基于SystemC的MIPS处理器建模与架构
2015-05-04彭德生蒋志翔
彭德生,蒋志翔
(中国航天科工集团第二研究院706所,北京100854)
0 引 言
2011年,IEEE发布了SystemC最新的1666-2011标准[1],开启以系统建模的方法进行系统架构设计和分析的新世代。各大EDA厂商均推出了自己系统建模的平台,如Synopsys的 Platform Architect,Mentor Graphics的 Vista Architect,系统建模成为芯片设计的热点。
以往用Verilog设计数字电路的工程师从硬件描述的思维设计电路,他们往往没有C++面向对象的编程经验,难以用SystemC进行系统级模型的设计。为规范化系统建模过程、提高建模效率,本文前部分提出并实践了基于SystemC建立MIPS构架处理器的周期精准模型的方法,以自顶向下的方式规范化建模过程,采用 “结构框图-模块细化-模型映射”3步走,并介绍使用 “宏映射”的技术,保持Verilog语言的一些基本特征,让硬件工程师能轻松转移到SystemC系统级模型设计上。SystemC从高抽象层次的系统级描述系统,便于进行系统架构设计空间的探索和验证。为探索用系统级模型进行系统架构设计的方法,本文后部分以高速缓存Cache的设计为例,基于系统级仿真定量分析Cache的命中率与Cache相联路数、容量的关系,找出最优的Cache架构设计。通过系统建模的方法,将系统级模型加上激励测试程序进行系统仿真,可提取出缓存命中率、总线访问延迟、性能指标CPI(cycle per instruction)等剖面数据,可评估当前处理器构架的性能,发现系统的性能瓶颈,寻求满足性能需求及设计约束最优化的架构方案。由于系统级建模的优越性,系统建模的方法将成为系统架构设计和分析的主要途径。
1 SystemC建模语言
1.1 SystemC
SystemC是由一组C++类库所组成的硬件建模平台,也是一种新型设计方法,结合了硬件建模机制原理和面向对象编程两方面的优点,可在寄存器传输级、事务级、系统级不同抽象层次进行硬件建模。SystemC基本单元是模块 (module),模块内可包含子模块、端口和过程,模块之间通过端口和信号进行连接和通讯,利用SystemC的这些基本机制可方便建立CA (cycle accurate)时钟周期精确的模型。SystemC重要概念有模块、进程、接口、端口以及通道[1]。
进程 (process)是程序在并发环境中的执行过程,SystemC的基本进程包括:SC_METHOD,SC_THREAD,SC_CTHREAD。
SC_METHOD:当敏感列表上有事件发生时,才被调用,调用后迅速返回,用法很像Verilog中描述的组合逻辑;
SC_THREAD:能够被挂起和重新激活,当敏感表上有事件发生,线程被重新激活运行到新的wait()语句再重新挂起,主要用于对程序的验证;
SC_CTHREAD:继承于线程进程,只能在时钟的上升沿或者下降沿被触发或者激活,用于时钟精确的建模。
模块间通道通信如图1所示。

图1 模块间通道通信
接口 (interface),提供一组固定的通信方法,是C++抽象类,它以纯虚数的方式定义了一组抽象的方法。通道 (channel),实现一个或者多个接口,接口中定义的虚函数必须在通道中实现,它是一个实现通信功能的 “模块”,只不过它仅完成通信功能。端口 (port),定义在模块中,模块通过端口与通道连接,通过端口,模块中的进程就能够连接到一定的接口,与其它模块通信。
1.2 TLM建模
TLM (transaction level modeling)2.0的 引 入,是 在事务层[1,2]对硬件建模,以获取更高的仿真速度,允许设计人员对系统架构及性能的分析、对固件驱动及应用软件在RTL (register transfer level)实现前进行开发验证。TLM 2.0是建立在SystemC类库之上的类库,方便用户进行事务级模型的开发。TLM 2.0主要由TLM-1、互操作层和实用类组成。TLM 2.0的核心是互操作层,主要由一般的负载模型及基本的总线协议、发起者与目标套接字、全局时间量和核心接口组成。而核心的接口又由阻塞传输接口、非阻塞的传输接口、直接存储访问接口、传输调试接口组成[1]。
TLM 2.0主要有两种模型风格:宽松时序LT (loosely-timed)和近似时序 AT (approximately-timed),以便用在不同场合。一般LT用在软件开发调试上,AT用在硬件架构性能分析上。宽松时序LT有较快的执行速度。一个事务有两个时间点,请求的开始时间点与响应的开始时间点。LT允许进程跑在仿真时间前以获得较快仿真速度。近似时序AT的事务有多个阶段,一般在请求响应的开始、结束都有时间点,并按照SystemC调度器严格按时间执行。
1.3 Verilog与SystemC
不难发现SystemC和Verilog在硬件描述方面语言特征很像,开发SystemC标准的工程师,正是借用Verilog的硬件描述方法和概念,将RTL级的描述语言升级为系统级的建模语言。Verilog采用层次化、模块化的设计方法,将一个复杂的设计划分成几个顶层模块,这些顶层模块又可细化为子模块,子模块又可细化为更小的模块,而模块之间的连接、通信是通过input、output或inout信号实现的。这样,一个复杂的硬件设计就划分为以模块为基本单元的层次化的树状结构,然后用分而治之的方法逐个设计每个模块,使设计变得条理化而更容易。模块内部定义了内部使用信号,有assign为代表的连续赋值语句和always块为代表的过程赋值语句。assign语句描述组合逻辑,输出随时随输入变化而变化,没有时钟周期的概念,只有输入到输出的最大延迟路径决定输出何时有效。电平敏感的always块主要用来描述复杂的组合逻辑,也可能描述含锁存器的电路。时钟边沿敏感的always块用来描述时序电路,通常在always块被赋值的信号都是reg寄存器,寄存器能存储信息,仅在时钟边沿改变值,做到信号的同步。模块就是通过其中的控制逻辑,将输入信号和内部信号加工处理,驱动输出信号;模块的输出仅取决于输入和内部的控制逻辑,而且一个输入信号只能有一个驱动模块,使模块间的耦合度降低,模块间的关联和通信仅靠输入输出端口;模块化的设计方法便于设计实现和调试验证。
Verilog语言的主要概念有模块module、输入信号input、输出信号output、连续赋值语句assign(描述组合逻辑)、过程赋值语句always块 (主要描述时序逻辑)、时钟沿等,SystemC建模语言主要概念有模块sc_module、进程sc_process、端口sc_port、接口sc_interface、通道sc_channel,它们的对应关系见表1。
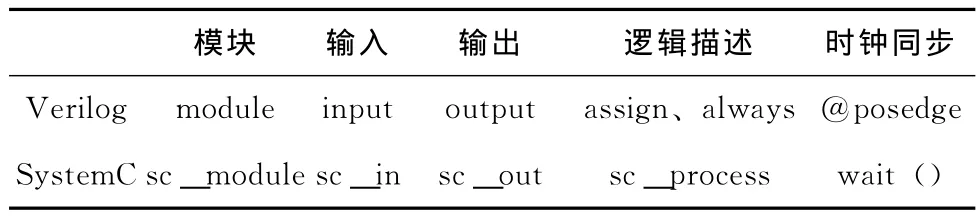
表1 Verilog与SystemC对比关系
2 SystemC模型建立
2.1 MIPS处理器结构
精简指令集计算机 RISC (reduced instruction set com-puter)的代表MIPS指令架构采用32位固定的指令长度、简明的指令结构,便于译码;拥有32个通用寄存器;仅Load/Store指令可访存,访存寻址方法少:这些特点使MIPS处理器便于采用流水线等技术增强CPU性能。
经典MIPS处理器的执行过程分为取指IF(instruction fetch)、译码ID (instruction decode)、执行 EX (execute)、访存 MEM (memory access)、写回 WB (write back)这5个阶段[3,4],用控制器产生的控制信号控制处理器的执行。根据处理器的执行流,MIPS处理器可划分为取指部件、译码部件、执行部件、访存部件和数据写回通路这5大功能部件;根据处理器的控制流,MIPS处理器包含控制各功能部件协同工作的控制器;根据处理器数据流的传递,MIPS处理器包含通用寄存器文件、L1指令Cache、L1数据Cache以及可选的L2共享Cache等数据存储部件。
(1)取指阶段:CPU在一条指令执行的第一阶段是根据当前程序计数器PC值从存储器中获得当前要执行的指令,对于MIPS结构的指令而言,这是一个固定的32比特数据。当L1指令Cache命中时,可快速取得指令存入指令寄存器IR内;当L1指令Cache缺失时,需要访问下一级高速缓存,最会的情况是到片外的主存储器中取指令,当然这会带来很大的处理器延迟。
(2)译码阶段:现在我们已将指令取来放在IR (instruction register)寄存器中了,在译码阶段就是根据IR产生各功能部件的控制信号和数据输入信号。MIPS指令分为算术逻辑指令、访存指令、程序转移指令、数据传输指令和处理器控制指令等类别。指令译码就是按照MIPS指令编码格式识别当前指令是何种类型指令、需用到什么功能部件,以产生该功能部件需要的控制信号和数据信号。译码阶段还需要完成的是源寄存器的读取,根据指令编码中源寄存器Rs、Rt的寄存器号,从寄存器文件中读取源寄存器的值,以用于指令执行的下一阶段。
(3)执行阶段:执行部件主要包含算术逻辑单元ALU(arithmetic logic unit)和 浮 点 运 算 单 元 FPU (float point unit)这些功能部件。算术逻辑单元ALU主要包括定点加法器、逻辑运算、移位运算、定点乘法器、定点除法器;浮点运算单元FPU主要包括浮点加法器、浮点乘法器和浮点除法器。经过译码,我们知道了当前指令的类型以及将占用的功能部件,然后使用译码阶段读取的源操作数进行计算。以整数加法 “A+B”指令为例,指令译码产生的控制信号将选择ALU的加法单元,使用译码阶段读取的寄存器值A、B为加法器的输入,经过通常是1个时钟周期的延迟,加法器的输出端产生有效的输出C,以供下一阶段使用。
(4)访存阶段:访存阶段不是所有指令都需要经历的指令执行阶段,仅访存Load/Store型指令才需要。访存与取指有些相同,都是对主存储器的访问,访存特指对数据的访问,可读可写,先要访问L1数据Cache;取指是指对程序指令的访问,只可读,先访问L1指令Cache。访存先要计算数据的地址,需要用到上一阶段的ALU计算出访存地址A,然后在此阶段先访问L1数据Cache,若命中就可快速返回,否则需要访问下一级存储层次,这将带来更大的方寸延迟。
(5)写回阶段:寄存器写回阶段也不是所有指令都需要经历的指令执行阶段,仅需要更新寄存器值的指令才需要,如大多数算术逻辑指令和Load型访存指令。写回阶段唯一需要做的是将ALU的输出或访存部件的输出链接到寄存器文件的输入端,更新寄存器的值,它其实起到数据通路的作用。
2.2 SystemC模型映射
针对周期精确及端口信号级精确的SystemC模型设计[5-7],本文提出模块化的 “结构框图-模块细化-模型映射”的规范化SystemC模型映设计方法。
2.2.1 结构框架
SystemC建模的第一步是根据目标系统的功能特征,将系统划分为独立的功能子系统,以结构框图的形式表示出来,各功能子系统的联系、数据交互可用箭头和文字标注。这样目标系统的结构框图被建立好,从这样的系统顶层框图可清楚看到系统可分为几大部分,以及各部分关联,为建模的下一步打好基础。如图2经典5周期MIPS处理器的结构框架。
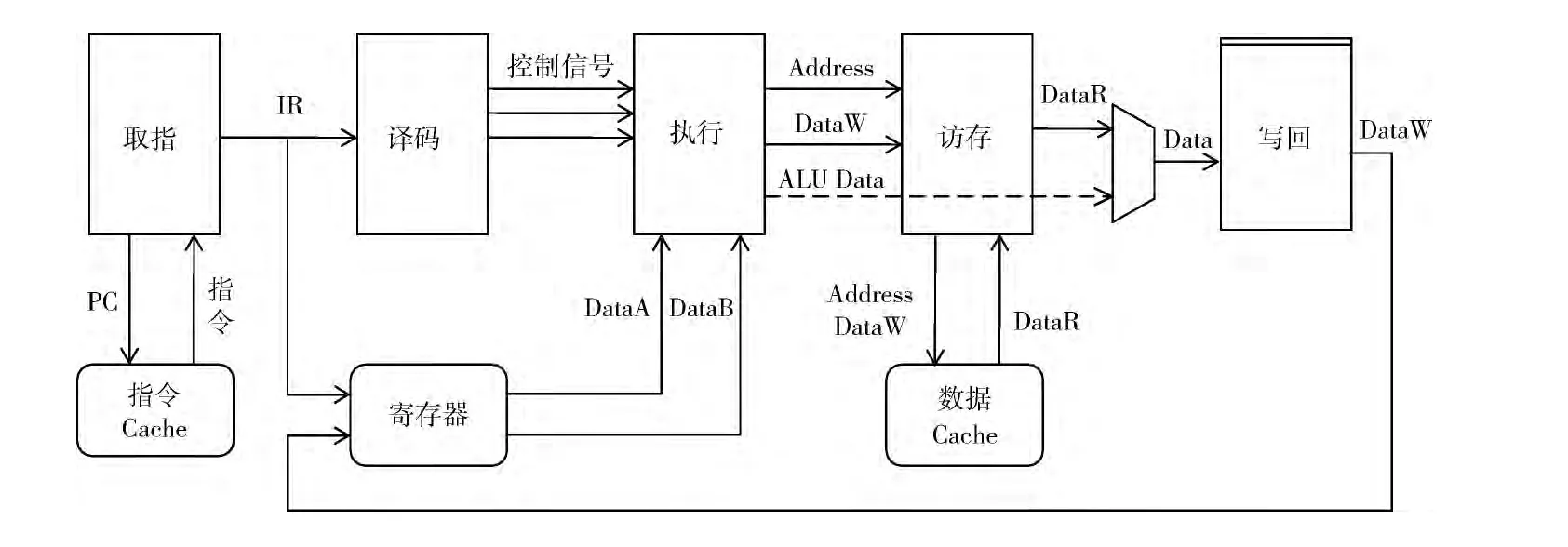
图2 经典MIPS处理器结构框架
2.2.2 模块细化
建模的第二步是模块细化,就是将顶层的功能子系统进一步模块化、功能细化。这一阶段要精确到模块module,找出系统的主要模块,并且要明确各模块的主要接口信号(input、output、inout),这时模块内的逻辑实现可先不考虑。
具体而言,IF取指功能部件,需要的输入信号有时钟输入Clk、指令的地址PC (program counter)、取指请求信号Inst_Req等,主要的输出有取指应答Inst_Ack、取到的指令Inst。取指部件包含L1指令Cache子模块,主要的输入是指令地址PC,输出为所取的指令Inst。取指功能部件可描述为:IF {Clk_I,PC_I,Inst_Req_I,Inst_Ack_O、Inst_O}。
ID译码功能部件,输入刚取的指令Inst,输出有ALU操作码ALU_Op、操作数ALU_DataA和ALU_DataB以及访存请求Mem_Req、访存地址基地址 Mem_Addr-Base、访存写数据Mem_DataWr等。经过仔细分析,译码部件要读取源操作数,因而包含寄存器读取子模块Regfile;输入是指令译码的RsIdx、RtIdx源寄存器索引号,输出是第一源操作数Rs和第二源操作数Rt寄存器的值。译码功能部件可描述为:ID {Clk_I,Inst_I,ALU_Op_O,ALU_DataA_O,ALU_DataB_O,Mem_Req_O,Mem_AddrBase_O,Mem_DataWr_O}。
EX执行功能部件,根据处理器所实现的运算功能,执行功能部件包括定点加法器Adder、逻辑运算Logic、移位运算Shifter、比较器Comparator、定点乘法器 Multiplier、定点除法器Divider等基本运算单元。这些运算单元的输入均是ID译码部件产生的ALU输入源数据ALU_DataA和ALU_DataB,而由操作码ALU_Op译码产生对不同子功能运算单元的选择信号,因一条指令仅使用一个运算单元,这样的选择信号可避免其它运算单元的工作,从而有利于低功耗的实现。这些运算单元主要的输出是各自的运算结果,通过前面的运算单元选择信号可选择当前有效的运算结果作为整个ALU的输出ALU_Out;而有些运算单元有自己特殊的输出信号,如加法器有溢出C输出标志、符号S输出标志,比较器有零Z输出标志、比较结果LT标志,除法器有除数为零异常标志信号等。执行功能部件可描述为:EX {Clk_I,ALU _Op_I,ALU _DataA_I,ALU _DataB_I,ALU_Out,C,S,Z,LT}。
MEM访存功能部件,仅供Load/Store型指令访问程序所使用数据。输入为ID部件产生的访存请求信号Mem_Req、读写控制信号 Mem_RW、访存写数据 Mem_DataWr,以及EX执行部件计算出的访存地址Mem_Addr。当是Store型指令时,将Mem_DataWr数据写入内存后指令执行完毕;当为Load型指令时,访问存储器取得数据Mem_DataRd,然后还要经写回阶段存入寄存器。MEM访存部件产生访存控制信号,主要包括L1级数据Cache子模块。访存功能部件可描述为 MEM {Clk_I,Mem_Req_I,Mem_RW_I,Mem_Addr_I,Mem_DataWr_I,Mem_DataRd_O}。
WB写回功能部件,主要作用是完成通用寄存器的更新。输入有算术逻辑指令使用EX功能部件产生的计算结果ALU_Out、Load型指令使用MEM功能部件取回的数据Mem_DataRd,以此选择寄存器文件写数据输入Reg_DataWr;另外有寄存器写控制信号Reg_WriteEN。写回功能部件可描述为 WB {Clk_I,Reg_DataWr_I,Reg_WriteEN}。
数字系统包含数据通路和控制逻辑两大部分,数据通路就是上面描述的5大功能部件;而为使各种指令在处理器上经不同执行路径有条不紊的执行,一个控制指令全局执行的状态机FSM是必需的。FSM状态有S_IDLE、S_IF、S_ID、S_EX、S_MEM、S_WB,输入为指令类型Inst_Type、取指完成信号Inst_Ack、访存完成信号Mem_Ack,输出为各阶段的执行控制信号和当前状态,状态机可描述为FSM {Clk_I,Inst_Type_I,Inst_Ack_I,Mem_Ack_I,Inst_Req_O,Decode_Req_O,Execute_Req_O,Mem_Req_O,WB_Req_O,Current_State_O}。
2.2.3 模型映射
经过用画结构框图方法进行系统顶层描述,再进行模块的细化后,最后进行系统到SystemC模型的映射。模型映射用SystemC语言实现各个模块module的内部逻辑,将顶层结构框图描述的系统映射为SystemC的模型系统。当有Verilog的RTL模型时,可更容易将RTL模型映射为SystemC模型,因SystemC标准参考了Verilog关于模块、接口等概念。
本文所建立的MIPS处理器模型,主要就是用SystemC提供的接口实现5大功能部件和控制状态机。下面以IF取指部件为例,介绍SystemC的实现。


取指用称为Fetch的类实现,该类继承与SystemC的模块基类sc_module,对应于Verilog的模块 module。Fetch类中首先定义模块的接口信号,sc_in接口类定义输入信号,对应于input;sc_out接口类定义输出信号,对应于output。然后定义类自己的内部变量,本例中是指令存储器imem,接着定义类的内部函数声明。最后是类的构造函数定义,使用宏SC_CTOR定义构造函数,宏参数为类的名字Fetch。在构造函数里,首先用SC_CTHREAD定义模块的SystemC线程,SC_CTHREAD在每个时钟周期边沿激活,用于周期精确模型建模,宏第一个参数FetchMain表示它是线程执行的入口函数,第二个参数CLK_I.pos(),表明线程在时钟的上升沿触发;然后申请了32KB的指令存储空间imem,从机器指令二进制文件Source.bin中读入指令数据初始化指令存储器imem。下面来看SystemC线程FetchMain:

SystemC的线程一般是个死循环,在运行了指定时钟周期数后,由SystemC调度器回收结束各线程。周期精确主要靠wait()函数同步各个SystemC线程在每个时钟周期执行一次,当线程被调度器调度执行,线程从wait()的下一条语句开始执行直到遇到wait()语句结束本次执行。在本IF取指部件的实现中,先对取指请求信号Inst_Req_I进行采样,若有效则继续执行,否则等待下一时钟周期再采样该信号。取指需先用程序计数器PC值计算下一条指令的地址,访问指令存储器imem并通过Inst_O输出端口输出所取得的指令,然后PC加4指向下一条顺序指令地址,置Inst_Ack_O信号有效,通知其它模块输出指令有效。
为了保持SystemC建模风格和Verilog硬件描述风格一致,让从已有的RTL模型映射到SystemC的系统级模型更容易,本文提出运用C++语言提供的宏,使用 “宏映射”技术:
对连续赋值语句的assign关键字,在SystemC中可定义空宏 “#define assign”,则可编译通过;
定义wire或reg型变量,可先定义以下宏:“#define wire(m,n) unsigned int”,则声明20位的信号可表示为:“wire(19,0) signal;”,与Verilog十分相似;
对于位选择,如signal[15:8],SystemC中可定义宏:“#define BITS (name,m,n)(((unsigned int)name<< (31-m))>> (32- (m-n+1)))”,可如 BITS (signal,15,8)使用。
3 仿真与架构探索
3.1 系统仿真
当系统的模型建立后,需要验证模型的正确性[7]。Verilog描述的RTL模型验证困难、可调式性差,验证需要用Verilog等语言写测试激励,测试激励生成效率低下而且不能充分测试系统的功能与性能;主要通过查看信号波形图分析系统的问题,不能进行运行时单步调试,不直观,也不容易定位系统的问题。而用SystemC描述的系统级模型,借助C++集成开发调试环境,将系统架构设计、系统级验证结合在一起;系统测试激励Testbench可用C/C++语言,和建模语言SystemC使用相同的高级程序设计语言,不但抽象程度高,而且Testbench生成效率高,能达到较高的覆盖率,充分验证系统功能;调试方面,C++调试器支持运行时单步执行、查看各信号变量值等,方便定位系统设计错误。
为了验证本文设计的MIPS系统级周期精确模型的正确性,即5大功能部件和控制逻辑设计正确,能正确执行每一条指令,需要在处理器模型上运行测试程序。
测试程序描述:冒泡排序算法,对100个数进行升序排序,初始化数组元素依次为100、99、98…3、2、1,输出应是1到100的升序排序,为了清晰本测试程序仅打印输出前20个数。此排序是冒泡排序的最坏情况,算法复杂度为O(n2)。测试程序用C语言描述,用Cygwin环境下MIPS-GCC交叉编译器编译生成机器代码。
测试机器配置:

运行结果如图3所示,测试程序顺序输出1到20的排序结果,印证了所建的处理器模型能正确工作,程序就像跑在一台真实的计算机上一样。另外可以知道处理器模型模拟了251 095个时钟周期,执行了83 699条指令,模拟器模拟总共耗时8.166s,仿真速度30 748个时钟周期每秒,指令执行速度10249条指令每秒。
3.2 构架探索
使用高级程序设计语言SystemC编写的处理器系统级模型最大的好处在于能用于处理器架构的探索以及系统的性能瓶颈分析。SystemC将硬件描述特征与C++面向对象特点结合在一起,使这样系统级的模型有较好的参数可配置性和可扩展性。在处理器架构探索方面,可配置处理器有几级高速缓存,每级Cache的容量、Cache组织方式以及Cache替换策略等[8,9];处理器采用多少核心,2核、4核还是8核,处理器采用同构多核还是异构多核[10]。在系统性能瓶颈方面,着重关注总线的设计,如采用什么总线协议,使用AMBA AHB或更快的AXI,采用多大总线频率,多宽的总线,什么样的总线仲裁协议等[11,12]。这些都是处理器架构设计空间需要考虑的问题,不同的构架方案都可方便对系统级模型进行参数的配置或少量修改完成,通过系统级仿真、量化分析的设计方法,帮我们找到系统性能瓶颈,指导我们找到满足系统设计需求的最优系统架构。

图3 处理器模型执行冒泡排序仿真结果
本文以所设计的MIPS系统级模型为基础,分析高速缓存Cache的设计对系统构架及性能的影响。我们知道,Cache的引入,减少了访存延迟,降低了 “存储墙”对系统性能的影响,因而Cache的设计对系统性能的影响至关重要。论文建立了带L1指令Cache和L1数据Cache的MIPS处理器模型,下面分析不同数据Cache的架构设计对系统性能的影响。
图4横坐标为Cache的容量,采用的是对数坐标,如“8”代表28=256字节,从256B到32KB。纵坐标为Cache命中率,如式 (1)为Cache平均访问时间的计算式[3],Taccess表示访存平均延时,Thit表示访存命中时间,Tpenalty表示访存缺失时额外需要的时间,Rhit表示命中率;命中率越高,访问较慢外存概率越小,Taccess平均访存延时越小,因而系统性能越高,故Cache命中率可用来反映处理器性能。图中有4条折线,代表不同Cache组织策略,分别表示1路、2路、4路、8路组相联Cache,注意1路Cache其实是直接映射Cache。Cache平均访问时间计算式如下
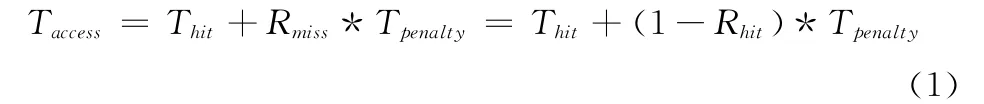
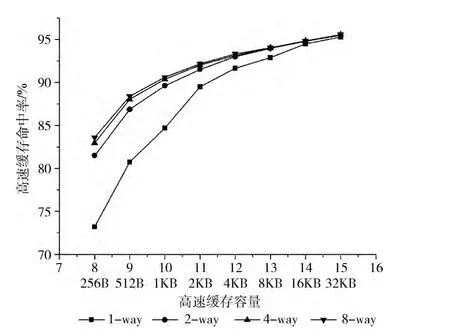
图4 Cache路数、容量与命中率关系
处理器模型采用的测试基准程序为常用的bzip2文件压缩程序,分别配置模型的Cache容量参数和组相联路数参数,运行仿真得到不同高速缓存配置下的Cache命中率。
分析图4曲线的走势,可知在相同Cache容量下,直接映射的Cache命中率最低,8路组相联命中率最高,命中率随路数的增多而提高。可以看到,4路组相联曲线和8路组相联曲线基本重合,2路组相联曲线略有下移,而直接映射曲线下移较多。我们需知道并不是相联路数越多越好,路数越多,主存与Cache同时比较标志位的路数也越多,比较逻辑越复杂,延时更大,L1命中时间Thit也越大;因而L1级Cache的组相联路数选择为2路或4路比较合适。
再看在Cache相联路数一定,Cache命中率随Cache容量增大的变化趋势。Cache命中率随Cache容量增加而单调上升,只不过先上升较快,然后上升较平缓。当Cache容量为512B时,曲线斜率最大,命中率上升最快;但命中率还较低,不足90%。当Cache容量增加到1KB时,曲线上升变得平缓,即使Cache容量进一步增加,命中率提高得较小;而此时Cache命中率已经较高,4路Cache的命中率超过了90%。当Cache容量增加到4KB后,2路、4路与8路相联Cache曲线基本重合,命中率十分相近,约为93%;增加到16KB时,直接相联曲线也基本和其它3条曲线重合;Cache容量为32KB时,命中率最高,约为95%。L1级Cache不应太大,因较大的L1级Cache会增加命中访问延时Thit,通常L1级Cache不超过32KB。因此,L1级Cache容量设计为4KB到32KB比较合适,本例中命中率在93%~95%之间。
4 结束语
电子设计自动化从底层硬件的描述语言Verilog/VHDL发展到系统级建模语言SystemC,为系统级架构设计与验证提升到一个新的高度。本文提出了 “结构框图-模块细化-模型映射”的规范化系统建模方法,有助于从RTL设计转化到系统模型的设计,并建立了MIPS处理器周期精确的系统级模型。然后基于建立的处理器模型,展示了将系统模型用于系统构架的设计上,通过对Cache的仿真分析,得出了L1级Cache宜采用2路或4路组相联组织结构、Cache的容量在4KB到32KB之间的结论。用SystemC对系统进行建模逐渐成为数字系统设计新的方向标,可以在设计早期对系统架构及性能进行定量评估,保证系统设计的成功。
[1]IEEE Std 1666TM-2011,IEEE Standard for Standard SystemC Language Reference Manual[S].2011.
[2]MA Qinsheng,LIU Yuan,ZHANG Ning,et al.Modeling of transaction level for SoC [J].China Integrated Circuit,2012,19 (Z1):42-46 (in Chinese). [马秦生,刘源,张宁,等.SoC事务级建模方法 [J].中国集成电路,2012,19 (Z1):42-46.]
[3]John L Hennessy,David A Patterson.Computer architecture:A quantitative approach [M].5th ed.Beijing:China Machine Press,2012:72-104.
[4]John L Hennessy,David A Patterson.Computer organization and design:The hardware/software interface [M].4th ed.Beijing:China Machine Press,2012:196-228.
[5]HE Weiqiang,YANG Liang,LU Qiang.Cycle-accurate DSP processor modeling with SystemC [J]. Microelectronics &Computer,2013,30 (4):3-7 (in Chinese). [何卫强,杨靓,卢强.基于SystemC的周期精确级DSP处理器建模 [J].微电子学与计算机,2013,30 (4):3-7.]
[6]LI Yuan.The system level application design and verification of turbo codec using the SystemC [D].Shanghai:Shanghai Jiao Tong University,2009:42-64 (in Chinese). [李源.基于SystemC系统设计的Turbo编解码器 [D].上海:上海交通大学,2009:42-64.]
[7]WANG Peng.The research on modeling of dynamic and reconfigurable SoC system [D].Chengdu:University of Electronic Science and Technology of China,2008:45-76 (in Chinese).[王鹏.基于SystemC的动态可重构SoC系统级建模框架研究[D].成都:电子科技大学,2008:45-76.]
[8]Marisha Rawlins,Ann Gordon-Ross.A cache tuning heuristic for multicore architectures [J].IEEE Transactions On Computers,2013,62 (8):3-5.
[9]Jinho Suh,Murali Annavaram,Michel Dubois.MACAU:A Markov model for reliability evaluations of caches under singlebit and multi-bit upsets [C]//IEEE International Symposium on High Performance Computer Architecture,2012:237-243.
[10]Xi E Chen,Tor M Aamodt.Modeling cache contention and throughput of multiprogrammed manycore processors [J].IEEE Transactions on Computers,2012,61 (7):3-7.
[11]Hansu Cho,Lochi Yu,Samar Abdi.Automatic generation of transducer models for bus-based MPSoC design [J].IEEE Transactions on Computers,2013,62 (2):5-8.
[12]WANG Yang.The joint architecture design of SoC SW/HW co-verification platform [D].Shanghai:Shanghai Jiao Tong University,2013:34-65 (in Chinese). [汪洋.SoC软硬件协同验证平台的联合架构设计 [D].上海:上海交通大学,2013:34-65.]
