基于机器学习的机票价格预测研究
2020-09-18单文煜吴垠陈鹏
单文煜,吴垠,陈鹏
(1.成都移花互动科技有限公司,成都 610041;2.成都市委办公厅,成都 610041;3.西华大学计算机与软件工程学院,成都 610039)
0 引言
因为民航市场的充分竞争以及航空公司相对先进的收益管理方法,机票价格时常会随时间大幅波动。面对这种不确定性,部分消费者尤其是个旅消费者,在做购买决策时会犹豫怕买贵,而OTA(Online Travel Agency)在销售过程中,如果能够适当提供一些确定性,就可以打消用户疑虑,提高购买转化。出于这个目的,我们开始了机票价格预测的研究,并最终变成我们产品中的功能,更好地服务了用户,为部分价格敏感型用户提供更多选择,也让用户放心下单。
价格预测本质是一个回归问题,现在机器学习领域已经有了很多成熟方法来应对各种回归问题,诸如线性回归、决策树回归、支持向量机回归、梯度提升回归、随机森林回归、XGBoost 回归等。
而要在实际应用中取得良好效果,主要取决与两点:
(1)拥有足够多高质量数据。正所谓garbage in,garbage out,一些远离业界的研究因为客观条件受限,往往只能得到短时间的小范围的数据。在这样的数据上得出的模型,很难实际应用。
(2)对所研究问题的业务有足够深刻的理解。机器学习本身就是一项与经验关联十分密切的技术,我们在选择机器学习算法时所做出的一些决定是否恰当,与算法的优化或技术层面关系并不大,有时对业务细节的掌握,才是踩准方法选择与参数优化方向的关键。
之前已有不少学者进行过这方面的研究,有的采用时间序列分析[1],有的采用贝叶斯算法[2],有的使用CNN[3],都取得了不错的效果。但他们都有上述两方面的不足。
我们作为中国移动互联网的早期参与者,在线旅行行业的创新型企业,自2012 年开始积累了大量的票价数据,也有能力从互联网上获取更多的数据。同时,我们作为旅行行业一线工作者,对整个行业,包括供应方、分销体系、消费者和监管机构都十分了解,是最能理解机票价格是如何构成,如何变化的那群人。这些积累对我们进行这项研究起了非常积极的作用。
1 数据准备
1.1 数据获取
数据全都取自历史业务数据。数据来源有两方面,一是机票销售的业务数据,这部分通过中国航信的API 接口查询获得,这种方式数据准确,但价格高;二是竞争对手的价格监控数据,这部分通过爬虫从各大OTA 网站页面上获得,这种方式数据不完全可靠,但价格相对低。
中国现在共有超过4000 个国内定期航班,数据量十分庞大,选取其中最有代表性的一部分进行研究已经足够。我们选取年旅客吞吐量超过100 万人的主要机场92 个,将各主要机场之间的航班纳入分析范围,提取了2019 年全年每天每个航班未来60 天的经济舱价格数据。
1.2 爬虫关键技术
利用网络爬虫获取如此大量的数据,会碰到诸多障碍:
(1)IP 限制。单IP 大量查询很容易触发反爬虫机制,比较好的解决方案是使用分布式爬虫,部署在拨号VPS 上
(2)动态页面。现代互联网网站大量使用前后端分离,浏览器页面渲染技术,这使得纯后端爬虫得不到需要的数据,应对方案是使用Headless Browser 或浏览器插件
(3)验证码。就算绕过诸多反制,业务请求过多还是会触发机器人检测(验证码识别),为这种任务做自动图像识别其实得不偿失,人工打码是更简单有效的方法。
1.3 数据聚合
所有这些数据在公司日常业务进行的过程中,就已存入了业务数据库,只是散落在多个数据库与表中。在开始研究之前需要写脚本归集这些数据到一个表中,方便后面的使用。在这个过程中,数据格式统一、缺失数据清理就已经完成,关键特征缺失的数据已经被排除在外。
2 特征工程
2.1 选取数据特征
作为机票销售的一线从业者,这部分更多是从业务理解出发,而不是从数据分析出发,开始就已经把想要的特征考虑好,然后去获取的这些数据。
民用航空领域的市场化程度非常高,机票价格最终是供求关系决定的。供应端的决定因素主要有航线航司分布、航司与代理的博弈、代理之间的竞争以及主管部门的政策影响,这部分因素相对稳定,短期内不会有大的变化。所以需求端的影响更加重要,需求端的变化也更大,有热门冷门线路的因素、有消费偏好的因素、有临时性计划性的因素、还有重大节假的影响因素,归纳如表1。
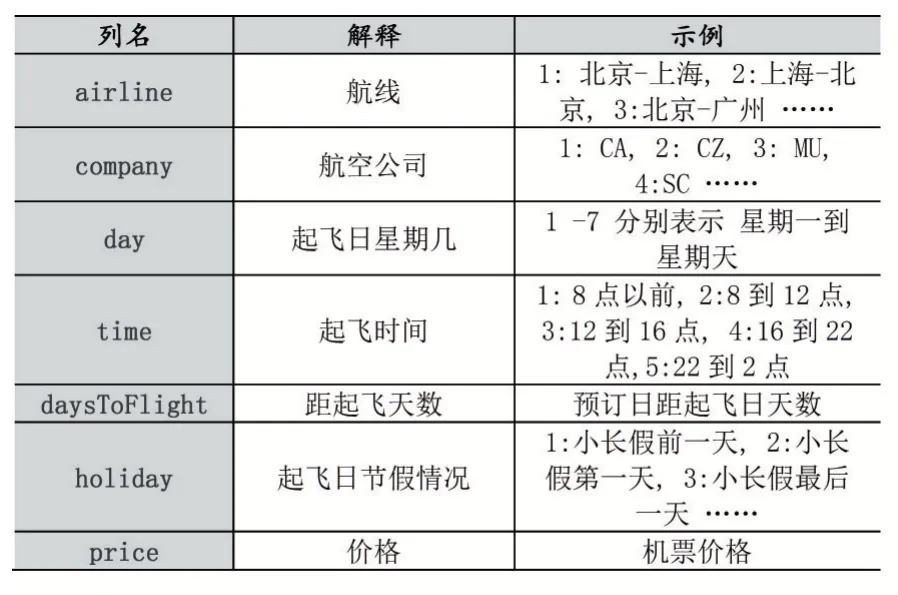
表1
2.2 数据预处理
按照上表将特征数据数值化,处理过后都是干净的数据。还需要额外做的处理是:
(1)通过均值分析,daysToFlight 大于 45 以后对价格影响很小,故删除daysToFlight>45 的数据。
(2)还需要额外处理的是价格。首先是异常值处理,通过查看频数确定正常边界,用边界值填充异常价格。其次价格不服从正态分布,所以在进行回归之前,必须进行转换。尝试用对数变换和无界约翰逊分布拟合,无界约翰逊分布拟合得更好。
3 模型训练
3.1 模型选择
我们选用了集成算法来训练模型。集成算法可以分为bagging 和boosting 两种集成方式。
Bagging 独立训练(可并行)多个基分类器,基分类器相互之间独立,然后用方法(投票法、平均法、stack⁃ing)把基分类器集成起来。代表算法为随机森林,森林的每棵树都是随机的。预测最终结果取N 棵树的平均,保证不会对某些特征的依赖。
Boosting 串行训练基分类器,基分类器之间相互依赖,每次训练完一个分类器后调整权重,再训练下一个分类器。代表算法XGBoost,XGBoost 更加有效应用了数值优化,Kaggle 竞赛平台上的TOP 算法一半以上使用了XGBoost 算法。
3.2 模型评价
评价标准为MAE(Mean Absolute Error),使用经典的五折交叉验划分训练集和测试集,多轮验证来减小过拟合。训练代码如下:

测试结果如表2。
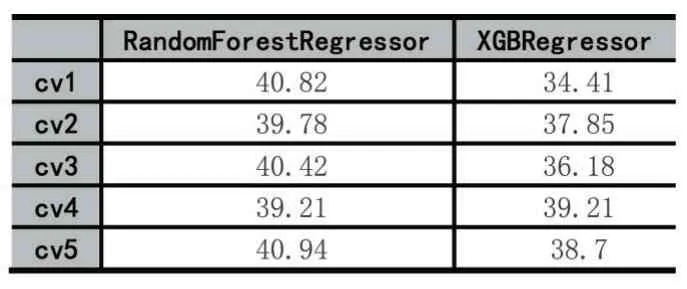
表2
相对于全部样本712 的均价来说,这个预测精度表现比较好。
4 模型融合
模型融合是一种能在各种的机器学习任务上提高准确率的强有力技术,Kaggle 比赛中最常用的就是Stacking 融合,基于初级学习器的概率输出,来训练次级学习器。一个Stacking 模型通过使用第一阶段的预测作为特征,比相互独立的训练模型能够得到更多的信息。Stacking 训练过程:
(1)拆解训练集。将训练数据随机且大致均匀的拆为m 份
(2)在拆解后的训练集上训练模型,同时在测试集上预测。利用m-1 份训练数据进行训练,预测剩余一份;在此过程进行的同时,利用相同的m-1 份数据训练,在真正的测试集上预测;如此重复m 次,将训练集上m 次结果叠加为1 列,将测试集上m 次结果取均值融合为1 列
(3)使用k 个分类器重复2 过程。将分别得到k列训练集的预测结果,k 列测试集预测结果
(4)训练过程3 得到的数据。将k 列训练集预测结果和训练集真实label 进行训练,将k 列测试集预测结果作为测试集
具体地,我们使用Stacking 融合随机森林和XG⁃Boost 构建一个新模型的过程如图1 所示。
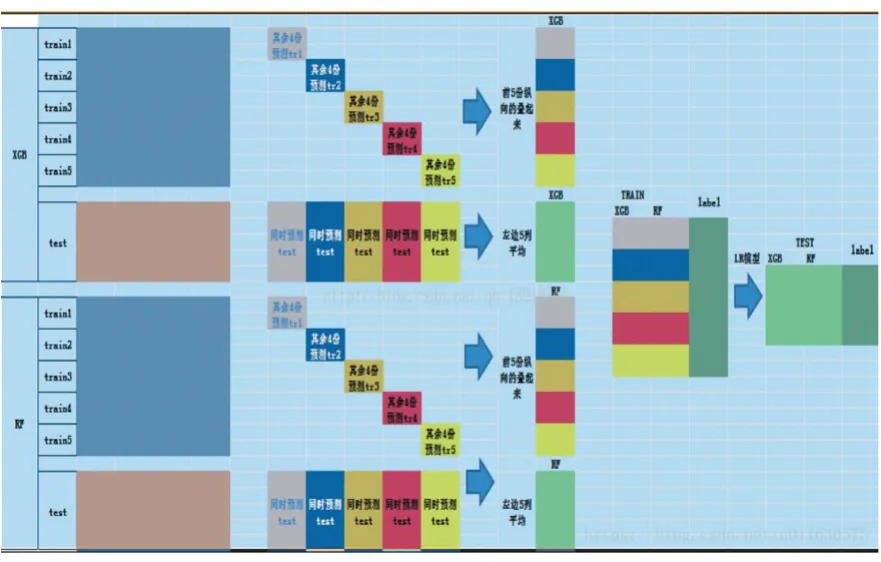
图1
融合后得到的结果

相较于融合之前又有了提高。对比融合前后价格预测实验结果,也可以观察到明显改进,以成都-广州的某航班为例,预测1 月到9 月的起飞前7 天的价格,融合前后的预测效果对比如图2。
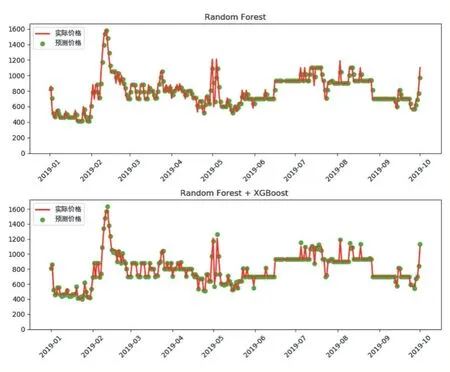
图2
5 结语
本文基于大量的实际数据和行业知识构建了预测模型,并在经典模型上做了一定改进,在测试集上取得了良好的预测效果。该模型最终应用到实际场景后,预测效果虽不及在测试集上的表现,但MAE 仍然可以控制在50 以内,对买没买贵的二元预测仍然有很高的准确率,达到了改进产品体验,提高销售转化的目的。
