基于大数据不平衡样本集的重采样方法及应用
2018-08-22汪海涛余永奎段春雨
汪海涛,余永奎,段春雨
(广东电网有限责任公司中山供电局,中山 528400)
0 引言
在电力生产及运行维护的安全监督管理中,将电力事故事件分为设备事故和人身伤亡事故两大类。近年来,随着电力设备可靠性的不断提高,人的不安全行为(违章)成为电力事故事件的主要风险源。揭示人的不安全行为与电力事故事件的内在关系及规律,进而开发出电力事故事件的预控模型,对电力事故事件防范于未然及提高电力企业安全生产具有重大的意义。
电力生产及运行维护中人的不安全行为俗称为违章,而导致违章的因素很多,诸如人员本身因素、自然环境因素、作业复杂程度因素、作业工器具因素以及安全管理因素等。要从这种数据规模体量巨大以及种类繁多的浩瀚违章大数据中去发现人的不安全行为与电力事故事件的内在关系及规律,并非一件容易的事。可以说,靠传统的统计分析方法和技术完成此类工作显然是力不从心的。因此,探讨应用大数据分析中的数据挖掘技术以及机器学习方法求解这类问题便成为目前的主要研究途径,其研究价值和意义是显而易见的。
机器学习方法中具有代表性的方法是聚类和分类,如果提供给机器学习的大数据样本集是不平衡的类样本,即正类和负类的比例差距悬殊,则用机器学习算法开发出来分类模型便会出现偏差和不可用,原因是机器学习算法往往是通过减少误差来提高准确率的,而忽视了样本类别的分布比例及类别平衡。例如,假设提供给机器学习的大数据样本集规模为1万个样本,正类样本9900个,而负类样本只有100个,则机器学习算法在保证99%的分类准确率下会对少量的100个负类样本视而不见(误为噪声),这种在不平衡样本集下机器学习得到的分类模型是没有实际应用价值的。
本文以笔者承担的国内某电网公司的“电力事故事件与违章大数据分析及预控模型研究和应用”科技项目为例,对从多个渠道收集到的违章大数据不平衡的样本集,提出一个从不平衡样本集创建一个平衡的类分布样本集的方法,解决电力违章事故事件机器学习分类算法模型中训练样本集的不平衡问题。本文研究的内容及成果,对解决其他行业开发机器学习分类算法模型中碰到的类似问题具有普遍的参考价值和意义。
1 基于增减法的样本数据集重采样[1]
增减法通过增加少数类的样本数量或减少多数类的样本数量实现数据集类别的平衡,平衡分类获得大致相同数量的类实例规模。表1是几种基于增减法的重采样方法比较,表2是电力违章事故事件大数据样本集重采样的实例。
1.1 基于增减法的样本数据集重采样方法比较

表1 几种基于增减法的重采样方法比较
1.2 电力违章大数据样本集重采样实例
用于“电力事故事件与违章大数据分析及预控模型研究和应用”的电力违章大数据样本集共有10300个样本,其中事故事件违章样本=300个,非事故事件违章样本=10000个,事故事件发生率=300/10300=2.9%。
2 机器学习算法分类模型的评价方法
评价机器学习算法分类模型性能的评价方法一般使用如下的混淆矩阵工具:
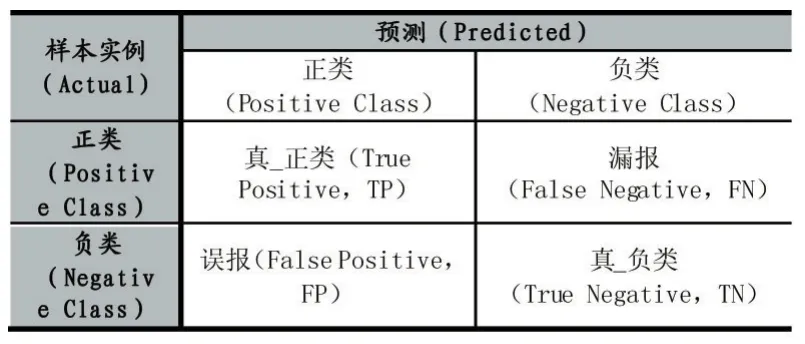
表3
混淆矩阵中各元素的定义是:
真_正类(True Positive,TP)是指属于类别 C 的样本实例而被分类成类别C;
漏报(False Negative,FN)是指属于类别C的样本实例而被分类成非类别C;
误报(False Positive,FP)是指非类别C的样本实例被分类成为类别C;
真_负类(True Negative,TN)是指不属于类别C的样本实例而被分类成不属于类别C。
评价机器学习算法分类模型性能通常使用下述三个指标:
分类模型的准确率=(TP+TN)/(TP+FN+FP+TN);
分类模型的精度=TP/(TP+FP);
分类模型的召回率=TP/(TP+FN)。
对于不平衡样本集的数据挖掘,如果不做平衡处理,则使用准确率指标评价分类器模型的性能是不恰当的。例如,决策树和回归等分类器模型分类性能会偏向于样本数量多的类别,而忽略样本数量占少数的类别,这就会使分类器模型对少数类的误判率会较高。当样本集少数类与多数类的比例严重不平衡时,例如2%比98%的情形,分类器模型把所有样本分为多数类,其准确率也达到98%,占2%的少数类样本被视为噪声而忽视。因此,评价分类器模型的性能应该综合考虑准确率、精度和召回率多个指标。
3 结语
在大数据分析研究领域,选择性能好的机器学习算法设计分类模型,往往是建立在多个机器学习算法预测性能的比较分析的基础上的。对大数据不平衡样本集进行平衡处理后,用作多个机器学习算法的训练样本,使这些机器学习算法的预测性能可以进行比较,从而为选择机器学习算法设计分类模型提供辅助决策信息。
我们在“电力事故事件与违章大数据分析及预控模型研究和应用”科技项目中,分别应用本文讨论的5种重采样方法,对电力事故事件大数据不平衡样本集进行平衡处理,并应用到目前流行的多个机器学习算法的训练学习中,为项目设计电力事故事件预控模型提供了有价值的辅助决策信息。本文阐述的研究方法,对大数据分析及机器学习算法分类模型的研究及应用具有普遍的参考价值和意义。
