基于文本内容分析的微博广告过滤模型研究
2014-08-05高俊波
高俊波,梅 波
(上海海事大学信息工程学院,上海 201 306)
基于文本内容分析的微博广告过滤模型研究
高俊波,梅 波
(上海海事大学信息工程学院,上海 201 306)
针对新浪、腾讯等微博平台出现大量广告的问题,提出一个微博广告过滤模型。通过对数据的预处理,将采集到的微博原始数据转换成干净且计算机易处理的数据。在预处理阶段,根据微博文本的特点,对停用词表进行改进,以提高查准率,然后基于支持向量机构建一个训练分类器对数据进行训练,经过不断的学习和反馈,取得较好的分类效果。实验结果表明,该模型进行广告过滤时准确率超过90%,效果优于基于关键字的方法。
微博;文本处理;向量空间模型;支持向量机;文本分类;广告过滤
1 概述
随着微博在广大网民中日益火热,微博广告也悄然而生。但是微博广告的增多也使得微博的总体质量下滑,甚至人们在浏览微博的时候,出现整个页面有一半以上的微博是广告的情况,而真正感兴趣的信息却没有几条,严重影响了人们正常的浏览,该现象依靠一般的手段很难进行监管。因此,如何有效控制这些广告的传播,进行广告的过滤成为了一个亟待解决的问题。
信息过滤一般指从动态信息流中将用户感兴趣的信息提取出来[1-2]。微博广告过滤是信息过滤的一种,主要指从大量的微博中把微博广告删除,保留非广告内容供用户浏览。文本内容分析的方法一般有2类:(1)基于知识的方法[3],该方法主要优点是准确率高,对文本内容的理解更好,但是该方法在处理微博如此大的信息流时,速度将非常缓慢。(2)基于机器学习的方法[4],该方法速度快,大大提高了信息过滤的实时性,该方法需要大量的训练样本进行训练,而且随着网络的变化,需要不断加入新的训练样本,以保证其准确率。
本文以微博作为研究对象,基于文本内容分析,对微博广告过滤模型进行研究,提出一个高准确率的过滤模型。
2 微博特性
作为新兴的网络社交平台,越来越多的研究人员开始研究微博。它相对于传统的网络文本有以下特点[5]:
(1)文本短:微博文本字数不多于140字,而传统的网络文本(如博客、新闻)一般都有几百字甚至几千字。因此信息量少,用户可以在空闲很短的时间内就能理解文本内容。
(2)源数据易获取:现有微博平台都提供了数据接口,研究人员可以很方便地获取大量的数据,网络上也有研究者提供自己抓取的数据供他人使用,因此数据获取非常容易,方便分析与研究。
(3)语言不规范:为了表达方便,微博里面会出现大量的网络语言如“表酱紫”,意思是“不要这样子”,文本更加口语化并且不规范的词语大量出现。
(4)实时且传播速度快:微博不光有电脑客户端,还有各种移动设备客户端,因此人们可以随时随地发微博,而且现在用户越来越多,传播速度非常快,世界上任何一个角落发生的事,在几分钟之内就能让所有人知道。
广告依附微博平台进行传播,是监管部门面临的新问题。微博广告隐蔽性强,监管困难,没有专门的机构对其进行监控,缺乏对微博广告的监管手段。因此,对微博广告过滤模型进行研究具有实用价值。
3 微博广告过滤模型
本文建立的微博广告过滤模型主要由以下部分组成,如图1所示。
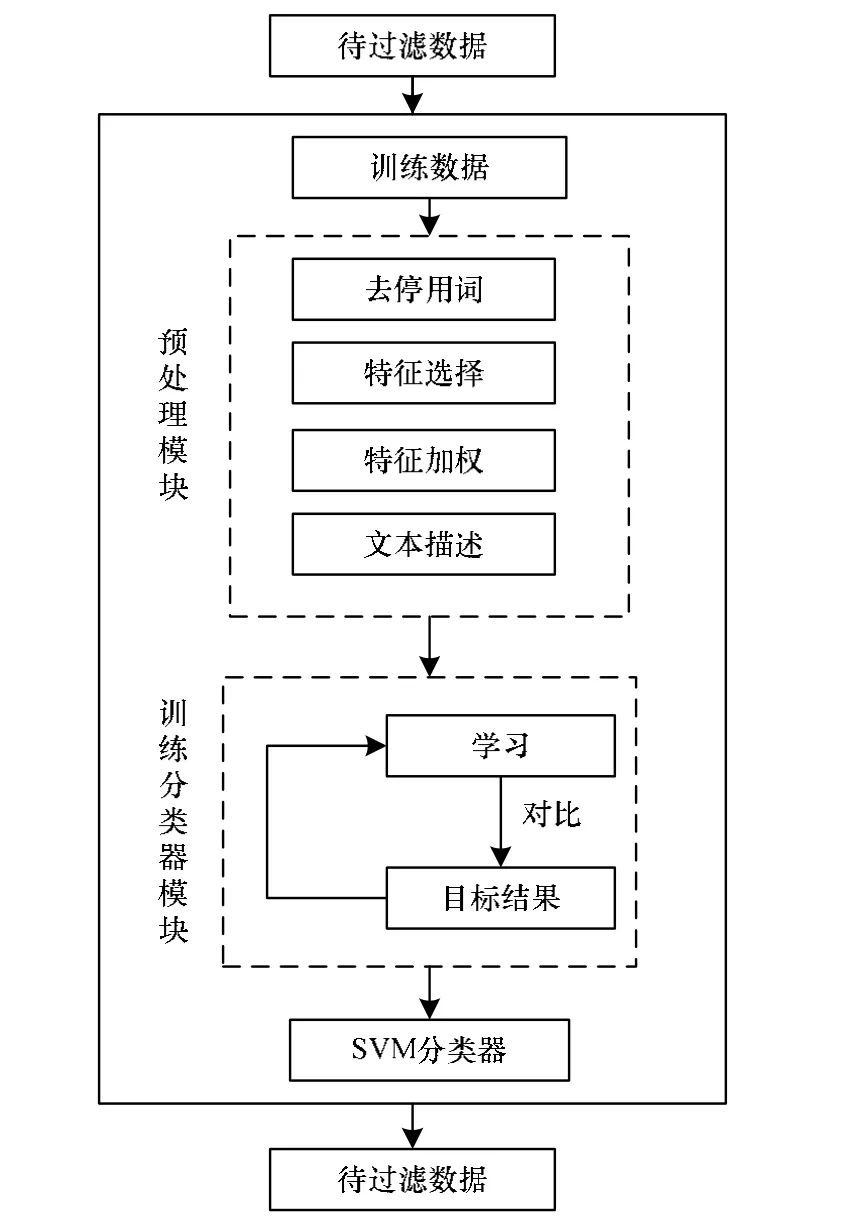
图1 微博广告过滤模型
该过滤模型主要采用支持向量机算法。首先对训练样本进行预处理,然后采用支持向量机(SVM)算法对过滤器进行训练,最终获得一个效果较理想的过滤器。
3.1 预处理
3.1.1 停用词去除
首先要对数据进行预处理。预处理部分也包括分词和停用词的去除。本文使用中科院设计的分词系统ICTCLAS,该系统对于中文的分词有非常好的效果。停用词的去除是使用一个停用词表对数据进行清洗,把对过滤无用的词或符号去掉。
大量微博中含有普通文本不具有的微博表情,清华大学计算语言学实验室统计了100万条新浪微博中使用到的全部表情数据,每个表情都有特别的意思,如“[给力]”,这些使用普通的停用词表进行处理是不可行的。为此本文针对这一特点,改进了原有的停用词表。如“@”“#”等表情及有关符号在原有停用词表中,但微博文本的特点却使这些词有其特殊的含义,所以必须保留。经过反复实验,在其他条件不变的情况下,使用改进后的停用词表取得了更好的效果。
3.1.2 特征选取
在分词过后,微博数据将被分成很多单词。使用向量表示文本数据,维度非常巨大。本文使用文本数据的维度在不进行降维的情况下,向量维度非常大,这将直接导致过滤效率下降,因此必须要进行特征降维。通过特征选取进行降维,可以把数据维度降至千级,以提高过滤效率[6]。本文采用CHI方法实现特征提取。CHI方法认为词和类别之间符合χ2分布。χ2统计量体现了词和类别之间的相关性,其值越高,词和类别之间的独立性越小,相关性越强,词对该类别的贡献越大,也表示包含该词的文本属于该类别的概率越大,χ2值为0表示两者不相关[7]。
3.1.3 特征加权
在特征选取之后,将为每个特征加权。本文采用TFIDF算法,TF-IDF特征权值计算方法是文本处理领域中常用的方法,由Salton首次论证提出[8]。它的主要思想是:一个特征词在一类文本中出现的频率越高,说明它对区分文本内容的能力越强,一个特征词在文本中出现的类别范围越广,说明它区分文本内容能力越低。目前,TF-IDF算法在自然语言处理领域广泛应用。其计算公式如下:

其中,wik表示特征项权重;tfik表示特征项tk在文档di中出现的频率;idfk表示特征项tk的文档倒数。
3.1.4 文本描述
本文利用向量空间模型对微博数据进行文本描述。在向量空间模型中,文本空间被视为一组特征向量组成的向量空间,所有的文本处理运算将在该向量空间中进行。根据上面的特征选择和特征加权的结果,向量空间模型将所有文本最终将表示成如下形式:
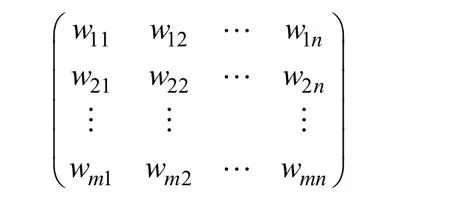
每一行表示一条文本,其中,wij表示第i个文本第j个特征的权重;n表示向量的维数;m表示文本的条数。
因为微博字数较少、特征维数较大时,最终产生的矩阵必将是一个稀疏矩阵,含有大量特征权重为0的项,用以上的形式表示将带来很多不便,而且浪费存储空间。因此每一个文本记录将采用(L T:w)的形式,其中,L表示文本标签;T表示特征项;w表示权重。例如,“世界上最好的安慰,并不是告诉对方一切都会好起来的,而是苦着脸说,哭个屁,你看,我比你还惨”,这句话经过前面的特征选取后得到4个特征词:“世界”、“安慰”、“脸”、“哭”。于是,这句话就可以表示为“1 274:0.095206 485:0.309332 502:0.432423 842:0.444010”。其中,1表示类别;274是特征词“世界”的编号;0.095206是特征的权重;后面数值表示也是如此。
3.2 SV M分类器的构建
本文构建支持向量机分类器对文本进行分类[9],并利用分类结果进行过滤。支持向量机(Support Vector Mach ine, SVM)是一种非常实用的机器学习方法,它是Cortes和Vapnik于1995年首先提出的[10-11]。相比于其他的算法,它在解决小样本、非线性以及高维模式识别问题中表现出了其特有的优势,并广泛应用于许多机器学习问题中。
文本问题是非线性的问题,把训练集数据x映射到一个高维特征空间H,并在H使用解决线性问题的方法,从而把复杂的非线性问题转化成线性问题。在高维特征空间H中寻找最优超平面,首先需要构造一个内积函数K,K表示如下:
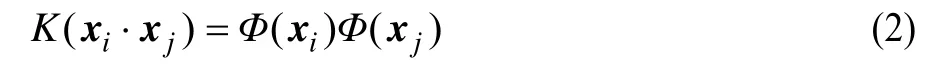
K函数的功能是利用原低维空间中的函数运算得到高维空间H中的内积运算的结果,称函数K为核函数。
因此,本文在空间变换后采用Sigmoid核函数,实现非线性问题转换为线性问题。Sigmoid核函数[12]如下:
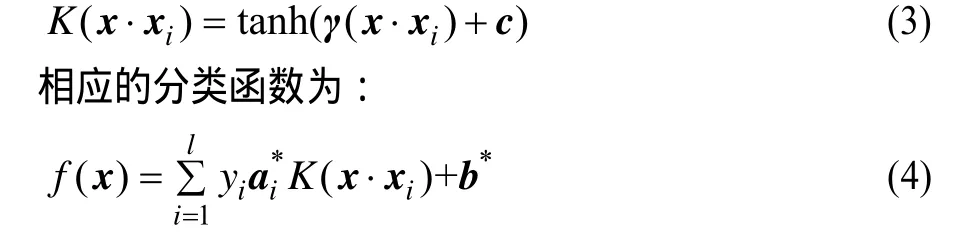
其中,x表示待分类微博文本数据;xi表示文本支持向量样本;yi表示xi对应的分类,当f(x)≥0时,则把x分为非广告,f(x)<0则分为广告。
4 实验结果与分析
4.1 数据的获取
本文实验是在Windows 7下进行的,在VC++编程环境下使用C++语言实现。目前针对微博广告过滤的研究还不多,虽然现在有很多公布的微博语料库,但是都不适合本文的研究。为此,本文自建了一个用于微博广告过滤的微博语料库。首先利用爬虫从网上获取数据,然后再进行人工标注,最终构建一个微博语料库。该微博语料库含有广告微博2 000条,非广告微博2 000条。
4.2 评价标准
本文采用查准率(p)、查全率(r)和F值(f)作为衡量过滤器性能的标准。查准率的意思是被保留下来的非广告数量除以保留下来的微博数量,体现了微博广告过滤器辨别广告的能力。查全率的含义是被保留下来的非广告数量占所有非广告数量的比例,体现了过滤器的过滤能力。F值是查全率和查准率的调和平均数。它们的公式定义如下:

其中,a表示非广告被判定为非广告的数量;b表示非广告被判定为广告的数量;c表示广告被判定为非广告的数量。
4.3 结果分析
实验1 从腾讯微博平台上随机采集1 000条微博文本,分别采用改进前的停用词表和改进后的停用词表进行实验。实验结果如表1所示。
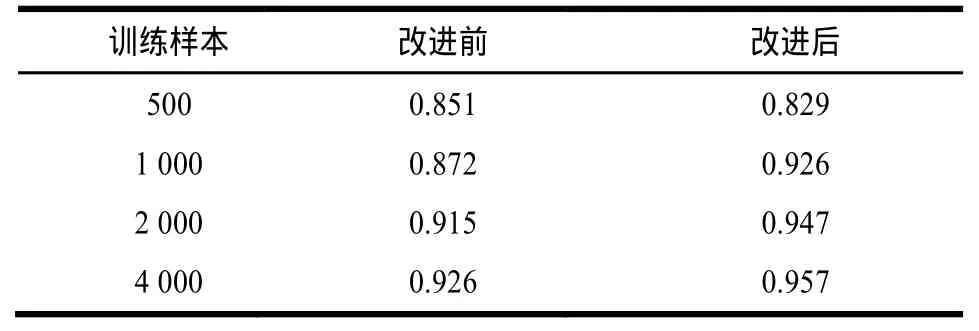
表1 停用词表改进实验的查准率
表1为2种情况下的查准率,从表中可以看出,随着训练样本的增多,改进后的效果明显优于改进前的效果。
实验2 从12月1日起到12月10日,每天从腾讯微博平台上抽取500条微博文本,使用本文微博广告过滤模型进行广告过滤实验,实验结果如表2所示。
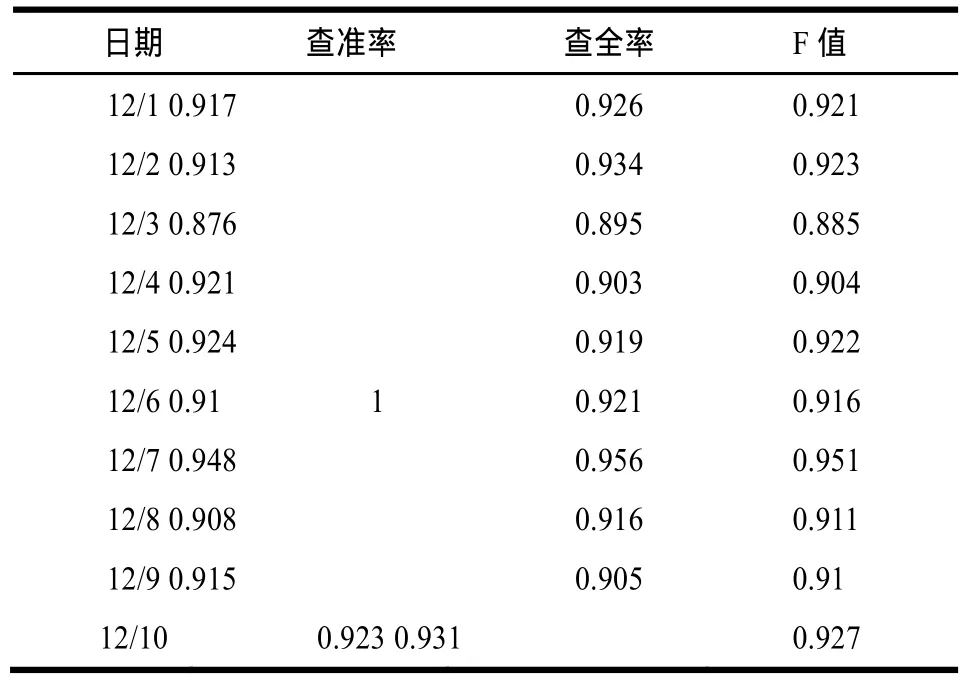
表2 广告过滤实验的结果
实验3 文献[13]对微博文本的噪音进行了过滤,取得了较好的效果。本文实验利用文献[13]采用的微博广告过滤方法重复进行实验2,并与实验2进行对比。实验结果如图2所示,其中,横轴表示日期12月1日-12月10日,纵轴表示F值,显示了使用2种方法进行实验得到的F值,实验表明本文方法优于文献[13]中的方法,且效果稳定。这主要是因为文献[13]是通过判断文本中是否含有URL以及简单的词频统计进行微博广告过滤的。本文发现因字数有限,很多非广告的微博会采用URL来链接更详细的内容,所以URL并不能作为其是否为广告的依据。相对于简单的词频统计方法,本文采用机器学习的方法显然更为优化。因此,本文使用的方法优于文献[13]的方法。
5 结束语
本文基于文本内容分析构建了一个微博广告过滤模型,实验证明该模型取得了比较好的结果。本文只针对微博文本特征进行研究,后续可以综合其他属性,如用户名、发表时间来对微博广告进行多属性综合过滤,以取得更好的效果。
[1] 牛洪波. 基于文本分类技术的信息过滤方法的研究[D].哈尔滨: 哈尔滨理工大学, 2008.
[2] Laskov P. Feasible Direction Dec omposition Algorithms for Training Support Vector Machines[J]. Machine Learning, 2002, 46(3): 315-329.
[3] 晋耀红. 基于语义的文本过滤系统的设计与实现[J]. 计算机工程与应用, 2003, 17(22): 22-25.
[4] Keerthi S, Gilbert E. Convergence of a Generalized SM O Algorithm for SVM Classifier Design[J]. Machine Learning, 2002, 46(3): 351-360.
[5] 张剑峰, 夏云庆, 姚建民. 微博文本处理研究综述[J]. 中文信息学报, 2012, 26(4): 21-27.
[6] Zhao Xi, Deng Wei, Shi Y ong. Feature Selec tion with Attributes Clustering by Maximal Information Coefficient[C]// Proc. of the 1st International Conference on Information Technology and Quantitative Management. Suzhou, China: [s. n.], 2013: 70-79.
[7] 王洪彬, 刘晓洁. 基于KNN的不良文本过滤方法[J]. 计算机工程, 2009, 35(24): 69-71.
[8] A izawa A. An Information-theoretic Perspective of tf–idf Measures[J]. Information Processing & Management, 2003, 39(1): 45-65.
[9] Phan X H, Nguyen L M, Horiguchi S. Learning to Classify Short and Spars e T ext & Web with Hidd en Topics from Large-scale Data Collections[C]//Proc. of the 17th
International Conference on World Wide Web. [S. l.]: ACM Press, 2008: 91-100.
[10] 张学工. 关于统计学习理论和支持向量机[J]. 自动化学报, 2000, 26(1): 32-42.
[11] V apnik V. The Nature of S tatistics Learning Theory[M]. New York, USA: Springer Verlag, 1995.
[12] 郭丽娟, 孙世宇, 段修生. 支持向量机及核函数研究[J].科学技术与工程, 2008, 8(2): 487-490.
[13] 王 琳, 冯 时, 徐伟丽, 等. 一种面向微博客文本流的噪音判别与内容相似性双重检测的过滤方法[J]. 计算机应用与软件, 2012, 29(8): 25-29.
编辑 任吉慧
Research on Microblog Advertisement Filtering Model Based on Text Content Analysis
GAO Jun-bo, MEI Bo
(College of Information Engineering, Shanghai Maritime University, Shanghai 201306, China)
In order to solve the problem of a large number of advertisements on Sina, Tencent microblog platform, this paper proposes a microblog advertisement filtering model. Through the data pretreatment, the raw data are converted into clean data and easy to be handled by the computer. In the pretreatment stage, according to the characteristics of the microblog, this paper emphatically improves the stop word list, and it plays a key role in improving precision. Then it builds a classifier based on support vector machine for training data, and through continuous learning and feedback, better classification results are achieved. Experimental results show that the model of advertisement filter achieves better effect, when filtering accuracy is more than 90%, which is better than the method based on keywords.
microblog; text processing; vector space model; Support Vector Machine(SVM); text classification; advertisement filtering
10.3969/j.issn.1000-3428.2014.05.004
上海海事大学科研基金资助项目(20100093)。
高俊波(1972-),男,副教授、博士,主研方向:计算智能,数据挖掘;梅 波,硕士研究生。
2013-12-19
2014-02-19E-mail:jbgao@shmtu.edu.cn
1000-3428(2014)05-0017-04
A
TP391
·先进计算与数据处理·
