大数据下最优教学方式选取模型设计*
2018-12-05许健松游晓东
许健松, 游晓东
(福建农林大学 a. 教务处, b. 管理学院, 福州 350002)
随着大数据环境下数据质量参差不齐的情况越来越严重,对最优教学方式选取问题的研究也逐渐引起人们的关注.当对多源数据进行最优选取时,由于数据特征不同,其融合度也是存在差异的[1],从而导致最优选取过程容易出现较大偏差,且干扰因素也会对其精度产生影响,因此,寻找合理方法滤除大数据环境下的干扰数据[2],从而设计最优教学方式数据选取模型具有重要的应用价值.吕小峰等[3]提出基于蚁群算法的教学辅助系统设计与实现方法,开发出了良好的用户操作界面,因而可以提高教学质量,但由于算法较为复杂,虽在一定程度上降低了教学难度,但未考虑到学生偏好,因此,无法增强学生的自主学习能力.明道洋等[4]提出了根据学生学习效果自动推送个性化教学内容的ICAI慕课系统,主要介绍了该系统的结构,并重点阐述了神经网络算法,但对系统的整体应用性测试较少,因而无法保证系统的有效性.将本文设计的最优教学方式选取模型应用到教师最优教学方式选取中,可以利用数据挖掘技术优势选取学生偏好,增强自主学习能力,从而可以因材施教,进而提高学生成绩.因此,对教学方式的选择进行科学系统的研究是极其重要的,教学方式的选择具有重要意义.本文设计的最优教学方式数据选取模型能够有效选取最优教学方式且精度较高.
1 大数据环境下数据估计量挖掘方法
1.1 基于大数据的参数特征分析
在对数据估计量进行高效挖掘之前,需要先对大数据参数特征进行分析.选取SQL数据库中的学生相关数据,在大量差异特征数据的基础上,设整体数据估计量集合D={M,N},且M、N分别为前半段与后半段数据估计量.由于不同服务器数据特征差异较大,故假设整个数据集中前半段数据具有n种参数特征变化,后半段数据具有m种参数特征变化.令
M={s1,s2,…,sn}
(1)
N={l1,l2,…,lm}
(2)
式中,si与lj分别为某一时段内的数据曲线拟合结果和直线拟合结果,且1≤i≤n,1≤j≤m.
数据估计量集合中涵盖大量信息,需要依靠大数据分析技术实现集合解析.大数据分析技术能够细化数据区间,并从区间中挖掘大量有效信息.
在大数据分析下某一时段的曲线拟合结果si与直线拟合结果lj具有各自的性质变量E与变量比重F[5],即
si=〈Ei,Fi〉
(3)
lj=〈Ej,Fj〉
(4)
此外,数据估计量集合中的性质变量与变量比重的数量均为m+n[6],且F1+F2+…+Fm+n=1,此时集合可表示为D={s1,s2,…,sn,l1,l2,…,lm}.
1.2 干扰数据源挖掘
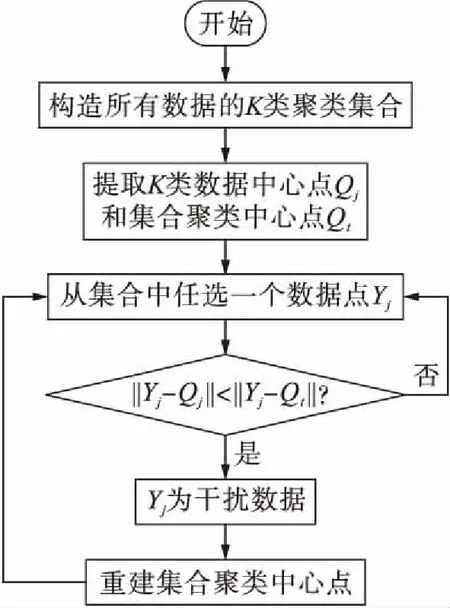
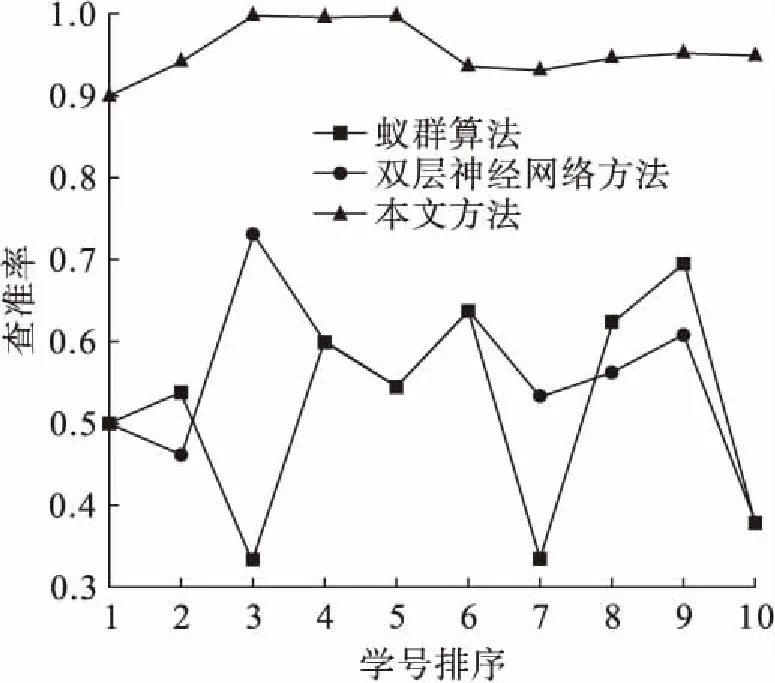
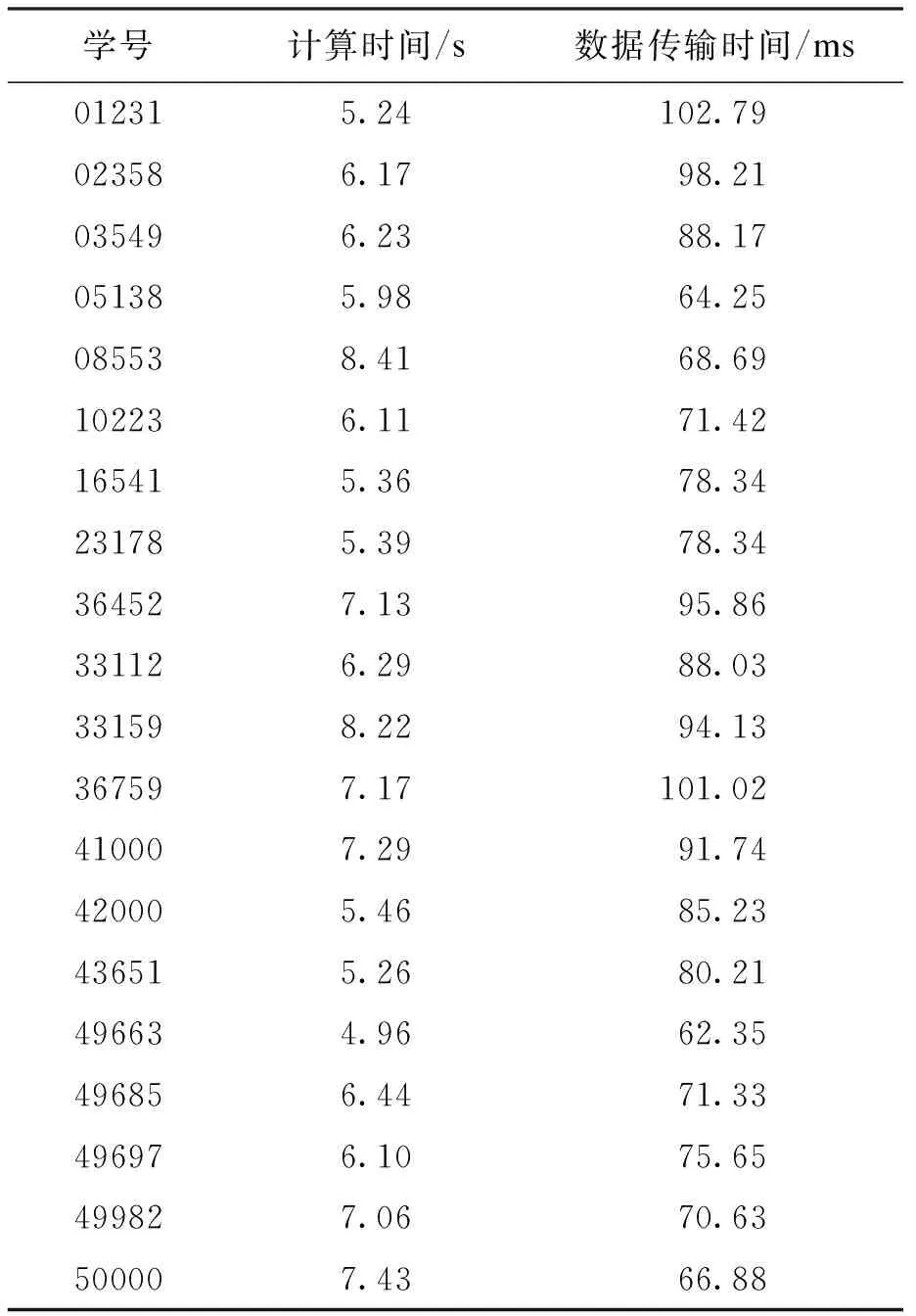
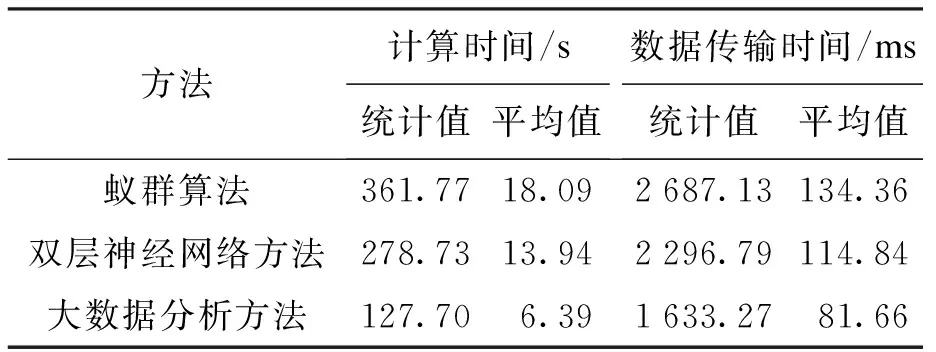
在大数据环境下对SQL数据库中的数据源进行最优选取时,会存在一些高噪声干扰数据,这些数据偏差较大,且会对最优教学方式选取模型精度造成一定影响[7],因而需要对其进行有效滤除处理,从而确保模型接收数据的正确性.当进行数据偏差滤除时,需要提取两个数据点阈值A与B,且其中一个数据点阈值需要偏大点.当0 (5) 图1 干扰数据挖掘流程图Fig.1 Flow chart of interference data mining 将Yj从DK中删除并写入M后,需要重新计算DK的聚类中心点[11],其相应函数表达式为 (6) 式中:mk为DK中的数据点数量;x为大数据聚类分析层数;t为K类数据总量. 为了更加精准地挖掘干扰数据,可以设置一个挖掘精度阈值α,当挖掘精度小于α时,应利用式(5)进行二次挖掘[12].在干扰数据挖掘过程中挖掘精度的函数表达式为 (7) 利用数据估计量挖掘模型进行运算,不同服务器数据在大数据分析技术下可被分门别类,但由于挖掘出来的数据参数特征过多,无法直接利用这些挖掘结果设计最优选取模型[13],因而需要依据以下两点进行筛选: 1) 挖掘出的数据具有的特征是否具有独特性; 2) 该参数特征是否值得选取. 对此,需要额外构建一个数据特征归纳集合R和数据特征选取标准集合T,目的是在大量数据参数特征挖掘下,以高精准度选取效率对数据进行融合[14].R中主要包括特征点集、数据拟合精度评估与参数特征,T中主要包括被挖掘的干扰数据和特征整合结果. 基于大数据分析的最优选取模型由数据源整合、数据拟合与滤除干扰三方面共同作用,大数据分析技术通过采取相关性定义[15]对最优数据的选择几率进行计算,最优选取模型可以表示为 (8) 式中:rp、cp、dij分别为集合R、T、D中的数据点;w为集合T中的数据点数量. 为了提高模型精度,大数据分析技术提出采用一个调整系数来平衡计算条件的方法.调整系数的作用是将数据特征集合中与教学科目完全无关的数据进行权重调整,这样既节省了模型存储空间,又不会删除有用资源.调整系数的函数表达式为 (9) 可见,调整系数与t成反比,与w成正比.加入调整系数后,最优选取教学方式模型表达式可以调整为 (10) 将基于大数据分析的最优教学方式选取模型应用在教学中,通过对教学方式的最优选取来判断所设计模型的有效性,且需要一个计算机硬件平台与数据库对其进行支持.计算机硬件平台采用NEXTSTEP系统实现开发,其开发成果完善且独立,能够最大限度抵御外界干扰,防火墙功能十分强劲.数据库的语言类型为结构化查询语言SQL,SQL数据库的灵活性与稳定性较强,即便是在存储大数据时也无需了解存储方式便可提供便捷的搜索功能. 将海量数据信息存储到SQL数据库中,数据样本采用5万条学生样本,每条样本中都含有2016年一整年的学生个人信息、班级、历史考试成绩、教师评价与学生评价.教学科目包括高数、英语与语文.对样本数据进行数据拟合,利用本文所设计的基于大数据分析的学生偏好挖掘模型获取上述数据的学生长期偏好与短期偏好,同时根据实际情况构造教学资源集合,并采取调查问卷的方式构造教师偏好集合. 本文旨在进行基于大数据分析的最优选取模型的教学方式选取能力评估与模型复杂度评估,并分别采用偏好查准率与模糊评估法实现.在选取教学方式的过程中,偏好查准率定义为学生偏好与教学方式选取结果的契合比率.可见,查准率并不以教学资源和教师偏好的选取为主导,而是建立在学生偏好表达能力之上,其函数表达式为 (11) 式中:o为存在于学生偏好集合中的结果数;g为教学方式推荐数量. 模糊评估法是指在复杂大数据环境中对模型做出的综合评估.由于基于大数据分析的教学方式选取模型在处理过程中涉及到的数据点数据极多,所以选择模糊评估法进行模型复杂度评估是比较合理的.模糊评估法需要构建可能对评估对象造成影响的参数集合与评估项目集合,其表达式分别为 U={u1,u2,…,um+n} (12) V={v1,v2,…,vm+n} (13) 利用专家评估法设置参数集合中数据的比重集合,其表达式为 A={A1,A2,…,Am+n} (14) 式中,A1+A2+…+Am+n=1. 模糊评估法的评估结果是评估项目集合条件下的一个模糊集合,相应表达式为 G=AUV (15) 若想获取基于大数据分析的最优教学方式选取模型复杂度,评估标准集合中需要包含最优教学方式选取时间、偏好计算时间以及数据传输时间.参数集合中包含学生历史成绩增长率和学生思维偏好. 基于蚁群算法的最优教学方式选取模型和基于双层神经网络的教学方式选取模型的理论架构与实际应用效果均比较完善,利用这两种模型与本文设计的基于大数据分析的教学方式选取模型共同进行评估具有一定代表性.采用三种模型对SQL数据库内容进行教学方式选取,将结果中的o、g值提取出来.由于学生样本数量太多,故对结果进行随机抽取,从学号为00001的学生开始抽取10个学生,所得到的具体评估值分别如表1~3所示. 表1 蚁群算法模型评估值Tab.1 Evaluation values with ant colony algorithm model 表2 双层神经网络模型评估值Tab.2 Evaluation values with double-layer neural network model 表3 大数据分析模型评估值Tab.3 Evaluation values with big data analysis model 根据查准率公式,将三个模型的查准率计算结果进行对比,结果如图2所示.由图2可见,基于大数据分析的教学方式选取模型查准率最高,表明利用所提方法设计的最优选取模型具有更高的选取精度. 在模糊评估法中最优教学方式选取时间、偏好计算时间与数据传输时间(包括收发延迟)为基于大数据分析的最优教学方式选取模型的复杂度评估项目.对于基于蚁群算法和基于双层神经网络的教学方式选取模型而言,并不存在对学生偏好的计算过程,因此,为了方便对比,将本文模型的教学方式选取时间和偏好计算时间统一看作“计算时间”,因而模型复杂度将主要取决于模型计算时间与数据传输时间. 图2 三种模型查准率对比Fig.2 Comparison in precision ratio of three models 任意抽取20个学生后,三个模型的计算时间和数据传输时间统计结果分别如表4~6所示.模型复杂度统计值和平均值对比结果如表7所示.由表7可见,本文模型复杂度具有明显优势. 表4 蚁群算法模型复杂度Tab.4 Complexity of ant colony algorithm model 表5 双层神经网络模型复杂度Tab.5 Complexity of double-layer neural network model 表6 大数据分析模型复杂度Tab.6 Complexity of big data analysis model 表7 模型复杂度统计值和平均值Tab.7 Statistical and average values of model complexity 本文设计了最优教学方式选取模型,在大数据分析的基础上分析了不同服务器大数据信息,预测了高噪声干扰数据,分析了干扰数据点滤除前后统计量的变化,对数据估计量进行了高效挖掘,构造出由数据源整合、数据拟合与滤除干扰三方面相结合的最优选取模型,并利用调整系数进一步提高了模型精度.实验结果表明,所设计模型能够有效选取最优教学方式,且模型复杂度不高,同时具有较高实用性.
2 基于大数据分析的最优教学方式选取模型设计
3 实验评估
3.1 实验数据准备
3.2 评估标准
3.3 查准率评估结果



3.4 复杂度评估结果


4 结 论
