分布式本体调试信息的存储优化与增量更新
2018-11-08闫智宣邱煜晶卢海强
吴 刚, 闫智宣, 邱煜晶, 卢海强, 李 洋
(东北大学 计算机科学与工程学院 辽宁 沈阳 100619)
0 引言
随着语义Web的规模和重要性的不断增长,越来越多的知识以机器可读的格式存储,如RDFS和OWL.对于许多应用,知识的提取和推理是核心要求之一.通过推理,知识可以有逻辑地导出,而不仅是明确存在于数据中[1].然而,大规模本体数据的推理可能导致产生大量逻辑冲突,为了定位和解释这些逻辑冲突,通常使用本体调试的方法[2].近年来,已经有一些程序以有效的方式实现了本体推理[3-5],本体调试领域也有了长足进展,提出了很多RDFS和OWL[6]本体上的调试方法.这些方法及相应的原型系统主要应用于特定的且规模较小的本体数据集,可以分为两类:一是基于修改描述逻辑推理引擎的白盒方法;二是将描述逻辑推理引擎作为外部信息源用于检查本体可满足性的黑盒方法[7].针对百万数量级的本体数据,传统的本体调试方法求取计算的时间长,不能满足大规模、大数据量的本体数据求取最小冲突公理集合的需求.
已有的分布式本体调试方法[8]存在耗时较长的问题,其原因是基于分布式文件系统HDFS的存储结构不能满足日益增多的本体调试的需求.本文提出了一种良好的存储结构和更有效的存储模式存储调试信息,以提高本体调试的速度.此外,考虑到普遍存在本体自身演化和本体间链接更新的情况,已存在的RDFS和OWL分布式推理与调试的静态算法是不够合理的,缺乏对已经推理的蕴含及调试信息的有效利用.本体的更新包括增加和删除本体数据,这些更新必然会导致已经推导出的蕴含及其调试信息失效,重新对所有本体数据进行推理和调试信息的收集耗时、耗力.因此,本文提出一种增量更新算法,以应对本体数据不断更新的情况,实现了本体数据的动态更新,LUBM数据集的实验结果表明该算法是有效的.
1 系统结构
分布式环境下RDFS和OWL pD*本体推理与调试系统主要由以下3个部分组成:
第1部分,数据预处理部分.将原始三元组中的资源数据以数字id的方式编码压缩,以减少数据的读写量,将尽量多的数据读入内存,达到加速的效果.需要存储的数据包括编码后的三元组,以及资源与id的对应关系.这些数据主要用于推理和辩解信息解码.
第2部分,本体推理部分.包括RDFS推理和OWL pD*推理,应用RDFS和OWL pD*规则进行推理,将推理出的三元组存储于数据库,循环执行两种推理机直到没有新的三元组产生.主要存储信息包括以七元组形式表示的蕴含及其调试信息.
第3部分,本体调试部分.利用调试信息递归求取最小冲突公理集合,然后对辩解集合中的资源进行解码,同时对辩解集合进行缓存.主要存储信息为最终的调试结果.
系统的3个部分都涉及密集的数据读写,需要对3个部分分别进行存储设计和优化.对相关算法进行优化以适应分布式数据的读写,并保证算法的正确性和完备性.系统采用Hadoop提供的MapReduce模型作为计算模型,采用Cassandra数据库作为分布式存储模型.系统的整体结构如图1所示.
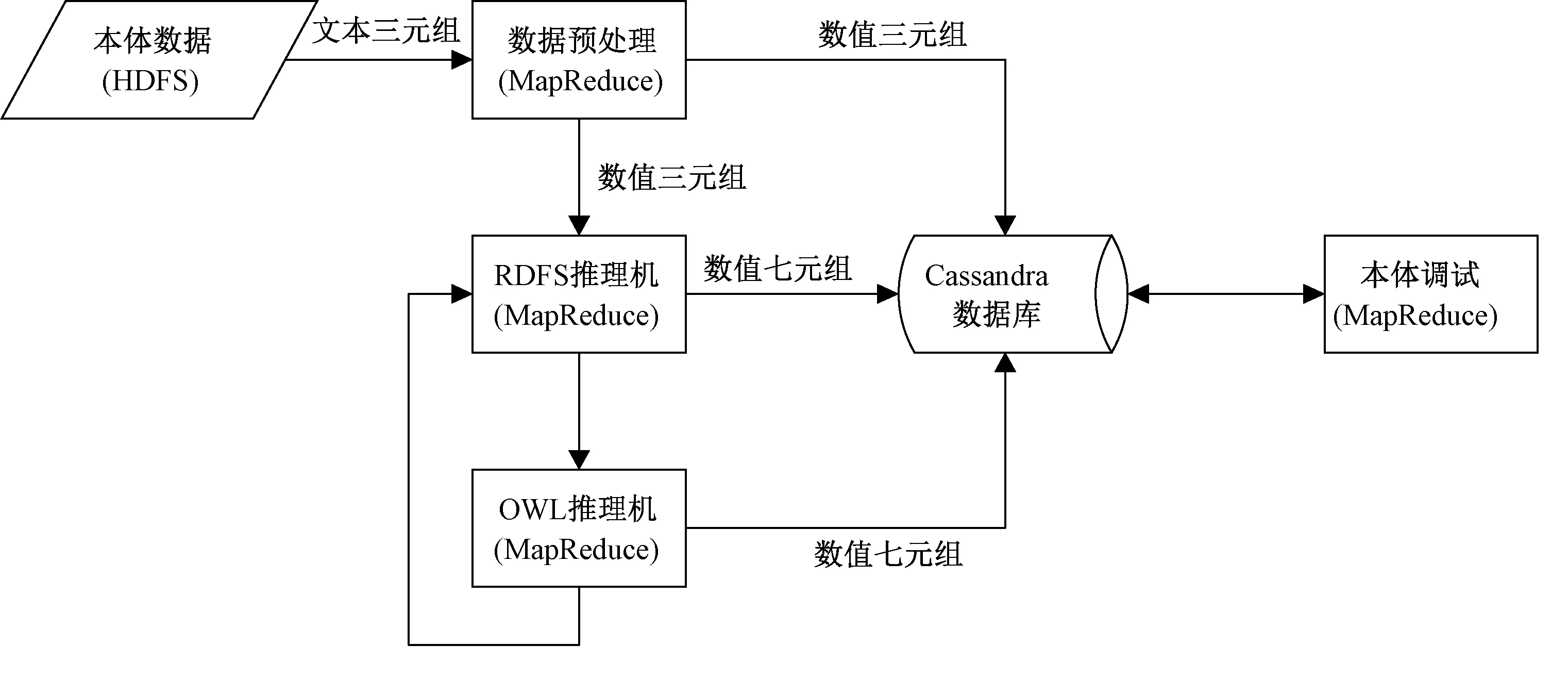
图1 系统整体结构Fig.1 The overall structure of system
2 数据预处理及其存储结构
2.1 字典编码
采用被广泛应用于数据压缩问题的字典编码技术,把以文本表达的三元组中的元素转换成数值id存储数据.将三元组进行压缩,能够减少空间的占用.使用的压缩方案是用3个数字代替三元组的3个元素,数据编码并不影响推理过程.使用MapReduce进行字典编码处理[9],编码后的字典和数值形式的三元组存储于分布式数据库中.
2.2 存储结构
对于分布式数据库的配置,由于系统的Cassandra数据库部署在一个高可用的集群上,因此采用单数据中心模式.Keyspace作为Cassandra中最大的组织单元,包含了一系列的Column family. 设计Keyspace采用的备份策略为SimpleStrategy,设置副本数为2,即同一份数据保存在两个不同的节点.设计数据库的写一致性为ANY,读一致性为ONE,即写数据库时写入任一个副本即标记为写成功;读数据库时读取最近的副本成功即可.
从数据库读取数据采用分页读取的方式.由于大数据量的三元组不能一次性完全读入内存,需采用分页读取的方式.Cassandra数据分页的数量直接影响MapReduce中的Map数量,每个分页对应一个节点的一个Map,因此,需要设置合适的分页大小.当分页较小时,产生的页数很多,会启动大量的Map,导致大量的时间用于job的启动和结束,用于处理数据的时间变少;当分页较大时,启动的Map数量较少,每个job承担的数据量变大,可能存在着job执行失败的情况,重启job需要重新进行推理,同样较为耗时.
3 本体推理调试及其存储结构
3.1 本体推理与调试
推理包含RDFS推理和OWL pD*推理两部分.规则的执行顺序存在着一定的特点,通过调整规则的应用顺序,能够有效地加快推理过程[9].对于整个系统的推理过程,需要循环执行RDFS推理机和OWL pD*推理机,直到没有新的三元组产生.
最小冲突公理集合的求取方法与真值维护系统(TMS)求解过程[10]有一定相似之处.TMS主要通过TMS依赖图实现[11],通过在推理引擎前向推理过程中记录调试信息来构建TMS依赖图.当推理引擎每应用一次推理规则产生新的推理结果,就在依赖图中添加相应的节点和有向超边[12].调试过程参照文献[8],使用JTMS(justification-based TMS)求取OWL pD*语义下推理结果的所有调试信息.
3.2 蕴含及其调试信息的压缩
为了实现本体调试,求取已经推理出的蕴含调试信息集合,需要保存推理过程中的相关调试信息.由于调试信息中有冗余信息,直接全部存储会造成存储空间的浪费,同时降低写速度,从而降低系统整体的运行速度.
假设本体中有两个三元组T1:〈QiE, type, Bird〉,T2:〈Bird, rdfs: subClassOf, Animals〉.根据推理规则可以推出一个新的三元组T3:〈QiE, type, Animals〉.对于T3只有一条调试信息〈T1,T2〉,可以表示为J(T3)={{T1,T2}}. 因此,需要存储的信息为T3: 〈QiE, type, Animals, QiE, type, Bird, Bird, rdfs: subClassOf, Animals〉. 可见RDF词汇“QiE”、“Bird”、“Animals”都被重复存储了.分析推理规则和结果发现,对于任何subClassOf规则的实例中,前提subClassOf和结论type均为已知且保持不变.因此,对于上述存储方案存在的冗余,提出标签压缩方案作为调试信息的表示方式.
调试信息的存储模式使用一个固定长度的标签方案来表示绑定的规则.规则绑定标签是一个七元组(Con-Sub,Con-Pre,Con-Obj,RuleName,Binding1,Binding2,Binding3),其中Con-Sub、Con-Pre和Con-Obj对应主语、谓语和宾语,是推理出的结果三元组的RDF术语;RuleName表示规则集合中的规则模式,即应用哪些规则得出新的三元组;Binding1、Binding2和Binding3的值表示RDF术语的来历和前提,即推导出该三元组的相关的三元组信息.具体的绑定标签的规则压缩方案见文献[8].
本体推理阶段,即调试信息的收集阶段,采用简化的JTMS依赖图与推理机的前向推理过程一起构建,方式是在前向推理过程中增加存储相关调试信息的步骤.对相同的三元组应用不同的推理规则会有不同的绑定标签.存储简化后的绑定标签的数量等于JTMS依赖图中的边数.因此,使用绑定标签对推理过程和依赖图不会产生太大的影响.
3.3 调试信息存储模式
推理机执行的每一步都需要读取全部三元组,包括公理和之前步骤推理出的结果.Cassandra数据库同时读取两个表的数据或同时向两个表写数据的速度远低于向同一个表读写数据. 因此,最佳存储方法是将公理与推理出的结果保存在同一个表中,以相同的格式存储.
通过对RDFS和OWL pD*推理过程的分析,以及调试信息绑定标签的存储方式可知,需要存储的信息包括绑定标签的七元组,justifications表结构如图2所示.
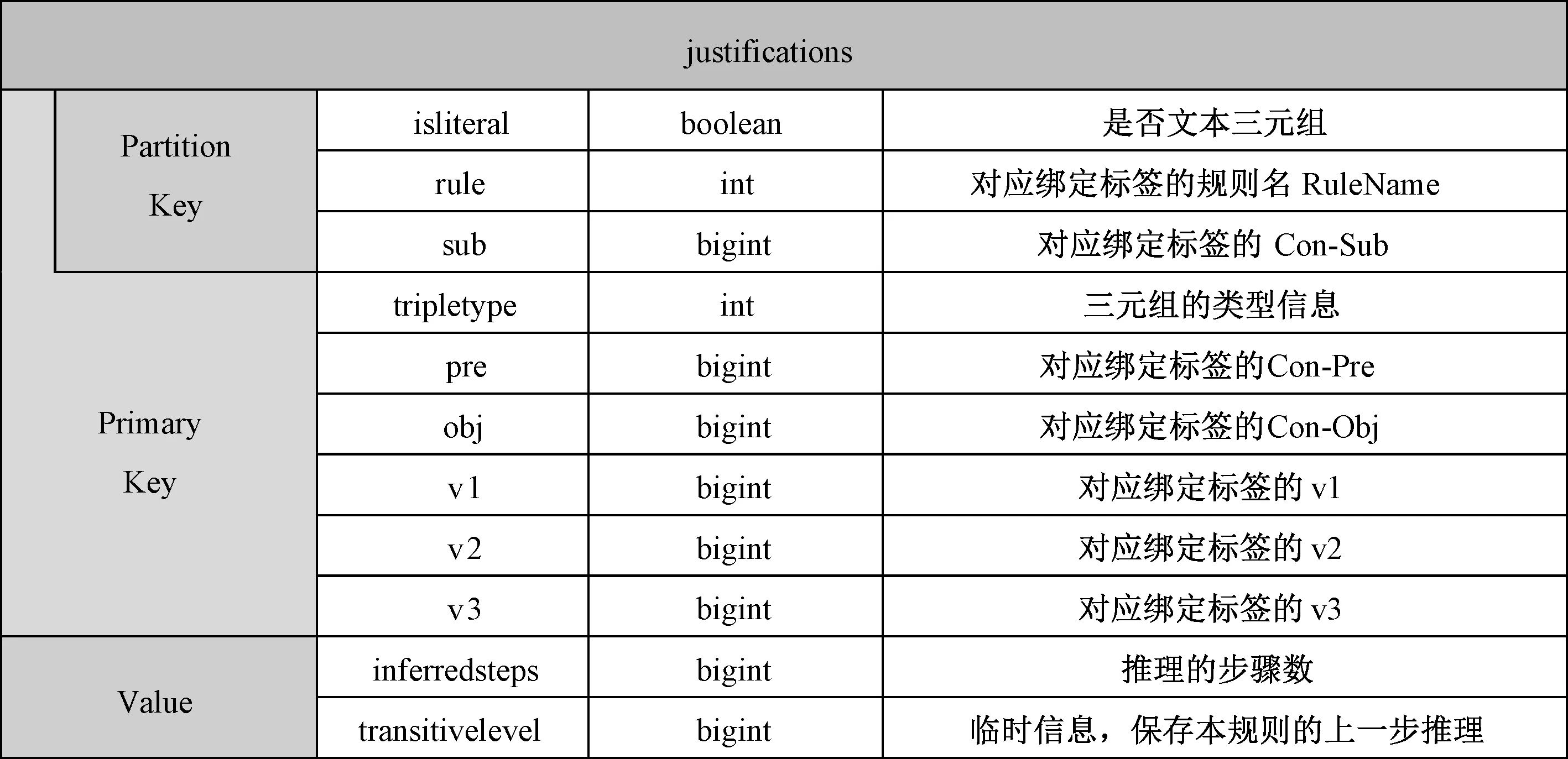
图2 Justifications表结构Fig.2 Justifications table structure
由于justifications表存储了所有的公理和推理结果及其辩解信息,存储的数据量巨大,并且在本体推理和调试过程中都需要大量读写该表. 因此,需要尽量优化该表的组织结构.在Cassandra数据库中,Partition Key作为Primary Key的一部分,主要作用是决定该行数据是存储于哪个节点,或者应从哪个节点读取.在本系统中Partition Key的设计选择主要有(sub, pre, obj)和(isliteral, rule, sub)两种方式,其中后一种设计能使集群的数据负载更加均衡.因此,设置justifications表的Partition Key为(isliteral, rule, sub).Primary Key其余的属性作为Clustering Key,主要作用是以此为依据对分区内的行进行排序. 由于推理过程中需要对tripletype属性进行条件查询,而Cassandra数据库不支持Partition Key或Clustering Key属性的跳跃选择查询. 因此,需要将tripletype排在Clustering Key的第1位,同时在tripletype列创建索引.
3.4 本体数据蕴含集缓存设计
为了避免重复求取所推理的蕴含集,尤其对于在本文后续的本体删除算法中会经常出现求取相同三元组的蕴含信息情况,对全部三元组推理的蕴含集进行了缓存.设计表entailments存储全部本体数据推理的蕴含信息,分布式求取过程如下:首先读取justifications表中能得到新推理结果的七元组,然后根据七元组找出推理结果并求出其所需的全部前提三元组[8].再遍历前提三元组,将每条三元组作为entailments表的主键,推理结果三元组作为表的Value值,更新到蕴含集.
4 增量更新算法
4.1 本体增加算法
当本体数据中有新的公理加入时,调试信息也会随之增加,此时完全地重新进行本体信息的推理与存储的开销较大.由于新增的公理与增加前已有的公理之间没有必然的联系,与已储存的推理结果也没有直接关系,因而当本体数据增加后,已有的调试信息不需要更改.通过JTMS依赖图亦可发现,依赖图中增加新的节点,不影响图中已存储的节点和边.据此提出以下算法:新增公理的情况下,当应用一条规则时,如果前置条件均为已有的公理或已有推理结果,则该蕴含的推理结果实际已存储,可直接跳过这个推理过程.只有前置条件中至少包含一条三元组为新增三元组才会产生新的推理结果.为此,当新增公理时,为推理机所有规则的执行设计了一个前提,即将规则应用到数据集合时,如果规则的前置条件至少存在一条公理是新增公理,就执行推理机;如果前置条件包含的三元组均为原始三元组,则直接跳过.添加该前提约束,以避免对已存储过的调试信息进行推理.
对于新增加的公理,经过本体推理可能会产生新的推理结果,并且可能会将其继续用于后续的推理规则.因此,需要将新增的推理结果同样标记为新三元组,加入到新增三元组的集合,与新增公理以相同形式存储.
整个更新过程使用的推理算法不变.具体的处理过程根据规则可以分为两类:一类是新增公理相对原有公理的推理没有受到影响,对应的规则如文献[8]中p1、p2、p3、D2等,可只进行针对新增公理的推理,由于相对简单就不再详述;另一类是在新增公理上使用具有传递闭包属性的规则,如规则D5、D7、D11、p4、p7、p12c、p13c等.这种情况下推理算法的输入数据为全部的本体信息,但是新增公理集的闭包关系只与新增本体有关,算法时间复杂度为O(n).
4.2 本体删除算法
当从本体数据中删除数据时,删除已有的公理可能会导致存储的调试信息失效.失效的调试信息是指从本体数据集合去除删除公理后无法通过剩余的公理推理得到的信息.
当删除本体数据时,除了要删除公理本身,还要删除失效的调试信息,即包含该公理的调试信息.因此,需要考察由此公理推理得到的各三元组,可分为两种情况:若某三元组对应的调试信息集合中删除与此公理相关的调试信息后,调试信息集合不空,则可以删除与该公理相关的调试信息,保留该三元组及其调试信息集合中的其他调试信息;若当一个三元组的调试信息集合中全部调试信息都与该公理有关,在删除与此公理相关的调试信息后,调试信息集合为空,则应该同时删除该三元组,同时将该三元组添加到删除集合,迭代执行删除算法,算法时间复杂度为O(n2).
删除算法的执行步骤如下:
1) 查找resources表,对需删除的本体数据进行数据编码,然后将其添加到集合D.
2) 删除由此公理推理出来的相关辩解信息.由于保存的调试信息都以绑定标签的形式进行,从存储的数据上不能直接判断一个蕴含辩解是否包含删除的三元组.因此,根据保存的调试信息一次性求取全部的蕴含信息并保存到数据库entailments表.
3) 对集合D中所有三元组Ti进行本体调试,查询蕴含表,找出D中三元组对应的蕴含信息,循环遍历所有蕴含,求取对应的辩解集合Ji.
4) 遍历所有辩解集合Ji,判断其中的每一个辩解集合中的每一条辩解信息是否包含删除三元组:对于不包含删除三元组的辩解信息保持不变;对于包含删除三元组的辩解信息,将该条辩解信息删除.
5) 删除所有包含删除三元组的辩解信息后,清空集合D.同时遍历所有辩解集合Ji,判断是否存在空集合:如果辩解集合为空的蕴含,将其添加到删除三元组集合D,重新从1)开始.如果删除集合D为空,删除过程完成.
5 实验
5.1 实验环境与系统部署
实验数据取自LUBM(Lehigh University Benchmark)标准测试数据集,分别为LUBM-1、LUBM-10、LUBM-100.系统部署在集群服务器上,集群共有9个节点.集群使用Hadoop-0.20.2,Cassandra-2.1.10,内存64G,硬盘50G,CPU双核单线程.
5.2 本体调试实验
对三元组进行数据编码,图3展示了压缩前后存储对比效果.实验中通过多次随机选择数据库justifications表中一行,即随机选取一条三元组,进行本体调试.
在经过多次随机求取调试信息集合后发现,影响求解过程用时的主要因素是MapReduce求解过程启动job的数量.当求解需要启动的job数量越多时,其耗时越长.存储优化前的系统基于HDFS调试信息存储,图4展示了对于相同job数的存储优化前后的本体调试用时对比效果.容易发现,对于使用分布式数据库作为存储的本体调试系统,即使启动较多数量的job,其调试时间较原系统中较少数量的job依然具有很大的优势,是优化前用时的15%~25%.

图3 压缩前后存储对比Fig.3 Storage comparison before and after compression
5.3 增量更新算法实验结果
测试增加的数据量为10条公理,增加新的公理后完全重新推理用时与使用本体增加算法用时的对比如图5所示.另外在LUBM-10数据集上进行了3组对比实验,分别增加原数据集的5%、10%、20%,实验结果如图6所示.这两个实验表明动态更新算法比重新推理更为有效.
删除算法需要一次缓存调试信息的过程,删除算法所用时间与重新推理所用时间对比如图7所示.结果表明,使用删除算法比完全重新推理具有明显的速度优势,并且随着数据量的增加,优势在慢慢变大.但是缓存全部调试信息的时间会随数据量的增大明显增加.另外在LUBM-10数据集上进行了3组对比实验,如图8所示,分别删除原数据集的5%、10%、20%,和重新推理用时进行比较,发现在删除本体数量超过原数据集的20%时,重新推理的速度便优于删除算法了,因而在少量本体数据删除时使用该算法会更加有效.
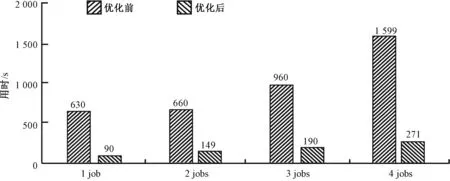
图4 本体调试用时对比Fig.4 Ontology debugging time comparison
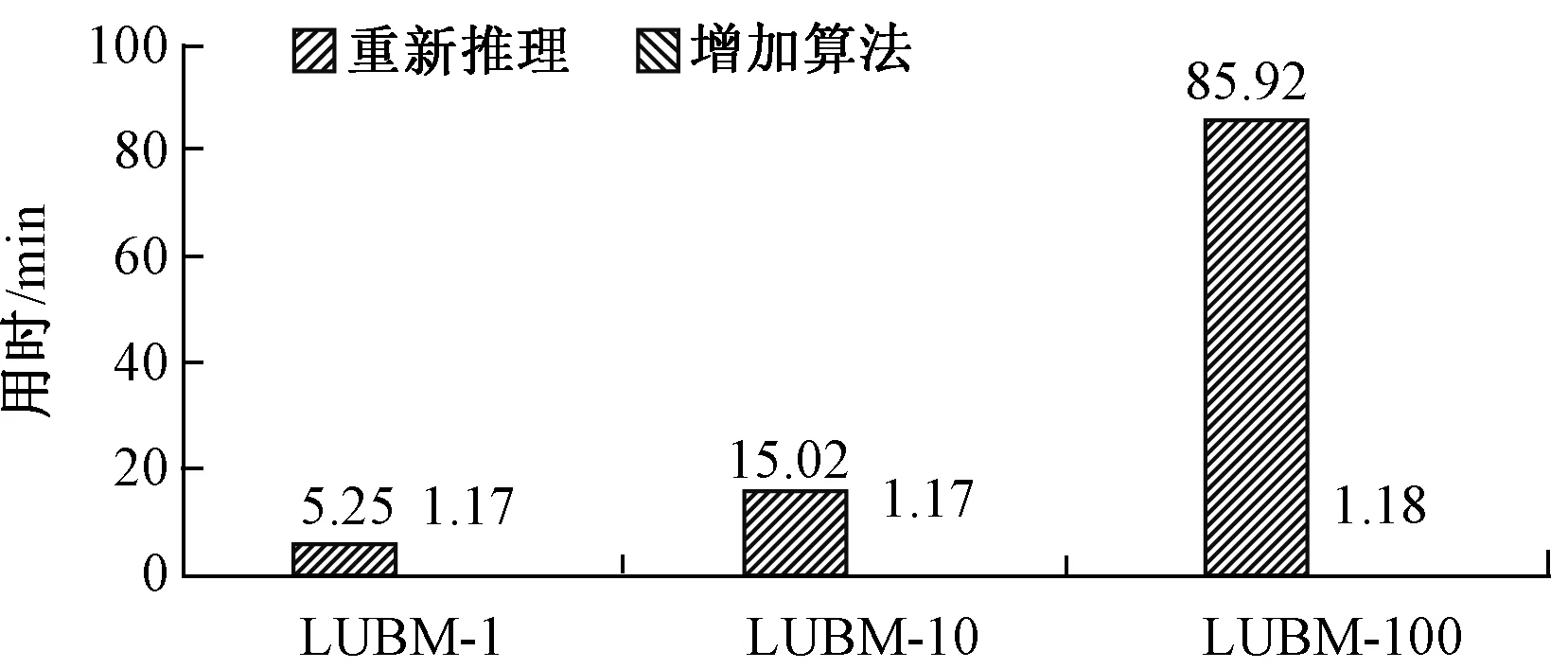
图5 不同数据集上增加算法对比Fig.5 Increase algorithm comparison on different datasets

图6 LUBM-10数据集上增加算法对比Fig.6 Increase algorithm comparison on LUBM-10 dataset

图7 不同数据集上删除算法对比Fig.7 Delete algorithm comparison on different datasets
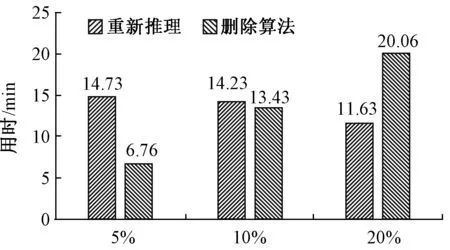
图8 LUBM-10数据集上删除算法对比Fig.8 Delete algorithm comparison on LUBM-10 dataset
6 小结
通过设计分布式数据库作为存储模式来提高本体调试的速度,本体修改后对本体数据进行了增量式更新,LUBM数据集的实验结果表明该增量更新算法是有效的. 针对本体调试信息呈现给用户的方式仍有不足,对辩解集合进行求解后,返回的结果是以三元组集合的形式呈现,当调试信息较多时,用户无法判断哪些调试信息更重要.因此,可进一步通过设计衡量调试信息重要性或相关性的算法,对调试信息进行度量,同时实现Top-k算法,返回经过排序的调试信息,从而改善用户体验.
