基于双空间模糊邻域相似关系的多标记特征选择
2022-10-17徐久成申凯丽
徐久成 申凯丽
在传统的分类学习中,每个样本只包含一个类别标签,即单标记学习.然而,在实际应用中,大部分样本同时包含多个类别标签,即多标记学习[1-3].多标记学习与单标记学习一样遇到维数灾难的问题,多标记数据中存在一些可能与分类任务不相关或冗余的特征,导致诸如计算成本过高、过拟合、多标记分类学习算法的性能较低和分类学习过程较长等问题.特征选择作为一种常用的解决维数灾难问题的有效方法,在多标记分类任务中占有重要位置[4].
经典粗糙集[5]是一种处理不确定数据的数学工具,广泛应用于特征选择.为了扩展经典粗糙集的适用性,学者们提出邻域粗糙集模型(Neighborhood Rough Sets, NRS)[6]、模糊粗糙集模型(Fuzzy Rough Sets, FRS)[7]和模糊邻域粗糙集模型(Fuzzy Neigh-borhood Rough Sets, FNRS)[8-9].NRS可处理连续数值数据,已成为多标记学习研究热点和处理特征选择的新方向.然而,NRS使用邻域相似类近似描述决策等价类,无法表示模糊背景下实例的模糊性[10-11].Lin等[12]利用不同的模糊关系度量不同标签下样本之间的相似度,提出基于FRS的多标记特征选择算法.赵晋欢等[13]基于FRS,构造模糊辨识矩阵,对连续型数据进行属性约简.姚二亮等[14]同样在FRS中基于模糊辨识关系,分别从样本和标记角度计算多标记特征重要度.然而,FRS只使用模糊相似度划分决策类,并未划分样本之间的相似度阈值.FNRS可构造一个鲁棒的距离函数,使用模糊信息粒度描述实例决策,降低数据分类的错误率[15].FNRS在特征选择中具有一定的优势,初步处理多标记数据集的同时具有邻域粗糙集和模糊粗糙集的优势,既从邻域关系角度将多标记数据集上的特征进行分类,又从模糊相似关系的角度计算每个样本之间特征值的相似度.虽然基于FNRS的特征选择方法已在单标记数据集上广泛应用,然而少有针对多标记数据集的研究.因此,开发基于FNRS的多标记特征选择方法是有必要的.
现有的基于模糊邻域粗糙集的多标记特征选择算法多从特征或标记的单一角度刻画特征对标记的重要程度,未综合考虑特征空间和标记空间对样本相似度的影响,并且大部分基于邻域关系的特征选择方法是借鉴专家的经验选取邻域参数值,具有一定的主观性.因此,本文基于模糊邻域粗糙集模型,引入自适应邻域计算公式,并在特征和标记空间上利用样本间特征值的相似性对标记值相似性的关联程度度量特征的重要度,设计基于双空间模糊邻域相似关系的多标记特征选择算法(Multi-label Fea-ture Selection Based on Fuzzy Neighborhood Similarity Relations in Double Spaces, DSFNS).首先,设计自适应邻域半径的计算方法,构建特征空间下样本的模糊邻域相似矩阵.再根据模糊邻域相似关系,得出特征空间下的样本相似度及标记空间下的样本相似度.然后,通过权重将特征空间和标记空间上的样本相似度进行融合,基于融合后的度量计算属性重要度.最后,运用前向贪心算法构建多标记特征选择算法.在12个多标记数据集上的对比实验验证本文算法的有效性.
1 相关知识
1.1 模糊邻域粗糙集
定义1[16]设MFNDS=〈U,A∪D,δ〉为一个多标记模糊邻域决策系统,U={x1,x2,…,xn},B为论域U中的属性子集,B⊆A,由B引出一个模糊二元关系RB,对于∀x∈U,y∈U,RB(x,y)称为模糊相似关系.RB满足
1)自反性:RB(x,x)=1,∀x∈U;
2)对称性:RB(x,y)=RB(y,x),∀x∈U,y∈U.
定义2[16]给定一个多标记模糊邻域决策系统
MFNDS=〈U,A∪D,δ〉,
B⊆A,∀a∈B,Ra为由特征a引出的模糊相似关系,定义
对于∀x∈U,y∈U,模糊相似矩阵
[x]a(y)=Ra(x,y),
则x在U上关于B的模糊相似矩阵定义为
定义3[16]设MFNDS=〈U,A∪D,δ〉为一个多标记模糊邻域决策系统,对于∀B⊆A,x∈U,y∈U,参数化的模糊邻域信息粒构造如下:
其中,δ表示模糊邻域半径,0≤δ≤1.通过模糊相似关系RB和邻域半径δ可确定∀x∈U的模糊邻域粒.
1.2 自适应邻域半径
模糊邻域粗糙集上的邻域半径是根据样本之间的距离决定的.当选取邻域半径δ过大时,样本的邻域粒子变大、正域变小,分类准确率下降;当选取的邻域半径δ过小时,分类准确率虽得到提高,但样本的邻域可能变成样本本身,达不到特征选择的目的.目前,为不同的数据集选取合适的邻域半径是提高特征选择性能的重要因素.在大多数模糊邻域粗糙集上,邻域值是根据以往专家的经验人为给出,主观性较强[17],在不同的数据集上选取的邻域半径值相同,未结合每个数据集自身的分布特征进行选取.此外,部分方法将邻域半径值按一定的步长进行全选,计算每个邻域值求出的分类结果,再从中选取最优邻域值,这不仅浪费时间,而且会增加很多不必要的工作量,增加特征选择的复杂性.因此,本文提出自适应邻域半径公式,自适应调整每个数据集的不同分布结构.
定义4[17]设MFNDS=〈U,A∪D,δ〉为一个多标记模糊邻域决策系统,对于∀dk∈D,
B⊆A,B={a1,a2,…,am},
∀aj∈B,设标记D对论域U划分为
U/D={D0,D1},
决策类
Dr={x1,x2,…,xp},r=0,1,
则决策类Dr中样本相对于标记dk的特征集B的标准差为:
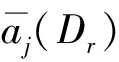
定义5[17]给定多标记模糊邻域决策系统
MFNDS=〈U,A∪D,δ〉,B⊆A,B={a1,a2,…,am}

2 多标记模糊邻域决策系统中的模糊邻域相似关系
多标记数据集上每列标记是二分值,每列特征为数值型数据,在计算某列特征下样本的相似度时,应在一定范围内从样本间的特征差值上定义,这个范围即为邻域半径,模糊邻域相似关系即为样本的相似性.特征之间的相似性与标记之间的相似性具有一定的关联性,从这一角度将模糊邻域相似关系应用在特征空间和标记空间下的样本相似度的度量中.
定义6设MFNDS=〈U,A∪D,δ〉为一个多标记模糊邻域决策系统,∀aj⊆A,x∈U,y∈U,其参数化的模糊邻域信息粒构造如下:
其中,δ表示由定义5得出的模糊邻域自适应半径,0≤δ≤1.通过模糊相似关系Raj和邻域半径δ可确定∀x∈U的模糊邻域粒.
定义7设MFNDS=〈U,A∪D,δ〉为一个多标记模糊邻域决策系统,U为论域,∀x∈U,y∈U,
A={a1,a2,…,am}
为特征集,∀aj∈A决定的模糊邻域相似关系定义为
其中,FNSajD(U)表示特征aj的相似样本对的集合,|FNSajD(U)|表示特征aj的相似样本对的个数.
例1给定多标记决策表MLDT=〈U,A∪D〉,如表1所示,
U={x1,x2,x3,x4,x5,x6},A={a1,a2,a3},D={d1,d2,d3},
设模糊邻域半径δ=1.

表1 多标记决策表Table 1 Multi-label decision table
根据
对表1中的数据进行归一化,如表2所示.
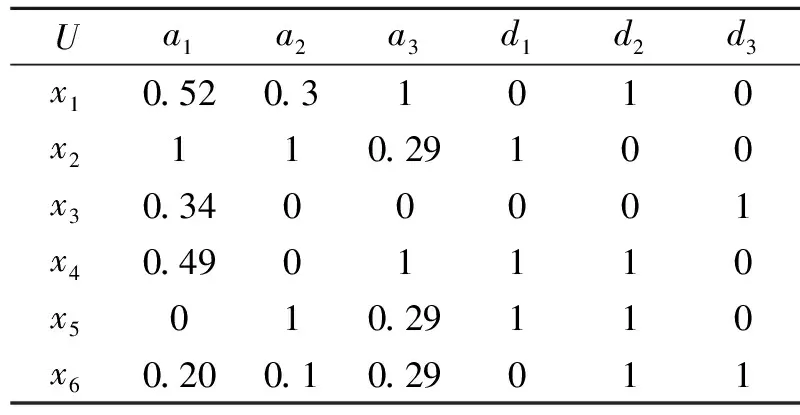
表2 归一化数据Table 2 Normalized data
特征ak在样本xi、xj之间的模糊相似关系为[16]:
Rak(xi,xj)=1-|xik-xjk|
.
由定义6可得

由定义7可得
FNSa1D(U)={(x1,x1),(x1,x2),(x1,x3),(x1,x4),
(x1,x6),(x2,x1),(x2,x2),(x3,x1),
(x3,x3),(x3,x4),(x3,x5),(x3,x6),
(x4,x1),(x4,x3),(x4,x4),(x4,x5),
(x4,x6),(x5,x3),(x5,x4),(x5,x5),
(x5,x6),(x6,x1),(x6,x3),(x6,x4),
(x6,x5),(x6,x6)},
FNSa2D(U)={(x1,x1),(x1,x3),(x1,x4),(x1,x6),
(x2,x2),(x2,x5),(x3,x1),(x3,x3),
(x3,x4),(x3,x6),(x4,x1),(x4,x3),
(x4,x4),(x4,x6),(x5,x2),(x5,x5),
(x6,x1),(x6,x3),(x6,x4),(x6,x6)},
FNSa3D(U)={(x1,x1),(x1,x4),(x2,x2),(x2,x3),
(x2,x5),(x2,x6),(x3,x2),(x3,x3),
(x3,x5),(x3,x6),(x4,x1),(x4,x4),
(x5,x2),(x5,x3),(x5,x5),(x5,x6),
(x6,x2),(x6,x3),(x6,x5),(x6,x6)}.
因此
|FNSa1D(U)|=26, |FNSa2D(U)|=20, |FNSa3D(U)|=20.
定义8给定多标记模糊邻域决策系统
MFNDS=〈U,A∪D,δ〉,
∀a∈B,B⊆A,特征子集B的多标记模糊邻域相似关系定义为
其中FNSBD(U)表示特征子集B的相似样本对的集合.
性质1设MFNDS=〈U,A∪D,δ〉为一个多标记模糊邻域决策系统,∀B1⊆B2⊆A,则
FNSB1D(U)⊆FNSB2D(U).
证明根据定义8,
由B1⊆B2,可得
进而可证
FNSB1D(U)⊆FNSB2D(U).
由性质1可知,
|FNSB1D(U)|≤|FNSB2D(U)|.
上述内容从特征空间角度计算样本间的相似度.例如:例2中样本x1、x3相似,样本x1、x4也相似,但样本x1、x3间只有一个相同标记,样本x1、x4间有两个相同的标记.由于FNSaD(U)只关心样本之间是否相似,并不关心相似的程度,因此,不能准确反映特征对标记的关联程度.
接下来,在标记空间上计算样本的相似度,进而刻画特征的重要度.
定义9给定多标记模糊邻域决策系统
MFNDS=〈U,A∪D,δ〉,
∀a∈A,特征a下相似样本的一致标记对个数为:
其中,
SD(x,y)={dk|dk(x)=dk(y),∀dk∈D}
表示样本x、y之间一致的标记集合,|SD(x,y)|表示样本x和样本y之间一致标记的个数.
性质2设MFNDS=〈U,A∪D,δ〉为一个多标记模糊邻域决策系统,∀B1⊆B2⊆A,则
|FNSB1D(U)|D≤|FNSB2D(U)|D.
证明已知∀B1⊆B2⊆A,由定义9可知
由性质1可知
FNSB1D(U)⊆FNSB2D(U),
则
因此,可得
|FNSB1D(U)|D≤ |FNSB2D(U)|D.
例2在例1中,∀a∈A的相似对样本对应的相同标记对个数为:
|SD(x1,x1)|=3, |SD(x1,x2)|=1, |SD(x1,x3)|=1, |SD(x1,x4)|=2, |SD(x1,x5)|=2, |SD(x1,x6)|=2, |SD(x2,x1)|=1, |SD(x2,x2)|=3, |SD(x2,x3)|=1, |SD(x2,x4)|=2, |SD(x2,x5)|=2, |SD(x2,x6)|=0, |SD(x3,x1)|=1, |SD(x3,x2)|=1, |SD(x3,x3)|=3, |SD(x3,x4)|=0, |SD(x3,x5)|=0, |SD(x3,x6)|=2, |SD(x4,x1)|=2, |SD(x4,x2)|=2, |SD(x4,x3)|=0, |SD(x4,x4)|=3, |SD(x4,x5)|=3, |SD(x4,x6)|=1, |SD(x5,x1)|=2, |SD(x5,x2)|=2, |SD(x5,x3)|=0, |SD(x5,x4)|=3,
|SD(x5,x5)|=3, |SD(x5,x6)|=1, |SD(x6,x1)|=2, |SD(x6,x2)|=0, |SD(x6,x3)|=2, |SD(x6,x4)|=1, |SD(x6,x5)|=1, |SD(x6,x6)|=3.
由定义9可得,
|FNSa1D(U)|D=44, |FNSa2D(U)|D=38,
|FNSa3D(U)|D=34.
例1中特征a2、a3的相似样本对数都为20.因此,从特征的模糊邻域相似关系角度上看,特征a2、a3具有相同的重要性.然而,由例2可知,特征a2、a3对应的一致标记数分别为38和34.从标记的模糊邻域相似关系角度上看,特征a2比特征a3重要.
综上所述,对于多标记特征选择问题,从特征和标记两个空间刻画特征的重要度优于单纯从特征空间刻画.
定义10给定多标记模糊邻域决策系统
MFNDS=〈U,A∪D,δ〉,
对于B⊆A,标记集D关于特征子集B的依赖度为:
其中,ω表示权重参数,0≤ω≤1.
性质3设MFNDS=〈U,A∪D,δ〉为一个多标记模糊邻域决策系统,若∀B1⊆B2⊆A,则
γB1(D)≤γB2(D).
证明由定义10可知:
由性质1与性质2可知,
|FNSB1D(U)|≤|FNSB2D(U)|, |FNSB1D(U)|D≤|FNSB2D(U)|D,
所以γB1(D)≤γB2(D).
性质3表明,γB(D)关于特征集具有单调性,即增加任何新的候选特征a∈A-B到已选的特征子集B上时,对应的依赖度
γB(D)≤γB∪a(D).
因此,可基于γB(D)设计前向启发式多标记特征选择算法.
定义11设MFNDS=〈U,A∪D,δ〉为一个多标记模糊邻域决策系统,∀B⊆A,
D={d1,d2,…,dt},
∀a∈B,特征a在B中相对于D的特征重要度为:
SIG(a,B,D)=γB∪a(D)-γB(D)
.
3 多标记特征选择算法
基于定义11给出的特征重要度,运用前向贪心策略,设计基于双空间模糊邻域相似关系的多标记特征选择算法(DSFNS),具体步骤如下.
算法DSFNS
输入MFNDS=〈U,A∪D,δ〉
输出最优特征子集R
1.初始化R=Ø;
2.计算邻域半径δ;
3.for ∀aj∈Ado
4. 计算FNSajD(U);
5.End for
6.for ∀dt∈D,∀x∈U,y∈Udo
7. 计算|SD(x,y)|;
8.End for
9.for ∀as∈A-Rdo
10. 计算|FNSR∪asD(U)|,|FNSR∪asD(U)|D,
γB∪as(D)和SIG(as,B,D);
11.End for
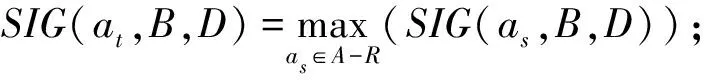
13.ifSIG(at,B,D)>0 then
14.R=R∪at,执行step 9;
15.Else
16. 执行step 18;
17.End if
18.返回最优特征子集R;
19.End.
在算法中,假设多标记模糊邻域决策系统包含n个样本、m维特征和t个标记,step 2的时间复杂度为O(nmt).step 3~step 5计算特征的相似样本个数的时间复杂度为O(n2m).step 6~step 8判断相似的样本在t个标记上是否一致的时间复杂度为O(n2t).step 9~step 18的时间复杂度为O(n2m).因此,算法提出的依赖度选择最优特征子集的时间复杂度为O(n2max(m,t)).
4 实验及结果分析
4.1 实验环境
为了评估DSFNS的有效性,本文在来自不同领域的12个多标记数据集(http://mulan.sourceforge.net/datasets.html和http://www.uco.es/kdis/mllre
sources)上进行实验.这些数据集的基本信息如表3所示,
表示标记的基数,
表示标记的密度,[dj(xi)=+1]表示样本xi中存在标签dj.当[dj(xi)=+1]满足时,[·]等价于1;否则为0[18].
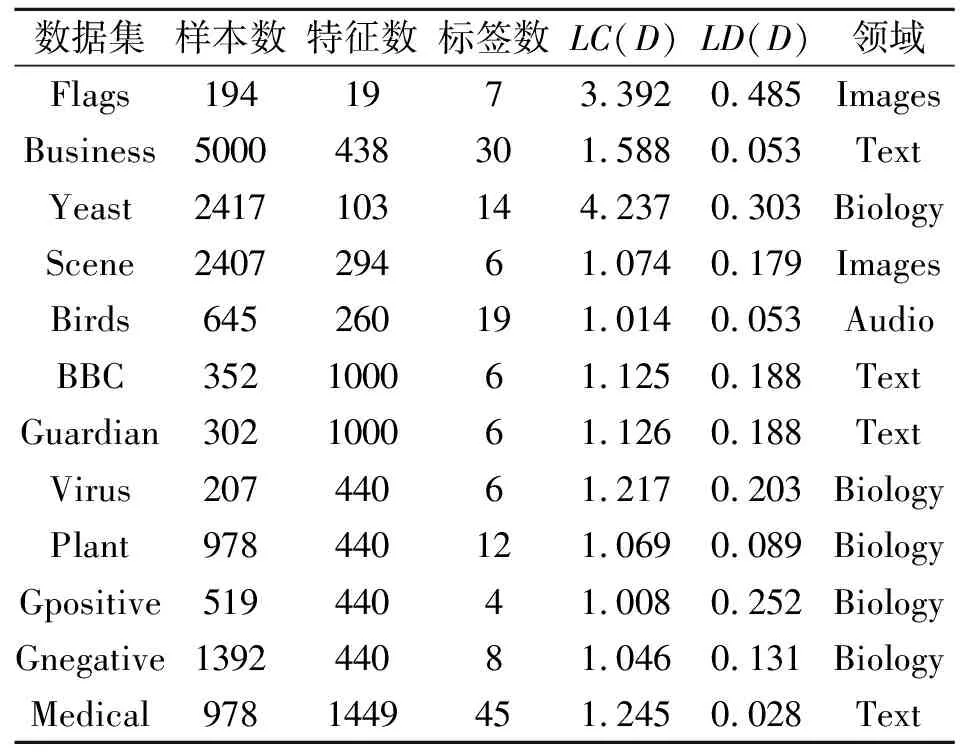
表3 多标记数据集信息Table 3 Information of multi-label datasets
本文实验均在Inter(R)Core(TM) i5-8500 CPU @3.00 GHz的处理器,16.00 GB的内存,Windows10系统及MatlabR2019a的实验平台上进行.采用ML-KNN(Multi-labelK-Nearest Neighbor)[18]和MLFE(Multi-label Learning with Feature-Induced Labeling Information Enrichment)[19]分类器验证DSFNS的分类性能,ML-KNN与MLFE中的平滑参数均设为1,最近邻K值均设为10[20].
此外,DSFNS的权重值ω设为固定值0.5,其它算法中权重的取值范围为[0,1],设定步长为0.1.通过实验选取各数据集上可使性能指标均为最优时的最佳权重值,并与其它算法进行对比[14],而本文通过选取固定值0.5作为后续实验的权重值,更能展现算法在随机选取权重值时的优越性.
实验中选取多标签分类中常用的7个评价指标,包括:平均精度(Average Precision, AP)、覆盖率(Coverage, CV)、汉明损失(Hamming Loss, HL)、1-错误率(One Error, OE)、排序损失(Rank Loss, RL)、宏平均F1(Macro-Averaging F1, MacF1)和微平均F1(Micro-Averaging F1, MicF1)[21].AP、MacF1、MicF1值越高,分类性能越优;CV、OE、RL、HL值越低,分类性能越优.
4.2 在ML-KNN分类器下的实验结果
实验选取如下6种相关的多标记特征选择算法:MDDMp(Multilabel Dimensionality Reduction via Dependence Maximization with Uncorrelated Projection Constraint)[21]、MDDMf(Multilabel Dimensionality Re-duction via Dependence Maximization with Uncorrela-ted Feature Constraint)[21]、PMU[22]、RF-ML(ReliefF for Multi-label Feature Selection)[23]、MLDFC(Multi-label Feature Selection Based on Label Distribution and Feature Complementarity)[24]、MFSFN(Multi-label Feature Selection Algorithm Based on Fuzzy Neighbor-hood Rough Sets)[25].在ML-KNN分类器上,各算法
在12个数据集上的指标值对比如表4~表8所示,表中黑体数字表示最优值,“-”表示数据缺失,无相应的对比数据.
各算法的AP值对比如表4所示.在Plant、Virus、Gnegative、BBC、Guardian、Gpositive、Yeast、Medical数据集上,DSFNS的AP值均最高.在Birds、Scene、Business数据集上,DSFNS的AP值居第二,分别仅次于MLDFC、MDDMf和PMU.在Flags数据集上,DSF-NS的AP值比最优值0.835 7下降0.005 7.
各算法的CV值对比如表5所示.除了Scene、Flags数据集以外,DSFNS在其它10个数据集上均最优.在Birds、Gnegative、BBC、Medical数据集上,DSFNS的CV值均显著低于其它算法,超过0.1,在Flags数据集上,DSFNS的CV值优于PMU和RF_ML,在Scene数据集上,DSFNS的CV值仅次于MDDMf.
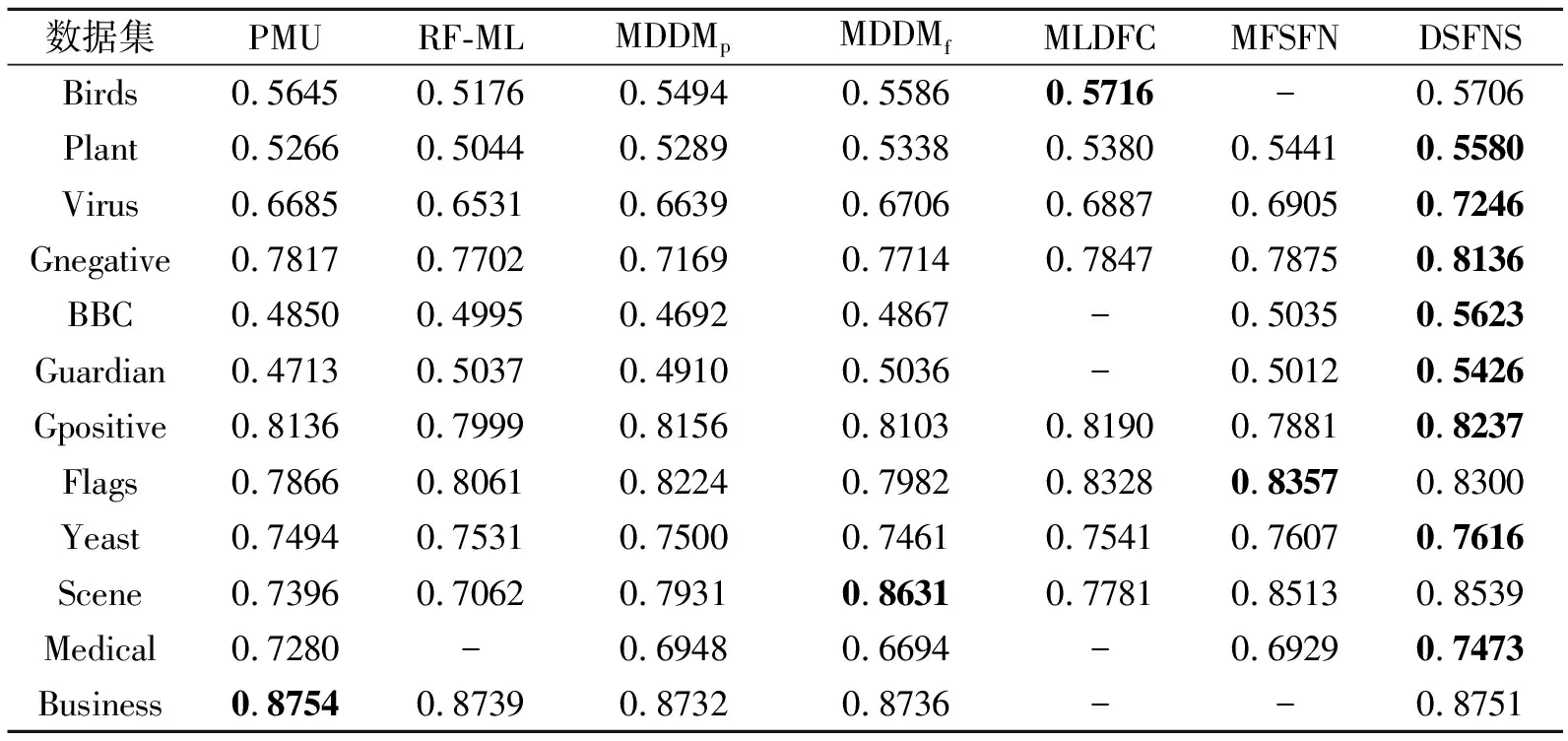
表4 各算法在12个数据集上的AP值对比Table 4 AP value comparison of different algorithms on 12 datasets
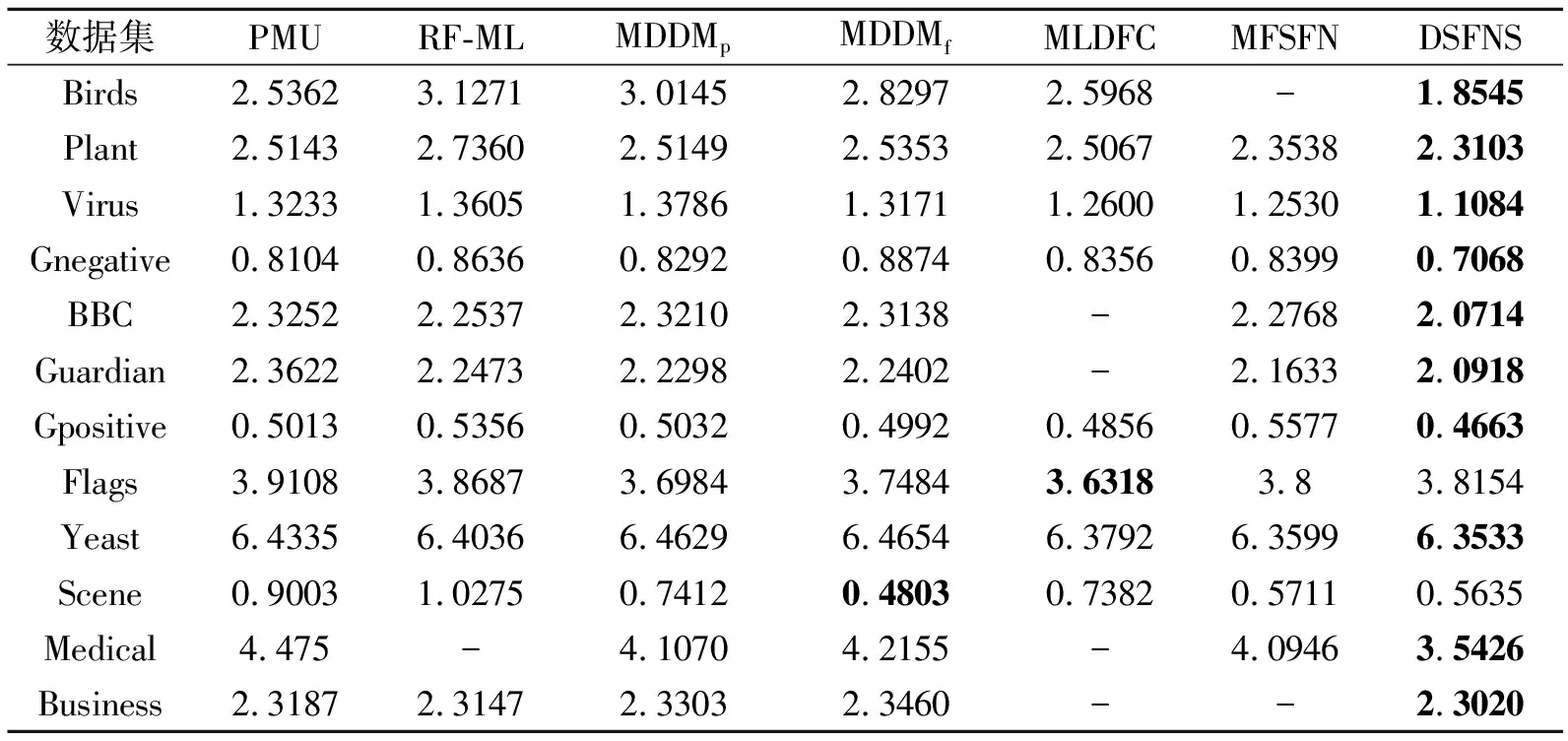
表5 各算法在12个数据集上的CV值对比Table 5 CV value comparison of different algorithms on 12 datasets

表6 各算法在12个数据集上的OE值对比Table 6 OE value comparison of different algorithms on 12 datasets

表7 各算法在12个数据集上的RL值对比Table 7 RL value comparison of different algorithms on 12 datasets
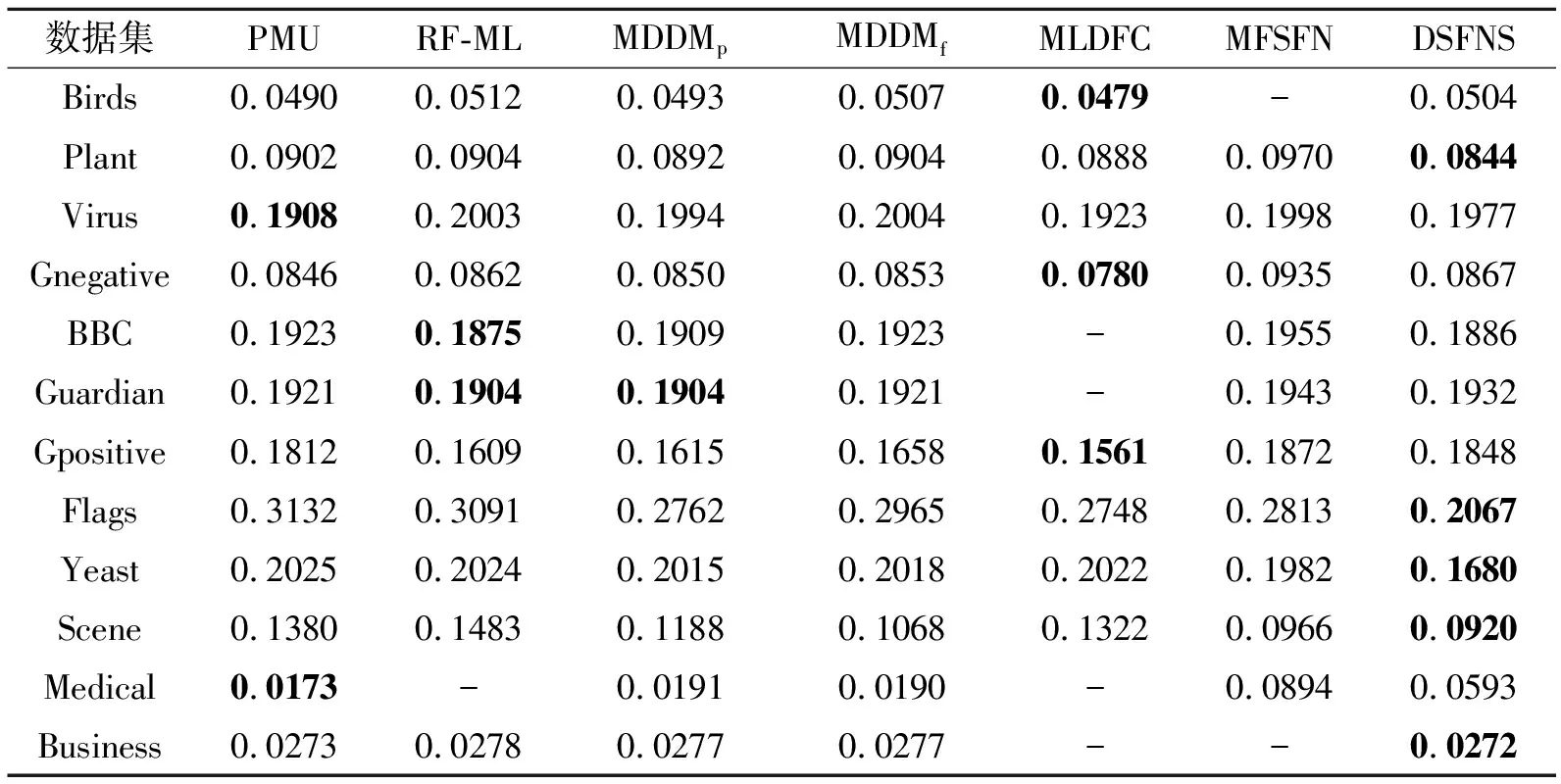
表8 各算法在12个数据集上的HL值对比Table 8 HL value comparison of different algorithms on 12 datasets
各算法的OE值对比如表6所示.DSFNS在超一半数据集上均具有显著的优势,在Birds、Virus、BBC、Guardian、Medical数据集上低于部分对比算法,超过0.1.在Scene、Business数据集上分别仅次于MDDMf和PMU.
各算法的RL值对比如表7所示.DSFNS在Plant、Virus、Gnegative、BBC、Guardian、Gpositive数据集上表现较优;在Business数据集上的RL值仅次于PMU,与RF_ML相当.
各算法的HL值对比如表8所示.在Plant、Flags、Yeast、Scene、Business数据集上,DSFNS表现最优,在BBC数据集上仅次于RF_ML,在Birds数据集上比MLDFC仅高0.002 5,在Guardian数据集上比RF_ML和MDDMp仅高出0.002 8.
综上所述,在不同的评价指标中,DSFNS都能获得较高的指标值和排名,在各评价指标中最优结果出现的频率最高,在所有数据集上的扩展能力明显优于其它算法.因此,DSFNS具有显著的有效性.
4.3 在MLFE分类器下的实验结果
本节选取如下对比算法:PCT-CHI2(Pair-wise Comparison Transformation Method Combined with Chi-square Statistics)[26]、CSFS(Convex Semi-super-vised Multi-label Feature Selection)[27]、SFUS(Sub-Feature Uncovering with Sparsity)[28]、文献[29]算法.在分类器MLFE下对比算法性能,在Yeast、Flags、Scene数据集上进行实验.
各算法的指标值对比如表9~表14所示.DSFNS的AP、macroF1、microF1值均最高,CV、OE、RL值均最低,总之,在3个数据集上,DSFNS均取得较理想的分类结果.

表9 各算法在3个数据集上的AP值对比Table 9 AP value comparison of different algorithms on 3 datasets

表10 各算法在3个数据集上的CV值对比Table 10 CV value comparison of different algorithms on 3 datasets

表11 各算法在3个数据集上的OE值对比Table 11 OE value comparison of different algorithms on 3 datasets

表12 各算法在3个数据集上的RL值对比Table 12 RL value comparison of different algorithms on 3 datasets

表13 各算法在3个数据集上的MacF1值对比Table 13 MacF1 value comparison of different algorithms on 3 datasets

表14 各算法在3个数据集上的MicF1值对比Table 14 MicF1 value comparison of different algorithms on 3 datasets
5 结 束 语
为了提高多标记模糊邻域决策系统的分类性能,本文提出基于双空间模糊邻域相似关系的多标记特征选择算法.在模糊邻域粗糙集框架下,提出自适应邻域半径,并通过模糊邻域相似矩阵计算样本间的模糊邻域相似关系,将特征和标记两个空间上所得样本相似度融合成新的度量方法,用于计算特征的重要度.本文还设计多标记特征选择算法.与以往的基于模糊邻域粗糙集的多标记特征选择算法不同,本文运用特征和标记两个空间上样本相似度之间的影响程度度量特征的重要性,全面刻画特征对标记的重要性.在12个多标记数据集上的实验结果表明本文算法的有效性.本文算法是在完备信息系统中进行特征选择,在今后的工作中,将设计针对不完备信息系统的多标记特征选择算法,并将标记分布和标记增强的因素加入到今后的特征选择方法研究中.
