基于深度神经网络的推荐算法
2018-08-22程磊高茂庭
程磊,高茂庭
(上海海事大学信息工程学院,上海 201306)
0 引言
互联网时代的飞速发展,为人类的信息共享提供便捷的同时,也带来了信息过载的问题。为了解决此问题,推荐系统应用而生,如今在各种领域得到广泛应用,例如电子商务、信息检索、社交网络、信息服务和新闻推送等。推荐系统通常是根据用户的历史记录进行推荐,其中推荐算法显得尤为重要,目前主流的包括协同过滤、基于内容和混合的推荐算法[1]。近年来深度学习已经成功应用于推荐领域。
深度学习是通过组合低层的稀疏特征形成高层稠密的语义抽象,从而挖掘数据的特征表示。深度神经网络(Deep Neural Network,DNN)是深度学习的一个学习模型,在较多领域上具有很高的推荐准确度。刘帆[2]等人将DNN用于图像融合,通过DNN提取低频子带的特征,并通过隐藏层的权值识别低频子带分量。王昕[3]等人将DNN应用到语音识别的邻域,DNN通过拟合噪语音和纯语音之间的非线性关系,得到纯语音的近似表征,达到降噪的作用。陈春利[4]等人将DNN进行改进,提出一种堆叠深度信念网络,通过探讨隐含层参数、迭代次数和学习率来将DNN用于信号分选,从而提高了分类的准确率。赵红燕[5]等人将DNN用于汉语识别,通过利用DNN自动学习目标词的上下文特征建立了一个汉语框架识别模型。张艳[6]等人将DNN用于DNA位点的选择,使用DNN构建数据分析模型,实现了致病位点与疾病的关联分析。万圣贤[7]等人将DNN用于微博情感分析,将微博中的文本输入到DNN中,经过处理后对文本进行分词,提高了分类的准确性。陈耀旺[8]等人将DNN用于个性化游戏推荐,通过分析用户的偏好及时间推移兴趣建立训练集,通过DNN进行建模分析,提高了推荐准确度。
本文将深度神经网络用于推荐算法,对用户的项目评分和项目类型进行分析,提出一种基于深度神经网络的推荐算法。该推荐算法是一种基于内容的推荐[9],主要根据项目的评分和项目的类型,挖据项目类型上的相似性给予推荐,相比于协同过滤,该推荐算法不需依赖于近邻用户的评分,只需根据用户个人的评分和项目类型就能产生推荐。
1 相关工作
1.1 深度神经网络
深度神经网络是一组限制玻尔兹曼机组成的层次神经网络[10],其结构如图1所示。
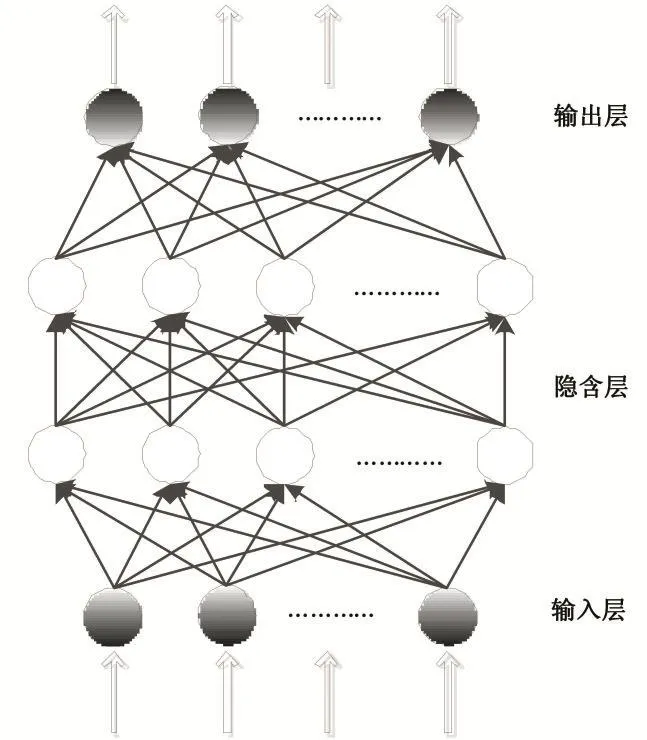
图1 DNN模型图
图1中,DNN是一个层级结构,包括输入层、隐含层(一层或者多层)和输出层。输入层用于接收输入信号,输出层节点用于输出信号。相邻层的节点采用全连接,每个连接都存在一个连接权值,而同一层的节点不存在连接。
1.2 数据说明
数据包括用户项目评分和项目类型,其中,Ui表示第i个用户,Ii表示第i个项目,Ti表示第i个类型。数据格式分别如表1和表2所示。

表1 用户项目评分表
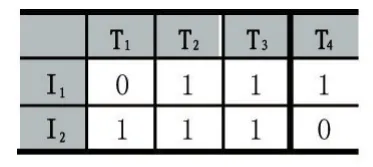
表2 项目类型表
表1中,数字1到5表示用户对项目的存在评分,且评分等级为1到5,等级越高,表明用户对项目越喜欢;数字0表示用户对项目不存在评分。表2中,数字1表示项目属于类型,数字0表示项目不属于类型。
2 基于深度神经网络的推荐算法
推荐算法主要包括离线部分和在线部分。离线部分主要是数据处理和DNN训练,在线部分是实时预测。
2.1 数据处理
DNN训练前,需要对模型输入层和输出层的数据进行处理,并建立一种对应关系。模型输入层的数据为用户项目喜好度,模型输出层为用户项目评分。
(1)输入层数据处理
用户对项目进行评分时,项目的类型起到了一定的引导性作用。例如,用户对不同项目的类型存在不同的喜爱程度,当项目类型中存在用户喜欢的类型时,用户就会给予项目更高的评分等级。通过统计用户评分过的项目数,可以得到用户对于不同项目类型的评分次数,出现评分次数越多的类型,表明用户对此类型的喜好程度越高。
首先,计算用户u对类型t的评论次数,用Sut表示,它是通过用户-项目隶属矩阵ˆ和项目-类型隶属矩阵Iˆ的对应项相乘得到。在ˆ中,当用户u存在对项目 i的评分时,=1,否则=0。同理,在 Iˆ中,当项目 i中属于类型 t时,ˆ=1,否则=0。如式(1):

其中,k表示项目种类数。
然后,计算用户u对所有类型的总评论次数,用Su表示。如式(2):

其中,m表示类型种类数。
最后,计算每个用户u对于项目类型t的喜好度,用 Put表示,如式(3):

(2)输出层数据处理
用户对项目的评分表示了用户对项目的喜好程度,将喜好程度进行编码,如表3所示。

表3 用户项目评分编码表
(3)建立对应关系
将处理后的输入层数据和输出层数据进行汇总,建立对应关系。以U1为例,其训练数据如表4。

表4 关系对应表
2.2 DNN训练
DNN训练前,需要搭建模型并确定方法,模型具体包括一个输入层,两个隐含层和一个输出层。输入神经元的个数为Nin,隐藏层第l层神经元的个数为,输出层神经元的个数为Nout。隐含层采用Dropout策略,激活函数为ReLU,输出层的激活函数为Softmax,代价函数采用分类交叉熵,代价函数的求解方式采用Adam。
模型中隐含层神经元的个数采用Kolmogorov定理,输入神经元数目与隐含层神经元的数目存在等量关系,如式(4):

DNN训练过程中,主要包括以下几个步骤:
线性求和,激活函数,代价函数和代价函数求解。
(1)线性求和
隐含层和输出层中每一个神经元的输入都来自前一层所有神经元输出值的线性加权和,为了防止过度拟合,对输入值采取 Dropout策略[11],如式(5):

(2)激活函数
激活函数是将线性求和的输入值进行非线性映射,使得神经网络具备了分层学习的能力。隐含层中的激活函数采用ReLU,输出层的激活函数采用Softmax,分别如式(6)和式(7):
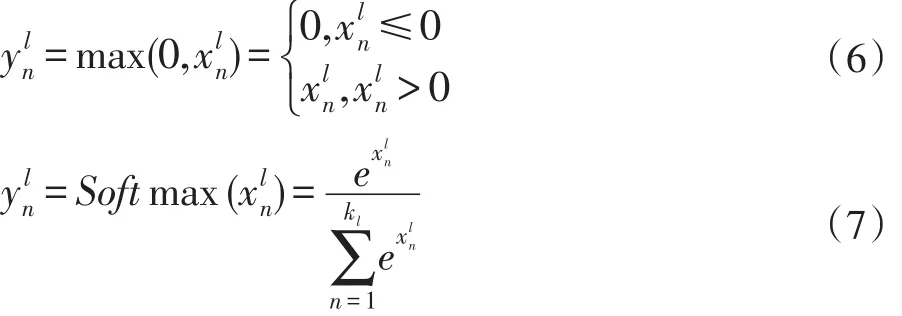
(3)代价函数
DNN接收输入信号并产生输出信号的过程称之为前向传播过程,当得到输出值后需要与实际值进行比对,这时需要代价函数。根据任务的不同,常分为交叉熵准则和最小均方差。在模型中采用交叉熵准则的一种,称为分类交叉熵,其表达是如(8):

其中,Li表示第i个输出值与目标值的差值,tij表示第i个输入信号对应的第 j个实际类,pij表示第i个输入信号对应的第 j个预测类,j表示预测值的类别数。
(4)代价函数求解
代价函数的求解采用Adam算法[12],即自适应时刻估计方法(Adaptive Moment Estimation),它是用来替代随机梯度下降的优化算法,它利用梯度的一阶矩阵和二阶矩阵估计动态调整每个参数的学习率,其中目标函数,一阶矩阵和二阶矩阵的更新参数分别为α,β1,β2。则算法流程如下:
输入:参数 α,β1,β2,目标函数 f(θ)
输出:使得目标函数收敛的θ
执行步骤:
1)Intial:parameter vector:θ0
2)1stmomentvector:m0←0
3)2stmomentvector:v0←0
4)timestep:t←0
5)whileθtnot converged do
6)t←t+1
7)gt← ∇θft(θt-1)
8)mt← β1∙mt-1+(1- β1)∙gt
9)vt← β2∙vt-1+(1- β2)∙g2t
10)mˆt←mt/(1-β1
t)
11)vˆt← vt/(1- β2
t)
12)θt←θt-1-α∙mˆt/(ˆ- ε)
13)end while
14)return θt
2.3 实时预测
DNN训练结束后,确定最佳的模型参数,即可得到最佳模型。当加入新项目时,将目标项目先进行数据处理,然后经过模型训练,便得到预测结果。对于预测后的结果,按照表3进行反编码,即可得到目标用户对目标项目的预测评分pui。
3 实验结果分析
3.1 实验数据集和实验环境
实验数据集采用MovieLens 100K数据集,它包含用户对电影的评分和电影的类型。实验数据集采用实验环境为Windows7 x64操作系统,Intel Core i5处理器和8G内存,代码使用Python3.5语言实现。
3.2 实验设置
模型的搭建使用Keras,它是一种基于Theano或TensorFlow的深度学习库、线性求和、激活函数、代价函数和代价函数的求解采用Keras中的默认参数,而剩余的其他参数的设置如表5。
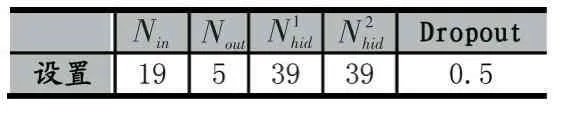
表5 实验参数设置
参数设置完毕后,需要对模型进行训练,模型训练的迭代次数为1000,批尺寸为20,实时保存最佳模型。模型保存后,需要对模型进行测试,采用5折交叉验证,通过均方误差去衡量预测的准确性。
3.3 实验度量标准
本文采用均方误差(RMSE)作为度量标准,它可以直观反映总体预测的误差,如式(9):
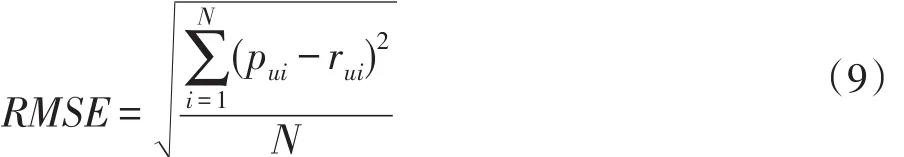
其中,pui表示用户u对项目i的预测评分,rui表示用户u对项目i的实际评分,N表示预测的项目数。
3.4 实验对比
实验对比的目的是确定算法在不同的训练项目数下模型预测的误差变化,从而给出最佳的训练项目数。由于本文推荐算法需要用户有一定的评论项目数才可以给出预测,并且在实际生活中,用户的评论项目数是一个不确定数目,所以设置模型训练的项目数分别为10,20,30,40,50,60,70,模型测试时的项目数均为30,比较在不同训练项目数下,算法预测评分的均方误差,如图2。
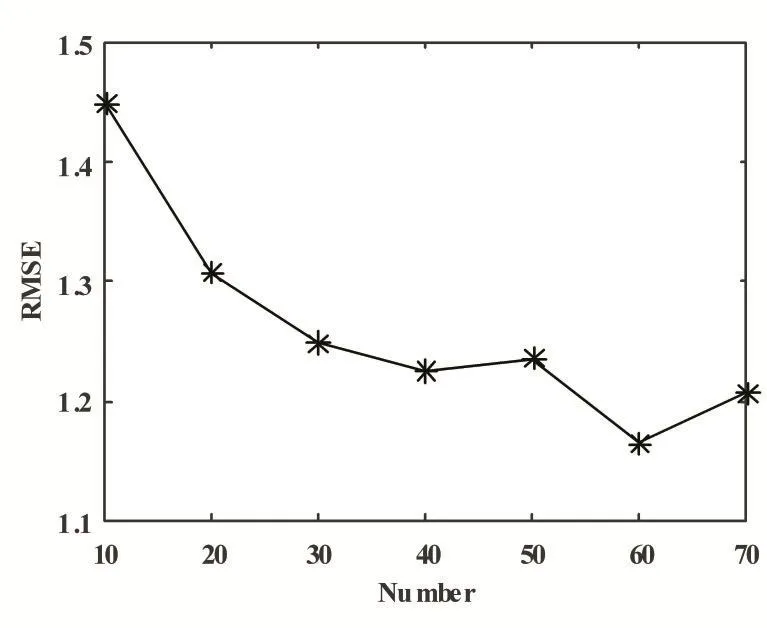
图2 不同项目数下的RMSE值变化
从图2中可以看出,随着模型训练的项目数增加,算法预测评分的均方误差逐渐降低,当模型训练的项目数为60的时候,其均方误差最小。因此,项目数为60时,算法预测的效果已经基本达到最佳。
选取模型训练的项目数为60,进行预测评分实验,当预测项目数为30时,其预测评分与实际评分的对比效果图,如图3。
从图3中可以看出,当模型训练的项目数为60时,算法预测评分的效果已经呈现不错的效果。在30个预测项目中,存在8个项目的预测评分与实际评分存在偏差,而剩余22个项目的预测评分与实际评分完全一致,若从命中率分析,算法的命中率高达73.33%。
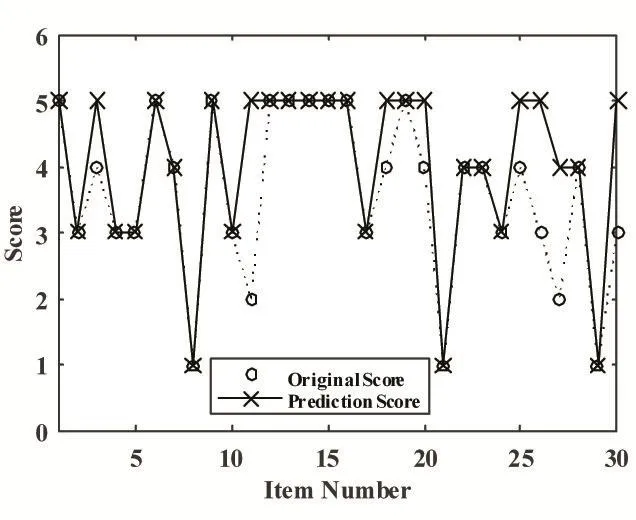
图3 预测评分与实际评分对比效果图
4 结语
本文提出了一种基于深度神经网络的推荐算法,算法不需要依赖于近邻的评分,只需根据项目类型和项目评分产生推荐。在用户存在一定的评分项目数时,利用本文算法可以产生令人满意的推荐效果。下一步将着手于融合用户的评分时间和评论留言,利用CNN或NLP等前沿的深度学习框架产生推荐,提高算法的准确度。
