结合注意力混合裁剪的细粒度分类网络
2021-10-28白瑜颖刘宁钟姜晓通
白瑜颖,刘宁钟,姜晓通
(南京航空航天大学 计算机科学与技术学院,江苏 南京 211106)
0 引 言
近年来,基于深度学习的图像识别技术迅猛发展,研究人员也不再局限于将目光放在通用物体分类如车和猫,转而向细粒度图像分类发起了挑战。细粒度图像分类旨在区分同属某一大类的物体的更加精细的子类,因而具有更高的识别难度[1]。对于细粒度图像分类而言,首先,类间差距大类内差距小,如何发掘图像中具有判别性的局部区域进行分类成为了关键问题;其次,细粒度数据集常常存在类别多,而数据量较少的问题,容易产生训练时的过拟合;最后,为了降低标注成本,易于实际应用,如何利用图片级别的弱监督方法进行细粒度分类,也是需要解决的问题。
针对上述问题,文中提出一种结合改进混合裁剪的弱监督注意力数据增强网络。通过基于弱监督注意力机制的混合裁剪数据增强解决过分拟合背景的问题,通过改进混合裁剪解决混合背景的问题。一方面避免网络过分拟合背景,另一方面增强网络对局部特征的学习。该方法仅需图像级别标注信息,同时可进行端到端训练。为验证方法的有效性,在四个细粒度公开数据集上进行了验证。
1 相关工作
(1)细粒度图像识别。目前主流的基于深度学习的细粒度图像识别方法大致分为四类:基于部件级别标注信息的强监督方法如借鉴了目标检测领域的R-CNN[2]方法的Part-based R-CNN[3]方法通过强监督信息提升性能;基于端到端特征编码的方法如双线性卷积神经网络B-CNN[4]、kernel pooling[5]、hierarchical bilinear pooling[6]和MC_Loss[7]等方法通过获取高阶特征或者设计新的损失函数进行细粒度识别;基于弱监督局部定位的方法如NTS-net[8]以及结合非局部和多区域注意力的改进方法,它结合了目标检测领域的RPN方法[9]进行值得关注区域的定位和MA-CNN[10]方法通过通道聚类进行部件检测从而进行细粒度特征提取;基于注意力机制的方法如循环注意力卷积神经网络RA-CNN[11]和基于多尺度特征融合与反复注意力机制的细粒度图像分类算法[12]。
(2)混合裁剪数据增强。Sangdoo Yun等人提出了一种训练具有局部特征的强分类器正则化策略[13],称之为混合裁剪。具体做法是在A图片中随机裁剪出一个矩形,之后在数据集中随机选择B图片,并将B图片对应位置的像素填充到A图片裁剪掉的区域。而新图片的标记由加权求和得到。这个策略可以显著地增强网络对局部特征的学习,同时丰富背景,增强模型的泛化性能。但在细粒度图片中容易混合到背景。
(3)弱监督注意力数据增强网络WS-DAN[14]。该方法借鉴了端到端特征编码方法中的双线性池化操作,先通过多个1*1卷积操作获取注意力特征图,之后再将特征图和注意力特征图进行双线性池化获取特征矩阵,同时进一步利用注意力的位置信息进行裁剪和丢弃进行数据增强。但是双线性操作在带来高维特征的同时会有过拟合风险,同时基于注意力的丢弃操作虽然能使网络关注次要特征,同样的也可能使得网络过分拟合背景。
文中结合弱监督数据增强网络(WS-DAN)和混合裁剪数据增强,针对细粒度数据集种类多数据量少的特点,提出了基于注意力图的混合裁剪数据增强,避免网络过分拟合图片中的背景等干扰信息。
2 文中算法
2.1 模型概述
算法流程如图1所示。首先将图片预处理为448*448大小,然后通过ResNet-50对输入图像进行特征提取,获得2 048*14*14的特征图;其次,利用M个1*1卷积得到M个带有位置信息的注意力图,之后一方面利用双线性注意力池化对注意力图与原来的特征图进行融合,再通过全连接层并计算交叉熵损失;另一方面利用注意力图中的位置信息,对图像进行改进的混合裁剪数据增强,并重新送入网络中进行训练。同时利用类似中心损失的注意力正则化来对注意力图进行规范。
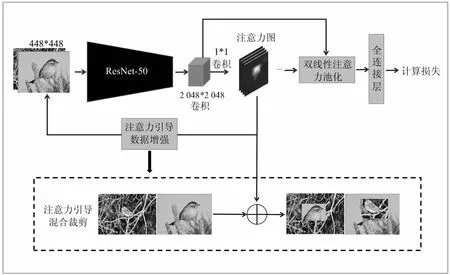
图1 算法模型
2.2 弱监督注意力数据增强网络
2.2.1 双线性注意力池化
首先,通过卷积神经网络提取到输入图像I的特征图F∈RH*W*C,其中H、W表示特征图的长和宽,C表示特征图的通道数。之后通过M个1*1卷积核将F转化为注意力图A∈RH*W*M。M的值为超参数,代表注意力图的数量。公式如下:
(1)
其中,f(·)即指代1*1卷积操作。
在获取到注意力图集合A之后,利用双线性池化操作将注意力图集合A与原本的特征图F进行汇合。对于每一个注意力图Ak,将其逐元素乘到原本的特征图F之上,得到M个强化局部特征的双线性特征图F∈R1*N,达到增强细粒度识别的效果。同时为了降低特征维度,利用全局平均池化或者全局最大值池化对M个fk进行判别性局部特征提取,获得M个局部特征向量。最后将这些局部特征拼接起来得到最后的特征矩阵。该步骤如公式(2):
(2)
其中,P表示最后拼接得到的特征矩阵P∈RM*N,⊙符号表示逐元素乘积,g(·)指代全局池化操作,Γ(A,F)表示对注意力图A的原特征图F的双线性池化操作。
2.2.2 弱监督注意力学习
借鉴中心损失思想,引入弱监督注意力学习正则化方式。具体做法是,对于每次通过模型得到的特征图fk,都与该类别的特征中心CK∈R1*N计算均方误差作为中心损失,见式(3)。模型即会倾向于对每一个类别学习到相似的特征,对于注意力图的每个通道亦会倾向于响应各自固定的部件。
(3)
而特征中心C在最初被初始化为全零,之后在训练过程中不断地根据训练中的特征图fk来更新其标记所属类的特征中心,如式(4)。
ck=ck+β(fk-ck)
(4)
其中,β为超参数,文中按照原文建议设置为0.05。
2.3 注意力引导混合裁剪
对于细粒度识别而言,采用随机混合裁剪的方式进行数据增强,往往会裁剪到背景,无法带来正向的收益,因此提出改进的基于注意力的混合裁剪算法。详细算法介绍如下。
令x1,x2∈RH*W*C分别为两张图片,y1,y2分别对应两张图片的标记。x1,x2在经过弱监督注意力网络之后,会得到各自的注意力图A1,A2∈RH*W*M。
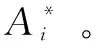
(5)
(6)
其中,(m,n)表示特征热力图或者掩膜的横纵坐标值。
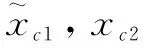
(7)

而对应的,不同于原本的混合裁剪数据增强采用根据面积比值求加权和的方式,笔者认为根据注意力引导的混合裁剪会将图片最主要最具判别性的特征全部裁剪掉,并进行交换,因此将两张图片的真实标记y1,y2进行交换,如式(8):
(8)

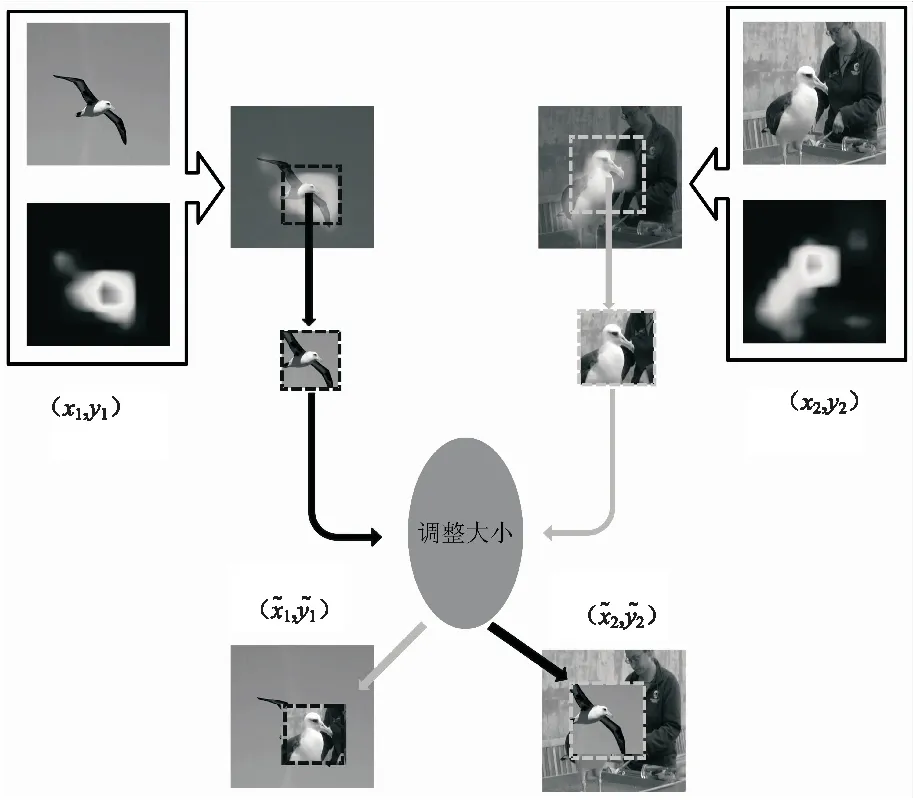
图2 改进的注意力混合裁剪算法流程
3 实验结果及分析
3.1 实验设置
3.1.1 数据集
实验在四个公开细粒度数据集CUB200-2011、Stanford Dogs,Stanford Cars,FGVC Aircraft上进行,数据集详细信息见表1,数据集部分图片示例见图3。
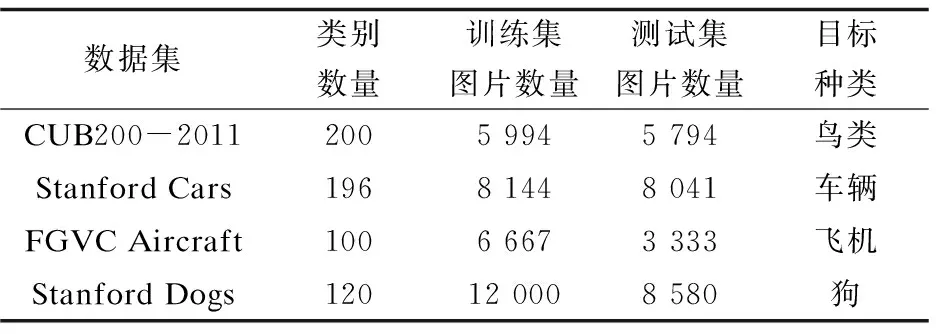
表1 四个常见公开细粒度数据集

图3 常用数据集图片示意
3.1.2 实验细节
在接下来的实验中,使用去除全连接层的残差网络Resnet-50[15]作为基础网络进行特征提取,注意力图的数量M设置为32,即使用32个1*1大小的卷积进行注意力图的获取。对于裁剪阈值θ,选取了(0.4,0.6)之间的一个随机实数。
对于模型优化方法选择随机梯度下降SGD,动量参数设置为0.9,最大迭代次数设置为80,权重衰减设置为0.000 01,同时将每个批次的大小设置为12。初始学习率设置为0.001,每两次迭代将学习率缩放为0.9倍。实验在RTX2080Ti 11G显存上进行,实现框架为pytorch。
3.2 对比实验
首先在四个数据集上与现有的先进算法进行了实验对比,对于基准算法WS-DAN,使用了pytorch的复现版本,在表格中同时将原文结果与复现结果进行展示。评价指标使用Top-1准确率(表2中将同一数据集下最好的结果进行加黑,将第二好的结果添加下划线以便查阅)。
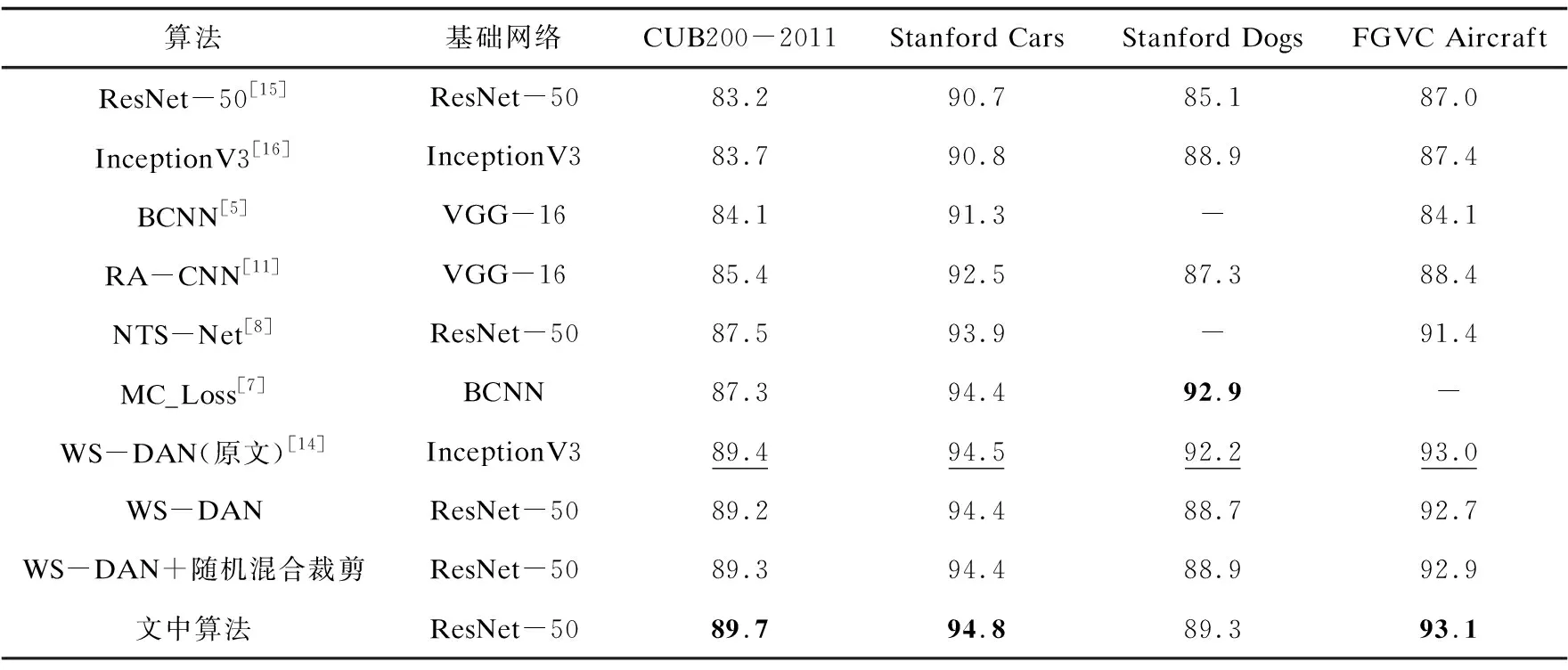
表2 对比实验结果 %
可以看到,文中方法在CUB200-2011鸟类数据集,Stanford Cars车辆数据集和FGVC Aircraft飞机数据集上,均取得了最好的效果,分别达到了89.7%,94.8%和93.1%,优于近年来的先进方法;同时相较于基准方法WS-DAN(ResNet-50),在使用相同的基础骨架网络的基础上,在四个数据集上的精度分别提升了0.5%,0.4%,0.6%,0.4%,同时与随机混合裁剪方法相比,也有较为明显的提升,证明了文中方法的有效性。
3.3 可视化
为了进一步对比与随机混合裁剪的效果,在cub200-2011数据集上进行了可视化实验,直观展示了基于改进的注意力混合裁剪算法的效果。
如图4所示,可以看到利用注意力机制引导的混合裁剪避免了混合到背景的问题,同时,将具有判别性的特征混合裁剪到其他图片的背景中,大大丰富了训练数据的背景,降低了网络对于背景的过拟合的可能性,同时强化了网络对局部特征的学习。

图4 可视化效果
4 结束语
文中创新性地提出了基于注意力机制的混合裁剪数据增强方法。利用注意力网络在弱监督学习到的位置信息引导混合裁剪数据增强,一方面利用混合裁剪丰富训练数据背景,同时避免随机混合裁剪混合到背景的问题;另一方面增强网络对局部特征的学习,避免网络对背景的过拟合。实验结果表明,该方法相对于基准方法WS-DAN在四个细粒度数据集上的精度均有明显提升,并且在其中的鸟类、车型和飞机数据集上展现了很强的竞争力。该方法简单高效,仅需图像级别标注信息,可端到端训练,有着良好的应用价值。但目前方法的耗时较高,在今后工作中将把工作中心放在提升识别速度和提升精度上。
