基于Linux的开放式数控系统译码解释器的研究
2018-11-05黄继威林述温周小宇
黄继威,林述温,周小宇
(福州大学 机械工程及自动化学院,福建 福州 350116)
0 引言
开放式数控系统的出现为智能数控技术的发展创造了有利条件。坚持走数控系统开放化的技术路线,跟踪掌握数控技术的最新进展,解决其中的关键技术,有利于为新一代国产开放式数控系统的研制打下坚实的基础[1-2]。解释器是数控系统的核心部分之一,数控系统解释器通过获取ISO标准的数据指令,并将其转换为内部命令用来控制机床和执行数控系统的辅助功能。数控机床采用G代码来完成这些操作[3-4]。如何准确、高效地对数控程序代码进行译码就成为数控系统开发过程中的关键问题。
鉴于高速高精、大数据量处理要求和开放式数控系统发展趋势,基于Linux平台开发了一种低成本、柔性化、可配置的开放式数控系统。现有的数控译码解释器进行译码的方式主要有两种:编译式译码和解释式译码。编译式一次性解析所有加工程序,速度快,但占用较大的系统资源。解释式每次只解析一段加工程序,结构简单,要求译码速度足够快以满足后续插补模块对加工数据的要求,这种方式对实时性的要求较为苛刻。
为满足本数控系统粗精异步插补的需求,实现高速高精运动控制,通过对以上两种方式的分析,结合其各自的优点,采用缓冲区中断机制进行分段预读译码,避免了资源浪费和实时性要求高的问题,并开发不同类型的五轴译码解释器以满足数控系统的可配置功能要求。
1 译码的层次结构及译码方式的选择
目前,国际上通用的数控机床的加工程序主要基于标准 ISO 6983 的G、M代码语言编写而成的。最常用的程序段字地址格式如下所示:
Nxxx Gxx Xxx Yxx Zxx Fxx Sxx Txx Mxx
1.1 译码的层次结构
解释器译码流程如图1所示。首先,在本数控系统中数控程序的文件格式为***.ncc,解释器识别该格式文件的并初始化寄存器,然后逐行读取数控程序代码文件,经预处理过滤去除掉多余的注释信息和空格,得到有效的字符程序段;接着执行词法分析和语法分析,若出现错误则返回错误编号进行错误处理并在人机界面显示错误信息,否则,将计算结果保存在预读寄存器中。若有刀具补偿指令就调用刀具补偿模块进行刀具补偿;计算并将底层控制指令存储到执行寄存器中,最后将指令添加到命令缓冲区中,若命令缓冲区的数据未达设定的值,那么就继续读取下一行数控程序代码,若缓冲区已满,则译码模块处于等待状态,等待任务管理器的再次调用。
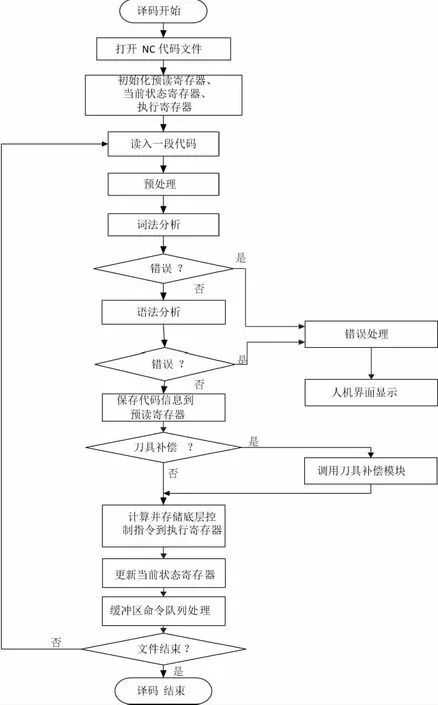
图1 数控程序解释器译码流程
1.2 译码方式的选择
编译式译码是一次性地将加工程序进行译码工作,译码完成后得到的数据全部交给后续模块。当代码量大时,一次性地将代码进行译码处理需要耗费较多时间,对系统实时性要求较高,增加系统成本。
解释式译码是将一行的数控程序代码作为每一次译码的处理对象,完成当前代码行的译码后,立即将译码数据交由后续模块进行处理,机床执行动作,如此往复,直至整个代码文件翻译完毕。整个译码的过程是以串行方式运行,译码模块必须为插补模块及时提供足够的数据,如果某条指令译码过程耗费的时间比较长,而插补模块已无数据可用,就会造成数控机床短时暂停。
经过对编译式和解释式的分析比较,提出了中断型预读译码方式。如图2所示,首先在数控系统中设置预读段数(M+N),数控加工时,译码模块先读取(M+N)段代码,并将译码后的数据按顺序存储到轨迹命令环形缓冲区中,但执行完N段数控代码后,产生中断命令,系统再次调用译码模块进行译码,确保缓冲区不被插补模块读空,保证插补模块运行的连续性。
为了确保命令的连续性,本研究中的M值由前瞻速度处理段数决定,为了使得指令获取命令队列连贯,实验中的N选取为M的2倍;由于本数控系统前瞻速度处理段数为7,故设置1个先进先出的环形缓冲区,该缓冲区大小为21,缓冲区的管理采用指针来实现。当人机界面调用译码子模块进行加工前轨迹模拟时则采用类似于编译式译码方式逐段解析全部的数控代码,但解析一行代码后的数据并不进行存储,而是直接将数据送到加工仿真界面进行显示,如此反复直到所有刀位点连接为加工轨迹,提前检查加工轨迹的正确性。
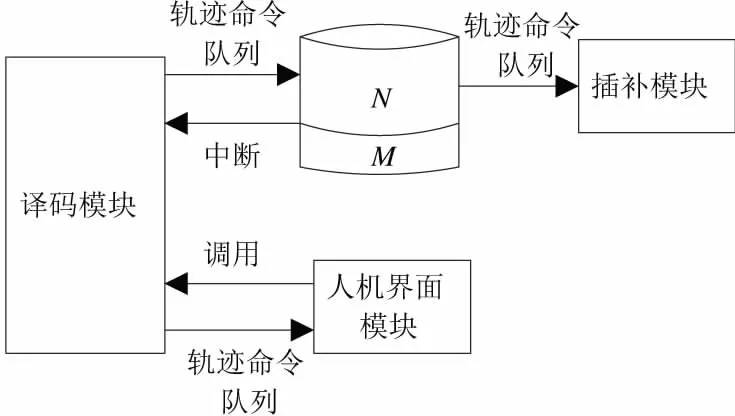
图2 中断型译码机制
中断型预读式译码的核心思想就是在数控加工流程中在译码模块数据生产和插补模块消费之间设置一定的缓存区,并采用中断机制,用缓存区的空间占有和中断机制来降低译码模块和插补模块的同步要求,加大操作时域裕度,避免了整体式译码引起的系统资源浪费问题,并且克服了解释式译码由于实时性差造成的译码数据获取不连贯导致数控机床短时暂停的问题,提高了系统的运行效率。
2 数控程序解释器的设计与实现
在解释器中,设计了3个寄存器用于存储译码数据。按照数据流方向分别为数控代码预读寄存器、当前状态寄存器和执行寄存器,这3个寄存器用来存储解释器执行过程中产生的所有译码数据。其中,预读寄存器是用来存储将要执行的下一行的数控程序代码;当前状态寄存器是用来存储当前数控系统的运行状态信息;执行寄存器是用来存储已完成分类封装的可以用于控制层执行的底层控制指令。
1) 预读寄存器
如图3所示,预读寄存器中主要用来存储经过词法分析和语法分析后,提取一行数控程序代码的有效加工信息,存储一行数控程序中出现的所有词并保存相应的参数数值。在数控程序语言中最小的语法单位是一个“词”,一个G代码、M代码、轴坐标或者其他加工参数都称为一个词。并且当前程序段的代码、程序段说明等也将进行存储,并保留了当前有效模态代码、代码和运动代码的空间。由于在一行数控程序中所有的词不太可能同时出现,因此在数据结构中一个词对应着两个不同的变量,开关类型的变量表示该词是否出现,参数类型用来保存相应的参数值。
预读寄存器中存储的代码段结构体CNC_LINECODE_STRUCT的基本定义如以下代码所示:
typedef struct CNC_LINECODE_STRUCT
{
int nNumber; //行号
int gCodes[G_GROUP] ; // 存储G代码
int mCodes[M_GROUP] ; // 存储M代码
ON_OFF aFlag; //是否有A坐标值的标志
double aNumber; // A坐标值
…
char comment[COMMENT_LEN] ; // 存储程序段注释
}LineCodeStruct;
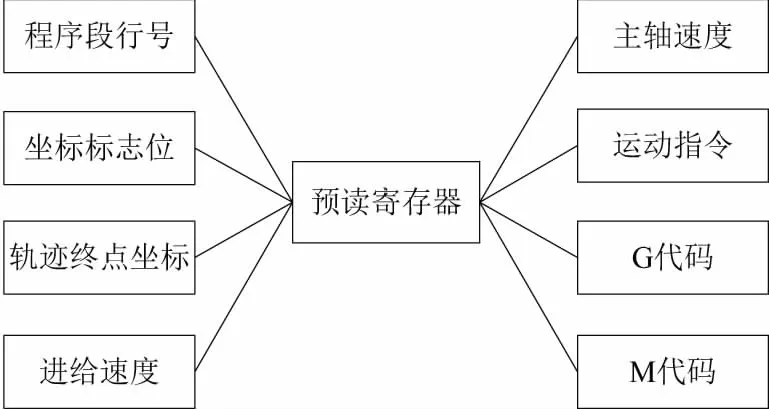
图3 预读寄存器结构
2) 当前状态寄存器
如图4所示,当前状态寄存器是一个用来存储解释器的全局信息和所有加工参数的全局数据,解释器内所有模块都将对该数据进行相应的操作。主要的数据有:G代码文件名、当前有效的模态G代码和M代码、加工点的当前坐标、当前编程坐标系原点偏移、刀位点所处平面等主要信息。
与该寄存器相对应的当前状态数据结构体CNC_SETTING_STRUCT的基本定义如下:
typedef struct CNC_SETTING_STRUCT
{
char filename[NAME_LEN] ; // 程序文件名
int gCodes[G_GROUP] ; // G代码
int mCodes[M_GROUP] ; // M代码
double xCurrent; // 加工点当前x坐标
…
double xOriginOffset; //编程坐标系原点x轴偏移
ACTIVE_PLANE plane; //刀位点所处平面
}SettingStruct;
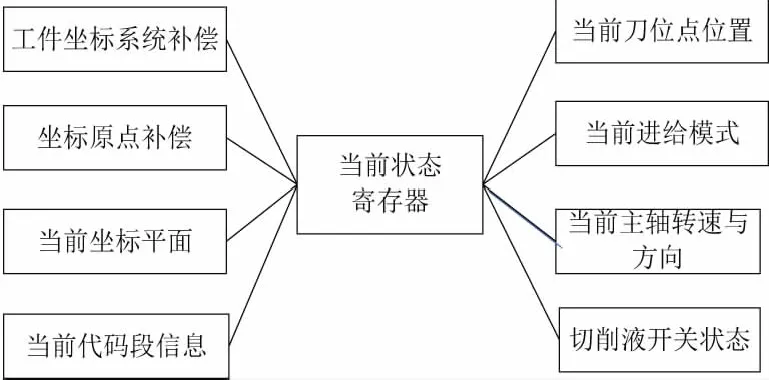
图4 当前状态寄存器结构
3) 执行寄存器
如图5所示,执行寄存器中主要存储控制层可以直接识别并执行的命令消息,解释器执行过程中通过NML提供的append(NMLmsg) 函数将命令消息送到执行寄存器中。其主要存储了直线运动指令、圆弧运动指令、延时指令、换到指令、开关量控制指令等。以圆弧运动指令为例,
class CNC_TRAJ_CIRCLE_MOVE:public CNC_TRAJ_CMD_MSG
{
public:
CNC_TRAJ_CIRCLE_MOVE():
CNC_TRAJ_CMD_MSG(CNC_TRAJ_CIRCLE_MOVE_TYPE,
sizeof(CNC_TRAJ_CIRCLE_MOVE));
void update(CMS * cms); // 状态更新函数
PoseStruct endPt; //圆弧终点
CartesianStruct center; //圆弧圆心
CartesianStruct normal; //圆弧法向
int turn; //圆弧方向
int type; //圆弧类型
double vel,maxVel,acc; //速度,最大速度,加速度
};
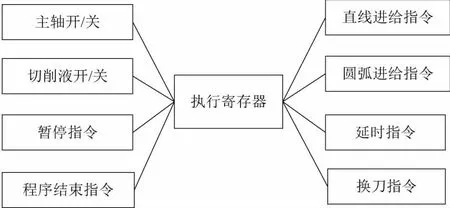
图5 执行寄存器结构
3 解释器测试验证
在Linux系统平台上,搭建了基于PC+可编程IO卡的开放式数控系统。基于以上对解释器译码的研究,对解释器相应的寄存器、预处理模块、词法分析模块、语法分析模块等进行了扩展,开发了五轴X-Y-Z-A-C型、X-Y-Z-A-B型解释器,用以支持五轴数控系统译码功能,并为数控系统的可配置功能提供配置项。
如图6所示,数控系统解释器正在执行1个五轴数控加工程序的译码。将X-Y-Z-A-C型译码解释器配置到所开发的数控系统中。从图6(a)中可以看出,该数控程序解释编译并未发现错误。而当数控加工程序中出现“B”或“b”时,如图6(b)所示,人机界面中出现错误提示“其他非法的数控代码或符号存在”,并且准确定位到所处行数。这是由于所开发的解释器是X-Y-Z-A-C型的,无法识别含“B”或“b”字符的数控加工程序,所以在词析阶段就显示错误提示。


图6 解释器X-Y-Z-A-C型五轴译码结果比较
同样,如图7所示,在所开发的数控系统中的译码解释器配置为X-Y-Z-A-B型。在图7(a)中该解释器能够识别数控程序中的“B”代码并完成译码功能。在图7(b)无法识别“C”代码,故在人机界面中提示第9行有错误:“其他非法的数控代码或符号存在”。并且系统能够及时地识别出不符合规则的代码段,如第6行错误:“同一行中存在两个字符B”,第8行错误:“B字符后面不存在数字”。


图7 解释器X-Y-Z-A-B型五轴译码结果比较
如图8所示,以X-Y-Z-A-C型为例,将译码成功的五轴加工程序输送到加工仿真模块进行模拟仿真。实验结果证明:所开发的解释器符合预期的要求,能够较好地实现五轴数控加工程序的译码并进行仿真加工。
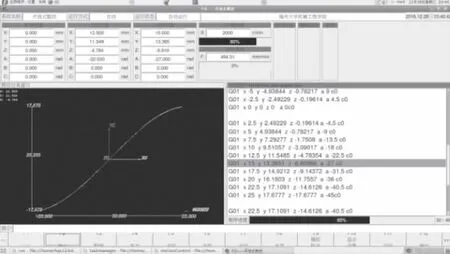
图8 解释器X-Y-Z-A-C型五轴模拟仿真
为了验证本译码解释器能够为后续的处理模块提供正确的译码数据,采用图8中的五轴数控程序,以直线加减速算法为例进行了仿真实验。直线加减速参数设定为:进给速度F为500mm/min,各直线轴的最大允许速度为3 000mm/min,各轴最大加速度为1 000mm/s2。如图9所示为所获得的进给速度曲线图。可知,解释器为后续的速度处理模块提供了正确的译码数据,能够满足数控系统的加工需求。
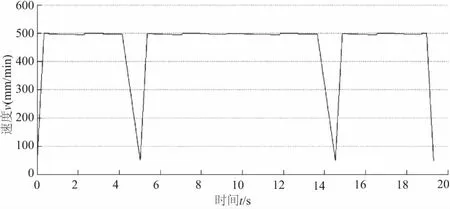
图9 进给速度曲线图
4 结语
基于Linux平台开发了数控程序解释器,该解释器采用缓冲区中断机制进行分段预读译码,避免了PC机资源浪费和由于实时性差导致的指令获取不连续的问题;并且该解释器根据模块化设计思路,采用面向对象技术进行开发不同类型的五轴译码解释器,满足可配置功能需求。程序结构简单明了,代码简洁高效,具有良好的开放性和通用性。经过实验证明,该解释器实现了对数控机床各种指令和功能的正确解释译码,完全可以用于计算机实际加工和仿真。该编译器在开放式数控系统的开发、可配置功能的实现和数控虚拟仿真软件的开发方面有很好的应用前景。
