基于切换字典的林区小气候监测数据压缩感知方法
2019-12-06郑一力赵燕东谢辉平
郑一力 赵 玥,2 赵燕东,2 谢辉平,3
(1.北京林业大学工学院, 北京 100083; 2.城乡生态环境北京实验室, 北京 100083;3.林业装备与自动化国家林业局重点实验室, 北京 100083)
0 引言
林区小气候监测系统能够及时准确对森林生态系统进行网格化实时动态监测,依据行业标准或大数据分析结果,实现森林火情预测预警、生态环境恢复评价、森林健康评价等分析决策功能[1-3]。林区小气候监测站多采用太阳能板和蓄电池的方式进行供电[4-6]。在低温和连续阴雨时,监测站存在供电不足的问题。大多数小气候监测站直接将采集的海量原始数据通过GPRS或北斗卫星上传至云服务器中,数据传输功耗较大。如何对海量原始数据进行压缩、保留数据的有效成分、降低监测站的数据传输功耗是林区小气候监测需要解决的关键问题。
压缩感知技术提出,对稀疏信号或可压缩信号可通过远低于奈奎斯特采样频率的方式进行采样,通过算法实现原始信号的精确重构,达到数据压缩的效果[7]。压缩感知技术主要包括信号的稀疏表达、编码测量和重构算法[8]。找到最合适的稀疏字典对原始信号进行稀疏表达,是压缩感知的核心任务。稀疏字典主要分为固定字典和学习字典两类[9]。固定字典如离散傅里叶变换基(DFT)[10]、离散余弦变换基(Discrete cosine transform,DCT)[11]、小波变换基(Wavelet transform,WT)[12]和Curvelet基[13]等,具有一定的普适性,但不能根据不同原始信号的特征进行分解和稀疏表达[14]。学习字典如K-SVD字典[15]、OLM(Online learning method)算法[16],可通过训练得到稀疏基,对符合训练数据特征的原始数据拥有更好的稀疏表达能力。文献[17]采用DCT固定字典对森林火灾早期图像进行压缩;文献[18]采用DFT固定字典对植物微环境及生理参数监测节点采集的参数进行压缩,能够节省13.62%的功耗;文献[19]采用K-SVD学习字典,有效压缩了林区微环境监测站数据传输数量。上述文献均使用单一字典对数据进行压缩,无法根据数据的不同特征选择最适合的字典进行稀疏表达。针对上述问题,在数据压缩时,可以切换使用多种字典,进一步提高数据重构的精度。
本文提出一种切换字典的数据压缩方法,在对原始数据进行特征表征和分类的基础上,合理切换使用DFT或K-SVD两种字典,对林区小气候监测数据进行稀疏表达,进一步提高数据重构的精度,降低林区小气候监测站的能耗。
1 数据获取
1.1 系统组成
课题组自主研制的林区小气候监测站连接了大气、土壤、光照和植物参量传感器组,通过太阳能板和蓄电池供电[4],见图1。小气候监测站自动采集各类传感器数据,经存储和格式变换后,形成GPRS或北斗卫星短报文通讯包,发送至云服务器的MySQL数据库中。系统软件运行在云服务器上,具备实时数据查询与下载、大数据分析与决策、数据库存储和管理等功能。多个小气候监测站可组网实现对森林生态大数据的全方位获取。

图1 北京鹫峰国家森林公园小气候监测站实物图Fig.1 Picture of forest microclimate monitoring stations in Beijing Jiufeng National Forest Park
1.2 数据获取与预处理
林区小气候监测站的各个传感器每5 min自动采集一次数据,并存储在SD卡中,每个传感器每天总共采集288组数据。监测站内部的数据采集器融合了基于压缩感知的压缩算法,将传感器原始数据进行压缩,集中发送到云服务器,在云服务器上通过重构算法进行解压缩运算。
监测站在长期运行过程中存在数据错误和丢失的问题,错误数据通过设置差分阈值直接剔除。单个数据丢失率大于10%的样本直接舍弃,丢失率小于10%的样本,采用三次样条插值法将数据补齐[19]。
2 数据压缩感知方法
2.1 切换策略
林区小气候监测站采集的各种传感器的数据特征不同。土壤温度和土壤湿度等参数波动性不大,信号能量集中在低频段,采用固定字典作为稀疏基,可以较好地稀疏表达原始信号,完成对原始信号的压缩传输;空气温度和空气湿度等参数容易受到外界干扰,原始信号变化趋势较大,采用学习字典作为稀疏基,可以较好地稀疏表达细节丰富、波动性较大的样本,提高数据的压缩精度。
切换字典方法的流程如图2所示,首先进行样本的特征表征,判断样本的波动性,然后根据切换因子,合理选择不同的字典作为稀疏基,实现数据有效压缩。本文固定字典选择DFT算法,学习字典选择K-SVD算法。
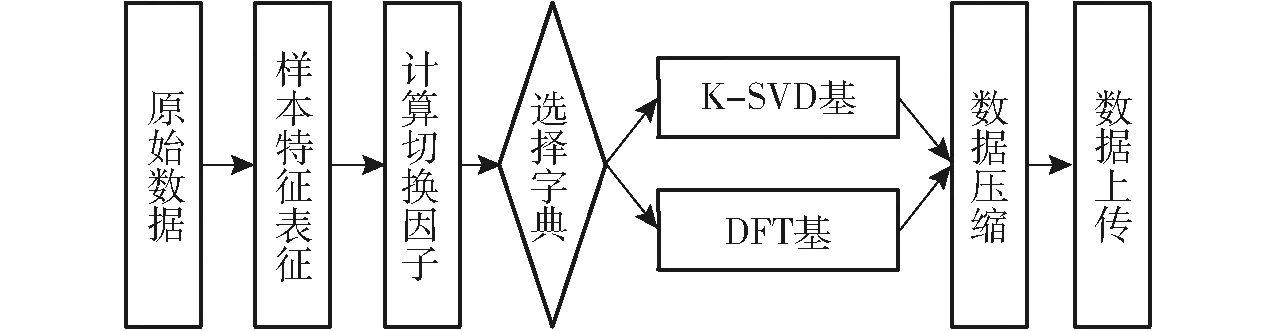
图2 切换字典流程图Fig.2 Flow chart of dictionary-toggling
2.2 样本的特征表征
图3为两个归一化处理后的传感器样本数据,图3a中的数据波动性较大,采集的数据分布较为散乱,含有丰富的细节信息,而图3b的数据较为平滑,波动性较小。
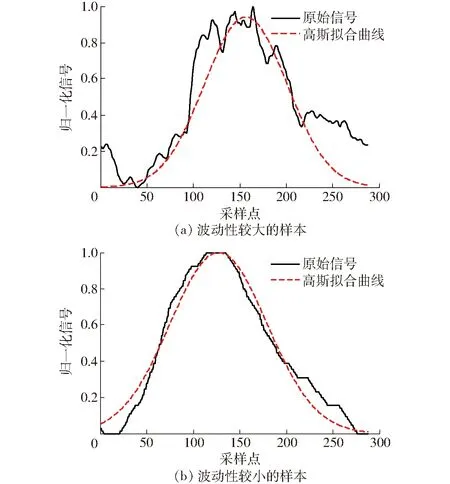
图3 不同类型样本与高斯拟合曲线Fig.3 Two types of samples and Gaussian fitting curves
两个样本数据大致符合正态分布,对样本进行拟合可采用高斯函数
(1)
式中A——高斯函数的幅值
μ——函数曲线在横坐标轴上的位置
σ——拟合的离散程度
拟合后的曲线如图3中的虚线。
为实现样本的分类,采用拟合决定系数R2和均方根误差(Root mean squared error,RMSE)2个分类标准共同判定。
当样本的波动性越大,拟合的决定系数R2越小,均方根误差(RMSE)越大,定义切换因子Q为
(2)
式中R0——决定系数阈值,R0∈[0,1]
E0——拟合标准差阈值,E0∈[0,∞)
定义固定字典为D1,学习字典为D2,根据切换字典策略,可定义切换字典D为
D=(1-Q)D1+QD2
(3)
对于波动性较小的样本,式(2)计算得到的切换因子Q等于0,代入式(3)中,可得到稀疏字典D=D1;对于波动性较大的样本,根据式(2)计算得到的切换因子Q等于1,代入式(3)得到稀疏字典D=D2。据此可根据不同数据特性,选择不同的稀疏基,达到切换字典的目的。
3 实验结果与分析
为了验证提出的切换字典策略,采用空气温度数据作为实验对象。截止至2019年3月,课题组在全国范围内采集到的空气温度数据样本共7 728个,将所有样本采用高斯函数拟合,计算其拟合决定系数R2和均方根误差(RMSE)。
式(2)中的R0和E0取人工优化筛选的经验值R0=0.8,E0=0.1,得出波动性较小的样本数为2 740个,占样本总量的35.46%,波动性较大的样本数为4 988个,占样本总量的64.54%。
对比实验中,将空气温度数据分别使用DFT字典、K-SVD字典和切换字典进行稀疏表达,采用随机高斯矩阵作为观测矩阵,使用正交匹配追踪(Orthogonal matching pursuit,OMP)算法对信号进行重构[20],将相同压缩率下的重构误差作为性能评价的标准进行比较。
3.1 DFT字典与K-SVD字典重构误差比较
从波动较小的2 740个样本中随机抽取100个检验样本,剩余的空气温度数据作为训练样本得到K-SVD学习字典。选取稀疏度K=16,定义DFT字典为Df1,通过K-SVD算法训练获取到的K-SVD字典为Dk1,将所有检验样本分别在Df1和Dk1上进行稀疏表示,经观测和重构后,计算所有重构信号与原始信号之间均方差,得到2个维度为100×1的重构误差集Ef1和Ek1,得到如图4所示的箱线图。
首先,在设计建筑的外观时,相关的设计人员可以利用色彩的组合营造出新的建筑风格,使整个建筑展现出不同的风格,利用色彩的搭配可以有更好的艺术效果,转变传统的陈旧风格和束缚,来使整个建筑变的主次分明,增加整个建筑的艺术魅力。除此之外,相关的设计人员可以采用两种不同颜色叠加搭配的方式来增强整个建筑的视觉效果,因为色彩可以带来视觉上的享受和冲击,让人们可以直观的感受到建筑物的美观性。
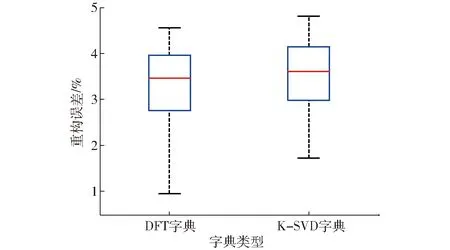
图4 波动性较小的样本集DFT和K-SVD字典的重构误差对比Fig.4 Comparison of reconstruction errors of DFT and K-SVD dictionaries for samples with low volatility
在图4中,基于DFT字典压缩的整体重构误差、极小值均小于K-SVD字典压缩的重构误差;误差集Ef1的箱体中位线在误差集Ek1的中位线的下方;Ef1的箱体1/4 和3/4分界线均低于Ek1。经统计,共有81个样本经过DFT字典压缩的重构误差小于K-SVD字典。
同理,从波动较大的4 988个样本中随机抽取100个检验样本,剩余的空气温度数据作为训练样本得到K-SVD学习字典。选取稀疏度K=16,定义DFT字典为Df2,通过K-SVD算法训练获取到的K-SVD字典为Dk2,将所有检验样本分别在Df2和Dk2上进行稀疏表示,经观测和重构后,计算所有重构信号与原始信号之间的均方差,得到2个维度为100×1的重构误差集Ef2和Ek2,得到如图5所示的箱线图。
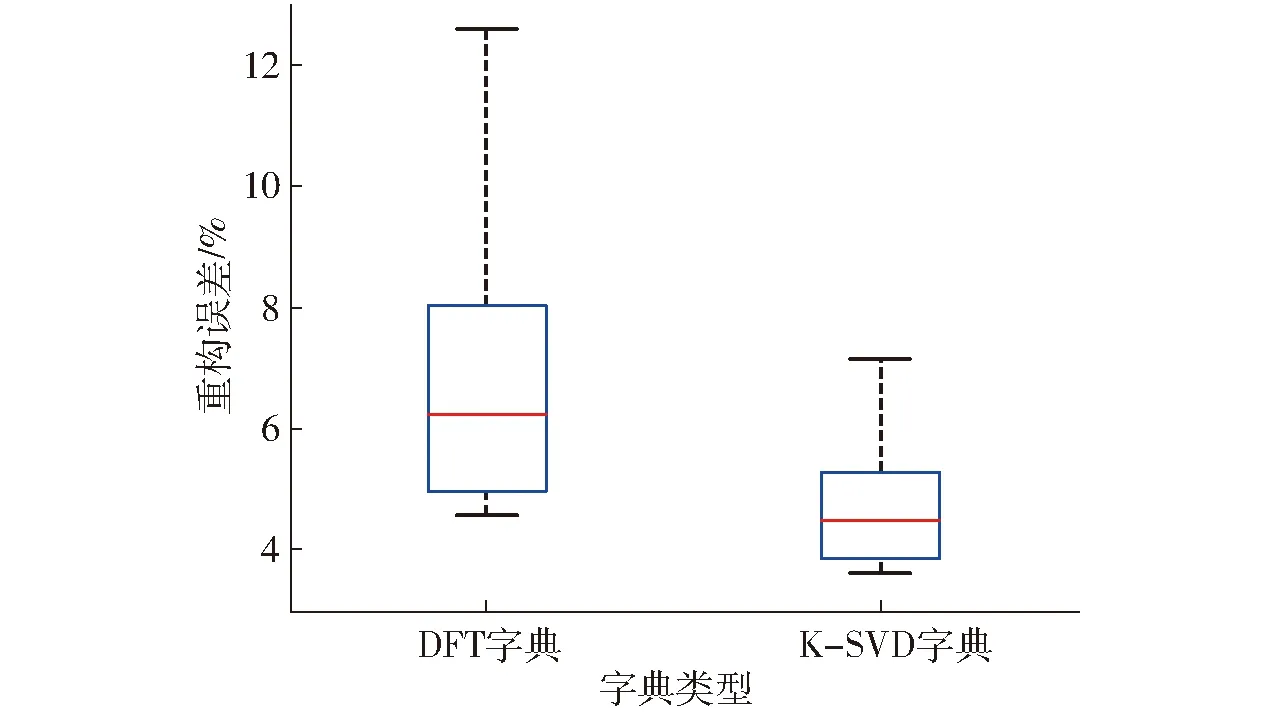
图5 波动性较大的样本集DFT和K-SVD字典的重构误差对比Fig.5 Comparison of reconstruction errors of DFT and K-SVD dictionaries for samples with high volatility
从图5中可看出:基于K-SVD字典压缩的整体重构误差、极大误差均小于DFT字典压缩的重构误差,误差集Ek2的箱体3/4分界线与Ef2的箱体1/4分界线基本持平,且Ek2的箱体中位线远远低于Ef2的箱体1/4分界线。经统计,共有83个样本经过K-SVD字典压缩的重构误差小于DFT字典。
对于不同波动性样本集的重构误差对比如表1所示。
对比表1的重构误差统计结果,对于波动性较大的样本,宜采用K-SVD字典进行压缩,对于波动性较小的样本,宜采用DFT字典进行压缩,这就为切换字典策略的提出提供了数据支撑。
3.2 相同稀疏度下切换字典与单一字典重构误差比较
从所有7 728个样本中随机抽取100个检验样本,剩余的空气温度数据作为训练样本得到K-SVD学习字典。选取稀疏度K=16,定义DFT字典为Df3,通过K-SVD算法训练获取到的K-SVD字典为Dk3,经式(2)、(3)计算得到切换字典Dt3。
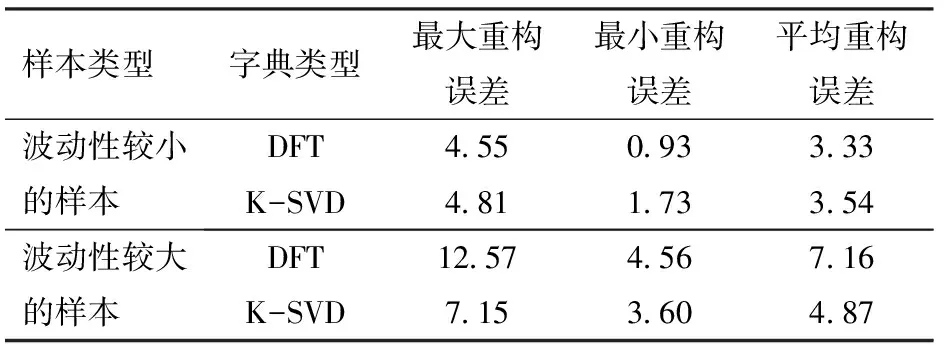
表1 DFT、K-SVD字典的重构误差对比Tab.1 Comparison of reconstruction error of DFT and K-SVD dictionaries %
将所有检验样本分别在Df3、Dk3和Dt3上进行稀疏表达,经观测和重构后,计算所有重构信号与原始信号之间的均方差,得到3个维度为100×1的重构误差集Ef3、Ek3和Et3,得到如图6所示的箱线图。

图6 DFT、K-SVD和切换字典的重构误差对比Fig.6 Comparison of reconstruction errors of DFT, K-SVD and toggling dictionaries
图6中,使用切换字典压缩的最大重构误差基本与K-SVD字典的最大重构误差持平,说明对于波动性较大的样本采用了K-SVD字典进行压缩;使用切换字典的最小重构误差与DFT字典的最小重构误差基本持平,说明对波动性较小的样本采用了DFT字典进行压缩。
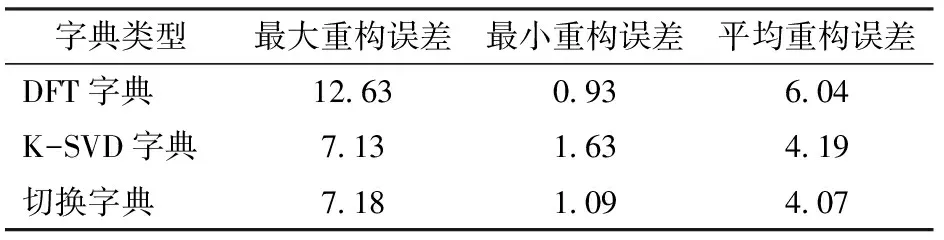
表2 DFT、K-SVD和切换字典的重构误差对比Tab.2 Comparison of reconstruction error of DFT, K-SVD and toggling dictionaries %
与K-SVD字典的最大重构误差基本一致,并且基于切换字典的最小重构误差为1.09%,与DFT字典的最小重构误差基本一致。
对比表2的重构误差统计结果,采用切换字典的压缩方法,综合了DFT和K-SVD字典的优势,能够判断全部样本数据的波动性,自动进行K-SVD和DFT字典的切换,比使用DFT或K-SVD单一字典的重构误差小。
3.3 不同稀疏度下单一字典和切换字典的压缩性能比较
采用DFT、K-SVD和切换字典对林区小气候监测站采集的空气温度、空气湿度、土壤温度和土壤湿度4个参数进行压缩,计算稀疏误差和重构误差,如表3所示。
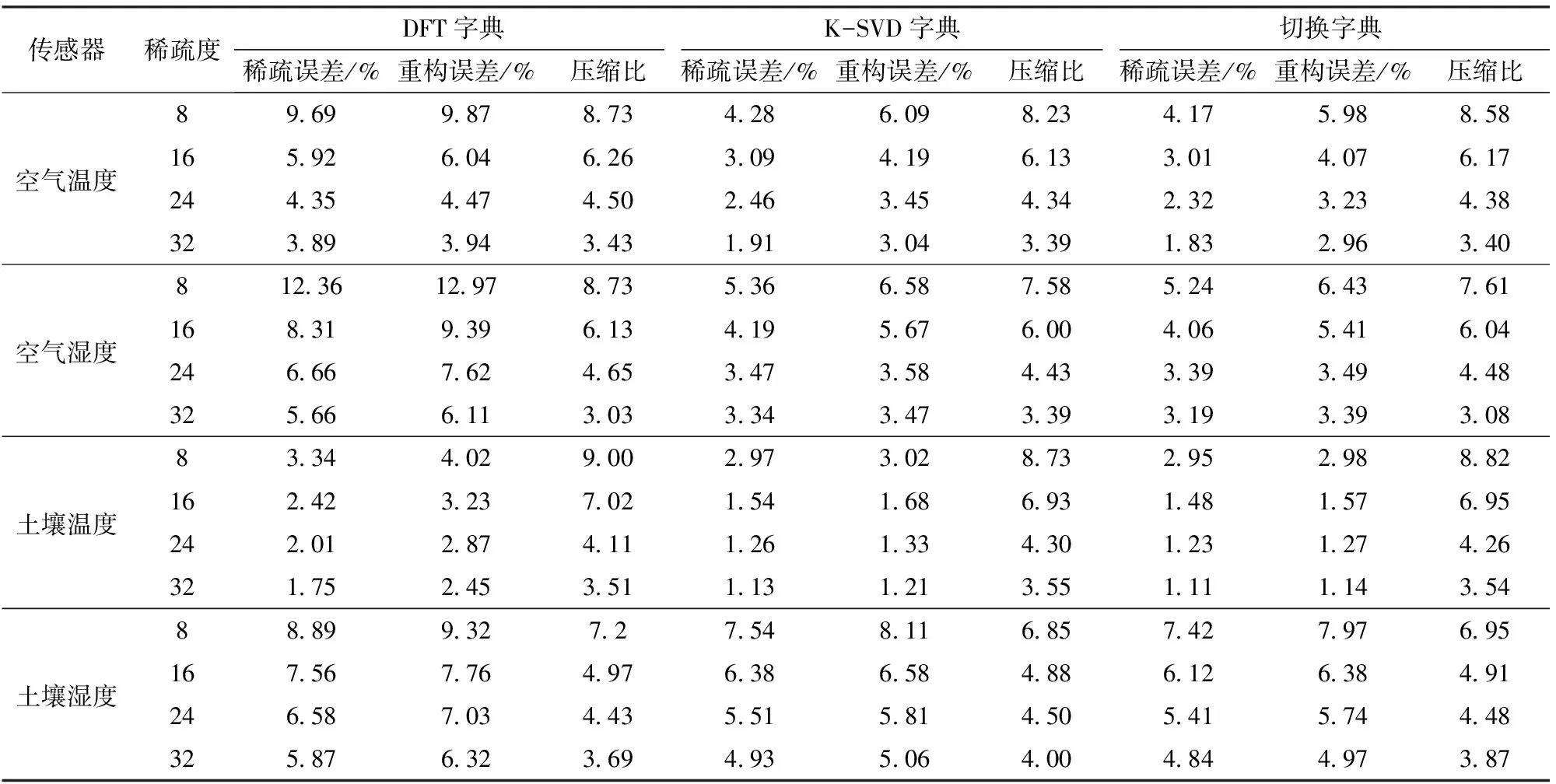
表3 不同稀疏度下DFT字典、K-SVD字典和切换字典的压缩性能Tab.3 Compression performance of DFT, K-SVD and toggling dictionaries with different sparsities
表3中,当稀疏度K逐步从8增加至32时,基于单一字典和切换字典的稀疏误差和重构误差均逐渐降低,压缩比也逐渐降低;使用切换字典进行稀疏表达的稀疏误差和重构误差均优于DFT或K-SVD单一字典。
4 功耗测试
为验证切换字典策略对降低林区小气候监测站功耗的效果,在北京市海淀区八家村北京林业大学实验基地开展测试。小气候监测站的传感器和GPRS通信模块由数据采集器供电。数据采集器中的处理器采用ATMEL公司的ATMEGA2560单片机,实现数据的采集、压缩和传输。
小气候监测站的总耗能采用PM9817D型电参数测量仪进行测量,见图7。电参数测量仪的量程为0~999 999 W·h,精度为±0.1%。在测试中,PM9817D型电参数测量仪连接小气候监测站数据采集器的总供电输入,对总耗能进行连续测量。

图7 功耗测试Fig.7 Power consumption experiment1.PM9817D型电参数测量仪 2.数据采集器 3.太阳能板 4.蓄电池箱
测试中数据采集器接收和传输空气温度、空气湿度、土壤温度、土壤湿度4个传感器的数据,每5 min采集1次,全天采集288次,共1 152个数据,选取稀疏度K=16,分别使用DFT字典、K-SVD和切换字典对原始数据进行压缩,发送给云服务器。经连续5 d测试,未压缩和经过DFT、K-SVD、切换字典压缩后每天平均能量消耗分别为20.73、17.25、17.52、17.34 W·h。
相对于未作数据压缩的监测站功耗,采用DFT字典、K-SVD字典和切换字典压缩后,监测站每天平均功耗分别降低了16.79%、15.48%和16.35%。使用切换字典的耗能介于DFT字典和K-SVD字典之间。结合表3,采用切换字典的压缩方式,在减小重构误差的前提下,有效降低了林区小气候监测站的系统功耗。
5 结论
(1)提出了基于切换字典的林区小气候监测数据压缩感知策略,切换选择最适合的字典对监测数据进行压缩,达到减小重构误差和降低系统能耗的目的。
(2)根据监测数据的不同特性,定义了切换因子,对样本进行分类,合理切换使用DFT固定字典或K-SVD学习字典,对样本数据进行稀疏表达和数据压缩。
(3)实验结果表明,结合两种字典的优势,采用切换字典对数据进行压缩,比采用单一字典进行压缩的重构误差小,林区微环境监测站功耗降低了16.35%,可有效提高林区小气候监测站的待机时间,保证低功耗运行和数据可靠传输。
