融合内容与协同过滤的混合推荐算法应用研究
2021-10-28李雪婷赛亚热迪力夏提赵昀杰
李雪婷,杨 抒,赛亚热·迪力夏提,赵昀杰
(1.新疆农业大学 计算机与信息工程学院,新疆 乌鲁木齐 830000; 2.成都大学 计算机学院,四川 成都 610000)
0 引 言
互联网数据量的激增导致信息过载成了大数据时代的显著问题。数据的增长率已远大于人们的处理能力,现有的技术已不能很好地处理日益加速增长的数据[1]。从冗杂的数据中,人们难以快速准确地获取有价值的信息。根据热门信息的展示很难满足用户的个性化需求,为此推荐系统应运而生[2]。近年来,推荐系统在电商平台、短视频App、社交网站等各个领域中广泛应用,使其快速发展并具有一定商用价值。比如在电商平台中用于挖掘用户行为数据里的隐藏商业价值。
据相关部门统计,推荐系统对网上商品销售的贡献率为20%~30%,已经成为电商平台中至关重要的工具之一[3]。
1 相关研究
推荐系统根据实现方式的不同可将其分为基于内容、基于协同过滤、基于深度学习和混合的推荐系统[1]。其中基于内容的推荐系统能够较好地为用户提供个性化推荐服务,适应冷启动问题,但准确率不高。基于协同过滤的推荐系统应用最广泛[4],能够较为准确地向用户进行推荐。该算法并不依赖于物品的相关内容信息,但需要有用户行为数据做支撑。当数据库中数据稀疏或者没有数据时,没有足够的信息使该算法进行用户行为分析,导致推荐质量不高,推荐结果的有效性较差[5]。混合推荐算法是解决上述问题较为成熟的方法之一,该算法将多种推荐算法进行混合,在实际应用中能够使各个推荐算法发挥其各自的优势,并且在一定程度上避免了其各自的劣势,进行高质量推荐[6-7]。目前,有众多学者将其在各个领域中应用。例如,何锴琦等人[8]将两种传统基于内存的协同过滤方法进行混合,应用在GitHub项目个性化推荐中。冉从敬等人[9]将基于内容和基于协同过滤的推荐算法进行混合,应用在高校专利个性化推荐中。王末等人[10]将动态加权的混合过滤推荐方法应用在地理数据共享领域中。叶小榕等人[11]将基于物品的协同过滤推荐算法和基于热点的推荐算法进行混合,应用在图书选取中,都取得了较好的效果。文中采用级联的方式将基于内容与协同过滤的推荐算法进行混合,将其应用在移动电商应用领域中,解决用户难以从大量信息中获取满足个性化需求数据的问题。
2 理论基础
2.1 基于内容的推荐算法
基于内容的推荐(content-based recommendation)算法最早用于信息检索[12]。该算法将用户和物品的特征都用显式标签进行表示,利用得到的用户标签与物品标签构建用户画像与物品画像,并进行相似度度量,得出相似度较高的TOP-N项完成推荐[13],其结构如图1所示。
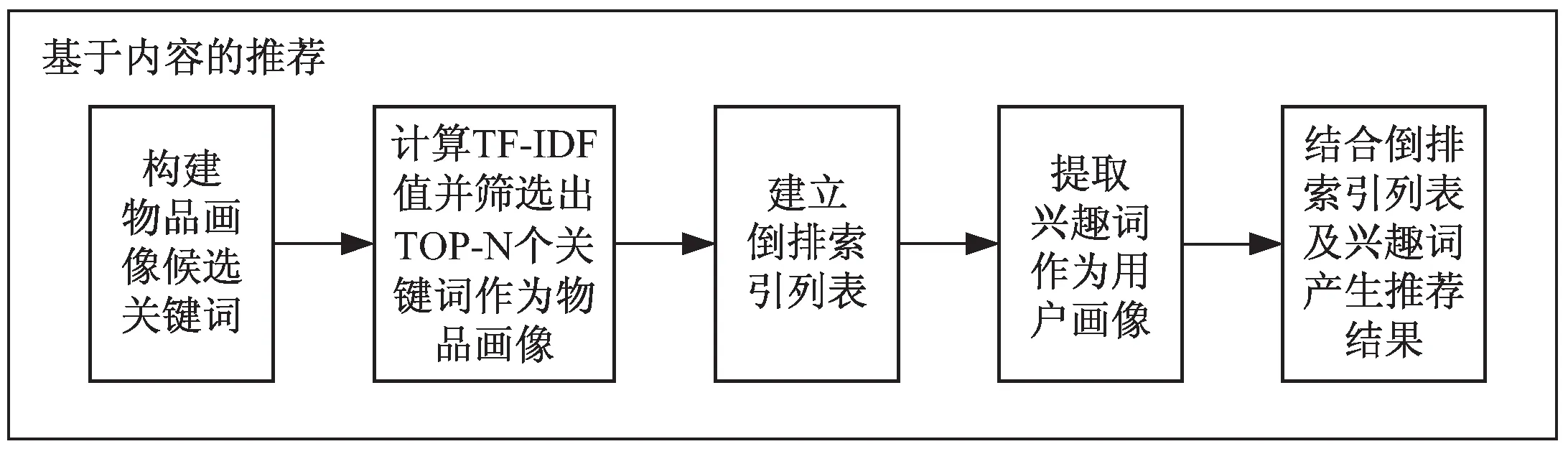
图1 基于内容推荐算法结构
通过物品的分类、属性特征等信息构建物品画像的候选关键词。利用TF-IDF(term frequency-inverse document frequency)计算出候选关键词的权重值:
(1)
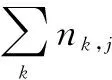
利用TF-IDF计算出的权重值选取TOP-N个候选关键词作为物品画像,建立倒排索引列表。根据用户在登录系统时的反馈信息收集用户兴趣词,并结合其属性特征构建用户画像。运用用户画像及物品画像进行相似度计算,其计算方法有很多种,如余弦相似度[15]、Jaccard相似度[16]及Pearson相似度[17]等。其中余弦相似度在计算过程中不考虑向量长度。Jaccard相似度计算的是两个集合的交集元素个数占并集的比例,适合用于布尔向量表示。Pearson相似度在计算过程中不仅考虑向量夹角余弦值还考虑向量长度。因此,选取Pearson相似度作为相似度计算方法:
(2)
最后,将相似度最高的TOP-N项作为推荐结果进行输出。
2.2 基于协同过滤的推荐算法
在基于协同过滤的推荐算法中,根据计算方式的不同可将其分为基于邻域和基于模型的推荐算法。文中采用的是Yehuda Koren等[18]提出的基于隐语义模型(latent factor model,LFM)的推荐算法,其结构如图2所示。
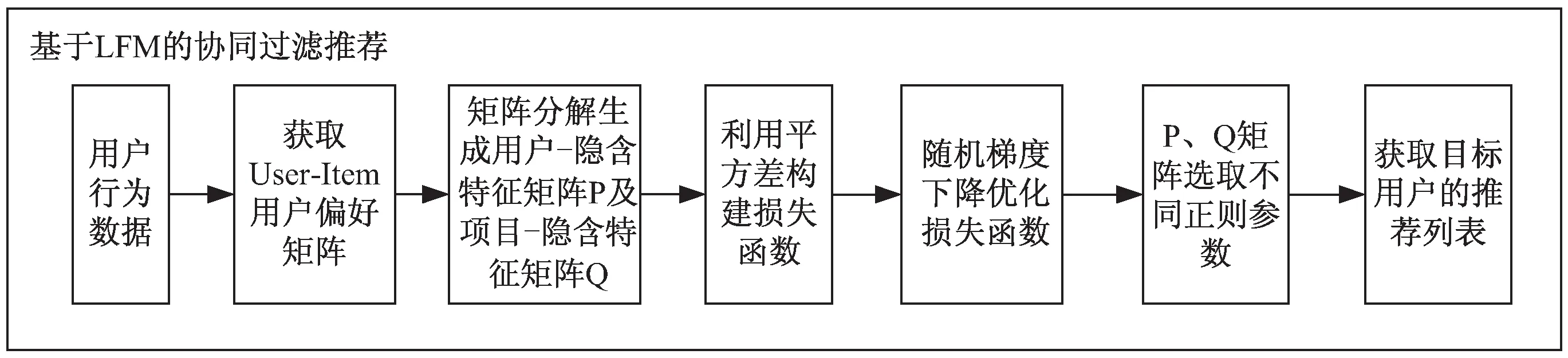
图2 基于LFM的推荐算法结构
LFM算法是一种基于矩阵分解(matrix factorization,MF)的协同过滤算法[19-20],其原理如图3所示。

图3 LFM算法原理
其中,P矩阵是User-LF矩阵,即用户-隐含因子矩阵;Q矩阵是LF-Item矩阵,即隐含因子-物品矩阵;R矩阵是User-Item矩阵,即用户-物品偏好矩阵。其中矩阵值P11为用户1在隐含因子1上的权重值;矩阵值Q11为隐含因子1在物品1上的权重值;矩阵值R11为预测用户1对物品1的喜爱程度。在该算法的实现过程中,运用矩阵分解技术将R矩阵进行降维,使其分解成P矩阵与Q矩阵,通过隐含因子将用户与物品进行关联:
Rui=PQ
(3)
再利用P矩阵与Q矩阵的乘积还原出R矩阵,将原有的稀疏矩阵进行填充,预测用户对物品的喜爱程度,F为隐含因子数:

(4)
如图3,有4个用户,3个物品及3个隐含因子。以用户1为例,用户1对隐含因子LF1、LF2、LF3的关联程度分别为P11、P12、P13。物品1与隐含因子LF1、LF2、LF3的关联程度分别为Q11、Q21、Q31。因此,用户1对物品1的感兴趣程度为:
R11=P11Q11+P12Q21+P13Q31
(5)
利用平方差构建损失函数:
(6)
为防止过拟合,加入正则化参数:
(7)
对损失函数求偏导:
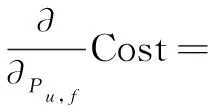
2λPu,f
(8)

2λQi,f
(9)
运用随机梯度下降法迭代计算,更新矩阵P和Q,从而找到最优的P矩阵与Q矩阵:
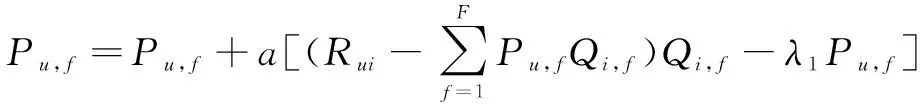
(10)

(11)
其中,a为学习率。
3 实验方法
3.1 实验数据
本实验采用的数据从马匹竞拍App的数据库中获取,数据集由两部分组成。第一部分是用户到马匹的评分数据集,收集80个用户在马匹竞拍App上的行为数据共22 423条。用户行为数据主要包括是否浏览,是否收藏,是否参与竞拍,用户浏览的马匹所具备的品种、价格、毛色、地区、性别、年龄等。并对其分别设置权重,计算用户对马匹的喜爱程度得出用户到马匹的评分数据集。其评分范围为0~5,其结构如表1所示。

表1 用户评分
第二部分是马匹竞拍App中925条马匹数据。每条马匹数据都含有马匹的RFID、品种、价格、毛色、地区、性别、年龄等属性,其结构如表2所示。
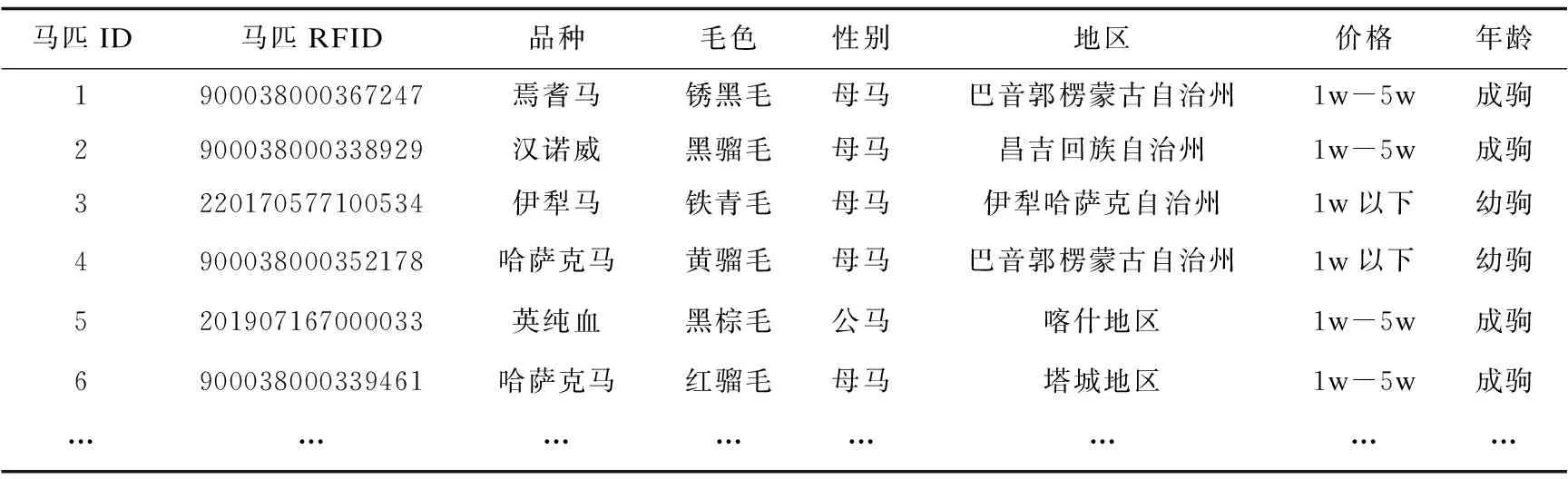
表2 马匹信息
在实验中,将数据集进行进一步划分,使其80%作为训练集,20%作为测试集。
3.2 混合推荐算法
文中采用基于内容和协同过滤的混合推荐算法来实现竞拍App中马匹的推荐。将参与竞拍的马匹向用户进行个性化推荐,产生较为可靠的推荐结果。使得用户能够快速地找到心仪马匹,提升用户参与竞拍的积极性,增加参与同场竞拍人数,降低流拍比例,优化马匹竞拍App首页商品展示界面。其流程如图4所示。
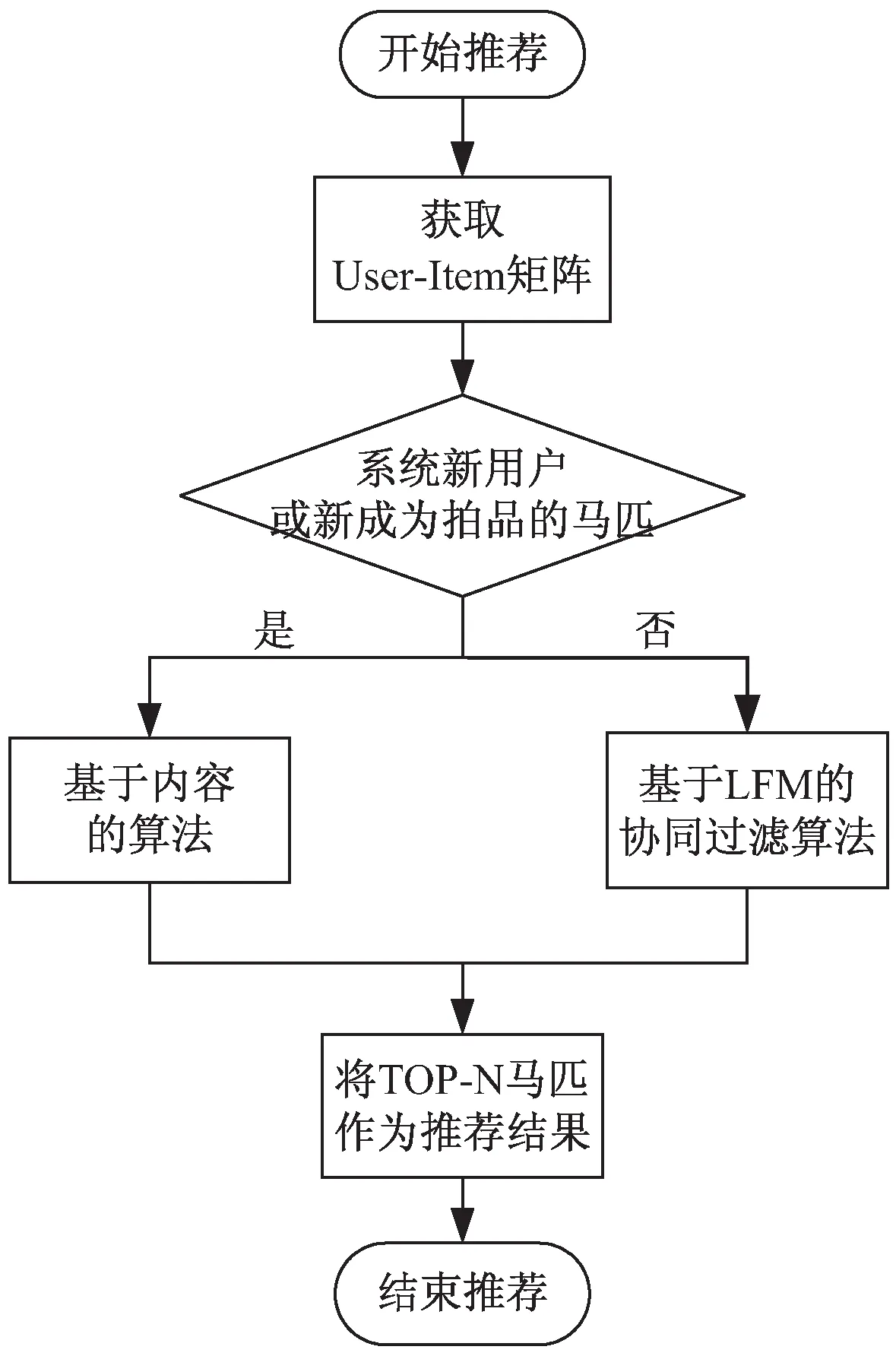
图4 混合推荐算法流程
收集用户在马匹竞拍App上的行为数据,获取User-Item矩阵。判断当前用户是否为马匹竞拍App新注册用户或马匹竞拍App中是否有新成为拍品的马匹。如果既不是新用户,也没有新成为拍品的马匹,那么通过矩阵分解将User-Item矩阵做降维处理,使其分解成用户-隐含因子矩阵P及马匹-隐含因子矩阵Q,用隐含因子做连接用户与马匹的桥梁。使用平方差构建损失函数,再运用随机梯度下降法迭代计算,不断更新矩阵P和Q,并加入避免过拟合的正则参数,从而找到最优的P和Q矩阵。建立LFM模型,对用户未评分马匹的兴趣度进行预测,将TOP-N项作为推荐结果进行输出。以马匹竞拍App中ID为10的用户为例,当N=10时,推荐结果如表3所示。

表3 基于协同过滤推荐结果
当有新注册用户使用马匹竞拍App或者有新马匹成为拍品时,数据库新增的数据没有任何历史行为,就会面临冷启动问题。此时利用基于内容的方式进行推荐,根据马匹的属性标签构建物品画像的候选关键词。利用TF-IDF算出关键词的权重值,从中选取TOP-N个作为马匹画像。此处选取部分马匹画像进行展示,如表4所示。

表4 马匹画像
根据用户在登录时对马匹进行的反馈信息收集用户兴趣词,结合用户的属性特征构建用户画像。以马匹竞拍App中新注册ID为144的用户为例,构建的用户画像如表5所示。
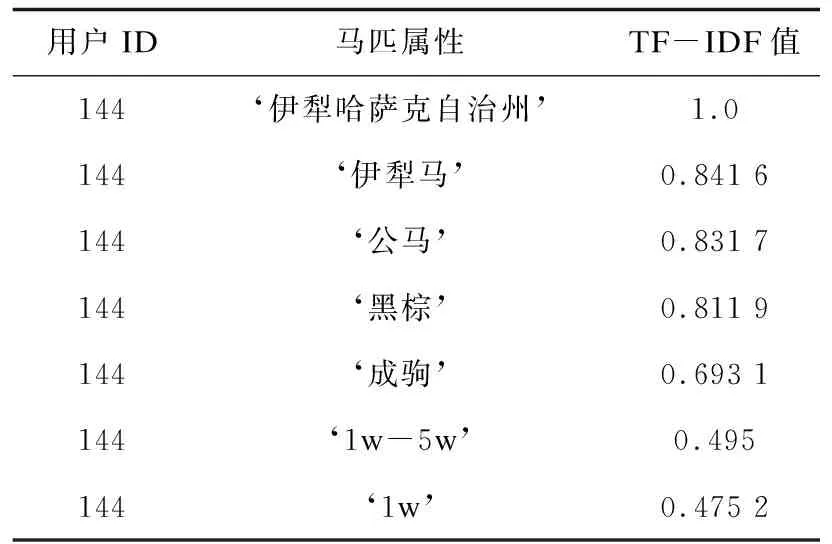
表5 用户画像
运用用户画像从物品画像中寻找最匹配的TOP-N项作为推荐结果进行输出。当N=10时,推荐结果如表6所示。
表6 基于内容推荐结果
4 实验结果及分析
4.1 评估准则
在本实验中选取的评估准则为以下三种:
(1)准确率(Precision):在产生的TOP-N个推荐结果中用户喜欢的物品个数和所有被推荐物品个数N的比值,用于衡量推荐系统对用户偏好的预测能力。其计算公式如下:

(12)
其中,U为用户总量,R(u)为对每个用户产生的推荐结果集,T(u)为用户实际的行为结果集。
(2)召回率(Recall):在产生的TOP-N个推荐结果中用户喜欢的物品个数和测试集中用户喜欢物品个数的比值,用于衡量推荐系统的实际推荐效果。其计算公式如下:
(13)
(3)覆盖率(Coverage):产生的TOP-N个推荐结果个数与物品总数的比值,用于描述推荐系统对长尾物品的发掘能力。其计算公式如下:
(14)
其中,I为物品总数。
4.2 实验结果分析
为证明本实验提出的方法推荐质量更佳,使用提出的基于内容和基于协同过滤的混合推荐算法与基于用户的协同过滤推荐算法和基于物品的协同过滤推荐算法进行对比实验。分别计算在推荐长度为5、10、15、20、25和30时,三种方法的准确率、召回率和覆盖率,其结果如表7~表9所示。并绘制出推荐长度为5、10、15、20、25和30时的变化趋势,如图5~图7所示。

表7 准确率 %
观察表7和图5可知,文中采用的融合内容与协同过滤的混合推荐方法在指定推荐马匹个数的情况下准确率优于基于用户和基于物品的推荐方法。当推荐长度大于或等于25时,准确率逐渐趋于稳定状态。

表8 召回率 %
观察表8和图6可知,随着推荐长度的增加,混合推荐方法的召回率也逐渐优于基于用户和基于物品的推荐方法。当推荐长度等于15时,混合推荐方法的召回率超过其基于用户和基于物品的推荐方法。

表9 覆盖率 %
观察表9和图7可知,混合推荐方法的覆盖率也优于其他两种推荐方法。当推荐长度大于等于25时,覆盖率逐渐趋于稳定状态。

图5 准确率对比 图6 召回率对比 图7 覆盖率对比
综上所述,混合推荐算法不仅能够解决冷启动问题,还具有更高的推荐质量,可以更好地为用户提供推荐服务。
5 结束语
随着电子设备智能化的发展,推荐系统在移动电商平台中得到了广泛应用。将统计分析方法与机器学习相结合,提出的融合内容与协同过滤的混合推荐算法能够规避单一算法的弊端,融合其各自优势。敏锐地捕捉用户需求,使用户能够从移动电商平台的大量数据中快速获取所需信息,产生有针对性的高质量推荐结果,减少用户时间成本,具有一定的应用价值。在真实的数据集下,将提出的混合推荐算法同传统的推荐算法进行对比实验,验证了该算法在准确率、召回率和覆盖率上具有一定的优越性。
