稀疏诱导流形正则化凸非负矩阵分解算法
2020-06-06邱飞岳陈博文陈铁明章国道
邱飞岳,陈博文,陈铁明,章国道
(1.浙江工业大学教育科学与技术学院,浙江 杭州 310023;2.浙江工业大学计算机科学与技术学院,浙江 杭州 310023)
1 引言
在一些研究和应用领域里,经常遇到输入的数据维数过于庞大,导致计算复杂度过高和模型过拟合[1]。为了保证模型的简洁性和准确性,寻求一种尽可能简单地描述数据的方法至关重要。矩阵的乘法分解是解决这一类问题的常用方法,常见的分解方式有主成分分析(PCA,principal components analysis)、奇异值分解(SVD,singular value decomposition)、矢量量化(VQ,vector quantization)和非负矩阵分解(NMF,nonnegative matrix factorization)等。1999 年,Lee 等[2]提出了对所有元素都是非负的矩阵的乘法分解方法NMF,将数据矩阵分解为基矩阵和编码矩阵的乘积。由于得到的矩阵均为非负矩阵,即基之间只允许做加法运算,不允许做减法运算,因此,NMF 保留了数据的局部特征。同时,新的隐式表征空间的维度远小于原始空间的维度,这些特性赋予了其可以从输入的数据中学习嵌入其中的低维子空间的能力。NMF 被广泛应用于降维与特征提取领域,如网络结构检测[3-5]、高光谱解混[6-7]、人脸识别[8]和推荐系统[9]等。
流形学习认为低维子空间是镶嵌在高维特征空间中的低维流形[10],通过恢复流形结构可以学习常被传统方法所忽略的样本空间的结构信息。常见的流形学习思想有局部线性嵌入(LLE,Locally linear embedding)、拉普拉斯图(LAPE,Laplacian eigenmap)和等距特征映射(ISOMAP,isometric feature mapping)[11]等。Cai 等[12]将基于拉普拉斯图的流形正则化项引入NMF,在非负矩阵分解的过程中学习了样本空间的隐式结构信息,提出了图正则化非负矩阵分解(GNMF,graph regularized NMF)。Huang 等[13]提出RGNMF(robust GNMF),把原始数据空间表示为特征空间与噪声空间的和,在添加图结构约束的同时向噪声矩阵添加L1范数,在原始数据存在噪声和野值点时仍然有良好的稳健性。Li等[14]提出图正则化低秩非负矩阵分解(GNLMF,graph regularized non-negative low-rank matrix factorization),先对数据进行降噪处理,再进行基于流形学习的非负矩阵分解。Wu 等[15]提出MNMFL2,1(manifold NMF withL2,1norm),在GNMF 的基础上为矩阵分解的误差添加L2,1稀疏约束,提高了模型的泛化能力和对噪声的稳健性。GNMF 中流形结构(关联图)旨在表达样本之间的近邻关系,Zeng等[16]基于超图理论构建超图流形结构,提出超图正则化非负矩阵分解(HNMF,hyper-graph regularized NMF)。超图中的近邻关系不再限制顶点数量,可以将关联图结构理解为超图结构的二阶特例,超图相比关联图可以保留更多的近邻关系。多数流形学习方法预先定义图结构,在算法迭代过程中图结构保持不变,因此失去了对空间结构信息变化的敏感性。为了解决这个问题,一些算法添加了动态图约束,以在迭代过程中保证图结构对目标空间的持续影响力。Wang 等[17]提出RALSE(robust adaptive low-rank and sparse embedding for feature representation)框架,集合了矩阵的稀疏低秩表示与添加了L1范数的图结构,实现了特征的有效学习与空间结构的实时保留。Yi 等[18]将正交约束、近邻样本间稀疏表示关系相结合,提出了带有局部关系保持约束的动态图结构的非负矩阵分解(NMFLCAG,NMF with locality constrained adaptive graph)。Lu 等[19]将局部线性嵌入模型与稀疏的动态图约束结合,在动态学习结构信息的同时保证了相似度矩阵的稀疏性。Yin 等[20]通过学习自适应的低秩图亲和矩阵来进行子空间聚类,其中图正则化项的各项参数不再预先指定,而是在更新过程中自适应更新。
NMF 和GNMF 都只适用于非负约束下的矩阵分解,即输入数据不允许出现负值,不能满足实际应用场景的需求。为了解决这个问题,Ding 等[21]提出了凸非负矩阵分解(CNMF,convex NMF),将NMF 适用范围从非负矩阵扩大至混合符合矩阵。Wang 等[22]在矩阵分解的基础上对非负基矩阵引入正交约束,提出基于矩阵分解的特征提取算法(MFFS,feature selection via matrix factorization)。一些方法将混合符号矩阵分解与流形正则化相结合,如Hu 等[23]提出带有流形正则化项的凸非负矩阵分解(GCNMF,CNMF with manifold regularization),聚类实验表明,其相较于没有学习数据空间结构信息的方法有很大的性能提升。Cui 等[24]将子空间学习与凸非负矩阵分解相结合提出SCCNMF(subspace clustering guided convex NMF),利用样本间的线性表示关系进行流形结构的动态保持。Li 等[25]考虑相同类标签的图像拥有类似的图像表示,在GCNMF 的基础上添加了成对约束,提出了PGCNMF(pairwise constrained graph regularized CNMF)。
传统的特征选择往往忽略了特征之间的关系,而基于稀疏约束的方法可以发掘特征间的潜在关联,同时可以增强模型的泛化能力和稳健性[26]。因此,各种稀疏化方法被引入非负矩阵分解方法。Kong 等[27]提出了L2,1-NMF,引入L2,1范数对编码矩阵做泛化处理。Hoyer 等[28]提出带有稀疏约束的非负矩阵分解(NMFSC,NMF with sparseness constraint),其对基矩阵、编码矩阵添加稀疏约束,提高了分解结果的稀疏性。张旭等[29]采用L2,1范数增强了图正则化非负矩阵分解在基因表达谱上的噪声稳健性。本文在GCNMF 的基础上引入L2,1范数,提出一种新的稀疏诱导流形正则化凸非负矩阵分解(SGCNMF,sparsity induced GCNMF)算法。该算法不仅学习了数据空间隐式流形结构信息,同时使数据矩阵不再受限于非负约束,将非负矩阵分解扩展到了混合符号矩阵分解。另外,SGCNMF 对模型进行了稀疏化处理,提高了其泛化能力和噪声稳健性。在一组图像数据集上的聚类实验结果验证了SGCNMF 的有效性。
2 相关工作
2.1 凸非负矩阵分解
NMF 将非负数据矩阵分解为2 个非负矩阵的乘积。给定一个矩阵,找到2 个非负矩阵,使
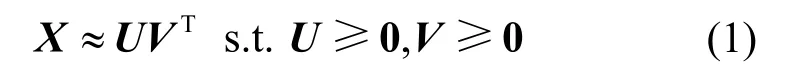
其中,U为基矩阵,V为编码矩阵。原数据矩阵与分解后矩阵乘积的误差越小,则对原始数据的拟合越好。为了最小化分解误差,Lee 等[30]提出了乘法更新规则算法。
混合符号矩阵是指含有正数、零和负数的矩阵,经典NMF 只解决含非负元素矩阵的分解问题。Ding 等[21]提出了CNMF 并证明其收敛性。与NMF将矩阵分解成2 个非负矩阵的乘积不同,CNMF 是一种矩阵的三分解方法[31],其允许数据矩阵X中出现负元素,分解为式(2)所示形式。
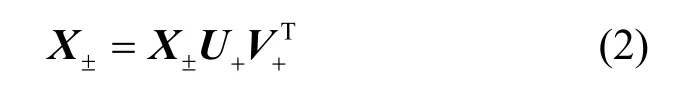
本文采用欧氏距离描述分解误差,CNMF 的代价函数O1定义为
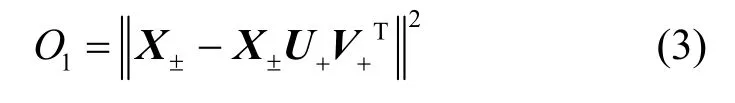
与NMF 的乘法更新规则[30]类似,CNMF 有乘法更新规则[21],如式(4)所示。
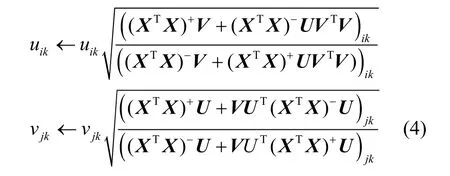
2.2 图正则化非负矩阵分解GNMF
局部不变性假设[32]认为,在高维空间里局部近邻样本映射到低维空间时对应的样本仍为近邻的。为了保持数据空间的几何结构,对于2 个原本近邻的点xi与xj,用新的基表示的两点vi和vj也应该相近。基于此,GNMF 首先构建一个邻接图G,并连接X=[x1,x2,…,xn]中近邻的点。然后,构建权重矩阵W用于量化点之间的近邻程度。构建W有3 种方式:0−1 加权、热核加权和点积加权。本文以0−1 加权为例。

为了保持vi与vj两点间的近邻关系,定义图正则化项如式(6)所示。
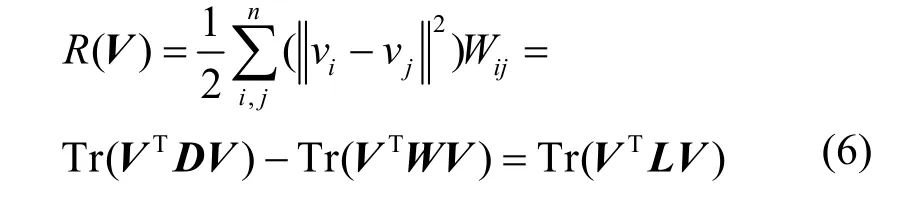
其中,Tr(•)表示矩阵的迹;D表示一个对称矩阵,其对角元素Dii为矩阵W的第i行的元素和(或者对应第i列的元素和);L为描述空间结构特征的拉普拉斯矩阵,且L=D−W。将图正则化项作为惩罚项,构建目标函数O2,如式(7)所示。
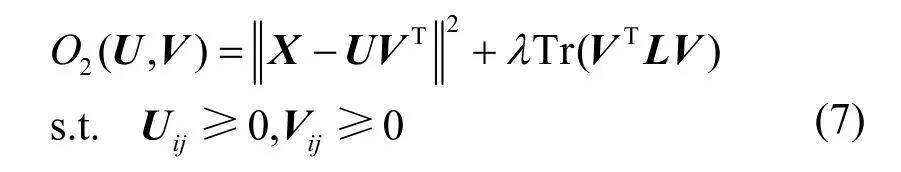
λ是非负的正则化参数,当λ=0 时GNMF 退化成NMF。使式(7)最小化,乘法更新规则为
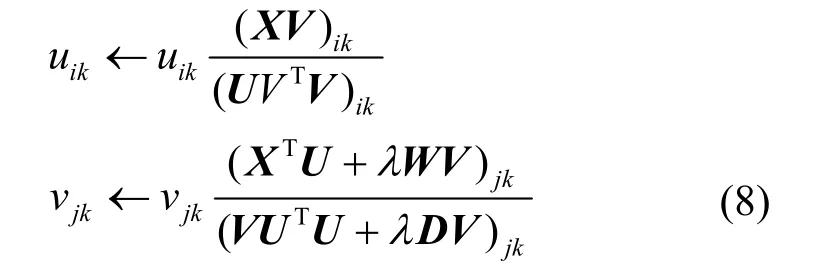
Cai 等[12]证明了在乘法更新规则式(8)下,目标函数O2可以保证收敛性。
2.3 流形正则化凸非负矩阵分解
CNMF可以看作K-means松弛编码空间的正交约束后的版本[21],CNMF 在分解过程中丢失了数据的空间结构信息。Hu 等[23]将GNMF 与CNMF 相结合,提出GCNMF,在松弛了NMF 的非负约束的同时,通过最小化流形正则化项来保留数据空间的流形结构特征。与GNMF 类似,GCNMF 构建了邻接图G、权重矩阵W和拉普拉斯矩阵L,并在代价函数O1中添加图正则化项R(V)。GCNMF 的目标函数O*为
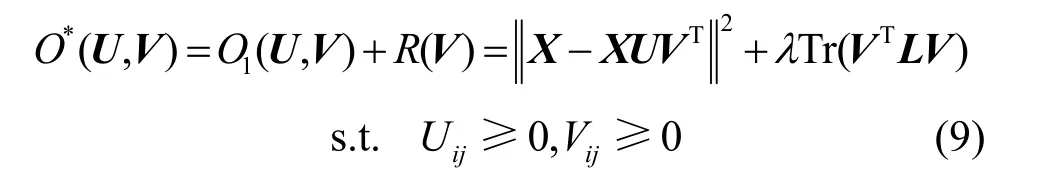
2.4 稀疏约束非负矩阵分解
基于稀疏约束的方法可以发掘特征空间的潜在关联。稀疏约束通常以对目标约束项添加Lp,q范数的形式存在,是一种常见的提高矩阵分解性能的方式。在矩阵分解中施加稀疏约束有多种方式,施加不同的约束项也有不同的侧重点[28]。例如,MNMFL2,1在全局分解误差上添加L2,1范数稀疏约束使分解误差更加平滑[15];RGNMF 向数据中的噪声添加L1范数,以提高对噪声特征的屏蔽能力[13];LMFAGR(low-rank matrix factorization with adaptive graph regularize)对局部线性嵌入的权重向量添加L1范数稀疏约束以提取更加有判别能力的特征[19]。在现有的多种范数中,L2,1范数对数据野值点的平衡更加平滑,对异常数据更加稳健,对处理噪声有良好的效果,是特征提取中常用的一种稀疏方式[33]。对于矩阵Xm×n,其L2,1范数定义如式(10)所示。
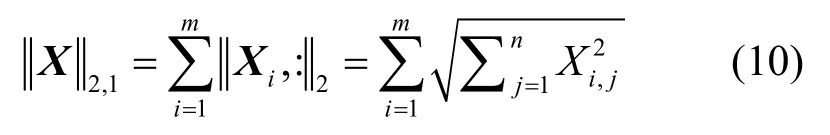
3 SGCNMF 算法描述与求解
现实中的原始数据往往夹杂着噪声,如图像中不同强度的光照、语音数据中的噪音等,这些噪声对特征学习造成了一定的干扰。在非负矩阵分解中,基矩阵是新的特征子空间的基,保留了原始特征空间中的局部特征,数据中的噪声特征同时被部分学习并保留到基矩阵中成为“噪声特征”。考虑到L2,1范数对野值点具有抑制和平衡作用,还可以提高模型的泛化能力,本文在GCNMF 的基础上引入L2,1范数,通过对基矩阵施加稀疏约束的方式,增强模型的泛化能力和抗噪声能力。
3.1 算法描述
对于非负矩阵分解,基矩阵越稀疏,局部特征的贡献度越低。式(9)中U为保留了噪声特征的基矩阵,采用基于L2,1范数的稀疏约束,提出目标函数O,如式(11)所示。
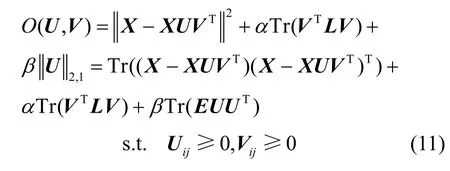
其中,α、β为正则化参数,α控制流形正则化项在矩阵分解过程中的影响力,β控制基矩阵的稀疏程度。E为对称矩阵,且其对角元素为
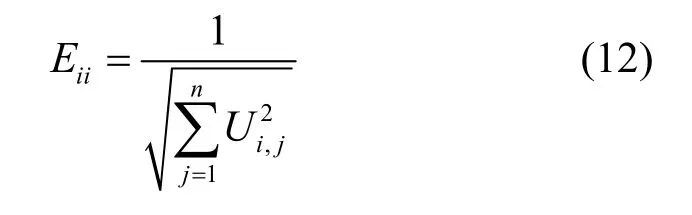
下面将讨论目标函数O的更新规则和在此规则下目标函数收敛的理论分析。
3.2 算法求解
令θik,φ jk分别为约束uik≥ 0,vjk≥ 0 下的拉格朗日乘子,构建矩阵Θ=[θik],Φ=[φ jk]。对式(11)构造拉格朗日函数G。
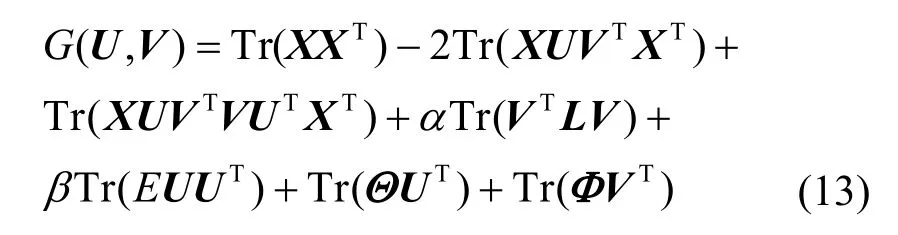
G对U、V分别求偏导并令其偏导数为0,有
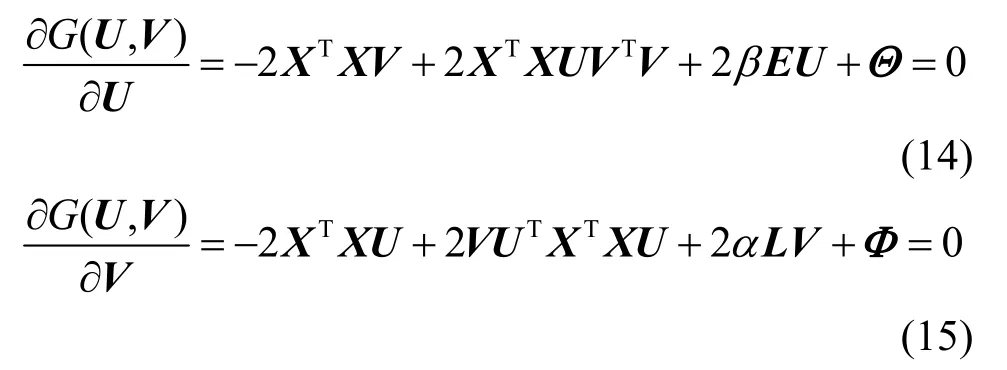
对式(14)和式(15)应用 KKT(Karush-Kuhn-Tucker)条件,即
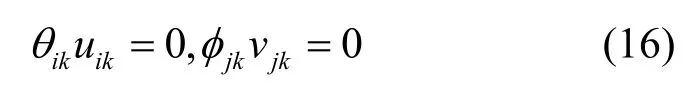
将式(16)代入式(14)和式(15)可得
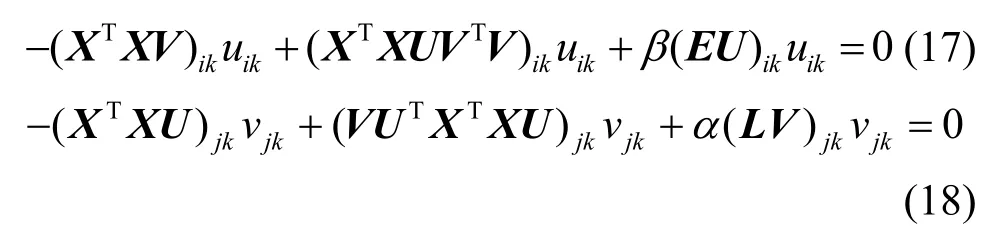
定义2 个非负矩阵(XXT)+和(XXT)−,如式(19)所示。
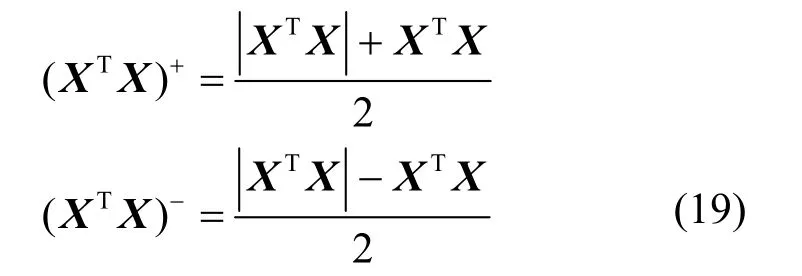
则存在式(20)所示的关系。
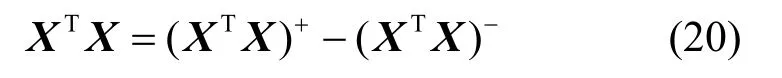
将式(20)代入式(17)和式(18),可得
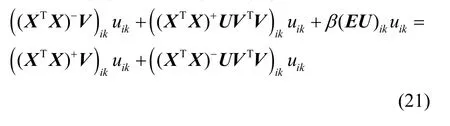
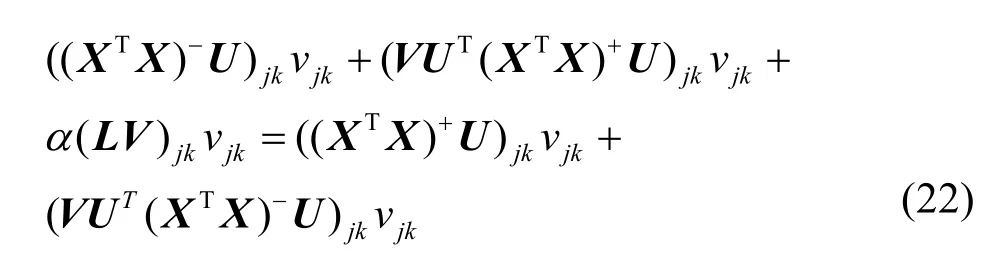
解得乘法更新规则,如式(23)所示。
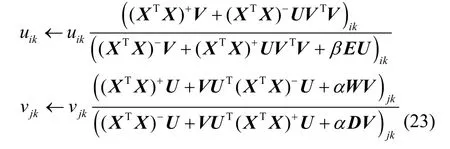
定理1式(11)所示的目标函数在式(23)所示的更新规则下是单调非增的。
证明见附录A。
在求出U、V的更新规则后,SGCNMF 如算法1 所述。
算法1稀疏诱导流形正则化凸非负矩阵分解算法
输入数据矩阵,聚类中心数k
输出低维矩阵

其中,⊗表示矩阵的哈达玛积;
6) while 目标函数式(11)收敛。
4 聚类实验及结果分析
非负矩阵分解在图像聚类上具有广泛应用,因此本节设计了图像聚类实验来测试所提算法SGCNMF 的有效性。本文对所提SGCNMF 算法与非负矩阵分解算法,即GNLMF[14]、HNMF[16]、NMFLCAG[18]、CNMF[21]、MFFS[22]、GCNMF[23]、SCCNMF[24]进行对比实验。当SGCNMF 的流形正则化项参数设为0 时,SGCNMF 退化为带有稀疏约束的凸非负矩阵分解算法(SCNMF,CNMF with sparse constraint)。为了验证流形学习和稀疏约束的效力,本文设置了一组SCNMF 对照实验,分别验证流形正则化项和稀疏约束对矩阵分解性能的影响。
4.1 数据准备
本文选取了图像聚类常用的3 个公开数据集,即Grimace 数据集、Faces95 数据集和USPS 数据集,并且设计了随机遮挡算法与Grimace 数据集和Faces95 数据集合成相应的有噪声数据集。
Grimace 数据集和Faces95 数据集是由英国埃塞克斯大学创建的面部数据库。Faces95 数据集包括72 个人、每人20 张,共1 440 幅面部图像;Grimace数据集包括18 个人、每人20 张,共360 幅面部图像。2 个数据库的每幅图像均为64 像素×64 像素,表示为一个4 096 维的列向量。数据集的所有元素为非负值。
USPS(United States postal service)数据集是美国邮政扫描快件上的手写体数据集,其中包括手写体字母和数字数据集。其手写数字数据集包括0~9 的手写体,共7 291 张训练图像和2 007 张测试图像,每张图像为16 像素×16 像素的256 灰度图[34]。本文采用其训练图像数据集,每类数字选取前 200 张图像组成聚类数据集进行聚类实验。该数据集为混合符号矩阵,同时存在正数、负数和零[23],因此不对其进行HNMF、GNLMF 和NMFLCAG 聚类实验。
4.2 噪声处理

图1 不同噪声类型示例
为了测试噪声的类型与强度对算法模型的影响,本文设置了3 种噪声类型,即黑色椒盐噪声、白色野值椒盐噪声和黑色块状噪声的对比实验。不同噪声类型如图1 所示。针对噪声强度实验,对于椒盐噪声,设置噪声强度数值组为[0.001,0.01,0.1,0.2,0.3],每个噪声强度数值代表噪声点占总元素数的比例;对于块状噪声,设置噪声宽度数值组为[2,4,6,8,10],每个噪声强度数值代表噪声块边长。具体噪声算法如算法2 所述。
算法2随机噪声算法
输入数据矩阵,噪声率ρ,噪声类型T
输出有噪声图像矩阵

4.3 性能评价指标
本实验采用2 个常用聚类评价指标,即准确度(AC,accuracy)和归一化互信息(NMI,normalized mutual information),来验证SGCNMF 的准确性和稳健性。AC 和NMI 的定义如下。
AC 用于衡量样本获得正确的类标签的比率。对给定n个样本的数据集,令其通过聚类方法获得的类标签集为L={l1,l2,…,ln},真实的类标签集为R={r1,r2,…,rn}。则该次聚类结果的AC定义为
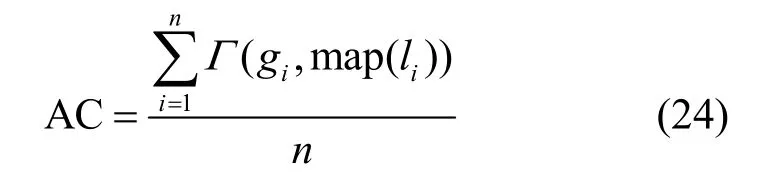
其中,map(•)表示基于Kuhn-Munkres 方法的一个最佳映射函数,它将聚类方法获得的类标签与真实的类标签做最佳匹配[35];Γ(•)是一个二值函数,当聚类标签映射后与真实标签相同时则为1,否则为0。AC 值越高则说明聚类准确度越高。
互信息(MI,mutual information)常用来度量2个聚类集合间的相似度。给定数据集的真实类别信息集合C和算法聚类出来的类别信息集合C′,则MI(C,C′)定义为
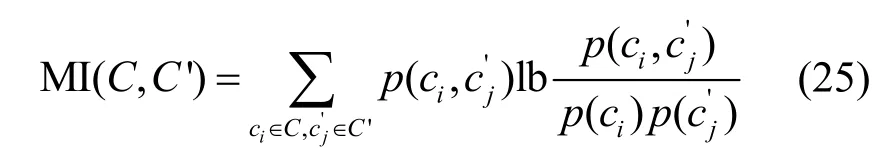
其中,p(ci)和代表从数据集中任意抽取一个样本分别属于类别ci和的概率代表抽取的样本既属于C又属于C’的联合概率。将MI 归一化后,定义NMI 为

其中,H(C)和H(C’)分别表示C和C’的熵。NMI值越接近于1,则2 个聚类结果相似度越高;反之,则相似度越低。
4.4 参数选择
SGCNMF 的2 个核心参数为流形正则化项参数α和稀疏系数β。本节在3 个数据集上进行了实验以确定α和β的取值范围。实验发现,α取值在10~102时效果良好且结果较稳定。若稀疏系数β太大,分解出来的基图像过于稀疏,图像的特征不能得到很好的保留;若稀疏系数β太小,则抗噪能力不足(β=0 时SGCNMF 退化成GCNMF)。β取值在10~103时效果良好且结果较稳定。实验选择流形正则化参数α为10,稀疏系数β为100。
经实验测试发现,各个算法在迭代50 次以内已基本收敛,因此将聚类实验中每次迭代的次数设为100 次,收敛情况详见4.6 节收敛性分析。
4.5 聚类实验
对每个数据集都均匀地选取了多个聚类中心进行聚类实验。为了消除实验结果的随机性,设计实验过程如算法3 所述。
算法3聚类实验算法
输入数据矩阵V,待测试聚类中心数K
输出各算法在数据集上聚类结果的平均值和标准差
1) 从数据集中随机选择K类数据,并选取K值作为编码矩阵的聚类数(进行噪声类型、强度对算法性能的影响实验时,K值固定为数据集最大样本类别数);
2) 对于给定的K值,运行相应的算法获取低维的特征空间;
3) 在新的低维空间上执行20 次随机初始化K个聚类中心的K-means 聚类。对聚类结果进行AC 和NMI 评估,每次运行的最佳值作为该次运行的结果;
4) 计算20 次聚类结果的平均值和标准差;
5) 重复20 次步骤1)~步骤4)并记录平均值和标准差。
对Grimace 数据集和Faces95 数据集添加噪声强度为0.2、噪声值为255 的白色野值椒盐噪声,各算法在数据集上的结果如表1~表4所示。对USPS数据集进行噪声处理,各算法的实验结果如表5~表6 所示。表1~表6 中数值都为百分数。
为了验证不同噪声类型和强度对模型性能的影响,按照算法2 所述流程对Grimace 数据集和Faces95 数据集添加3 种不同强度的噪声并进行实验,实验结果如图2 和图3 所示。
从实验结果可以得到以下结论。
1) 基于流形学习的算法在实验数据集上聚类准确度和归一化互信息均明显优于非流形学习算法,证明了特征空间的隐式结构信息在聚类应用中的重要性。
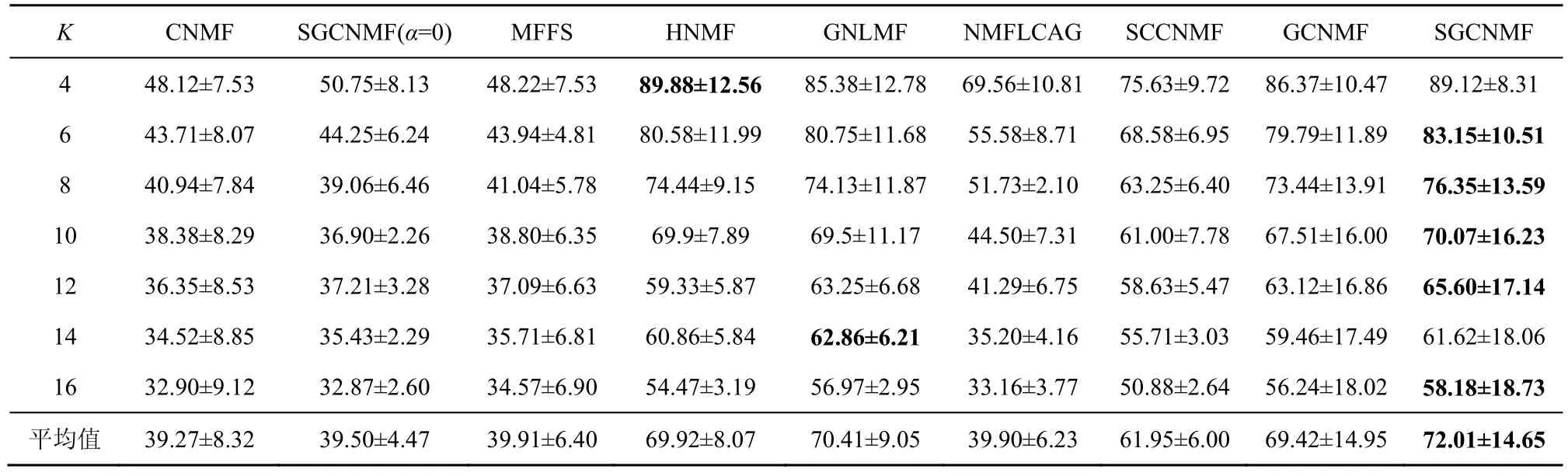
表1 聚类算法在噪声Grimace 数据集上的准确度对比
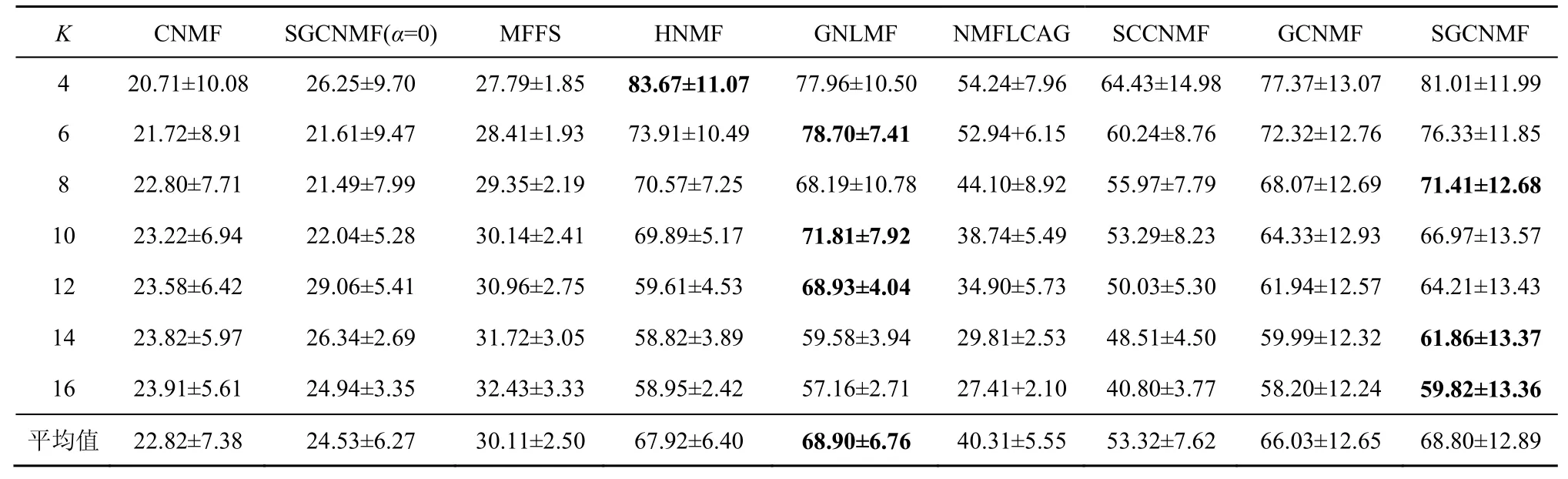
表2 聚类算法在噪声Grimace 数据集上的归一化互信息对比
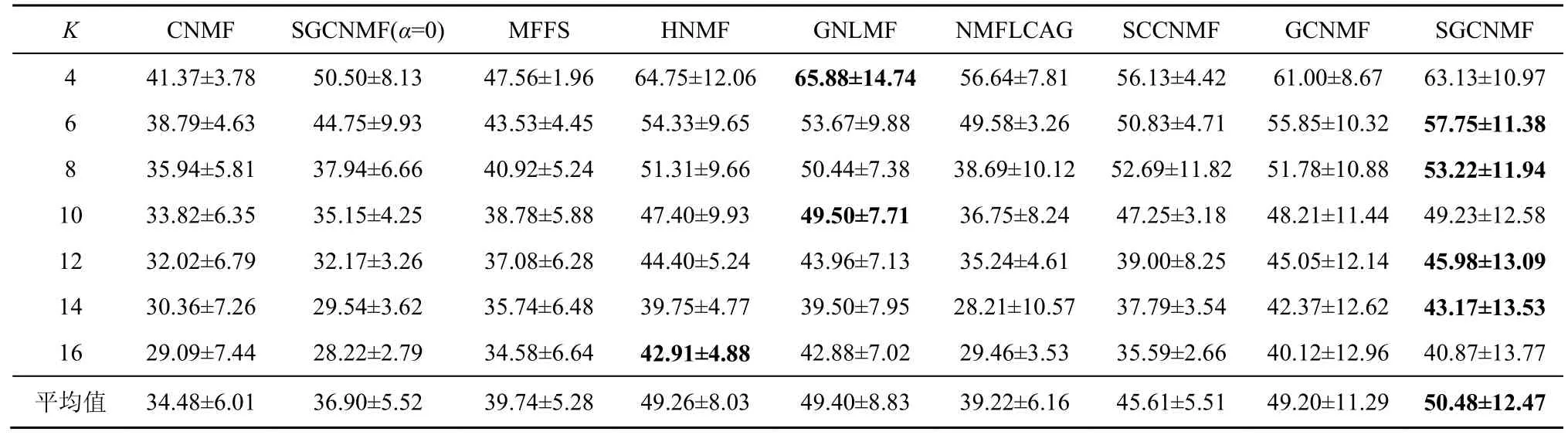
表3 聚类算法在噪声Faces95 数据集上的准确度对比
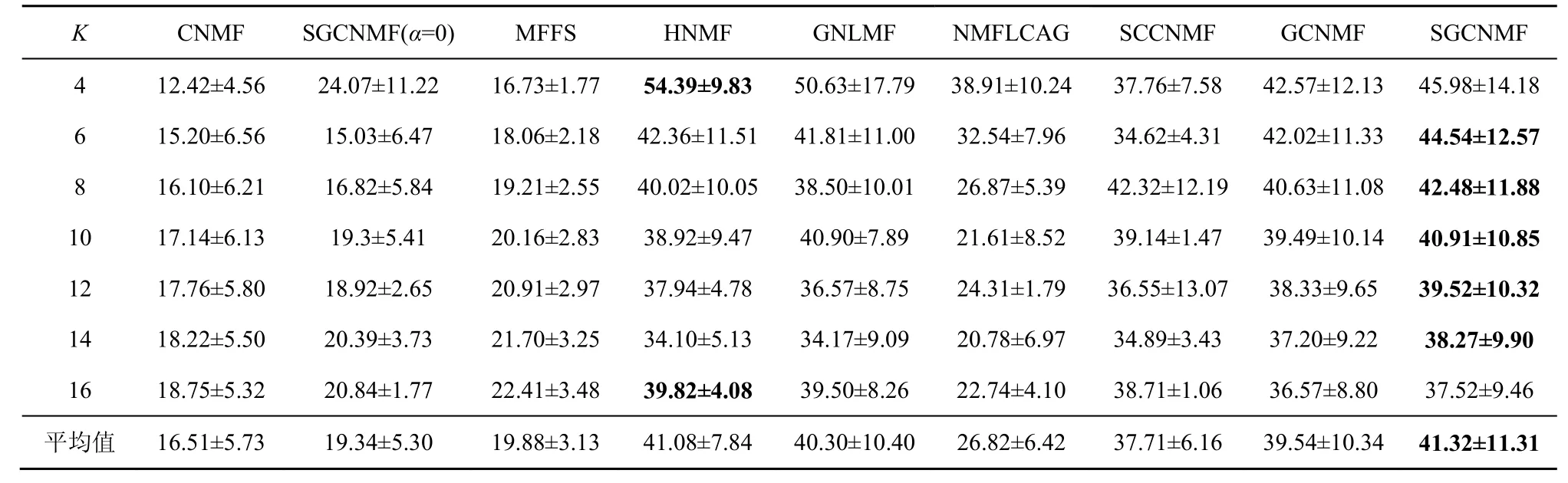
表4 聚类算法在噪声Faces95 数据集上的归一化互信息对比
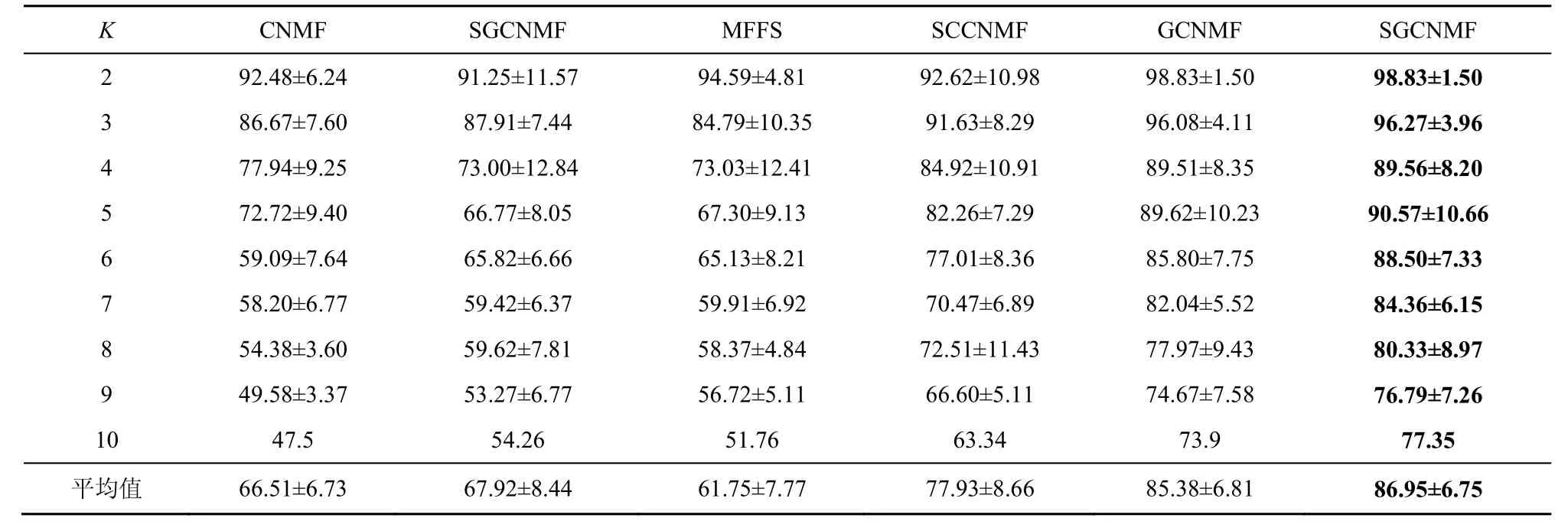
表5 聚类算法在USPS 数据集上的准确度对比
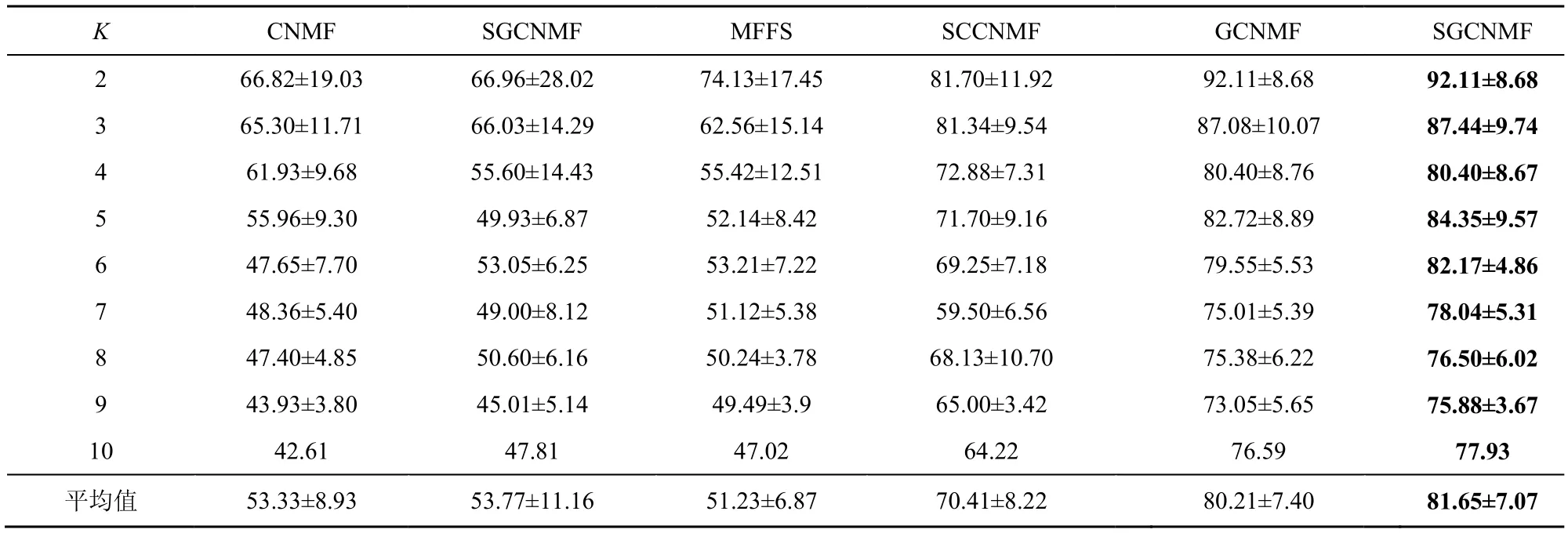
表6 聚类算法在USPS 数据集上的归一化互信息对比
2) 在不同的噪声环境下,SGCNMF 的效果均优于其他同类凸非负矩阵分解方法,证明了本文提的增加基矩阵稀疏约束的有效性。稀疏约束平滑了数据中野值点对分解结果的影响,同时使基矩阵所表达的局部特征更加稀疏,提高了模型的泛化能力。但是,在黑色椒盐噪声和黑色块状噪声中其效果往往不如GNLMF,在白色野值噪声中SGCNMF 的效果优于其他算法。证明了GNLMF的去噪算法的有效性,以及L2,1范数对数据中的野值点的平滑作用。
3) 在将SGCNMF 方法的图正则化参数设置为0 时,SGCNMF 退化为SCNMF。与CNMF 相比,SCNMF 的性能虽有一定的提升,但是不够稳定。尽管基矩阵的稀疏约束给GCNMF 带来了稳健的性能提升,聚类结果显示独立的稀疏约束还不足以改进算法的性能,需要与流形正则化项等其他约束项结合才能达到更好的效果。
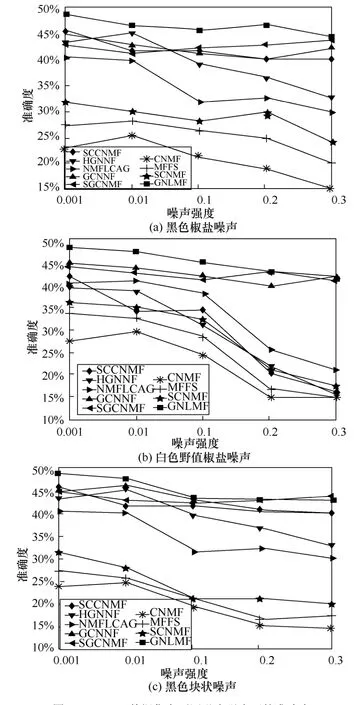
图2 Faces95 数据集在不同噪声强度下的准确度
4) 非负矩阵分解(X≈UVT)着重于非负矩阵的局部特征提取与线性加权,而 SGCNMF 拓展非负矩阵到混合符号矩阵的分解,并引入了带有噪声的数据矩阵作为分解结果的一部分,即X≈XUVT这种三分解方式,这也使SGCNMF 很难取得比HNMF 和GNLMF 明显优异的效果。但是,SGCNMF 分解混合符号矩阵的能力是这2 种方法所不具备的,因此在实际使用中也有着更大的应用范围。
5) 对于噪声类型来说,黑色噪声相较于白色野值椒盐噪声对算法的性能影响更小。这可能是由于在归一化数据后数据接近0,即黑色噪声对原始数据的改变幅度小于白色野值椒盐噪声,这意味着无论是在计算样本间距(即流形结构)还是计算分解误差时影响程度均小于白色野值椒盐噪声。
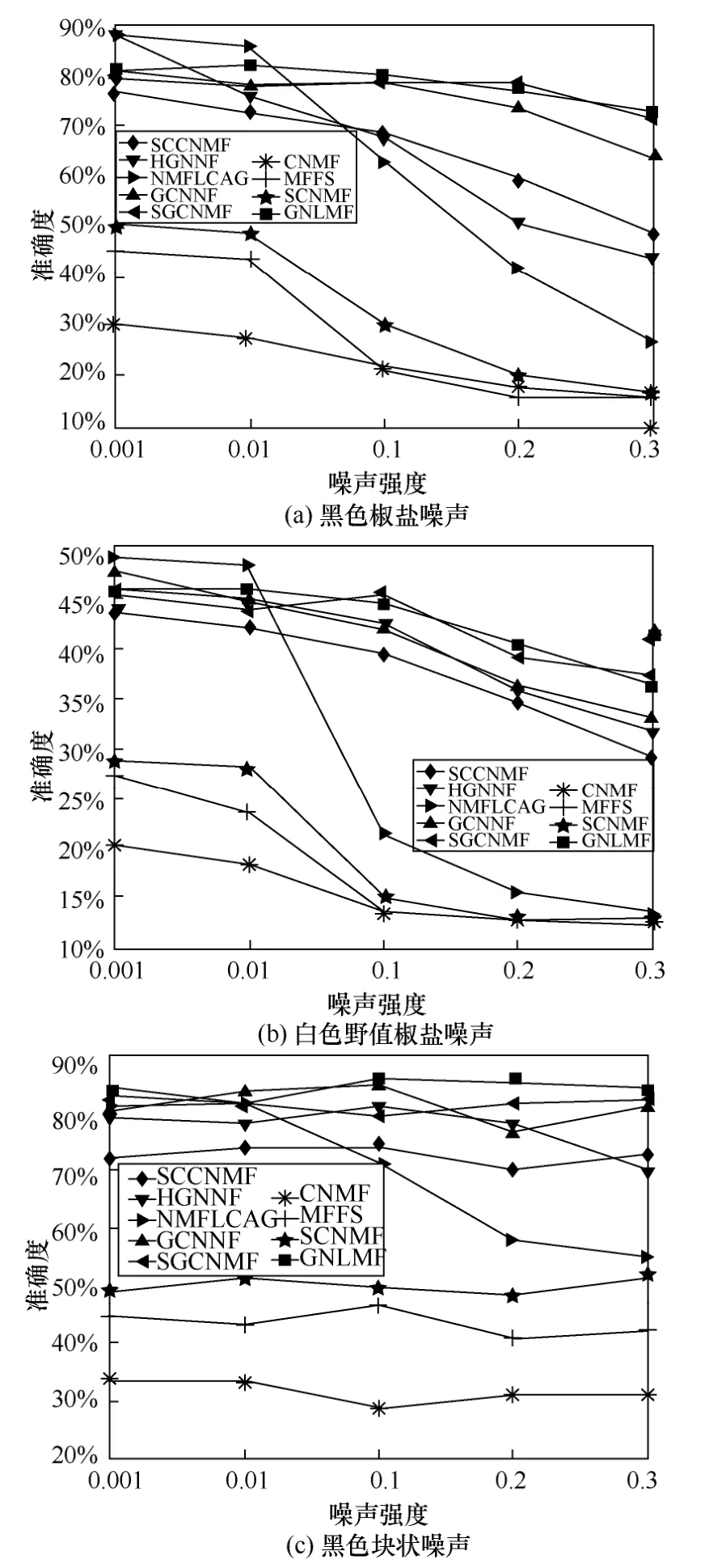
图3 Grimace 数据集在不同噪声强度下的准确度
6) 对于噪声强度来说,随着噪声强度的增加,各个方法的准确度和归一化互信息一般均有不同程度的下降,这在白色野值椒盐噪声上表现尤为明显。在噪声强度分别为0.001 和0.01 时,其效果相差往往不大,这说明了流形非负矩阵分解类方法本身就带有一定的稀疏性[23],在噪声强度过小时并不会过多影响算法的性能。随着噪声强度的增加,基于流形学习的方法相较于非流形学习方法仍然能保持较大的性能优势。值得注意的是,NMFLCAG 在低噪声环境下效果优异,但是其性能在噪声强度达到0.1 时出现大幅度下降,远低于其他流形学习算法,这意味着该方法的动态图结构对噪声的稳健性不够强。
4.6 收敛性分析
本文在附录A 给出在式(23)所示的更新规则条件下,式(11)所示的目标函数式(11)的收敛性理论证明。在聚类实验过程中SGCNMF 在3 个数据集的收敛结果如图4 所示。图中纵轴表示算法的分解误差值,横轴表示迭代次数。从图4 中明显可以看出,SGCNMF在3 个数据集上都很快收敛,在迭代20 次以内就几乎逼近极限值。
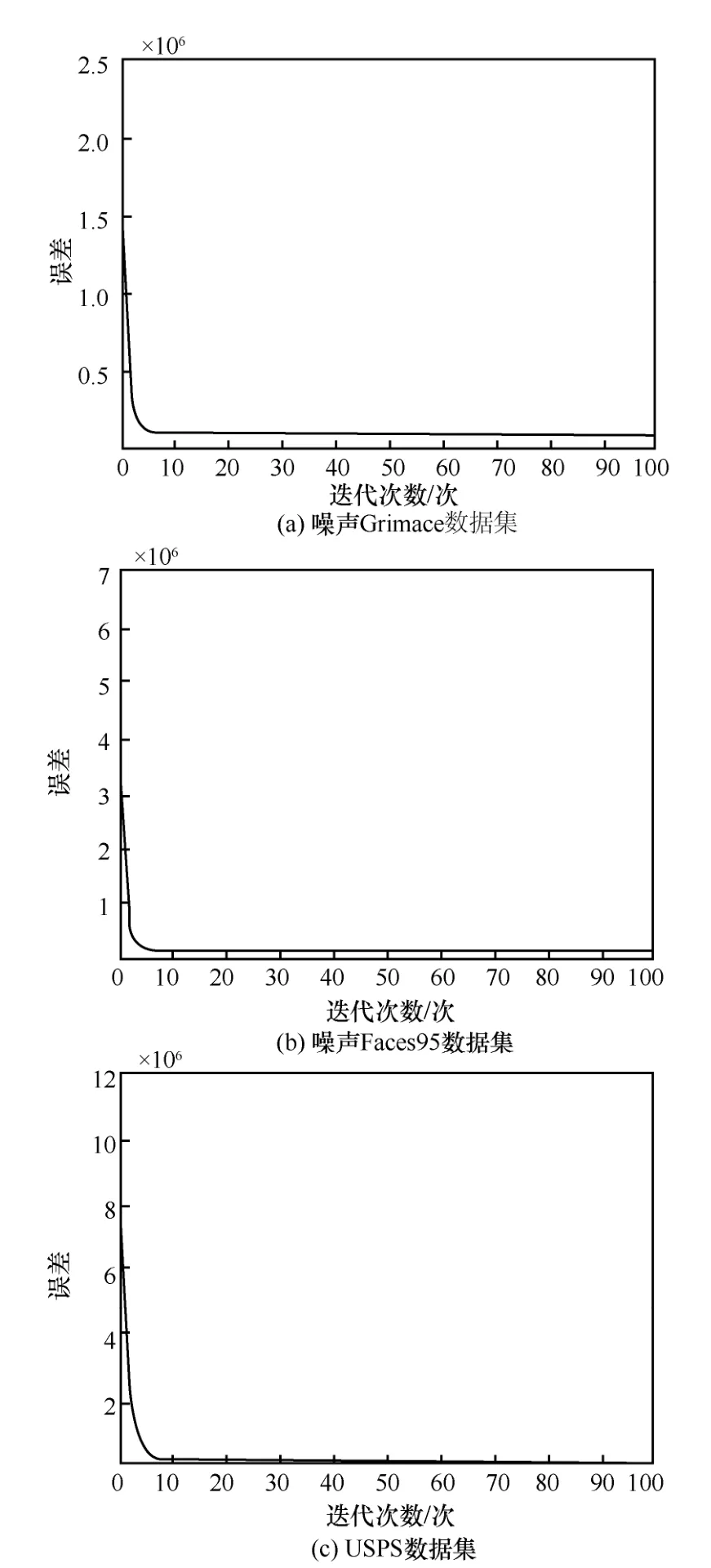
图4 SGCNMF 收敛情况
5 结束语
本文结合流形学习和凸非负矩阵分解,提出了一种稀疏诱导的流形正则化的凸非负矩阵分解算法SGCNMF。所提算法在松弛非负矩阵分解的非负约束的同时,通过流形学习,保留了数据空间的结构特征,向基矩阵添加了稀疏约束,给出了乘法更新规则,证明了在该规则下目标函数的收敛性,增强了算法的聚类准确性和对噪声的稳健性。实验结果表明,添加了基矩阵稀疏约束的流形正则化凸非负矩阵分解在聚类问题上,与没有稀疏约束的方法相比聚类准确度得到了提升,并且在数据存在大量噪声时具有更强的抗干扰性。
附录A 定理1 的证明
目标函数O(如式(11)所示)在U,V上并不同时具有凸的性质,但固定一个变量,求解另一个变量时目标函数是收敛的。下面证明目标函数O在式(23)所示的乘法更新规则的收敛性。
定义1当Q(u,u’)满足下列2 个性质时,定义Q为函数T的辅助函数,具有以下性质。
1)Q(u,u’) ≥T(u)
2)Q(u,u’)=T(u)
引理1如果Q是T的辅助函数,则T在式(27)约束条件下迭代时,值不会增大。
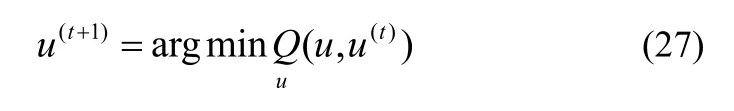
证明在约束条件式(27)下,第t次迭代时Q(u(t+1),u(t))取得最小值,即
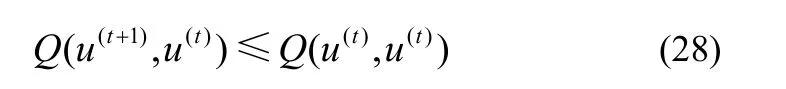
由定义1 中辅助函数的性质1)可得到
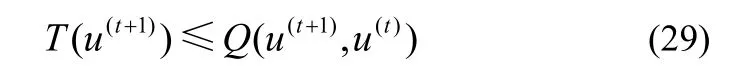
联立辅助函数的性质2)和式(28)、式(29),可得
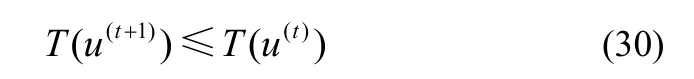
即在式(27)所示的约束条件下T是非增函数,引理1 证毕。
要证明式(11)收敛,即证明在式(23)乘法更新规则下的每一次迭代,目标函数O的值都不会增大,则在有限次迭代后,O的值一定可以取到极小值。在GCNMF 中已经说明了式(9)中O*的收敛性[23],且范数只与U相关,即只需证明在式(23)中U的迭代规则下O的值不会增大即可。
函数T表示O中仅与U相关的部分,T对U求偏导,有
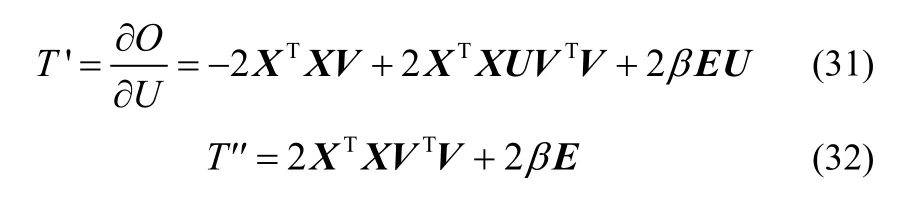
引理2函数Q(u,u(t))是仅与U相关的函数T的辅助函数,且有
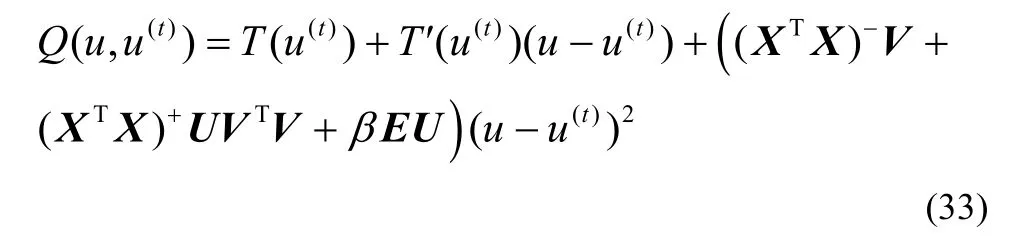
证明证明Q为T的辅助函数,即证明Q符合定义1中辅助函数的2 个性质。很明显,将u(t)=u代入Q(u,u(t)),有Q(u,u)=T(u),即再证明有Q(u,u(t)) ≥T(u),则引理2 得证。对函数T做泰勒展开,有
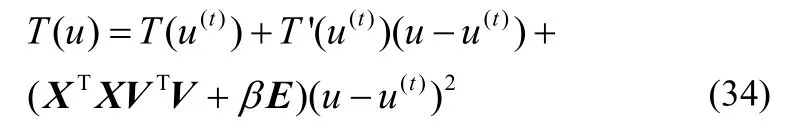
此时只需证明
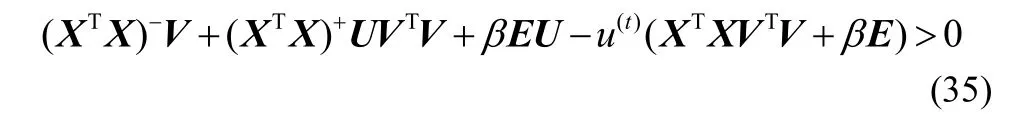
GCNMF[23]中已说明在没有稀疏项时目标函数的收敛性,即有

联立式(34)和式(36),有

引理2 证毕。
将式(33)代入式(27),则在以下更新规则下,Q是函数T的辅助函数,T是非增函数。
引理3式(11)中的目标函数O在式(23)所示更新规则下是非增的。当且仅当U和V在某一个固定点时,目标函数O在这些更新规则下是稳定的。
证明在第t次迭代时,对于给定的vt,根据引理2 和式(23)所示的更新规则,得到式(38)所示的不等式
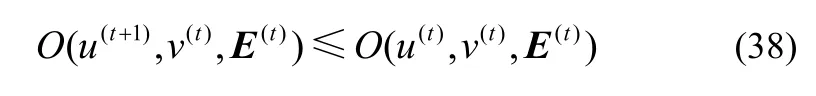
给定u(t+1),根据引理2 可得
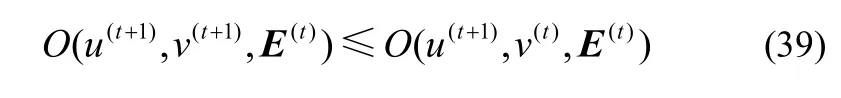
综合式(38)和式(39),可得
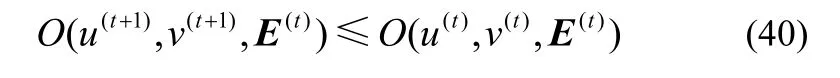
因此,有
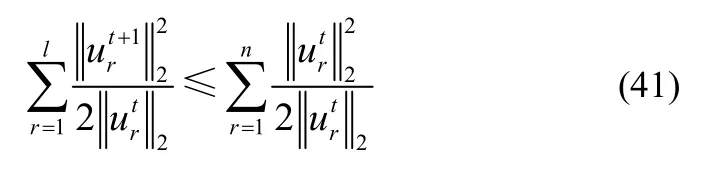
由Nie[32]中引理1,有
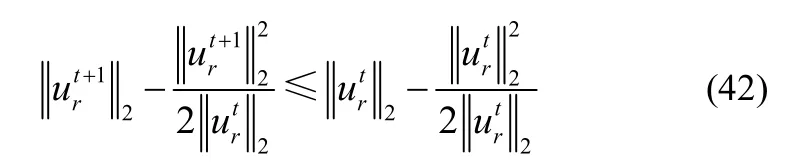
即
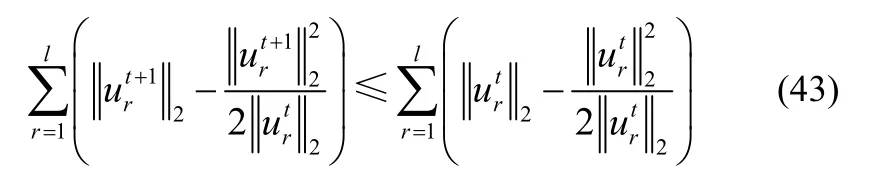
结合式(41)和式(43),可得
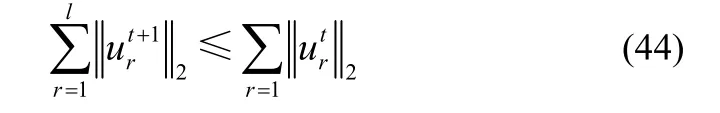
即

因此,有
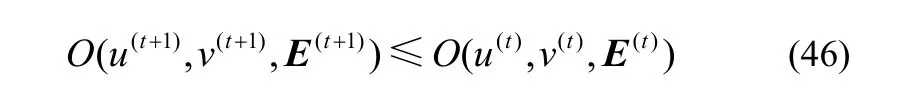
引理3 证毕。T在式(23)乘法更新准则下是非增函数。SGCNMF 收敛性证毕。
