基于机器学习的文本倾向性分析特征选择研究
2020-02-18唐琳
唐琳


摘 要:本文围绕文本倾向性分析的基本流程进行论述,主要研究了以文本情感分析技术为主的倾向性分析,以主观性文本及客观性文本识别为前提,从特征选择算法和特征加权算法方面对现有文本倾向性进行分析,介绍了算法的推导公式及模型训练代码,重点涵盖了基于机器学习的文本倾向性分析方法,对其算法复杂性、算法效率和适用范围给出了具体的概括和总结.
关键词:机器学习;文本倾向性;特征选择;特征加权
中图分类号:TP391 文献标识码:A 文章编号:1673-260X(2020)01-0036-03
作者在之前发表的《微信订阅号文本采集及预处理关键技术研究》一文中,详细介绍了微信的使用情况,其订阅号中的文章数量更是浩如烟海,如果仅仅凭借人工途径来获取文章作者的观点是十分不切实际的事情,因此文本倾向性分析的提出,作为文本智能化理解的一种高效手段和方法,有效解决了文本意见挖掘这一难题.文本倾向性分析,正是在主题挖掘的基础上,对文章中作者所表达出的观点、意见、情感甚至态度进行提取,通过分析得知当前的舆论导向,从而作为舆情处理的可靠依据.
文本经过前期分词、去停用词等预处理后,正式进入了倾向性分析环节,作为自然语言处理领域的研究热点,国内外许多学者都对文本倾向性分析进行了系统深入地研究和探索,而文本倾向性分析的同义词或者别称又是五花八门,令人眼花缭乱,比如:意见挖掘、情感分析、舆情分析等等.虽然名称很多,但是其技术的发展主要经历了三个过程,分别是:基于简单统计的文本倾向性分析方法、基于机器学习的文本倾向性分析方法和基于相关性分析的文本倾向性分析方法.基于简单统计的倾向分析由于实现简单、有一定的准确度,在倾向性研究初期称霸一时;基于相关性的文本倾向分析,首先要求算法能够实现特征判断,遴选出有倾向判断的特征级别,特征倾向分析与句子倾向分析和文章倾向分析相比,难度更大,但实用性更高,同时它对自然语言处理技术水平依赖较大,现有方法主要通过信息结构化抽取和语义分析标注等来实现.[1]
文本倾向性分析同时涉及自然语言处理、信息检索和抽取、机器学习、统计学、人工智能等多个领域,所涉学科比较广泛,我们课题组结合自身专业,主要从机器学习和人工智能角度入手,对文本进行倾向性分析.基于机器学习的文本倾向性分析方法相较简单统计法和相关性分析法而言,既弥补了简单统计的粗粒度分类的不够精确度的弊端,又比相关性分析在技术上容易实现,因此我们将基于机器学习的文本倾向性分析方法作为本文中进行文本倾向性分析的首选方法,这种方法可靠、可行,既可以结合机器学习、人工智能的手段和方法,又可以运用统计学、常微分方程等工具对齐进行推导演算,大大提高了分析结果的准确性,基于机器学习的文本倾向性分析流程如图1所示.
1 主观性文本与客观性文本的识别技术
网上发表的文章,一般可分为两大类,一类是客观性文本,主要是对人物事件的客观性叙述或描述,属于写实主义,不带有作者的感情色彩,比如新闻、纪实、记录等;另一类则是主观性文本,所谓主观性文本,是带有作者感情色彩来对人物事件的描写或叙述的文章,因为作者主观性差异,所表述的观点、想法乃至世界观都极具个人特性,从而导致文章带有倾向性情感,而通过网络的传播,这种情感倾向又被放大,甚至形成了新的网络舆情.因此,主观性文本是文本倾向性分析的主要对象.而如何区分主观性文本和客观性文本,则是倾向性分析所有做的第一步工作,即主客观文本分类.这种主观性文本的有效识别,可以有效缩小分析范围,提高文本分析的效率和精度,压缩了网络舆情分析的成本.
目前,最为简单的方式是通过提取形容词进行识别来判断文本是否主观性,即将文本中的句子分为主观句和客观句,含有主观句的文本,则是主观性文本.[2]
我们在这个理论的基础上,建立了情感词库,利用SimFinder工具来计算文本中句子的相似度,结合词性标注[3]構造情感训练集,按照Yu等人的方法[4]构建基于贝叶斯分类算法的多分类器,通过以上方法的实施有效避免了构造训练集时的不确定性,提高了训练集的构造质量.这里所用的分类器,主要采用了朴素贝叶斯分类算法来设计分类器,极大地增强了主观性句子提取的抗干扰能力,提高了文本分类的准确性.
对于客观性文本来说,我们不需要进行后续的文本倾向性分析流程,可以过滤掉,筛选出来,接下来我们将主要精力都放在主观性文本的倾向性分析上.
2 特征选择技术
在前期文本经过分词、去停用词等预处理之后,在主客观文本识别阶段,形成了众多的特征词,这些特征词数量非常多,非常容易造成选词维度灾难,就需要进行特征选择分析.特征选择就是将特征词集合在去除无关特征、多余特征等噪声特征后,细分成特征子集,大大降低特征分析及训练模型所需要的时间,提高了特征训练模型的精确度.
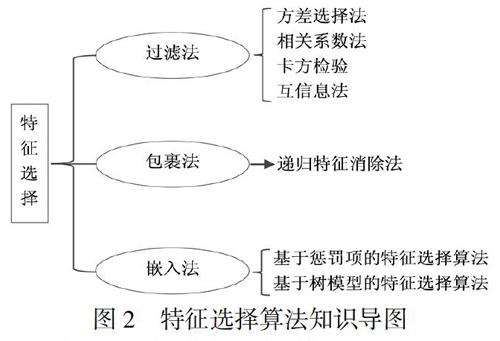
特征选择阶段去除噪声特征,压缩特征集,具有重要的现实意义,既可以减少过拟合、降低特征维度、增强模型泛化,又可以提高模型解释性,从而增强模型对特征和特征值之间的理解,加快模型的训练速度,进一步获得更优性能.然而,现实中倾向性分析系统在面对未知领域时,缺乏如何判断特征与目标之间、特征与特征之间相关性的基本认知,这就需要用到数学或工程上的方法来帮助我们更好地进行特征选择,特征选择要求其结果精确,选择算法高效普适.目前,在文本倾向性分析方面,基于机器学习的特征选择方法主要有以下几种:过滤法(Filter)、包裹法(Wrapper)、嵌入法(Embedding)等.
过滤法,顾名思义,将有效特征过滤出来的方法,首先它要依据发散性原则或相关性原则对特征集中的每个特征进行评估并打分,进而设定一个分数值作为特征阈值,或者将待选择阈值的个数作为特征标准,从而选择出适用特征;包裹法是以目标函数作为工具,每次选出或排除若干特征,直到选择出最佳的子集为止;嵌入法使用的是机器学习的算法和模型,在它们的基础上进行模型训练,经过数学推算得到各个特征的权值系数,然后再根据这一系数从大到小来选择特征,这种方法来源于过滤法,和过滤法很相似,但其二者的区别在于嵌入法是通过训练来进行特征的选取.具体特征选择算法如图2所示.
2.1 基于惩罚项的特征选择算法
这里主要使用并介绍嵌入法的基于惩罚项的特征选择算法,其结合了过滤法和包裹法的优点, 在构建模型的同时计算模型的准确率.基于惩罚项的特征选择算法是基于机器学习模型的一种方法,具体流程见图3所示,其本身就具有对特征进行打分的机制,或者很容易将其运用到特征选择任务中,主要通过正则化方法(regularization methods)来实现,所谓正则化方法,简单来说就是通过增加惩罚系数来约束模型的复杂度.
基于惩罚项的特征选择算法需要设置一个惩罚项,也就是惩罚系数,这一算法的原理是构造一个使用带惩罚系数的基模型,在基模型中筛选出特征词的同时进行了降维处理.我们选择使用Python语言的扩展库feature_selection库里的SelectFromModel类,设计出结合带L1惩罚项的逻辑回归模型,带L1惩罚项的逻辑回归模型选择特征的代码如图4所示.
选用L1惩罚项降维的原理是从多个对目标值具有同等相关性的特征中选取出一个保留下来,这样一来,没选到的特征并不代表不重要,恰恰相反,需要结合L2惩罚项来为没选到的特征进行优化.
2.2 特征加权
在基于L1惩罚项的特征选择算法流程结束后,没选到的特征需要结合L2惩罚项来进行优化,也就是进行特征加权的操作,特征加权是判断文本中特征关键性、相关性的重要评估指标,它通过计算公式为每个特征项赋予一个权值,常用的特征加權算法有布尔权重、绝对词频权重、TF-IDF权重等,我们采用TF-IDF权重算法进行加权优化.
TF-IDF权重是目前最为常用的一种权值计算方法,这里的TF是Term Frequency的缩写,意为词频,表示词组在文本中出现的频率;IDF是Inverse Document Frequency的缩写,意为逆向文件频率,表示包含特征词的文本数量,包含词条的文本越多,IDF值越小.TF-IDF权重具体算法见公式1所示,其中wik是TF-IDF权重.
wik=TFik×log■+0.01 (1)
由公式1推知,如果某个特征词条TFi在文本TFk中出现的频率较高,但是在其他文本中出现频率较低,则称该特征词条具有良好的类别区分功能,词条的wik越大.
优化具体步骤为:若一个特征在L1中的权值为1,选择在L2中权值差别不大且在L1中权值为0的特征构成同类集合,将这一集合中的特征平分L1中的权值,故需要构建一个新的逻辑回归模型,回归模型需要使用:sklearn.linear_model中的LogisticRegression类,代码为:from sklearn.linear_ model import LogisticRegression.
创建LogisticRegression类的派生类LR类,其构造方法如图5所示.
定义成员方法fit,分别训练L1逻辑回归模型和L2逻辑回归模型,代码如图6所示.
使用feature_selection库的SelectFromModel类结合带L1以及L2惩罚项的逻辑回归模型,来选择特征,具体代码如图7所示.
3 总结
在经过前期文本分词、去停用词等文本预处理之后,又对文本进行了主客观识别和特征选择加权处理,无疑,这一阶段在算法实现上遇到了一些瓶颈,幸好有sklearn这一Python第三方扩展库的存在极大地提高了进展效率,有效的完成了逻辑回归模型的设计与实现,最终成功完成了特征选择功能.
参考文献:
〔1〕厉小军,戴霖,施寒潇,黄琦.文本倾向性分析综述[J].浙江大学学报(工学版),2011,7(7).
〔2〕HATZIVASSILOGLOU V,WIEBE J M. Effects of adjective orientation and g radability on sente nce subjectivity[C]. Proceedings of the 18th Conference on Computational. USA:ACL, 2000:299-305.
〔3〕FINN A,KUSHMERICK N,SMYTH B.Genre classification and domain transfer for information filtering[C].Proceedings of the 24th BCS-IRSG European Colloquiumon Information Retrieval Research:Advances inInf ormation Retrieval.UK:Springe r, 2002: 353-362.
〔4〕YU H,HATZIVASSILOGLOU V.Towards answering opinion questions:separating facts from opinions and identifying the polarity of opinion sentences[C].Proceedings of the 2003 Conference on EMNLP.US A:ACL,2003 :129-136.
