文本分类中TF-IDF算法的改进研究
2022-07-04吴宗卓
吴宗卓
关键词:文本分类;特征选择;CHI平方统计;TFIDF;分类准确性
随着在线信息的快速发展,如何有效地处理大量文本成为一个热门的研究课题,文本分类是其中的关键任务之一。文本分类是将新文档分配给预先存在的类别,并且已广泛用于许多领域,如信息检索、电子邮件分类、垃圾邮件过滤、主题定位。
近年来,大多数研究集中在寻找新的分类算法上,对信息检索的文献表示模型的改进研究很少。传统模型有三种:向量空问模型、概率模型、推理网络模型。向量空问模型把对文本内容的处理简化为向量空间中的向量运算,并且它以空间上的相似度表达语义的相似度,直观易懂,使用最广泛。在向量空间模型中,有一些常用的加权方法,如布尔加权、频率加权、TF-IDF加权、TFC加权、LTC加权、熵加权,其中TF-IDF加权是其中使用最广泛的一种。
提出了对向量空间模型的TF-IDF加权算法的改进算法。TF-IDF考虑术语频率(TF)和逆文档频率(IDF),在这种方法中,如果术语频率高并且该术语仅出现在一小部分文档中,那么这个术语具有很好的区分能力,这种方法强调能够更多地区分不同的类,但忽略了这样一个事实,即经常出现在属于同一类的文档中的术语可以代表该特征。因此引入一个新的参数来表示类内特性,然后进行了一些实验来比较效果,结果显示这种改进具有更好的准确性。
1文本分类步骤
文本分类通常包括5个主要步骤:文档预处理、文档表示、降维、模型训练、测试和评估。
1.1文档预处理
在这一步中,需要删除html标签、稀有单词、停用词,并且需要标注一些词干,这在英语中很简单,但在中文、日语和其他一些语言中很难。通过文本预处理后,文档内部的噪音数据就被剔除。文档在内容方面就能进行分类使用了。
1.2文件表示
在进行分类之前,需要将文档转换为計算机可以识别的格式,矢量空间模型(VSM)是最常用的方法。此模型将文档作为多维向量,并将从数据集中选择的特征作为此向量的维度。其中每一个维度对应一个特征词,如果某个特征词存在于某个文档中,那它在矢量空间模型的向量中的值为非零。
1.3降维
因为在文档中,有成千上万的单词,不做处理的话就有成千上万个特征词。如果选择所有单词作为特征,那么进行分类是不可行的,因为计算机无法处理这样的数据量。因此需要选择那些最有意义和最具代表性的分类特征作为特征词,最常用的特征选择方法包括CHI平方统计、信息增益、互信息、文档频率、潜在语义分析。
1.4模型训练
这是文本分类中最重要的部分。写好改进算法的代码之后,通过从语料库中选择一部分文档以组成训练集,剩下文档作为测试集。在训练集上执行学习,然后生成模型。
1.5测试和评估
此步骤使用从步骤4生成的模型,并对得到的测试集执行分类,最后选择适当的索引进行评估。
2 TF-IDF
在向量空间模型中,TF-IDF(术语频率一逆文档频率)是一种广泛使用的加权方法,TF-IDF算法是基于这种假设的:对于最优特征词来说,这些特征词在一类或一部分文档中大量出现,而在其他文档中很少出现或者不出现。所以使用术语频率TF就可以划分相同文本。
另外,考虑一个特征词在所在文本当中的重要程度,认为一个文本中,特征词出现次数越高,特征词就越重要,因此引入了逆文档频率IDF。以术语频率TF和逆文档频率IDF的乘积作为向量空间模型的取值测度。不过在本质上IDF是避免噪音数据的一种加权手段,同时认为文本量少就重要,文本量多就不重要,这明显是有不完全正确的。所以该算法的精度并不高。
TF-IDF没有考虑不同文件长度对加权的影响,为了改进这一点,提出了TFC,它实际上是公式(1)的标准化。同时当N等于n时,a变为零,这通常出现在小数据集中。为防止计算中出现零的结果需要改进公式(1),TFC如下所示:
LTC是TF-IDF的一种不同格式,它考虑了小数据集的限制,它实际上是公式(2)的归一化。公式为:
3 TF-IDF-IF
关于TF-IDF的缺点,引入了一个新的参数来表示类内特征,称之为类频率,它计算一个类中文档中的术语频率。然后将这个新的加权方法重命名为TF-IDF-IF,其公式基于公式(2):
该方法通过引入类中文档中的术语频率,可以缓解IDF认为文本量少就重要、文本量多就不重要的问题。
4实验和分析
在实验中,选择使用常用的路透社Reuters数据集和20newsgroup数据集。在继续之前,进行一些预处理,例如删除html标签,过滤无效字符,删除停用词。在此处理之后,对于路透社,选择了6088个训练样本,2800个测试样本共59个类别。对于20newsgroup,选择8000个训练样本,2000个测试样本共20个类。然后使用CHI卡方统计特征选择方法来选择1000个特征,然后分别使用TF-IDF、TF-IDF-CF、LTC、TFC方法在一些常用的分类器如朴素贝叶斯、贝叶斯网络、KNN、SVM中进行实验。实验结束后,比较了TF-IDF-IF与TF-IDF,LTC,TFC的结果。
4.1CHI卡方统计
卡方统计是一种非常有用的文本分类特征选择方法,它可以测量特征和类之间的相关性。设N是训练样本文本总数,A是文本集中包含特征t且在类别c中的文本个数,B是文本集中包含特征t在但不属于类别c的文本个数,D是文本集中属于类别c但不包含特征t的文本个数,E是文本集中不包含特征t也不在类别c中的文本个数。卡方统计可以描述为:
当卡方统计量y2(t,c)=0时,表示特征和类别没有关系,即特征和类别相互独立。卡方统计量x2(t,c)越大表示两者关系越密切。
4.2实验
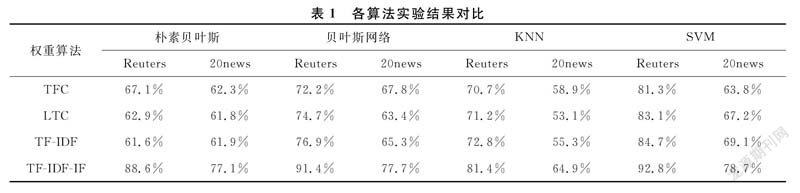
基于这两个数据集,使用CHI平方统计方法来选择1000个特征,然后使用一些常用的算法如朴素贝叶斯,贝叶斯网络,KNN,SVM在一个著名的数据挖掘工具WEKA上进行实验,只考虑比较结果时的分类准确度:
4.3分析
从表1的实验结果可以看出,改进的TF-IDF-CF加权方法在路透社Reuters和20newsgroup中具有最佳精度,与原始TF-IDF加权方法相比,精度大大提高。虽然TFC和LTC在像朴素贝叶斯这样的分类器上比TF-IDF有更好的结果,但它不像TF-IDF那样有意义,所以它们通常不用于计算加权。新方法大大提高精度的原因是TF-IDF只强调区分不同类的能力,但低估了表示类本身的能力。在一个类的文档中出现的术语越多,该术语代表该类的重要性就越大。从理论和实验中,可以看到这种改进可以达到更好的准确性。
5结论
文本分类是当前信息检索的热门研究课题,是数据挖掘和信息检索的重要分支。如何提高分类准确率是文本分类中的一个重要课题,为了解决这个问题,已经做了大量的研究来寻找能够提高准确性的新分类器,而本文试图通过提出改进TF-IDF加权方法来提高准确性。从实验中可以看出这种改进显著提高了准确性,因此认为这种改进是可以接受的。
