基于Lucene的多源数据全文检索的研究与实现
2018-08-22邱敏明任洪敏顾利军
邱敏明,任洪敏,顾利军
(上海海事大学信息工程学院,上海 201306)
0 引言
在当今社会,软件开发的速度、规模都在快速提升,软件开发过程中产生的文档无论是文档的存在格式还是存储方式都存在着各种方式。在文档的格式层面有.doc、.docx、.pdf等;在存储方式层面,有存储在本地磁盘的、MySQL数据库、Git仓库等几种方。这些文档就是检索系统的数据,文档的存储地方则是检索系统的数据源。如何从多种数据源中快速有效地检索到期望的数据,这点在企业日常的开发中日益受到重视。
由于数据的多样性,这里的多样性不仅仅是数据之间的格式差异,也包括了不同数据的不同属性,同时也还有数据存储方式的差异性。所以对索引的创建提出了较为苛刻、复杂的要求。基于Lucene的全文检索系统,通过使用Lucene提供的接口,提出了利用XML配置文件的方式来降低数据多样性带来复杂度,同时通过配置文件来实现检索的多样性的方式。系统还针对如何保证检索结果的准确性和有效性的问题,提出了通过注册监听服务的方式,来即时获取数据的变化,再根据这些变化即时调整相关的索引,以此来保证索引的有效性。
1 系统模型
1.1 Lucene简介
Lucene是一个高性能的Java全文检索工具包而不是完整的全文检索引擎,它提供了完整的查询和索引引擎以及部分的文本分析引擎。
Lucene具有如下突出的优点:
(1)索引文件格式独立于应用平台。
(2)它提供了一套强大的查询引擎,Lucene的查询实现中默认实现了布尔查询、模糊查询等,开发人员可以使用这些查询接口。
1.2 系统模型
基于Lucene的全文检索系统将主要用于提供文档的快速检索,这些文档的来源主要是本地的文件系统、MySQL数据库以及Git仓库。图1展示了系统的主要结构。
系统主要由四个部分构成,一是数据获取模块、二是索引创建模块、三是检索模块、四是数据展示模块。该系统将作为一个独立的检索工具为用户提供简单有效的文档检索工具。
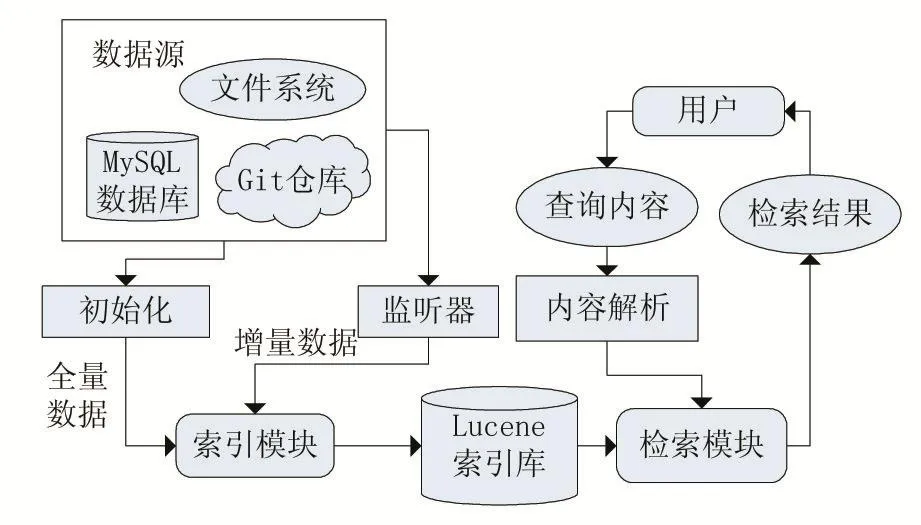
图1 系统结构
2 索引创建
2.1 Lucene及其索引文档
首先需要了解需要用到的Lucene的索引。
●文档(Document):文档在索引和搜索的时候都会用到,是索引和搜索的基本单位(类似于关系数据库关系表中的记录),在搜索的时候根据这些内容进行匹配,找到的也是一个个匹配的文档,然后再从文档中找出需要的内容,进行还原。
●域(Field):域是文档中真正用来匹配的东西,Lucene中文档是由域构成,每个域都有其名称、类型和值。
●分析器(Analyzer)/词元(Term):
分析器同样是在索引和搜索的时候都需要用到,分析器是把原始文档(或者用户输入)解析成一个个的词语(称为词元),Lucene的索引就是一种倒排索引的结构,存储的是从词元到文档的映射。原始文档通过分析器转换成词元然后将词元和文档的映射关系存储为索引,用户搜索时分析器将用户的输入转换为词元然后到索引中去查找匹配的文档。图2是各个类型的文档创建索引的过程,主要包括,读取文档、解析文档、再将解析的文档利用Lucene进行索引创建。这个过程其实就是将普通的文档转换成Lucene能够识别的文档。

图2 索引创建流程
2.2 索引模型设计
通过XML的Schema和Lucene的索引文档格式的比较,为检索系统设计了如下Schema模型:

图3 XML Schema模型
这样设计可以达到以下几点效果:
(1)可以对文档按所属项目进行分类,实现分类检索;
(2)实现索引内容的可配置化,降低对不同格式文档创建索引时的复杂性;
(3)可以数据根据数据来源库进行分类,利于显示数据来源;
(4)实现索引内容的可配置化,灵活调整需要索引的库、表、字段;
(5)实现数据读取自动化。
2.3 索引创建
在完成索引模型设计之后,通过调用Lucene提供的索引创建API,即可完成索引工作。在索引创建的过程中,有一步很重要的工作,那就是“分词”。
分词主要是将一段语句进行切分,例如“我是一个学生。”这句话可以被切分成“我”、“是”、“一个”、“学生”这几个词。然后系统就将这几个词作为“Term”保存在索引文件中,因为Lucene索引文件中的最小单位是词元(Term),在检索的时候其实也是匹配词元的。
基于Lucene的多源数据全文检索系统采用的是IKAnalyzer这一分词器,而并非是Lucene提供的Smart ChineseAnalyzer。图4是两个分词器对于同一段语句的分词结果。
可以看出Lucene自带的Smart ChineseAnalyzer在切分语句中包含的英文单词时,英文单词被切分后与原单词出入较大,相比IKAnalyzer则没有出现该问题,并且IKAanlyzer有着其他好处:
(1)IKAnalyzer可以设置切分粒,支持细粒度分词;
(2)实现了Lucene的分词接口的同时也支持独立分词系统;
(3)可以配置自己的语境字典,策略很随意。
3 索引数据的实时更新
索引文件的准确性是保证检索结果有效性的关键,在数据源中数据发生改变但未更新索引文件时就会导致检索的结果不准确。所以基于Lucene的全文检索系统采用了数据订阅与消费组合的模式来处理增量数据,以此来保证索引文件的有效性。
3.1 增量索引
在上一节中提到的索引创建过程,是用于系统初始化时创建索引的,这种方式称之为全量索引。但在系统开始运行后,若有新的文档被添加到数据源或原有文档数据在数据源中发生更改,为了保证用户检索结果的准确性,必定需要更新原有的索引。如果还是采用全量索引的方式来更新,就会存在以下几点缺点:
(1)耗时长。创建索引所消耗的时间主要取决于带索引数据的量,在大数据量的情况下,索引创建将消耗大量时间;
(2)检索结果准确性不受保证。若原有数据已发生改变,但全量索引还未完成,那么这时的检索结果将会显示数据未更新时的状态,那么检索结果就不是正确的。
正是以上缺点,基于Lucene的全文检索系统采用增量索引的方式来更新索引。
增量索引,即,对新增的数据进行索引。这里新增的数据并不仅仅只限于“Add”操作产生的数据,同时也包含了“Update”和“Delete”操作带来的数据变更。系统对些变化了的数据进行索引更新处理,这样就能保证检索结果的正确性。由于这些数据变更操作主要是来源于其他应用,同时,该检索系统是作为独立的检索工具来使用,要求对其他应用的依赖性和侵入性有很好的控制,所以检索系统采用了以下的模式来实现增量索引。
3.2 数据订阅与消费模式
数据订阅与消费,分为数据订阅和数据消费两个动作。数据订阅主要是用来捕捉变化的数据,数据消费是指将获取到的变化了的数据进行索引。这完成两个步骤即可实现所需的增量索引。
(1)数据订阅
对于本地文件系统,系统采用Java Listener监听器的方式,对目标目录进行监测,当有文件变动时就会捕捉到变动的文件以及具体的变动形式。
对于MySQL数据库,通过注册监听服务,并解析其二进制文件的方式来获取数据库中的数据变更。
对于Git仓库,利用Git Hooks可以及时得到仓库内文件的变更。当有Git的提交操作时,通过Hooks就能抓取到操作的内容。
通过这三种方式就实现了对不同数据源的数据订阅操作。通过订阅数据的方式来实现增量索引可以在减少检索系统对其他系统的侵入性和依赖性。

图4 分词结果图
(2)数据消费
数据消费是指系统的索引服务将获取到的增量的数据进行转化从原始的格式转换成Lucene可识别的索引文件。这个过程亦可称为增量更新。这样保证了索引文件的准确性,在一定程度上实现了索引的实时性,同时不会对原有的索引文件有太大变动,不会对整个系统的检索的服务产生较大影响。图5展示的是系统采用的数据订阅与消费模型。

图5 数据订阅与消费模型
4 检索及检索结果
4.1 多样化的检索
基于Lucene的多源数据检索系统提供了多种检索方式有常见的模糊检索也有精确检索。迷糊检索提供的是广而全的检索结果,精确检索提供的是细而精的检索结果。
(1)建立制造业企业分类目录,推动劳动密集型制造业转移、转型或退出。政府应顺应劳动力成本上升的形势,科学地建立制造业企业分类目录,依据所建立的目录推动劳动密集型制造业转移、转型或退出,改变制造业企业的“粗放型”发展方式,引导制造业结构优化。
(1)模糊检索
模糊检索是检索系统最基本的检索功能,系统会将获取到的待检索内容在系统的三个数据源的索引文件中进行检索,这样的模糊检索就类似于SQL语句中用“like”关键词一样,只要包含了搜索关键字的数据,都被检索出来。
(2)精确检索
基于Lucene的多源数据检索系统也提供了精确检索的功能。由于检索粒度相较模糊检索会小很多,所以检索结果的量也会小很多,主要是针对精细化检索。
4.2 检索的实现
检索总的来说其实就是从Lucene的索引文件中搜索的与关键字匹配索引记录的操作,但这一步操作可以细分成多个步骤。
第一步是将检索内容进行分词,这一步也是整个检索的关键一步,目的是将长句进行切分,以此获得Lucene索引的最小单位“Term”,然后再按最小单位保存在索引文件中。所以检索时也需要用相同的分词器将页面输入的待检索值进行分词,如果不是用相同的分词器,对相同内容的切分结果或许会有不同,那么就会导致待检索内容和索引文件里面的关键字不匹配,这样就导致了检索结果不正确,所以必须使用和创建索引时相同的分词器。
第二步是将经过处理的检索内容和现有的索引文档进行比较得到与检索内容相关的索引文档。
第三步是将获得的索引文档按照相关度进行打分。在给索引文档打分的过程涉及到一个很重要的步骤,那就是计算权重(Term weight)。计算权重是指找出词(Term)对文档的重要性的过程称。影响一个词(Term)在一篇文档中的重要性主要有两个因素:
(1)Term Frequency(TF):即此 Term 在此文档中出现了多少次。TF越大说明越重要。
(2)Document Frequency(DF):即有多少文档包含次Term。DF越大说明越不重要。
如果词(Term)在文档中出现的次数越多,说明此词(Term)对该文档越重要,如“搜索”这个词,在本文档中出现的次数很多,说明本文档主要就是讲这方面的事的。然而在一篇英语文档中,this出现的次数更多,就说明越重要吗?不是的,这是由第二个因素进行调整,第二个因素说明,有越多的文档包含此词(Term),说明此词(Term)太普通,不足以区分这些文档,因而重要性越低。Lucene就根据这两个因素,设计了给索引得到的文档进行打分的计算公式:
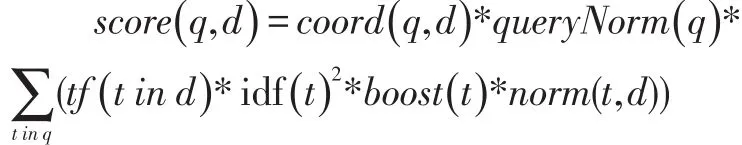
其中 queryNorm(q):queryNorm(q)是查询权重对得分的影响,这个因素对所有文档都是一样的值,所以它不影响排序结果;
tf(t in d):即term t在文档d中出现的个数;
idf(t):关联到反转文档频率,文档频率指出现term t的文档数docFreq。docFreq越少idf就越高(物以稀为贵),但在同一个查询下些值是相同的;
boost(t):查询时期term的加权,这个就是一个影响值;
norm(t,d):这个项是长度的加权因子,目的是为了将同样匹配的文档,比较短的放比较前面。
最后按照文档得分进行排序,得到了索引结果顺序。图6为系统运行结果图,搜索包含“上海海事lucene”的文档,最终搜索结果如图6所示。
在检索服务刚启动时,由于不可避免的文件的I/O操作导致了耗时增加到500毫秒左右,但再进行检索时,检索耗时可降低到100毫秒左右,整个的效率还是很可观的。
5 结语
基于Lucene的多源数据检索系统提供了快捷方便的文档检索操作,提供了多样化的检索方式。同时由于采用可配置划的方式来实现索引创建工作,使得整个系统更加方便,且易维护,而且实现了对于第三方程序最低程度的依赖和侵入性,实现了较高的独立性。
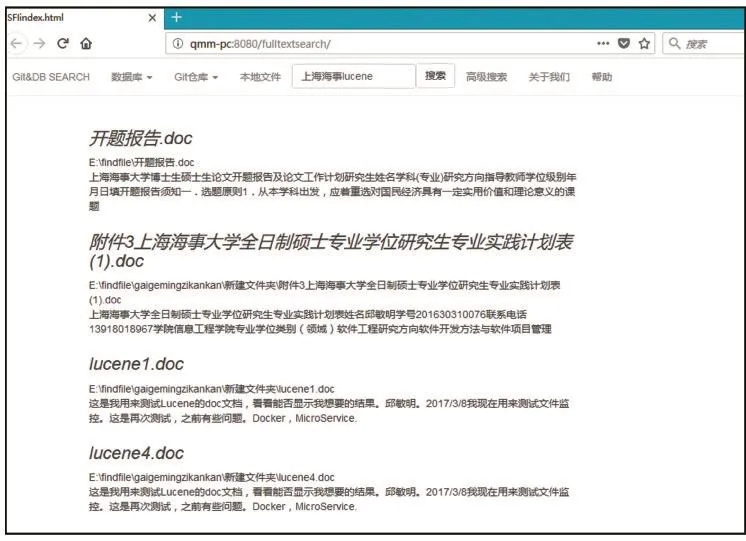
图6
