改进的混合激励线性预测编码算法
2015-07-23朱宗明姜占才
朱宗明,姜占才
改进的混合激励线性预测编码算法
朱宗明1,姜占才2
(1.中国人民解放军69220部队,阿克苏 843000;2.青海师范大学物理系,西宁 810008 )
针对混合激励线性预测编码中子带声音强度的硬判决导致激励源欠精细问题,将子带声音强度视为5维的模糊特征矢量,用改进的LBG算法设计码本并用5bit对其作矢量量化;以精细量化的子带声音强度调制带通滤波器,以此获取精细的混合激励信号,最终达到改善合成语音质量的目标。仿真实验表明:改进算法能有效地改善合成语音的自然度。
低速率语音编码;混合激励;子带声音强度;矢量量化;码本
0 引言
语音编码是语音通信的核心技术,其中低速率编码广泛应用于移动通信、卫星通信、军事保密通信、多媒体存储和数字数据网(DDN)中。语音编码的目的是用尽可能低的比特率获得尽可能高的合成语音质量,其意义是去除语音信号中的冗余,降低传输比特率或存储空间[1]。低速率语音编码分为3类,即参数编码、波形编码和混合编码,其中混合编码兼有参数编码和波形编码的优势,混合激励线性预测编码(M ixed excitation Linear p rediction,M ELP)[2-4]是混合编码的一种经典编码方案。
MELP以线性预测编码(Linear predictive coding,LPC)的参数模型为编码的整体框架,将语音帧的线性预测系数即声道模型参数转换为线谱对参数(LSF)后,用25bit矢量量化(Vector quantization,VQ)后编码、传输。为了克服LPC方案激励源信息描述过于简单、不准确的缺陷,将二元激励改为混合激励来获取更加准确的激励源信息,以混合激励信号激励合成滤波器,明显提高了合成语音质量。
MELP编码方案并非完美,仍在不断的改进中[5]。在进一步降低比特率方面,文献[6]从降低边带信息编码比特入手,将深度学习理论引入参数编码,尝试将LSF参数的传统矢量量化法改为利用深度自编码机直接对语音幅度谱进行编码的新方法,结论是在不降低合成语音质量的前提下,进一步降低了编码速率。
MELP编码方案将语音帧划分为宽度不等的5个子带,分别提取各子带的声音强度,称为子带声音强度或带通声音强度,记为iV¯,其中i=1,2,3,4,5,表示各子带序号,然后将其4bit量化、编码、传输。对子带声音强度的量化结果为非0即1,优点是对运算带来方便、不增加内存空间,欠缺是对各子带的清/浊音仍然执行硬判决。
无论是一帧语音还是一个子带,对其的清/浊音分类采用硬判决都不能准确地描述语音的激励源信息。文献[7]对语音生成模型的激励源提出了模糊激励的概念—浊音隶属度,它是一个5维矢量,其每一分量Vi都是介于0和1之间的数,是一个模糊量。本文将MELP编码方案中的子带声音强度清/浊音硬判决改为模糊判决,以模糊量浊音隶属度调制5通带带通滤波器,以此获得较精细的混合激励源,最终获得较高的合成语音质量,而又不增加运算开销。
1 子带声音强度矢量的提取
用5个6阶的Butterw orth带通滤波器将输入语音帧分为(0-500)Hz、(500-1000)Hz、(1000-2000)Hz、(2000-3000)Hz、(3000-4000)Hz的5个子带;提取某个能够反映子带隶属于浊音程度的归一化特征量V,获得当前帧的子带声音强度[7],表示为:

2 子带声音强度的精细量化
2.1VQ及LBG算法码本设计
VQ是一种高效的数据编码压缩技术,而码本的设计是VQ的关键环节。码本设计的本质是以系统的失真函数最小作为目标,寻求将所有的训练矢量划分为N类的最佳方案,各类的质心就是码本的码字。
码本设计的基本方法是LBG算法,实际上是寻求最佳码本的必要条件的反复迭代过程,即由初始码本开始,使之逐步优化,直到系统性能满足要求或不再有明显的改进为止。基本的LBG算法过程如下:
(1)已知码本尺寸N,给定设计的失真门限ε(0<ε<1),给定一个初始码本yN(0)。已知一个训练样本集[Xj,j=0,1,⋅⋅⋅,m −1]。先取n=0(n是迭代次数),设初始平均失真D(−1)→∞;
(2)用给定的码本yN求出平均失真最小条件下的所有区域边界Si(i=1,2,…,N),即根据最佳划分准则把训练样本集划分为N个胞腔,应使训练样本集的样本Xj∈Si满足条件d(Xj,Yi)<d(Xj,Y) (Y∈y ),由此得出最佳的区域边界S(n )。计算该区域边界下(一次迭代后)参与训练的训练样本的平均失真

(3)计算与前一次迭代的相对平均失真,判断是否满足阈值门限条件

满足上式即为满足设计要求,此时的yN就是设计的码本;如果不满足,进行下一步;
(4)用各胞腔的质心置换各初始码字,构成(n=1)次迭代的新码本,重复前两步,直至满足阈值门限为止。
2.2LBG算法的改进
LBG算法设计码本的过程是一个非凸优化问题,设计过程中有陷入局部最优的可能;若想通过群举码本的全部可能来寻找全局最优码本,在现有计算能力下几乎不可能实现。MELP中LSF参数VQ的码本采用LBG算法,所获得的码本为局部最优或接近全局最优,存在初始码本的选择影响码本训练收敛速度和最终码本性能的缺陷。
子带声音强度作为5通带带通滤波器的调制信号,是获得精准混合激励信号的关键技术,直接决定合成语音的质量,对其应当用VQ技术作精细量化。为了克服LBG算法的缺陷,对其作如下改进:
(1)初始码本的选取:用模糊聚类代替传统的随机选取法,将聚类中心数设为码本尺寸N,在一定规模的训练样本集上作模糊C均值聚类,聚类的结果即为各类的中心,将其作为LBG训练的初始码本[8]。该法选取初始码本有效地避免了随机性和偶然性;聚类结果既是陷入局部最优,对后续LBG算法趋于全局最优的单调性几乎没有影响;聚类结果非常接近设计目标。
(2)在LBG的迭代过程中,每次迭代后都检测、处理空胞腔:码本尺寸是预先确定的,胞腔的数目即为码本尺寸,这就难免每次迭代后划分到某些胞腔的输入矢量较少,这样的胞腔称之为空胞腔。显然,空胞腔的认定与设计码本的尺寸和训练样本集的规模有关:码本尺寸越小、样本集规模越大,自然进入每个胞腔的输入矢量就多,反之,码本尺寸越大、样本集规模越小,形成的空胞腔数就越多。定义胞腔尺寸CZ:平均进入胞腔的输入矢量的最小值,取CZ=200。这一定义对设计尺寸确定的码本,对训练样本集的规模提出了下限。定义空胞腔下限δ:是胞腔尺寸CZ的百分比,设为δ=10%CZ。定义空胞腔:进入胞腔的矢量数小于δ的胞腔。空胞腔必须剔除,方法是:测定空胞腔下限δ并存储;每次迭代后检验中间码本中的空胞腔数;检测同等数目的大胞腔数;删除所有的空胞腔,同时将每个大胞腔分裂为两个胞腔;用处理后的结果替换当前的中间码本,进入判断和下一迭代过程。
2.3子带声音强度码本训练
建立码本训练样本集:分别以31分钟、26分钟和24分钟长度的三段连续语音的录音为语音样本,经8kHz采样、8bit量化、转换为码率为64kb/s的线性PCM码后保存;以帧长22.5ms分帧,提取各帧的子带声音强度矢量[7],建立三个训练样本集YB1、YB2和YB3。最小的样本集YB3的规模是64000×5维,对设计尺寸为128×5的码本,平均胞腔尺寸CZ为500,显然大于最小值200的要求。
将植入空胞腔剔除算法的LBG算法级联到模糊C均值聚类算法之后构成改进的LBG算法(ALBG)。
3 精细混合激励信号的获取
获取精细混合激励信号的实质是对子带声音强度矢量的精细量化,即将MELP编码方案中对各子带声音强度非0即1的硬判决改为即非0也非1、而是介于0和1之间的模糊量的软判决。量化的精确度除跟量化字长有关外,还与量化码本的性能有关。当量化字长一定时,码本的性能决定于训练样本集和训练算法;量化的失真测度在VQ码本训练算法中已选取,本课题选择欧氏距离失真测度;由于子带声音强度码本尺寸(64或32)较小,采用最基本的全局搜索法即可满足搜索速度要求;精细混合激励信号的获取过程如图1所示。

图1 精细混合激励信号获取流程 Fig.1 Acquisition process of accurate mixed excitation signa l
4 算法仿真实验
4.1实验方案
①改进的LBG码本训练算法(ALBG)仿真实验;
②MELP编码方案的改进算法(AMELP)仿真实验。
4.2实验材料(实验用语音样本)
实验用语音取自笔者建立的语音库yyk2.w av,库中语音为8kHz采样、8bit量化、线性PCM编码的数字语音。实验时从语音库随机抽取语音段,也可加入高斯白噪声后形成含噪语音即语音的噪声观测。帧长和帧移都为180点(22.5ms),帧间无重叠。
4.3实验系统(程序)
分别对改进的LBG算法和MELP改进编码算法编程,以文件名ALBG.m和AM ELP.m存盘;在PC机上仿真实验。
4.4实验结果及其分析
4.4.1ALBG算法仿真实验
设置初始误差是一万级的随机数,目标误差(设计精度)ε=0.001;分别训练尺寸为256、128、64、32的4个子带声音强度码本,并且对同一码本依次调用YB1、YB2 和YB3三个训练样本集训练;在23次(至少需要12次)的仿真实验过程中,都无一例外的显示目标函数平滑单调地达到全局最优,迭代次数少,收敛速度快。图2是用YB1训练码本V¯(128)过程中目标函数变化过程图。
4.4.2AMELP仿真实验
(1)码本尺寸选择实验。理论上码本尺寸越大,量化精度越高,但会增加编码比特开销使比特率增大;当码本尺寸增大到一定值时,再增大实际上对量化精度的贡献甚微,因此,码本尺寸(量化字长)的选择应在提高量化精度和控制码率之间通过实验作出折中。
将用ALBG算法训练得到的4个子带声音强度码本依次置换MELP 编码方案中子带声音强度的量化,得到基于子带声音强度码本和量化的4 个AMELP软件声码器,在同一输入语音下,依次收听合成语音,从可懂度和自然度两个方面比较合成语音质量。实验结果表明:当量化字长超过5bit时,对提高合成语音质量的贡献已经不明显。为此,选取子带声音强度码本的尺寸为32×5,即量化字长为5bit。
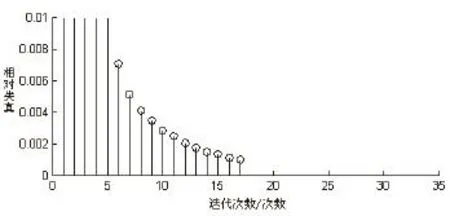
图2 码本训练目标函数变化过程 Fig.2 Objective function change process of codebook training
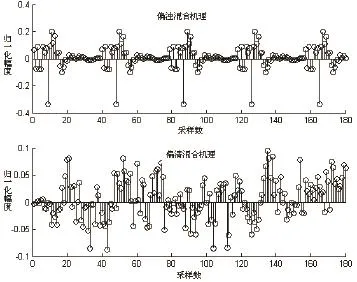
图3 精细混合激励信号 Fig.3 Accurate mixed excitation signal
(2)AMELP合成语音质量实验。将同一实验语音样本,分别作为MELP编码方案和AMELP编码方案的输入语音,分别得到两种编码方案的合成语音,如图4所示,试听者的平均意见为:两者的可懂度相同,但后者的自然度较前者稍优。
(3)AMELP对背景噪声的顽健性实验。分别在信号与背景噪声的信噪比(SNR)为26dB、20dB、16dB三种情形下作仿真实验,其中16dB时的实验结果如图5所示。实验结果表明:AMELP和MELP对背景噪声的顽健性是相同的。
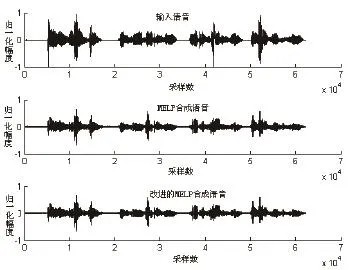
图4 两种编码方案合成语音Fig.4 Synthetic speech of two coding program

图5 16dB时两种编码方案的合成语音 Fig.5 Synthetic speech of two coding program on 16dB
5 结论
用改进的LBG算法(ALBG:用模糊C均值聚类算法选择初始码本;每次迭代后及时剔除空胞腔)设计、训练5维的子带声音强度码本,将其用于MELP编码方案中子带声音强度的矢量量化,得到MELP的改进算法AMELP。仿真实验表明:ALBG算法有效地克服了经典LBG算法的两个缺陷,目标函数快速、平滑、单调地趋近全局最优,训练得到的码本量化性能好;AM ELP方案将M ELP方案中子带声音强度精细量化,从而获得精准的混合激励信号,最终达到了提高合成语音质量(自然度)的目标。
[1] 张雄伟,陈亮,杨吉斌.现代语音处理技术及应用[M].北京:机械工业出版社,2003:112-172. Zhang Xiongwei,Chen liang,Yang Jibin.Modern speech processing technique and application[M].Beijing:China Machine Press,2003:112-172.
[2] Department of defense telecommunication systems standard. Mil-std-3005,Analog-to-Digital conversin of voice by 2.4kbps mixed excitation linear predication(MELP)[S].Washington,USA:Final Committee Draft,1995.
[3] Gray R M.Vector quantization[J].IEEE ASSP Magazine,1984,4:4-29.
[4] A lan V.McCree,Thomas P.Barnwell III.A Mixed Excitation LPC Vocoder[C]. ICASSP,1991,593-596.
[5] 鲍长春.数字语音编码原理[M].西安:西安电子科技大学出版社,2007,296-315. BAO Chang-chun. Princip le of digital speech coding[M].Xi’an:Xidian University Press,2007,296-315.
[6] 张雄伟,吴海佳,张梁梁,等.一种基于重构性深度网络的MELP语音编码改进算法[J].数 据 采集与处理,2015,30(2):307-314. ZHANG Xiong-wei,WU Hai-jia,ZHANG Liang-liang,et al. Improved MELP Algorithm Based on Reconstructive Deep Neural Network[J].Data Acquisition and Processing,2015,30(2):307-314.
[7] 姜占才,杨林.语音模糊特征提取及码本训练算法[J].吉林大学学报(信息科学版),2012,30(3):279-283.JIANG Zhan-cai,YANG Lin.Algorithm of Voice Fuzzy Feature Extraction and Codebook Training[J]. Journal of Jilin University(Information Science),2012,30(3):279-283.
[8] 姜占才,孙燕,姚刚.模糊聚类与LBG级联的VQ算法[J].计算机工程与科学,2011,33(5):155-158. JIANG Zhan-cai,SUN Yan,YAO Gang.VQ A lgorithm of Fuzzy Clustering and LBG Cascade[J]. Computer Engineering and Science,2011,33(5):155-158.
Improved Algorithm for Mixed Excitation Linear Prediction Coding
ZHU Zong-m ing1, JIANG Zhan-cai2
(1.The Chinese people’s liberation army 69220 troops, Akzo 843000,China; 2.Physics Department of Qinghai Normal University, Xining 810008,China)
As modulating signal of five passband band-pass filter, subband voiced intensity vector which determ ines the quality of synthetic speech directly, is the key to acquire accurate m ixed excitation signal. In the scheme of m ixed excitation linear prediction coding (MELP), for the defects of excitation source which lacks accurate caused by hard decision that subband sound intensity is either 0 or 1, subband voiced intensity is seen as 5-dimension obscure eigenvector; subband voiced intensity codebook is designed using modified LBG algorithm and subband voiced intensity is quantized using 5-bit vector; five passband band-pass filter is modulated using accurate and quantized subband voiced intensity, thus acquiring accurate m ixed excitation signal; finally the quality of synthetic speech is improved. Simulation experiments show that modified algorithm not only can improve the naturalness of synthetic speech, but also has stronger robustness for background noise.
Low rate speech coding; M ixed excitation; Subband voiced intensity; Vector quantization; Codebook
10.3969/j.issn.2095-6649.2015.09.002
ZHU Zong-m ing, JIANG Zhan-cai. Improved A lgorithm for M ixed Excitation Linear Prediction Coding[J]. The Journal of New Industrialization, 2015, 5(9): 8-13.
国家社科基金(15XYY 026)。
朱宗明(1985-),男,助理工程师,从事军事通信和军械保障方面的研究。
姜占才(1958-),男,教授,主要从事通信语音处理与保密通信方面的研究。
本文引用格式:朱宗明,姜占才.改进的混合激励线性预测编码算法[J]. 新型工业化,2015,5(9):8-13
