基于用户项目特征分组的隐私保护算法*
2018-12-05林荣智苗耀锋
林荣智, 苗耀锋
(西安外事学院 工学院, 西安 710077)
随着互联网技术的发展,社交网络、大数据等技术也不断地被应用到社会各个场景中[1-4].由于海量数据不断涌向网络用户,学界提出了推荐系统来解决其严重的信息过载问题[5-8].该系统通过采集用户的个人信息和操作数据,精准地向用户提供有效信息[9-10],然而,由于该系统存储了用户的敏感隐私信息,所以用户的信息与财产安全面临较大的威胁,即互联网中的推荐系统存在用户隐私保护的问题[11-16].
为了解决系统中用户隐私保护的问题,本文扩展并改进了传统的推荐系统,提出了保护用户隐私的新型推荐系统.其主要原理是以推荐项目为中心,基于项目特征相似度的计算结果,将系统中所有推荐项目进行详细划分,推荐给系统中不同兴趣爱好的用户.因该系统只需采集用户对项目的评价信息,并不会存储其隐私信息和敏感数据,所以这种新型的推荐系统可以有效地保护用户的隐私信息.
1 隐私保护问题
一般而言,互联网推荐系统中推送信息的准确度与用户信息的完整度是成正比的,而与隐私保护程度成反比.在推荐系统中,用户隐私泄露的主要途径包括服务器直接获取、黑客窃取和其他系统泄露等几种方式.而用户隐私信息主要包括个人信息、操作数据和关注信息三个方面,其中,个人信息主要是指用户的姓名、性别和身份证号等高敏感度隐私信息;操作数据是指用户的网页访问数据、提交信息等具体数据;关注信息主要包括用户在各个网站的定制信息等内容.目前,学术界在该问题的研究上主要使用三种隐私保护技术,即基于密码学技术、数据干扰技术和k匿名技术.基于密码学的常用技术就是安全多方计算、同态加密算法等,而这些都使用了复杂的密码学计算方法,推荐系统的用户信息都具有庞大的规模,所以基于密码学的技术安全性虽高,但并不实用;k匿名技术即是去除敏感信息来保证用户的隐私信息不泄露,这种技术不能抵抗链接攻击,同时也会减少数据表中的信息,所以也难以应用到实际的推荐系统中;数据干扰技术是使用一些算法修改或干扰原始数据,从而保护用户的隐私,这种算法会直接导致数据的准确性和完整性受损.综上所述,以上技术并不能解决推荐系统的隐私保护问题,而本文使用的推荐算法与这三种技术都不一样,本文的算法计算相对简单,不像基于密码学技术那样复杂,并且不直接对用户的隐私信息进行操作,所以也不会减少系统中的数据,较好地保持系统数据的准确性与完整性.
2 保护用户隐私的推荐系统
2.1 推荐系统的建立


图1 系统工作流程Fig.1 Workflow of system
图1中项目之间的相似性模型计算过程包含项目属性数据量化、项目之间相似性计算和确定项目邻居集合.具体过程如下:
1) 项目属性数据量化.一般而言,项目的属性数据是使用向量表示的,即对项目的属性数据分为n个相互独立的分量,从而刻画出项目的具体特征.项目属性矩阵为[ci1,ci2,…,cin],cin表示第i个项目的第n个特征属性的特征值,该特征值的类型有描述型和数值型两种.系统通常使用TF-IDF公式描述属性特征值,数值型的特征值包括固定值和区间值两种,固定值可以直接参与计算,而对于区间值,系统使用区间占用的比例值来计算.

(1)
3) 根据式(1)项目之间相似度的计算结果便可度量项目之间的相似性,从而确定项目的邻居集合.通常相似性度量方法具有不准确和数据稀疏的问题,为了避免这些问题,本文使用了新算法度量项目之间相似性,工作流程为:
① 总结所有评价了第i个项目或第j个项目的用户集合,用Sij来表示,rui表示任意用户u评价第i个项目的评价信息,令S代表所有用户,则Sij表达式为
Sij={u|u∈S∩(rui≠0∪ruj≠0)}
(2)
② 根据Sij中用户的评分,预测未被用户评分项目的评价结果,在用户集合Sij中使用Pearson相关性分析度量i项目和j项目之间的相似性,得到当前项目的邻居集合.系统中预测用户u对未评价的第i个项目评价结果为
(3)
式中,Ei为第i个项目的邻居集合.之后系统便可以计算Sij中任意用户u评价第i个项目的评价信息Rui,即
(4)
2.2 推荐系统的具体实现框架
具体推荐系统实现步骤如下:
4) 根据预测评分信息对用户推荐排名靠前的项目.
3 推荐系统实验与分析
3.1 实验方案设计
本文对提出的推荐系统进行了必要的实验.其中,实验需要的原始数据集来自MovieLens,由Minnesota大学的GroupLens课题组提供.Movie-Lens数据集主要用于同名的电影推荐系统,而该推荐系统需要用户评价浏览过的电影,并利用评价信息预测并推荐用户喜欢的电影.需要指出的是,MovieLens数据集是学术界用来实验推荐系统的经典数据集,其内容包括了943位用户评价1 682个项目的10万条评分数值.其数值是1~5的离散整数,代表了用户对某项目的喜欢程度,其基本信息如表1所示.
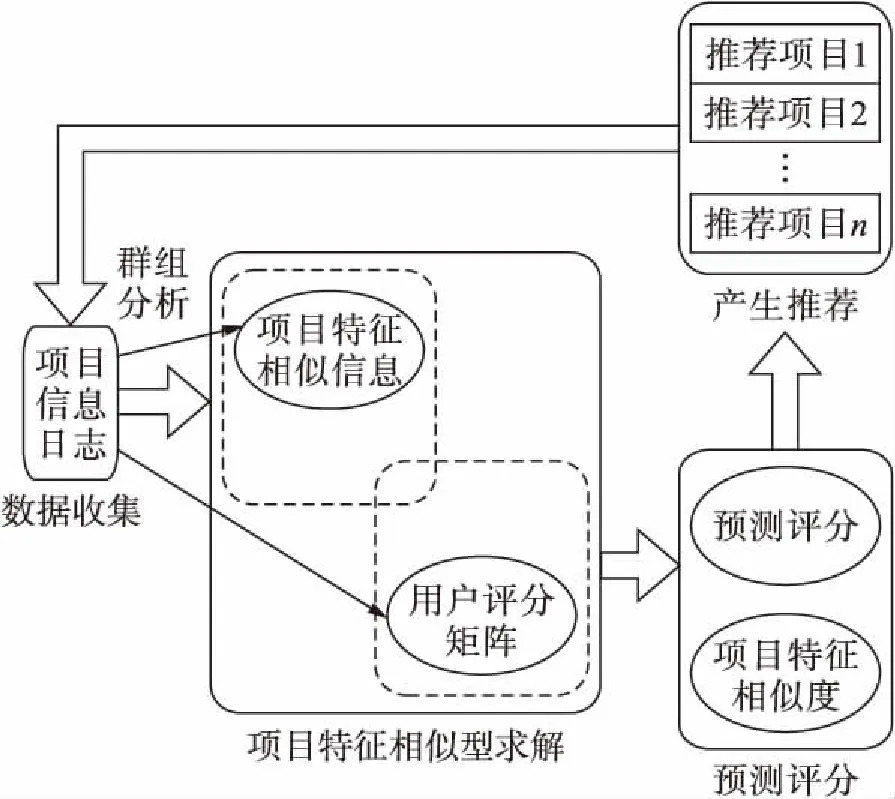
图2 推荐系统的实现框架Fig.2 Implementation framework of recommendation system

表1 MovieLens数据集基本信息Tab.1 Basic information of MovieLens data set
在该数据集中,本文选取了300个用户、600部电影项目的评分数值,同时,得到了按照用户统计信息排布的所有电影项目的属性特征矩阵.本文设置80%的评价数据作为推荐系统的训练数据集,20%的数据作为推荐系统的测试数据集.由于本文的推荐系统是以项目为中心,所以需要设定项目的属性分类,600部电影项目的属性分类被分为18种类型,分别是动作、冒险、动画、儿童、喜剧、犯罪、纪录片、戏剧、幻想、恐怖、音乐剧、悬疑、浪漫、科幻、惊悚、战争、西部和黑色电影.
具备所有的属性分类之后,则需要量化所有项目的属性数据.在MovieLens数据集中,假设电影m是一个悬疑惊悚片,即该电影具有两个或多个属性,则其具备的属性向量的分量就是1,其他分量是0,则电影m的属性矩阵就是[0,0,0,0,0,0,0,0,0,0,0,1,0,0,1,0,0,0].使用这种方法量化所有的电影项目之后,便可根据本文提出的方法计算项目的属性相似矩阵.再使用式(1)计算项目之间的相似度,从而将所有的项目划分为多个群组,并设群组数量为Ng.其中,一个群组所包含的项目数为s,该项目参数是根据相似度的计算结果阈值来确定的.
本文实验引入了3个评价指标:均方根误差(RMSE)、平均绝对误差(MAE)和归一化累计增益(NDGG),分别描述了推荐系统的评分准确性、评分偏差性和推荐准确度.均方根误差的表达式为
(5)

平均绝对误差定义为任意观测值与均值差的绝对值均值,其计算表达式为
(6)

在实验中归一化累计增益(NDGG)用来测量推荐系统的排序质量,即对比推荐系统的排序和实际数据集中的评分排序.归一化累计增益的计算表达式为
(7)
(8)
式中:NDGGp为推荐系统中排名前p的NDGG值;DGGp为根据实际评分结果计算出的排名前p的累计增益;IDGGp为排名前p的理想累计增益;reli为该项目的实际评分.
3.2 对比方案设计
一般而言,第1组对比实验的推荐效果是相对较差的,其原因主要是该实验未对项目本身进行研究学习,只将用户对于电影项目的平均评分因素加入计算过程.而第2组实验的准确度要高于本文的推荐系统,其原因主要是该方法使用了更细数据粒度的训练数据集.
3.3 实验结果与分析
本文的实验可以被分为2部分,第1部分的实验主要研究了项目属性维度和项目之间相似性关系,对比了两组方案与本文推荐系统在不同属性维度时的推荐效果.为了便于比较本文推荐系统的应用效果,引入损失率δ这一指标,即
(9)
式中:aPMF为概率分解算法计算的评分值;a为实际评分值.本文分别选择了项目属性维度D为5、10和18,其他输入均设为令推荐效果最佳的最优值.运行本文的推荐系统与两组实验进行对比,对比结果如表2所示.表3给出了推荐系统不同维度损失率的结果对比.
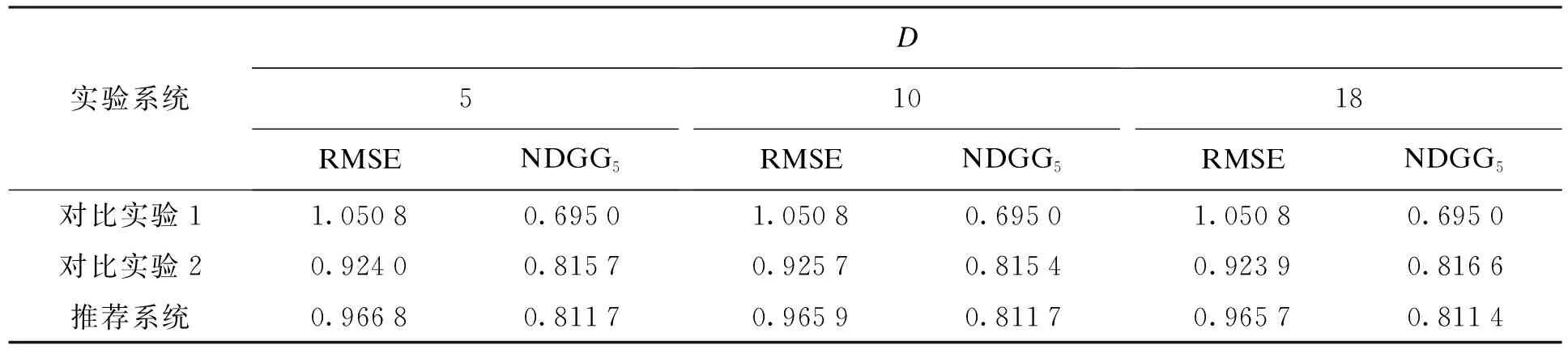
表2 RMSE和NDGG的结果对比Tab.2 Comparison in results between RMSE and NDGG

表3 损失率的结果对比Tab.3 Comparison in results of loss rate %
从表2中可以看出:若项目属性维度增加,第1组对比实验的准确性不变;第2组对比实验的准确性刚开始有一点降低,随后有所提高;本文推荐系统的准确性随维度变化不大,其原因是随着项目属性维度的增加,项目的数据信息更加详细,进而降低推荐误差,从而提高了算法的推荐准确度.如果算法的设计比较合理,其准确度也没有太大的变化,甚至会略微降低一点.然而需要指出的是,属性维度的增加将使用更多的计算资源,过多增加属性维度也会降低系统运行效率,但本文推荐系统的NDGG5指标不易受到项目属性维度数量的影响,效果明显,实用且值得推广.
第2部分的实验主要研究了项目的属性数量和最近邻居数量对数据粒度的影响,数据粒度是指推荐数据的细致度,可以衡量出推荐系统的推荐效果.图3、4为数据粒度随属性数量和最近邻居数量的变化状态.

图3 项目属性数量对推荐系统数据粒度的影响Fig.3 Influence of project attribute number on data granularity of recommendation system
由图3可知,若项目属性数量增加,能够反映推荐系统推荐效果的3个指标MAE、RMSE和NDGG5也会逐渐稳定.其主要原因是项目属性数量的增加能够使电影项目属性数据更加详细,其相似度的计算结果也会更精确,进而推荐效果也会变好.而项目属性数量增加也会增大用户隐私暴露的风险,同时增加系统计算资源的消耗.
由图4可知,项目属性数量确定时,若最近邻居数量增加,反映推荐效果的指标MAE、RMSE和NDGG5就会逐渐变坏.其主要原因是项目群组的规模增加,推荐系统的数据粒度便会增加,由此会引起提取数据的困难.根据图3可知,项目的属性数量增加到15之后,系统的推荐准确度基本保持不变,所以项目属性数量最佳区间应是[10,15].
4 结 论
本文对社交网络中推荐系统的隐私保护问题进行了深入研究,在一般推荐系统的基础上,基于项目属性的相似度将所有项目划分为若干个项目群组,从而得到项目的最近邻居集合,推荐给具体的用户.该系统无需采集用户的隐私信息,大幅降低了用户隐私泄露的风险.实验结果证明:虽该系统在推荐准确性上有损失,但能够更好地保护用户的隐私,具有较高的实用与推广价值.
