面向电力行业的热词语音识别技术
2020-09-18张云翔李智诚
张云翔,李智诚
(深圳供电局有限公司,深圳 518001)
0 引言
随着智能电网的高速发展,电网业务中对语音识别的需求也在不断增加。与众多现有行业相同,电力行业有其特定的专业信息,例如:简写词汇、名字、系统名称等[1]。然而在利用面向公共领域的语音识别技术进行语音识别转化时,这些专业信息词汇很难被识别,使得电力行业语音的识别准确率不高,这也影响了电网系统中各项业务和服务的效率和成本。因此,研究面向电力行业的语音识别技术,实现针对智能电网的语音信息识别和处理是十分有必要的。
语音识别技术,又名自动语音识别(Automatic Speech Recognition,ASR),指的是将人类所述的语音信号转化为计算机可以识别读取的输入信息或是相应的文本[2]。它属于自然语言处理(NLP)的研究领域,涉及声学、语言学、模式识别及信息理论等学科[3],它的典型应用有自动语言翻译、自动客服、语音验证码和命令控制等[4]。现如今的语音识别技术主要分为三种类别,第一类是模型匹配法,矢量量化技术(VQ)[5]和动态时间规整技术(DTW)[6]均属于此类。第二类是以隐式马尔可夫模型(Hidden Markov Model,HMM)方法为代表的基于统计模型方法[7]。除此以外,高斯混合模型(Gaussian Mixture Model,GMM)也是常用的统计概率模型方法,而基于GMM 和HMM 的语音识别框架更是一度在语音识别研究中占据了主导地位[8]。随着深度神经网络的提出和发展,第三类辨别器分类方法成为了目前主流的语音识别建模方式,该类方法包括支持向量机(SVM)[9]、人工神经网络(ANN)和深度神经网络(DNN)[10]等,该类方法在大词汇量和连续语音识别技术上取得了突破性进展。2017 年,谷歌提出了用于解决NLP 中机器翻译任务的Transformer 模型,改善了RNN 训练慢的缺点,达到了SOTA 效果,使得Transformer 模型成为NLP 领域中最受欢迎的特征抽取器[11]。本文便是在利用CTC 算法将语音信息转化为基本因素信息后,再利用Transformer 模型和发音字典将基本音素信息转化为中文信息,实现针对电力行业的语音识别技术。
1 方法准备
1.1 CCTTCC算法
CTC 算法(Connectionist Temporal Classification)是一种用于时序数据分类问题的算法[12]。在传统语音识别声学模型中,需要先对数据进行反复迭代来确保语音对齐,而CTC 算法引入了空白占位符对语音信号进行分割,每个预测值都对应语音信息中的一个尖峰,因此无需对齐操作,可以直接识别语音信息。
在进行语音信号识别时,通常为利用RNN 等特征提取算法将音频信号转化为与输入维度相同的概率向量,再利用CTC 算法得到最有可能的输出结果,在此将特征提取算法与CTC 作为一个整体的声学模型算法进行描述。定义提取的语音信号特征为X={x1,x2,…,xT},经过 CTC 算法后输出的拼音音素信息为Y={y1,y2,…,yP},那么模型的目的就是通过训练数据找出输入X 与输出Y 之间的映射关系。在训练完成的声学模型中输入X 后,通过RNN 等特征提取算法得到众多条件概率输出Y,再利用CTC 算法得到一个条件概率最高的Y 值。换句话说,对于一个输出(X,Y),CTC 声学模型的目标为:
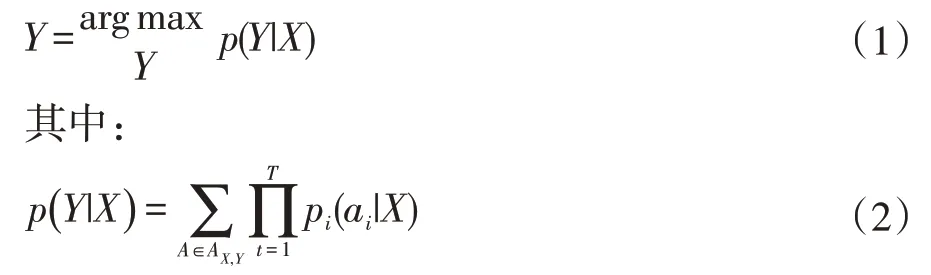
其中pi(ai|X)为RNN 等特征提取算法的输出,所有pi相乘表示一条路径中的所有字符概率相乘。
1.2 Transfoorrmmeerr模型
Transformer 模型由Self-Attention 集成,其实现了传统的RNN 结构无法实现的并行化训练、结合上下文语境等功能。Transformer 模型由编码器和解码器构成,其中编码器包含Feed Forward 层和Self-Attention层,解码器在编码器结构的基础上多一个Attention层。其注意力机制计算公式如公式(3)所示。
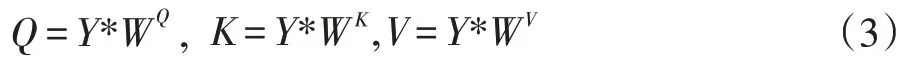
分别计算查询向量Query,键向量Key 和值向量Value,Y 为输入向量,W 为权值矩阵。

其中vQ,K表示Q 或者K 中的维度。通过Softmax归一化得到概率分布值,将其与V 相乘获得输出Y'。
2 方法构建
本节提出了一种面向电力行业的热词语音识别技术。技术模型主要分为预处理模块,CTC 声学模型模块和语音识别解码模块三部分。如图1 所示为模型的架构图。
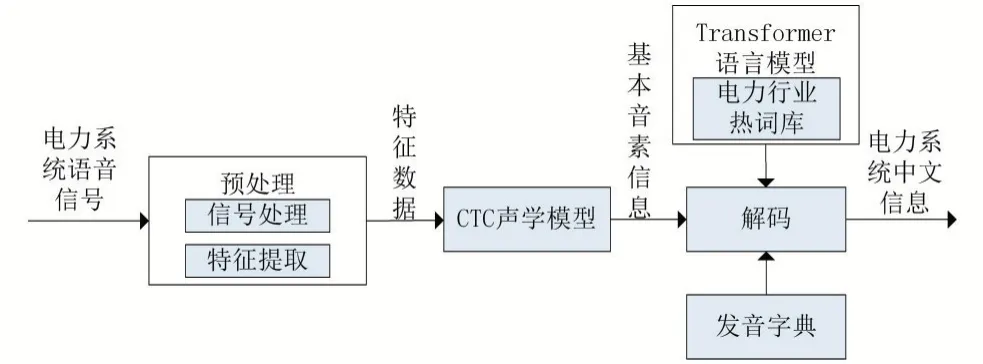
图1 面向电力行业的热词语音识别技术模型
2.1 预处理模块
由于采集的语音信号通常会含有噪声,因此模型的第一个模块为预处理模块。预处理模块主要分为信号处理与信号特征提取两部分,如图2 所示。
其中,信号处理的具体步骤如下:
(1)信号滤波:设置上下截止频率,利用带通滤波器对语音信号进行滤波处理。
(2)信号平滑:将语音信号高频与低频衔接段进行平滑处理,使信号可以在同一信噪比下下进行频谱求解。
(3)分帧加窗:设置不同长度的采集窗口,将连续的语音信号分割为频域稳定独立部分,使信号具有短时平稳特性。
(4)端点检测:通过短时能量和短时平均过零率对语音信号的起始点进行判断,进行识别。
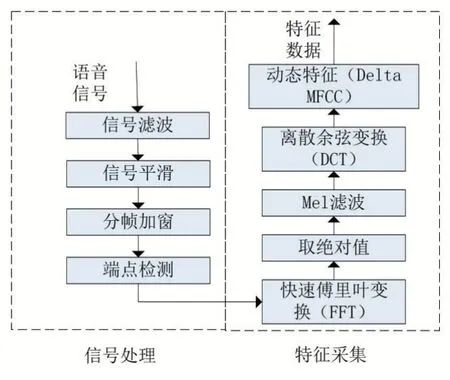
图2 信号预处理步骤图
由于直接对原始波形进行识别效果不佳,在完成语音信号的预处理后,需要将原始波形进行频域变换,再将变换之后提取的特征进行识别。本文采用梅尔频率倒谱系数(MFCC)特征参数进行特征提取。MFCC通过模拟听觉模型,先将线性频谱映射到基于听觉感知的Mel 非线性频谱中,然后转换到倒谱(Cepstrum)上,获得Mel 频率倒谱系数MFCC,MFCC 即为该帧语音的特征。
将频率转化为梅尔频率的公式为:
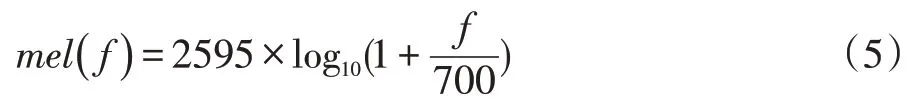
2.2 CCTTCC声学模型构建
本文采用CTC 算法来将声学信号转化为拼音信息。经过预处理模块后,得到了语音信号特征序列X={x1,x2,…,xT},其中xi表示第i 帧的语音数据经过MFCC 特征提取之后的结果。
输入:语音信号特征序列X={x1,x2,…,xT}
输出:基本因素信息Y={y1,y2,…,yP}
步骤1:建立并训练RNN 网络。
步骤2:输入X 序列,其中每一个特征xt在经过RNN 的计算之后,再经过Softmax 层得到音素的后验概率;
步骤3:前向计算从1~t 时刻,预测正确前缀概率;
步骤4:后向计算从t~T 时刻,预测正确后缀概率;
步骤5:利用前缀概率与后缀概率计算出t 时刻所有正确预测的概率;
步骤6:反向传播,最大化目标函数,即所有正确预测序列的概率和,得到条件概率最高的输出yt。
2.3 语音识别解码
要进行语音识别解码,首先需要制作发音字典。汉语含有21 个声母和35 个韵母,声韵母集合大小合适且符合汉语拼音规则,本文采用汉语声韵母作为基本因素信息,并采用汉语语音识别的主流声调方案五声调方案来标注音调变化。
其次,利用Transformer 制作语言模型。首先利用互联网文本语料库得到文本语料信息,再删除文本中的标点符号,数字和其它特殊字符,得到纯汉字文本,再利用Jieba 分词方法进行分词,之后对分词集进行词汇量、词频的统计。同时,利用电力行业的术语、工作人员名单、电网项目研究报告等资料创建电力行业文本资料库,再对其进行处理和分词,统计该分词集的词汇量、词频,最后将两个分词集的词频信息进行整合。之后,利用Transformer 建立针对电力行业数据的语言模型。
完成Transformer 语言模型和发音字典的构造之后,就可以将2.2 获得的基本因素信息Y进行解码,解码过程如下:
(1)将声学模型识别得到的基本因素信息及声学模型分数输入发音字典,得到备选词语串及声学模型分数;
(2)将上文的识别结果输入Transformer 语言模型,得到备选词语串及对应的语言模型分数;
(3)将声学模型分数与语言模型分数结合,在备选词语串中选择最优词语序列,将其作为语音识别输出。
3 实验验证
本文实验部分的数据来自于南方电网提供的基于南网信息系统语料库。其采样频率为16k 赫兹,大小为16bits。本文使用TensorFlow 构建模型。其中学习率为 0.0002,beta1=0.7,beta2=0.88。训练次数为 30次。通过与BiGRU、BiLSTM 进行对比验证模型性能。
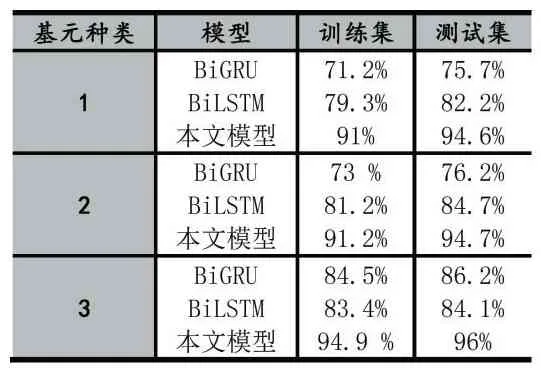
表1 实验结果
4 结语
针对面向大众领域的语音识别技术识别电力行业语音的准确率不高的问题,本文设计了一种面向电力行业的热词语音识别技术,通过构建CTC 声学模型将语音信息转化为基本音素信息,再利用电力行业热词库构建针对电力数据的Transformer 语言模型,最后通过语言模型和发音字典将基本音素信息解码为中文信息,并通过基于南网信息系统语料库的实验验证了本方法的有效性。
