基于词级DPPM的连续语音关键词检测
2014-08-05张连海
王 勇,张连海
(解放军信息工程大学信息系统工程学院,郑州 450002)
基于词级DPPM的连续语音关键词检测
王 勇,张连海
(解放军信息工程大学信息系统工程学院,郑州 450002)
提出一种基于词级区分性点过程模型的连续语音关键词检测方法。利用时间模式结构和多层感知器计算每个音素帧级后验概率,使用区分性点过程模型将一段时间内多个音素事件形成的点过程作为整体,把关键词检测看作二元分类问题,经分段和拼接构成超矢量,输入支持向量机分类器,判断该段语音是否为待检测关键词。该方法充分考虑语音信号上下文相关性,直接以词作为基本单元建模,提高了系统检测的准确性和鲁棒性。实验结果表明,对采样的语音,其关键词平均召回率和准确率分别可达71.5%和84.6%以上,并且结合相关语言模型知识,系统性能将会进一步提高。
点过程模型;音素后验概率;时间模式;关键词检测;支持向量机;区分性点过程模型
1 概述
目前语音识别常采用子词单元(如音素)进行声学建模,在此基础上联合发音字典进行词的识别。但在进行关键词检测时,由于语音信号具有上下文相关性,若直接以词作为基本单元建立模型,可能会提高系统准确性和鲁棒性[1]。语音点过程模型[2](Point Process Model, PPM)表示方法与传统的基于帧的时间向量表示方法不同,它使用基于时间的稀疏声学事件表示语音,使用基于声学事件的点过程模型取代基于声学状态的HMM模型[3]。本文使用点过程表示语音信号,研究基于词级区分性点过程模型(Discriminative Point Process Model, DPPM)的连续语音关键词检测方法。
之前的研究给出了一般的PPM框架[4],证明基于声学事件的关键词检测方法与传统方法相比,能够保证关键词检测系统的准确性并降低系统的复杂性。但是,一般的PPM模型建立在音素事件之间独立性假设基础之上,且在使用泊松过程计算似然比时,似然比值往往依赖于某个或某几个音素事件。本文考虑将关键词点过程作为整体,经适当处理后,输入支持向量机(Support Vector Machine, SVM)[5],通过输出的词级置信度得分判断该段语音是否为关键词。
2 点过程建立
基于DPPM关键词检测分为2个阶段:点过程建立和关键词检测。首先计算帧级音素后验概率并建立点过程,其次由关键词检测模块计算词级置信度得分,通过设定阈值判断候选语音是否为关键词。
图1为本文使用方法检测关键词结构。语音信号首先经过信号处理单元S得到帧级音素后验概率X,检测器D给定适当的阈值,X经过检测器D后,转化为n个点过程P,那么语音信号就可以用n个点过程表示,再由关键词分类器计算词级置信度得分,最终实现关键词检测。

图1 关键词检测结构
2.1 音素后验概率
目前,语音识别声学特征主要使用MFCC、PLP等[6]频谱参数,但这些参数只使用了20 ms、30 ms左右的语音信息,极易受到噪声的影响。TRAP[7]是一种长时属性,反映了长时间特征变化情况,有效地利用语音信号之间的相关性,能够提高语音识别的性能[8]。本文将TRAP结构引入到音素后验概率的检测之中。
基于TRAP结构的音素后验概率检测流程如图2所示,具体步骤如下:
(1)预处理:选择帧长与帧移分别为25 ms和10 ms,对语音信号进行预加重、加汉明窗,将频谱转化为梅尔频标后进行三角窗滤波,每帧语音信号输出为23个子带能量的一维向量。
(2)拼接加权:将当前帧与其前n帧的子带能量拼接成一个长序列,称为左子带序列;将当前帧与其后n帧的子带能量拼接成右子带序列。由于语音信号帧与帧之间距离越近,相关性越强,距离越远,相关性越弱。因此,给距离当前帧较远的帧分配较小的权值,距离当前帧较近的帧分配较大的权值,并且同一帧内的各个子带能量系数分配的权值相同。然后,分别对加权后的序列进行离散余弦变换(Discrete Cosine Transformation, DCT)变换,将变换后的系数规范化后作为低层MLP输入特征。
(3)后验概率检测:采用低层MLP分别对左、右2个子带序列进行音素检测,对输出结果进行非线性变换,将低层2个MLP的输出拼接成新的向量并作为高层MLP的输入特征,最后高层MLP的输出为音素后验概率识别结果。
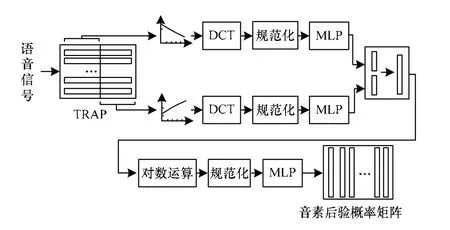
图2 音素后验概率检测流程
由于TRAP结构使用了上下文相关信息,因此最终检测结果准确率相对更高。图3所示为词problem帧级音素后验概率图,颜色越深表示该帧信号为某个音素的概率越大。

图3 pr oblem帧级音素后验概率
2.2 点过程
在计算出帧级音素后验概率的基础上,得到语音信号音素后验概率矩阵。对于后验概率矩阵的每一行,也就是语音信号每一帧,取后验概率最大值,其余后验概率置为0。然后给定阈值γ,若该帧信号后验概率最大值大于γ,则将其置为1,表示该帧语音信号是某个音素,若小于γ,则将其置为0。由此可以将音素后验概率矩阵0、1离散化,得到语音信号点过程表示。图4所示为词problem的点过程表示,其中的点表示该帧信号为problem相应的某个音素,点的个数代表音素出现的次数。

图4 pr oblem点过程表示
3 DPPM关键词检测
SVM是建立在统计学习理论的VC维理论和结构风险最小原理基础上的,根据有限的样本信息在模型的复杂性和学习能力之间寻求最佳折中,以期获得最好的推广能力。它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。在文本分类、生物信息、图像分析、语音识别等诸多领域中,SVM有着广泛的应用[9]。
给定如上所述语音点过程表示,需要对每段语音产生的点过程建立合适的模型,以达到区分关键词与非关键词的目的。本文采用SVM分类器对候选语音进行检测。
3.1 SV M基本理论
SVM通过事先选择的非线性映射将输入空间变换到高维空间,然后在高维空间中构建最优决策超平面,使得该平面两侧距离平面最近的2类样本之间的距离最大化。非线性映射通过定义适当的核函数实现。SVM关键在于核函数,低维空间向量通常难以划分,需要将它们映射到高维空间,但会增加计算复杂度,核函数恰好解决了该问题[10]。实际应用表明,RBF核函数具有良好的性能和很强的学习能力,无论对于低维、高维、大样本还是小样本等情况,该核函数都适用,有较好的收敛域,采用RBF核函数:

对语音点过程进行分类。
3.2 D PPM关键词检测

将所有的候选语音段时长归一化后,对归一化时长进行均匀分段,将Si'映射为(M| P|+1)维超矢量xi。其中,M是所分时间段数;|P|是音素个数。前M|P|维向量由音素事件数|P|个M维向量拼接构成,数值为当前段当前音素事件发生次数,即超矢量xi第k个元素xi[k]=nj,d为第j个音素在第d段时间内发生次数。其中,j=k/M,d=mod(k,M);第(M|P|+1)维向量为时长Ti(候选语音段的帧数)。给定候选语音,并将其转换为上述超矢量形式,即可使用SVM分类器判别其是否为待检测关键词。
4 实验与分析
4.1 实验配置
4.1.1 语料库
本文实验使用TIMIT[11]语料库,排除其中用于说话人识别实验的SA1和SA2中的语句,选择训练集中3 296个语句和测试集中1 344个语句进行实验,时间共计3.95 h。由于实验需训练关键词样本,因此选择TIMIT语料库中出现频次较高的词进行相关实验。
TIMIT语料库中共含有61个音素单元,其划分较为精细。根据CMU/MIT标准,对TIMIT中发音类似的音素进行合并,由61个音素映射为47个[12],对应关系如表1所示。

表1 TI MIT中音素映射关系
4.1.2 DPPM设置
在实验中,对于不同的音素设置的后验概率阈值δ也不尽相同,本文设置阈值由统计平均得出。对于时长较短的关键词,设置分段数M=10;对于时长较长的关键词,设置分段数M=20,然后根据3.2节所述方法,将分别获得471维和941维超矢量。
4.2 实验结果
召回率和准确率是衡量关键词检测性能的2项重要指标,可以用来对检测的结果进行量化评价。一般而言,召回率和准确率是互相对立的,一个指标的上升伴随着另一个指标的下降。在应用过程中,一般寻找两者的平衡点,使得召回率与准确率均能满足实际的需求。

本文选取关键词容错误差为±30 ms,表2所示为文献[4]方法与本文方法关键词检测结果对比。

表2 PPM关键词检测结果
由于本文中并未考虑词边界信息,在进行关键词搜索时,若某个词的发音完全包含另一个词的发音,会将该词作为关键词检出。例如搜索关键词every(发音为|ehvr iy|)时,因为词everyone(发音为|eh v r iy w ah n|)完全包括词every的发音,所以会将everyone的前半部分作为关键词检出,本文中未将这种情况作为插入错误进行统计。对于包含音素较少的词,如take(发音为|t ey kcl|),由于英文单词中包含发音|t ey kcl|情况较多,本文未统计准确率。
在实验中,为提高系统关键词召回率,在准确率允许条件下,可适当将易混淆的音素如|iy|、|ix|等作为同一音素处理。例如某候选语音通过音素后验概率检测发音为|eh v r ix|,可酌情将其作为发音|eh v r iy|处理。
在理论上,当关键词时长越长、包含的音素越多时,建立点过程模型可利用的信息越多,关键词模型的复杂度越高,容易引起的混淆越少,相应的关键词召回率、准确率应该越高。在实验过程中,随着关键词包含音素的增加,关键词检测准确率呈上升趋势,但是由于关键词包含音素的增加,音素后验概率错误也就相应增多,关键词召回率不一定能相应提高。由于语料库中,某些关键词存在较多的发音变体[13],单纯地依靠某一个关键词模型并不能将所有的发音变体检测出,因此可能存在某些关键词的检测效果并不理想。由表2可以看出,people召回率仅为52.3%和58.3%,与其他词有较大差距。
表3所示为在相同条件下,本文方法与其他方法的关键词检测结果。可以看出本文方法在召回率和准确率方面均优于文献[4]和基于HMM垃圾模型关键词的检测方法。

表3 PPM与HMM关键词检测结果比较 %
5 结束语
本文给出了一种新的基于PPM的关键词检测方法,建立语音点过程处理模型,然后经过分段和拼接形成超矢量,通过分类器输出候选语音段整体词级得分,最终实现关键词检测。由于本文方法仅使用了音素后验概率信息,后续研究中可以将语言知识与本文方法相结合,进一步提高关键词检测性能。由于音素后验概率对关键词检测性能具有决定性作用,因此如何提高音素后验概率准确率问题亟待解决。本文只使用音素事件建立点过程模型,实际上,可以根据其他语音事件建立多个点过程模型,然后将各个点过程进行融合,建立更为复杂精确的关键词模型。
[1] Lee C H, Juang B H, Soong F K, et al. Word R ecognition Using Whole Word and Sub word Models[C]//Proc. of International Co nference on Acoustics, Speech, a nd Signal Processing. [S. l.]: IEEE Press, 1989: 683-686.
[2] Jansen A, Niyogi P. Point Process Models for Spotting Keywords in Continuous Speech[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2009, 17(8): 1457- 1470.
[3] Rose R C, Paul D B. A Hidden Markov Model Base d Keyword Recognition System[C]//Proc. of International Conference on Acoustics, Sp eech, and Signal P rocessing. [S. l.]: IEEE Press, 1990: 129-132.
[4] 王 勇, 张连海. 基于点过程模型连续语音关键词检测[J].太赫兹科学与电子信息学报, 2013, (6): 958-963.
[5] Vapnik V N. The Nature o f Statistical Learning T heory[M]. New York, USA: Springer-Verlag, 2000.
[6] 王炳锡, 屈 丹, 彭 煊. 实用语音识别基础[M]. 北京:国防工业出版社, 2005.
[7] G rezl F. Trap-based Probabilist ic Features for A utomatic Speech Recognition[D]. Brno, Czech: The Brno University of Technology at Czech, 2007.
[8] Schwarz P. Phoneme Recognition Based on Long Temporal Context[D]. Brno, Czech: The Brno University of Technology at Czech, 2008.
[9] 邓乃扬, 田英杰. 数据挖掘中的新方法:支持向量机[M].北京: 科学出版社, 2004.
[10] 张 翔, 肖小玲, 徐光祐. 基于样本之间紧密度的模糊支持向量机方法[J]. 软件学报, 2006, 17(5): 951-958.
[11] Garofolo J S, Lamel L F, Fisher W M, et al. TIMIT Acoustic-phonetic Continuous Speech Corpus[D]. Philadelphia, USA: TIMIT Ac oustic-Phonetic Continuous Spee ch Corpus Linguistic Data Consortium, 1993.
[12] Lee K F. Speaker-indepe ndent Phone Re cognition Using Hidden Markov Models[J]. IEEE Transactions on Acoustics, Speech and Signal Processing, 1989, 37(11): 1641-1648.
[13] Jurafsky D, Martin J M. 自然语言处理综论[M]. 孙志伟, 孙 乐, 译. 北京: 电子工业出版社, 2005.
编辑 顾逸斐
Continuous Speech Keyword Detection Based on Word Level Discriminative Point Process Model
WANG Yong, ZHANG Lian-hai
(School of Information System Engineering, PLA Information Engineering University, Zhengzhou 450002, China)
This paper proposes a key word dete ction method ba sed on word lev el Discriminative Point Process Model(DPPM) i n continuous speech. It computes frame-level phone posterior probability using temporal pattern and multilayer perception. DPPM sees point process produced by p hone events of the d uration as a whole. Then input Support Vector Machine(SVM) with super vector formed b y segmenting and jointing the point process representation, so can distinguish whether the point process is produced by the keyword. Due to long range c ontext dependencies, it is reasonable to expect that directly modeling e ntire words may permit a more ac curate and robust decoding of the speech signal. Experimental results show that for speech, the average recall and precision rate of keywords are above 71.5% and 84.6%, and improves significantly with language model.
Point Process Model(PPM); phoneme posterior probability; time mode; keyword detection; Support Vector Machine(SVM); Discriminative Point Process Model(DPPM)
10.3969/j.issn.1000-3428.2014.05.051
王 勇(1987-),男,硕士研究生,主研方向:连续语音关键词检测;张连海,副教授。
2013-03-05
2013-05-29E-mail:wyong0609@yahoo.cn
1000-3428(2014)05-0247-05
A
TP391
