基于标签的微博人脉网络挖掘算法和结构分析
2014-08-05张连明
王 莎,张连明
(湖南师范大学物理与信息科学学院,长沙 410 081)
基于标签的微博人脉网络挖掘算法和结构分析
王 莎,张连明
(湖南师范大学物理与信息科学学院,长沙 410 081)
针对互联网微博业务的广泛应用及其对大数据挖掘和分析的影响,提出一种基于标签的微博人脉网络挖掘算法。分析该网络的结构特征,利用微博用户标签,在模糊匹配过程中计算词语之间的匹配度时,主要考虑词语语素、次序和词长3个因素。为弱化以不同用户为起点对算法准确率的影响,分别以普通用户和名人用户为起点用户,挖掘微博人脉网络数据。同时,研究微博人脉网络的结构特性,通过分析发现微博人脉网络同时具有小世界和无标度特性。实验结果表明,运用该算法对名人用户和普通用户朋友中对IT感兴趣的人进行挖掘的误差率是可接受的。其中,挖掘10个名人用户朋友时算法的平均误差率为14.08%,挖掘10个普通用户朋友时算法的平均误差率为10.63%。
标签;微博;人脉网络;模糊匹配;数据挖掘;结构特征
1 概述
随着Web2.0技术的不断发展,社交网络发展势头强劲,微博人脉网络更是成为一个强大的新媒体社交平台[1]。微博人脉网络极大地改变了人们的社会生活方式,人们享受其带来的自由和便利。微博人脉网络结构的测量与建模、微博用户行为的分析对重构通信网络结构、个性化推荐、社会管理等方面具有一定的指导意义和实用价值。
微博人脉网络是以用户ID为节点、以用户之间的关系为边的有向网络[2]。新浪微博是中国第一家推出微博业务的门户网站,经过2年的发展,它已经和Twitter[3]一起成为全球使用最多的微博类服务网站。随着微博业务的广泛应用,微博用户剧增,微博信息更新频繁,信息传播速度越来越快[4]。微博数据的挖掘及其内在联系的理解显得非常重要[5]。
面向微博的数据挖掘技术面临2个挑战:(1)得到微博相关的所有数据;(2)所有得到的微博数据不是绝对精确的,只要在保证速度的前提下近似地反映宏观和整体情况。在以用户为中心的Web2.0环境中,用户按自己的理解为资源添加标签来对其进行标注,以更好地为用户组织资源。传统的资源推荐考虑用户和资源2个方面,即使用的是资源-用户2个维度。后来发展的网络资源在前一个的基础上增加了标签因素,也就是说推荐是基于资源-用户-标签3个维度,所以在系统向用户进行推荐的时候,与传统的推荐相比要多考虑标签这一因素。例如在新浪微博中[6],用户可以给自己设定特定的标签来表示自己的兴趣爱好,系统可以根据用户设定的标签为用户推荐其有相同爱好的人,这样就只需考虑用户-标签2个维度,在为用户进行推荐时节省了时间和资源[7]。也可根据用户设定的标签在微博领域的竞争中挖掘同类人,即有着同一兴趣爱好的用户,这不仅有利于微博企业了解特定领域用户的行为,而且能够为特定领域的用户提供个性化服务,分析信息在此类人群中的传播速度等。
本文利用微博提供的API接口获取数据,提出基于标签的模糊匹配微博人脉网络挖掘算法,分析网络的结构特性。由于标签为词语或短语,在标签的匹配过程中主要考虑词语语素、次序和词长这3个方面,计算标签之间的匹配度。此外,基于上述算法所得的微博人脉网络数据,分析其结构特性。
2 挖掘算法
2.1 算法原理
微博中使用的标签用来表示用户的兴趣,由此可以根据标签系统挖一些兴趣相投的人,即人脉聚合。用户可以给自己设定标签,标签一般为一个词语或者短语,在进行模糊匹配时首先建立一个标准标签库。
本文以获取对IT感兴趣的人为例,因每个人的习惯不同,在给自己设定标签时,表达方式不同可能表示的兴趣爱好相同,比如A用户给自己设定一个标签为程序员,B用户给自己设定一个标签程序猿,这2个标签表达方式不同,但语义相同。所以,若要对对IT感兴趣的人进行聚类,可以先建立一个标准库,这个标准库中的标签都与IT相关,当得到某一用户的标签时,拿这个用户的标签去和标准库中的标签进行匹配,如若符合要求,则将该用户的基本信息挖掘出来。
标准库的建立方式如下:
(1)用户先注册一个微博账号,在微博名人堂的IT、通信中的IT业界里选取做IT的给自己设有标签的20位名人,分别取到他们的标签。
(2)将这些标签中与IT行业无关的标签去掉。
(3)将标签中重复的、以及表达意思一样或者相近的标签去掉,得到的这些标签作为标准库。标准库中有13个标签,它们分别是IT、移动互联网、Twitter、软件、社交网络、程序员、数据库、云计算、架构设计、三网融合、编程、数据挖掘和Linux。
在汉语中,语气、语调、语素等结构的细微变化都可能造成词义的变化。为了提高挖掘算法的准确度,本文对语素、次序和词长这3个方面进行综合考虑,2个词语A 和B的相似度WordSim(A,B)可以使用下列公式来计算[8]:


其中,α,β,γ为可调节参数,且满足α + β + γ =1;Same(A,B) 为A和B中相同字的个数;Len(A)和Len(B)分别为A和B中字的个数;Once(A,B)表示当且仅当在A和B中出现一次的语素集合;若用Pfirst(A,B)表示Once(A,B)语素在A中位置序号构成的向量,Psecond(A,B)表示Pfirst(A,B)中分量按对应语素在B中次序排序生成的向量,则RevOrd(A,B)表示Psecond(A,B)各相邻分量的逆序数。
根据经验数据可知,语素占主要地位,其次是字序和词长,故在设置参数时,一般要求α大于β,远大于γ。本文取α=0.7,β=0.29,γ=0.01。
2.2 算法实现
标签是基于网络对网络资源进行自由标注的一种方法,它具有自由性[9]。对资源进行标注之后,用户可以根据标签更方便地获取自己所需的资源。在微博中,用户给自己设定的标签代表着用户的喜好,根据用户的喜好可以对其进行推荐,使其找到与之兴趣相投的人[10]。微博用户能为自己设定标签,这样为用户进行推荐时只涉及用户-标签2个维度,节省了时间和资源。
标签设定具有自由性,2个同时对IT感兴趣的人在分别给自己设定标签时,由于年龄、个人习惯、教育程度等差异,造成他们各自的表达方式可能不同,因此在挖掘对IT感兴趣的人脉网络时必需对标签进行模糊匹配。
具体方法如下:
(1)调用微博API获取用户标签。
(2)将获得的标签分别与标签标准库中的标签进行相似度计算。
(3)若计算得到的结果有一个匹配度值大于阈值µ,则认为该用户也对IT行业感兴趣,该用户满足条件,把该用户的信息挖掘出来(本文取µ=0.5)。
本文算法的伪代码如下:
算法 基于标签的模糊匹配微博人脉网络挖掘算法
输入 一个用户ID,标准标签库,阈值µ
输出 用户ID的朋友中符合条件的用户信息


假设朋友关系的层数为l,平均每个人拥有的朋友数为m,平均每个人拥有的标签数为t,标准标签库含有的标签数为s。所以MATCH()方法内层循环占用的时间为O(s),外层循环为O(t),则MATCH()方法的复杂度为O(st)。Crawler()方法外层循环为O(l),内层循环占用的时间为O(ml),所以整个算法的复杂度为O(mlst)。
2.3 匹配度计算实例
假设一个用户的标签为旅行、汽车、互联网观察、云计算中心、摄影、美食,对这6个标签与标准库中的13个标签分别进行匹配度计算,结果如表1所示。其中,该用户的标签“互联网观察”与标准库中的“移动互联网”标签相似度最大,达到0.720 0,其次是该用户标签“云计算中心”,它与标准库中“云计算”的相似度为0.527 5。该用户的“互联网观察”和“云计算中心”这2个标签与标准库中13个标签的平均相似度分别为0.085 6和0.048 0。其余4个标签与标准库中13个标签的相似度都非常低,且平均相似度均为0.005 0。显然,该用户的2个标签“互联网观察”和“云计算中心”与IT标准库中标签的相似度均大于阈值µ=0.5,可以判断该用户是一个IT人。

表1 标签的匹配
3 算法检验与评价
取2组数据集来分析和检验对IT感兴趣的人脉网络挖掘算法的准确率。为了削弱以不同类型的用户为起点对分析结果可能造成的影响,分别选取2类用户,即名人用户和普通用户,其中,名人用户为新浪微博中针对IT、通信行业中拥有真实社会身份并提供证明材料且通过认证的人群,普通用户为新浪微博中没进行认证的用户。第一组数据是在新浪微博名人堂中取10个与IT相关的名人,挖掘出他们所关注的朋友信息,从这些信息中的标签中人为地判断这些人哪些是对IT感兴趣的,统计出这个用户中对IT感兴趣的朋友的个数。因为本文算法是动态地进行人脉网络挖掘,即满足条件的用户就获取他的信息,这样就可以分别把这10个名人的朋友中同样对IT感兴趣的人挖掘出来,得到相关数据如表2所示。
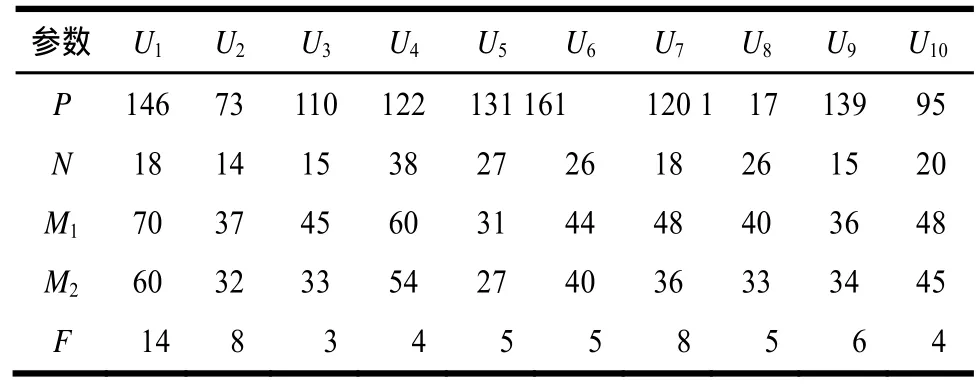
表2 名人用户朋友的相关数据
在表2中,U1,U2,…,U10分别表示10个名人用户;P表示对应名人用户的朋友个数;N表示没有给自己设定标签的朋友个数;M1表示人为地判断用户朋友中对IT感兴趣的朋友个数,其判断方法为通过新浪微博提供的API接口分别挖掘所选名人用户的朋友信息,其中包括标签信息,再根据朋友给自己设定的标签来判断该朋友是否对IT感兴趣;M2为计算机模糊匹配后挖到的朋友中对IT感兴趣的朋友个数;F表示对IT感兴趣的朋友中女性人数。
从表2可以看出,在名人的朋友中只有很少一部分用户不会给自己设定标签,同时,名人朋友中的女性朋友对IT感兴趣的人数比较少,这符合女性用户的兴趣爱好和职业选择特点。
第2组数据是选10个普通人,按同样的方法获取数据,得到相关数据如表3所示。

表3 普通用户朋友的相关数据
从表3中还可以看出,普通用户的朋友中也只有很少一部分人未给自己设定标签,且普通用户朋友中女性朋友对IT感兴趣的人数非常少。
为了分析本文算法的效率,采取人工判断方法得到的相关结果与其进行比较。图1给出了运用本文算法就用户中对IT感兴趣的朋友个数与基于人工判断得出用户朋友中对IT感兴趣的人数关系图。总体看来,本文算法挖掘出名人用户的朋友数目略小于人工判断得到的名人用户朋友数目,普通用户朋友数目略小于或等于人工判断得到的数目。普通用户的朋友中对IT感兴趣的人数相对IT名人的朋友中对IT感兴趣的人数来说少了很多,这是因为在现实生活中存在物以类聚的现象,从事IT行业的人的朋友中对IT感兴趣的人相对从事其他行业的人的朋友中对IT感兴趣的人要多些。

图1 挖掘名人用户朋友的准确率
图2给出了运用本文算法对名人用户和普通用户朋友中对IT感兴趣的人进行挖掘得到结果的误差率。挖掘10个名人用户朋友时,算法的平均误差率为14.08%,而挖掘10个普通用户朋友时,算法的平均误差率为10.63%,其中,普通用户6、7和9的所有朋友全部被挖掘出来。作为现阶段大数据挖掘面临的2个挑战之一,利用本文算法得到的微博数据允许有一定的不精确性,只要在保证速度的前提下近似地反映宏观和整体情况,这将在本文第4节中予以讨论。

图2 算法误差率
综上所述,在新浪微博中不管是普通用户还是名人用户,他们都会给自己设定标签。利用用户给自己设定的标签,构造基于标签的模糊匹配微博脉挖掘算法的准确率较高,从而本文可以根据需要挖取特定领域的用户,分析不同领域用户之间的各种关系,这样微博就能为用户提供个性服务,更好地满足用户的需求。同时还可以看出,从事IT行业的人的朋友中对IT感兴趣的人数相对较多,且对IT感兴趣的女性人数非常少,这符合IT工作性质和人们的职业选择。
基于本文算法研究了对IT感兴趣的不同数量的名人微博人脉网络,以及教育、体育等其他领域中大量名人微博人脉网络,发现算法均具有较好的性能。
4 人脉网络结构分析
在本节利用新浪微博提供的API获得的数据来研究微博人脉网络的结构特性,同时以显示其宏观性和整体性。采用广度优先策略,以笔者本人的新浪微博账号为起始用户,获取作者用户ID以及朋友ID,再以朋友ID的起始点,获取朋友的朋友ID,获取数据154 0 33条,其中包含101 496个节点,154 021条边。
聚集系数是反映一个用户的朋友之间关系的一个特征量,求出该微博人脉网络络的聚类系数为0.127。显然远大于同等规模的随机网络的聚类系数,较大的聚类系数说明所关注的对象之间很可能也互相关注,即微博人脉网络络具有高聚类特性。该微博人脉网络络的平均路径长度为4.57,这对于微博这样一种有向社会网络来说是很小的,也就是微博具有较短的平均最短路径,这也说明微博用户之间平均通过4~5个用户就能与任意一个用户建立联系。较大的聚集系数和较短的平均路径长度说明微博人脉网络络具有小世界特性。微博人脉网络的小世界特性使得信息传播的平均路径长度很小,因此信息能在微博网络中迅速地传播开来。
图3给出了微博人脉网络络节点度分布情况(节点度小于等于500的情形),显然,该网络节点度满足幂律分布,通过计算得到幂指数为1.906,这说明微博人脉网络络属于无标度网络。名人用户受到更多用户的关注,容易成为微博人脉网络中的中心节点。

图3 微博人脉网络节点度分布
5 结束语
本文提出一种基于模糊匹配的人脉挖掘算法,在标签匹配过程中综合考虑词语语素、字序、字长,通过模糊匹配可以挖掘特定领域的人,实验结果表明该算法准确率较高,同时通过分析微博网络数据表明微博网络具有小世界特性。但本文算法只能挖掘大领域的人群,无法挖掘更小领域的人,这是今后研究的方向。
[1] Kang Shulong, Zhang Chuang, Lin Zhiqing, et al. Complexity Research of Massively Microblogging Based o n Human Behaviors[C]//Proc. of the 2nd International W orkshop on Database Technology and Applications. Wuhan, China: [s. n.], 2010: 1-4
[2] Wang Rui, Jin Yongsheng. An Empirical Study on the Relationship Betwe en the Followers’ Number and In fluence of Microblogging[C]//Proc. of International Conference on E-business and E-government. Guangzhou, China: [s. n.], 2010: 2014-2017.
[3] Cha M Y, Haddadi H, Ben evenuto F, et al. Measuring User Influence in T witter: The Million Follower Fallacy[C]//Proc. of the 4th International Conference on Weblogs a nd Social Media. Washington D. C., USA: AAAI Press, 2010: 10-17.
[4] 孙晓莹, 李大展, 王 水. 国内微博研究的发展与机遇[J].情报杂志, 2012, 31(7): 25-33.
[5] 廉 捷, 周 欣, 曹 伟, 等. 新浪微博数据挖掘方案[J].清华大学学报, 2011, 51(10): 1300-1305.
[6] 张岚岚. 新浪微博的网络舆情分析研究——模型、设计与实验[D]. 上海: 华东师范大学, 2011.
[7] Golder S A, Huberman B A. The Structure of Collaborative Tagging Systems[J]. Journal of Information Seienees, 200 6, 32(2): 198-208.
[8] 朱毅华, 侯汉清, 沙印亭. 计算机识别汉语同义词的两种算法比较和测评[J]. 中国图书馆学报, 2002, 28(4): 82-85.
[9] 刘向红, 宋 文, 姚 朋. 基于标签的Folksonomy机制研究——以CiteUlike为例[J]. 图书馆理论与实践, 2010, (5): 29-33.
[10] 易 明. 基于Web挖掘的个性化信息推荐[M]. 北京: 北京科学出版社, 2010.
编辑 任吉慧
Mining Algorithm and Structural Analysis of Microblog Interpersonal Relationship Network Based on Tag
WANG Sha, ZHANG Lian-ming
(College of Physics and Information Science, Hunan Normal University, Changsha 410081, China)
For the widespread use of microblog business and the impact on data mining techniques, a mining algorithm of microblog interpersonal relationship network is proposed based on the fuzzy matching of tag, and the characteristics of the network are analyzed. Use the tag of the us ers, the algorithm mainly considers w ord morpheme, order, and word length to calculate the match degree of the words when matching the tag. For weakening the influence that using different users as a starting point may have different result, ordinary users and celebrities as a starting point separately are used. At the same time, the structural characteristics o f the netw ork are st udied, and the analysis results show that the network has small-world and scale-free properties. The results show that the mining error rate o f celebrities and common users friends who are interested in IT. When mining 10 celebrity users’ friends, the average error rate of the algorithm is 14.08%, and 10.63% for common users.
tag; microblog; interpersonal relationship network; fuzzy matching; data mining; structural characteristics
10.3969/j.issn.1000-3428.2014.05.002
1000-3428(2014)05-0007-05
A
TP393
国家自然科学基金资助项目(60973129);广东省自然科学基金资助项目(S2011010000812)。
王 莎(1988-),女,硕士研究生,主研方向:社会网络;张连明(通讯作者),教授、博士。
2013-08-15
2013-10-31E-mail:zlm@hunnu.edu.cn
