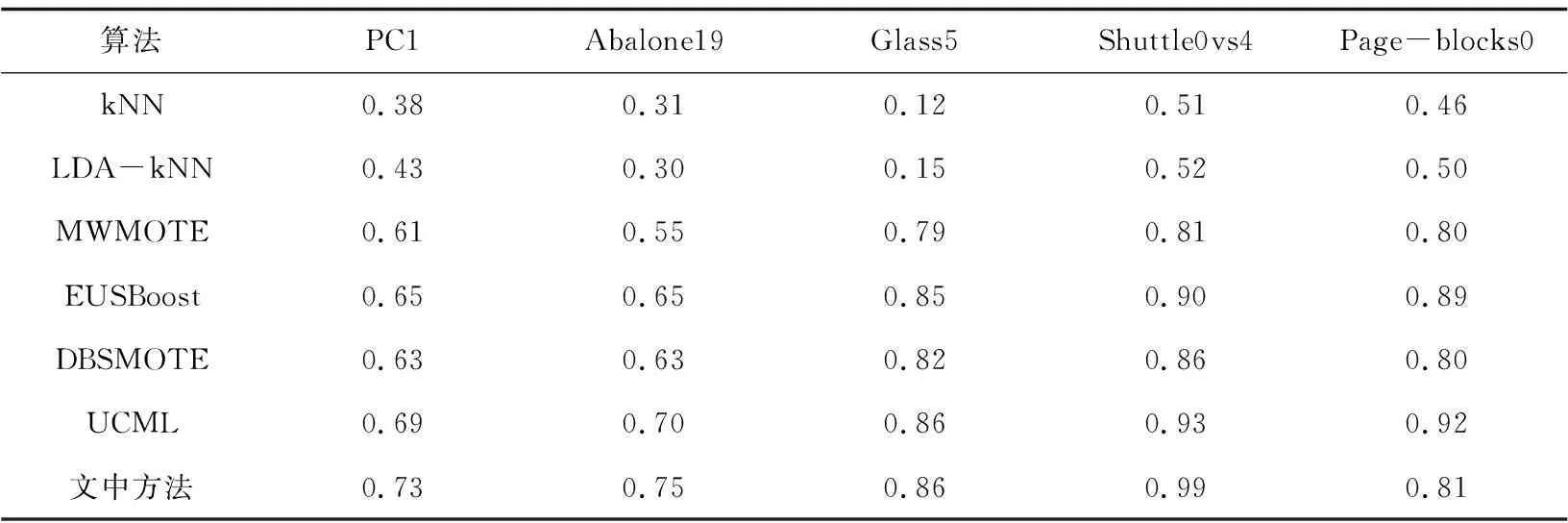
表3 G-mean实验值
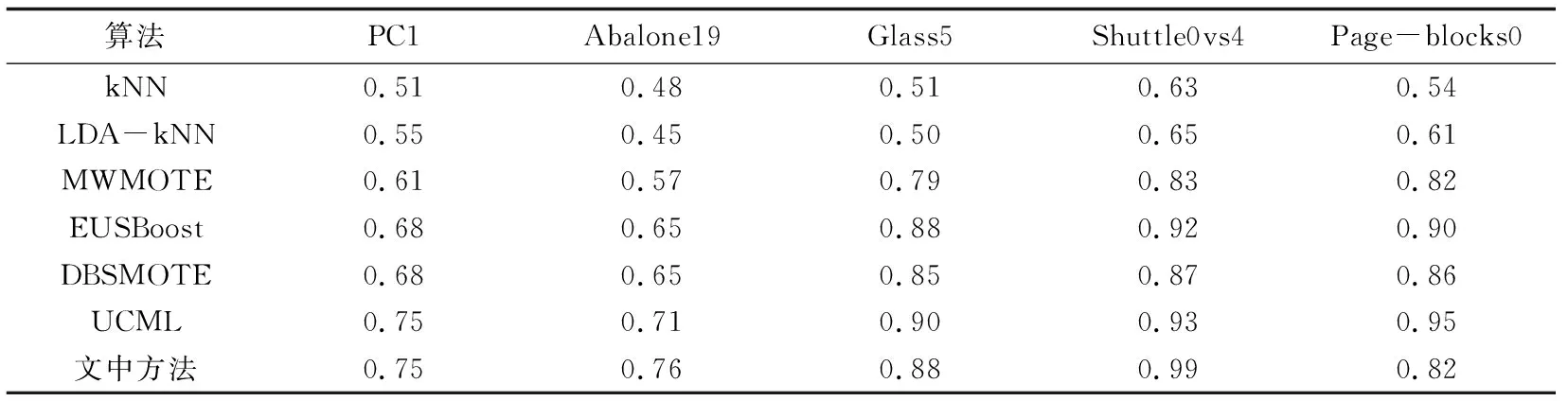
表4 AUC实验值
实验结果显示,与六个对比方法相比,文中方法在其中三个数据集上得到了最高的G-mean和AUC值,在另两个数据集上的G-mean和AUC值也处于较高的水平。文中方法不仅平衡了数据集中多数类与少数类样本的数量分布,同时去除了多数类中的噪声样本,还利用线性判别分析提高了多数类与少数类样本的分离度,并利用Bagging集成学习思想提升弱分类器的分类性能,从而提升了算法总体的类不平衡分类性能。
4 结束语
提出了基于Bagging集成学习的多集类不平衡学习算法,算法由基于Bagging的多集构建和特征提取与多集融合两个模块构成。该算法有效地缓解了不平衡数据集样本数量分布不均衡、存在噪声样本、类间分布重叠等问题。在PC1、Glass5、Shuttle0vs4等多个不同领域的不平衡数据集上的实验表明,该算法对于类不平衡数据具有良好的分类性能。但该算法只适用于二分类场景下的不平衡数据分类,接下来将进一步研究多分类情况下的不平衡数据分类。
