一种磁盘历史数据库模型研究
2014-08-05令晓明郝玉胜
令晓明,郝玉胜
(1. 兰州交通大学光电技术与智能控制教育部重点实验室,兰州 730070;2. 国家绿色镀膜技术与装备工程技术研究中心,兰州 7 30070)
一种磁盘历史数据库模型研究
令晓明1,2,郝玉胜1
(1. 兰州交通大学光电技术与智能控制教育部重点实验室,兰州 730070;2. 国家绿色镀膜技术与装备工程技术研究中心,兰州 7 30070)
为解决流程工业中过程历史数据的存储以及大量数据的快速查询问题,提出一种基于关系数据库的磁盘历史数据库模型。在数据存储方案设计中,将关于位号和数据采集接口的静态信息存储在关系数据库中,历史数据以文件形式存放,采用三重二级缓存机制避免频繁访问磁盘,并使用经典的SDT算法对实时数据进行压缩存储,降低存储成本。数据查询方案采用三级索引文件结构,即总索引文件、二级索引文件和位号索引文件,提高查询效率。该磁盘历史数据库的第一版已经成功实现,应用结果表明,数据存储方案和查询方案的设计是合理的,100个位号的查询时间约为500 ms。
实时数据库;内存数据库;过程历史数据;位号数据;三重二级缓存机制;SDT算法
1 概述
将采集到的实时数据保存到特有的数据库中形成历史数据,为之后的再现生产过程、数据分析、应用开发提供数据支持,是流程工业信息化的必然需求[1]。对企业而言,反映生产过程的历史数据意义重大,对这些数据的分析,可以帮助改进生产工艺、提高生产效率、分析生产故障。由于反映整个生产过程的实时数据在流程工业中一般都是秒级、毫秒级的,而且必须处理数以万计的位号数据(位号是工业生产中每一个数据采集点在关系数据库中的表示形式,采集点的数值在历史数据库中被称为位号数据)。因此,传统关系数据库显然无法存储这些实时数据,即使存储其查询效率也会非常低。然而,尽管这些历史数据量大,但较高的查询效率仍是亟需解决的问题[2]。所以,相比关系数据库,生产过程的历史数据在组织方式上需要重新设计。
工业上常用的历史数据库有2种:(1)内存数据库[3]:采集的实时数据位于内存中,数据只是有选择性地被保存到磁盘,有利于先进控制和实时优化;(2)磁盘历史数据库:历史数据主要以磁盘数据文件的形式存在,可以长时间地存储大量数据,为上层应用系统提供历史数据支持[4]。目前,国际上主流的实时数据库产品有PI、IP21以及Industrial SQL Serve r等。PI系统性能优越,数据压缩比非常高,查询速度也非常快;IP21集成生产过程信息,为应用程序提供基础数据平台,其分析工具强大,图形化的界面也易于操作。Industrial SQL Server内嵌MS SQL Server,它具有一些关系数据库的特性并且继承了Mail和Internet的优势。
过程历史数据库所涉及的信息主要有静态信息、历史数据信息。核心模块包括数据采集、内存数据结构、数据的压缩存储以及高效的数据查询接口。本文在分析其他实时历史数据库优缺点的基础上,借鉴实时数据库的典型设计思想,提出一个高效率、低成本的实时历史数据库设计方案。不论是存储方案还是查询接口,都体现了“为提高数据查询效率而设计”的原则。
2 磁盘历史数据库模型架构
磁盘历史数据库采用组件方式设计,不同的组件负责实现的不同的功能,这些组件共同构成数据库服务器端[5]。整个系统架构设计为客户/服务器结构,分为历史数据库服务器端和历史数据库客户端。历史数据库服务端主要负责数据采集接口的建立、内存数据结构的维护、数据的压缩存储以及响应数据库客户端发来的查询请求。如接口名称、接口采集频率、接口服务器IP等接口配置信息以及位号名称、位号单位、位号上下限、位号回路、位号属性等位号配置信息统统存储在关系数据库中;API服务组件主要用于向服务器管理工具和客户端提供查询数据的函数,客户端通过远程调用这些函数得到满足条件的结果;另外,服务器端的数据库管理进程用于管理员维护数据库。历史数据库客户端负责向服务器端发送用户的数据查询请求,整个系统模型架构见图1。
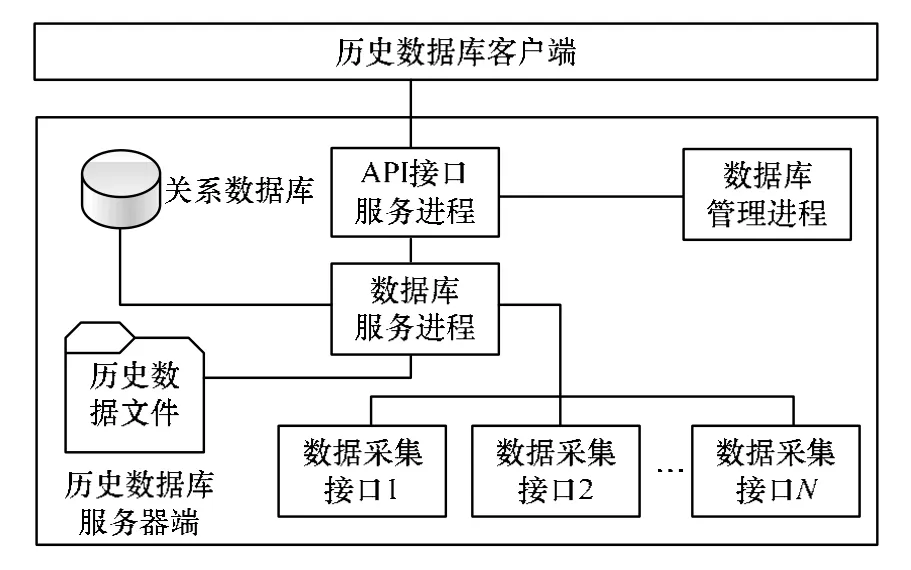
图1 历史数据库模型架构
历史数据库模型架构具体如下:
(1)数据库服务进程:数据库服务进程作为历史数据库的主引擎,主要负责接收来自数据采集接口的数据并将数据置于队列中进行缓冲;另外,它还负责将已经存满数据的二级缓存以数据块的形式保存到磁盘文件中。
(2)数据采集接口:数据采集接口主要负责从传感器获取数据,并将其发送到历史数据库服务引擎。数据采集接口在建立时需要的配置信息都是从关系数据库中读取的。每个数据采集接口可以同时采集几百个位号的数据,数据采集接口建立后应立即读取关系数据库中所属位号的所有静态信息并保留一份备份。每次数据请求都会利用这些位号的配置信息。当位号配置信息发生改变后,数据库服务进程会通知数据采集接口尽快更新所属位号的配置信息。
(3)API接口服务进程:API接口服务进程主要维护服务器端的各种API函数,这些API函数为历史数据库管理工具提供监视和管理数据库的接口,也为客户端提供查询位号数据的接口。
(4)历史数据文件:历史数据文件中存放的是经过高度优化的历史数据文件。
(5)关系数据库:关系数据库在系统中用于存放所有采集点基本配置信息和所有位号的配置信息,也可以为上层应用程序的开发提供关系数据库支持[6]。
(6)数据库管理进程:数据库管理进程是用于监视历史数据库运行的工具,通过数据库管理进程可以对数据库的运行情况进行全面的管理监控。
3 存储方案设计
在存储方案设计上,常用的做法是将传感器采集到的数据先放到内存缓冲区中,待缓冲区满后再将数据经过压缩后写到磁盘中。对于数据压缩,SDT算法是最为经典的算法之一,国内也有学者针对SDT算法作了一些细微的改进[7]。本文模型中的数据压缩算法采用经典的SDT算法。
3.1 数据存储流程
当数据采集接口将从传感器采集到的数据送达数据缓冲队列后,数据存储线程将这些数据写入到二级缓存1中,二级缓存1被写满后,数据继续被送往二级缓存2中,只有当二级缓存2被写满后,才开始往二级缓存3中写数据。与此同时,数据库存储线程会把二级缓存1和二级缓存2中的数据经过压缩处理后按照2个数据块存入文件队列的当前文件组。如果当前文件组已满,则将文件队列中的下一个文件组作为当前文件组并写入数据,存储流程见图2。
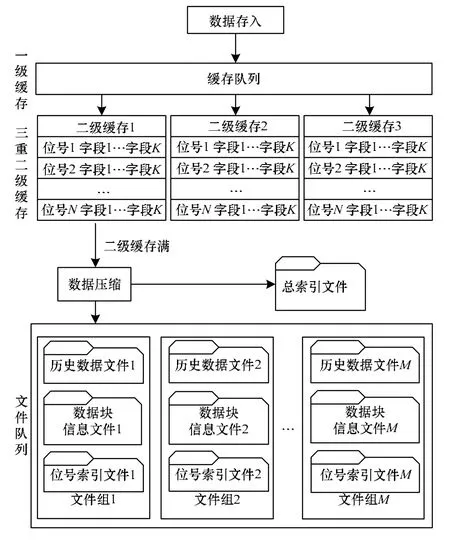
图2 历史数据存储流程
数据存储方案中使用的是三重二级缓存机制。一级缓存其本质是一个队列,数据采集模块和数据存储模块都可以访问该队列,实际上是一个将传感器上的各个位号数据送达数据库的通道。设置三重二级缓存的目的是为了增大缓存区域,当二级缓存1被写满后,将数据写到二级缓存2中,当二级缓存2写满后,继续往二级缓存3写数据。与此同时,二级缓存1和二级缓存2中的数据在经过压缩处理之后作为2个历史数据块写入到文件队列的当前文件组中。依次类推,当前一个二级缓存被写满后开始往下一个二级缓存写,当下一个二级缓存写满后,继续往第3个二级缓存写,同时还要将前2个二级缓存的数据压缩并写入文件队列的当前文件组。在只有2个二级缓存的情况下,第1个二级缓存写满后往第2个二级缓存写数据的同时把第1个二级缓存的数据写入历史文件组。引入第3个二级缓存后,等写满2个二级缓存再写第3个二级缓存的同时才保存前2个二级缓存,访问磁盘的次数减少了一半,效率提高了一倍。
任意时刻,只有一个二级缓存是当前二级缓存。这样,既避免了数据压缩保存时无法缓存历史数据的问题,又减少了磁盘的访问频次。而且,由于存在3个二级缓存,使得内存中的历史数据量增多。在具体应用中刚要求数据接口采集的那些位号往往是最近要查询的位号,而内存的二级缓存中正好是一些刚被采集到的位号,这对于查询效率的提高具有十分明显的作用。
在二级缓存中,每一个位号都占有同样大小的内存区域,存储线程将一级缓存队列中取得的位号数据,逐个写入到当前二级缓存相应的位号对应的内存区域,也就是说位号在每一个二级缓存中的排序是相同的。
除二级缓存中暂存的数据外,其余的数据全部都存储在磁盘文件中。磁盘文件按照队列的形式组织起来,队列里的基本单元是文件组。一个文件组由数据文件、数据块信息文件和位号索引文件组成[8]。数据库在运行过程中,文件队列中至少有一个文件组是当前历史文件组。前2个二级缓存被写满之后将作为2个历史数据块并产生索引信息写入到当前文件组中。只有当前文件组被写满(数据文件有大小限制,这样做的目的是为了防止数据文件过大影响查询效率)之后,才在队列中寻找下一个文件组并将其作为当前文件组。如果队列中没有可用的文件组,则按照一定的命名规则新建一个文件组。队列的长度和文件组的大小都是可以配置的。
3.2 历史数据库文件系统设计
整个历史数据库有一个总的索引文件,该索引文件记录着每一个文件组记录数据的起始时间和结束时间[9]。
文件队列中每一个文件组包括数据块信息文件、位号索引文件和数据文件。当前2个二级缓存满后,其中所有位号的历史数据依次被压缩后形成数据文件的2个数据块。同时,在数据块信息文件和位号索引文件中写入对应的索引信息。其中,数据块信息文件记录着每一个数据块记录数据的起始时间、结束时间以及该数据块相对于数据文件首部的偏移量;位号索引文件则记录着每一个位号在数据块中的起始位置和压缩后的数据量。
图3显示了数据块信息文件、位号索引文件和数据文件之间一一对应的关系。图中仅表达了数据文件的一个历史数据块。数据块信息文件中的信息包括:数据压缩存储后数据块在数据文件中的位置信息。位号索引文件中的信息是指在数据文件的数据块中每个位号数据的位置以及压缩后的数据量。
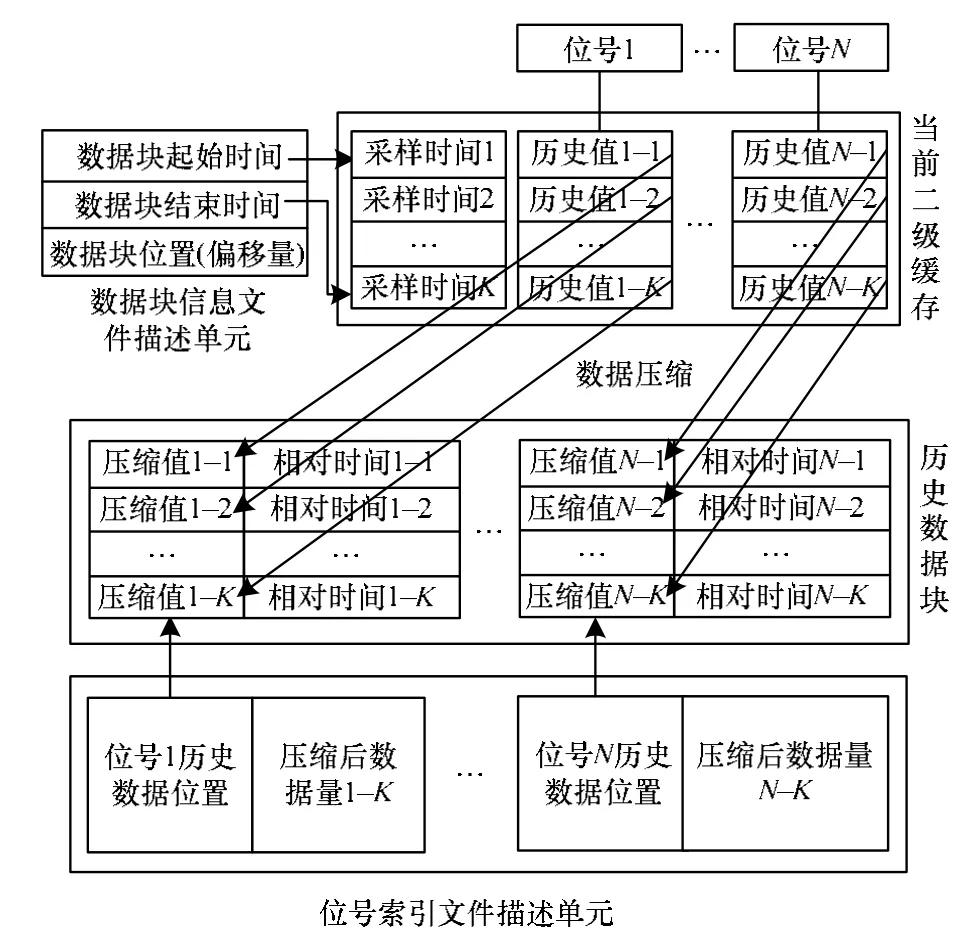
图3 历史数据文件系统结构
为了节省存储空间,数据文件中并不会保存绝对时间值,而是保存相对时间[10]。假设数据记录时间为T,数据记录所在的数据块记录的起始时间为TStart,则相对时间计算表达式为:

其中,TSample是对应数据所属位号的记录周期。简而言之,相对时间是数据记录时间与其所在的数据块记录起始时间之间的记录周期个数。一般在二级缓存中,将单个位号的采样次数限制在255以下,这样相对时间就可以用一个字节来表示,如果存储绝对时间值,则一个字节是根本不够用的。
3.3 历史数据的压缩算法
工业上对数据的压缩技术主要有无损压缩技术和有损压缩技术2种[11]。对不同类型的数据,使用不同的压缩技术才能够得到较好的压缩效果。
(1)浮点型数据的压缩。在本文模型第一版的实现中,针对浮点型数据采用美国OIS公司开发的有损压缩算法SDT[12],其原理如下:
设ΔE为SDT算法的压缩精度参数,起点t0为上一个存储的点,以距离t0为ΔE的上下两点作为支点,建立两扇虚拟的门,只有一个数据时门闭合;随着数据点的增加,门会旋转打开,门的宽度可延伸,门一旦打开就不能再闭合;只有两扇门的内角和小于180°(两扇门未平行),旋转操作就可以继续;当两扇门的内角和大于180°,就停止操作,存储前一数据点,并由该点开始新一段压缩。在图4中,经过旋转门压缩后,压缩段1由t0~t4的线代替了t0~t4的数据点;压缩段2由t4~t7的线代替了t4~t7的数据点。

图4 旋转门算法原理
SDT算法是一种有损压缩算法,但是适当的压缩偏差能够消除小信号扰动,起到过滤噪声的作用,有利于进行数据挖掘和分析。
(2)开关量数据压缩。开关量在计算机中可以用1位表示。对于开关量,本文模型中采用了变化即保存的方式,这是一种无损压缩方法。压缩模块在处理开关量数据时,都会与最后一次记录的开关量数据做比较,如果变化则保存该点,否则就不保存该点。如一串连续的开关量值为11101001,其实经过压缩后只保存10101。
(3)字符串数据的压缩。字符串是一种比较特殊的数据类型,单个数据的长度可能比较长。因此,有可能要使用二次压缩。针对原始字符串数据,首先通过有损压缩算法筛选出需要保存的字符串历史数据,然后再根据具体情况做无损压缩处理。对于字符串数据的压缩,一般采用标准的LZW算法[13]。
3.4 SD T算法仿真
使用Matlab对SDT压缩算法作仿真,实验数据采用一条正弦曲线上的629个数据点。经过SDT算法压缩处理之后,需要存储在历史数据文件中的点只有41个,由于时间值采用相对时间的形式存放,一个位号在某一时刻的数据只占5 Byte(1 Byte存放相对时间,4 Byte存放数据)。这样629个位号在某一时刻的存储空间只有41×5 Byte=205 Byte,仿真结果如图5、图6所示,其中,横轴是离散的时间点,表示采集位号数据的某一时刻;纵轴表示在某一时刻位号的采集值。

图5 S DT算法仿真结果(所有数据点)

图6 S DT算法仿真结果(需要存储的数据点)
4 历史数据查询接口设计
4.1 设计方案
基于数据库的应用,其本质是对数据的查询。本文模型中的存储方案在设计时充分考虑了数据查询效率。总索引文件、文件组中的数据块信息文件和位号索引文件构成了查询的索引结构[14],如图7所示。
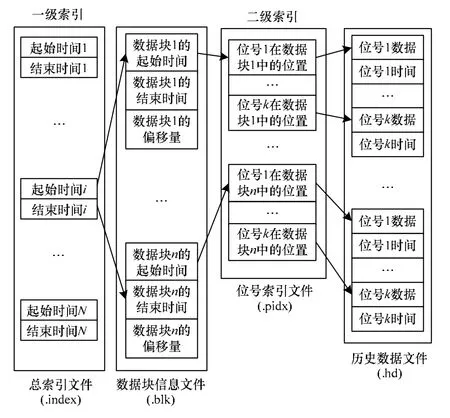
图7 历史数据查询索引结构
数据查询的基本形式为:从Ts时刻起,到Te时刻结束,查询步长为Tspan的位号集合S={S1, S2,…,Sn}在所有时刻的值。
具体的查询流程为:
(1)查看三重二级缓存中的历史数据是否符合查询条件。如果所查询数据全部位于某一个二级缓存当中,则直接将数据返回;否则,转到步骤(2)。
(2)进入总索引文件,顺序比较查询时间,假设Ts所代表的时间比总索引文件中最早的时间Tbegin还要早,则将Ts设置为Tbegin,然后依次顺序比较直到查出Te所在的信息单元。同时,记录下查询过程中涉及到的历史文件组的名称(为了便于查找,本文模型中历史数据文件组名称按照其在文件队列中的序号命名)。若找不到查询的时间范围,则返回。
(3)根据步骤(2)所得二级索引信息,顺序查询数据块信息文件中的各信息单元,记录所有符合时间条件的历史数据块信息,即历史数据块的起始位置、起始时间以及对应历史数据块在历史数据文件中的序号。
(4)进入位号索引文件信息单元,查询位号历史数据信息,即单个位号历史数据在历史数据块中的位置和压缩后的数据量。
(5)根据各个符合条件的历史数据块的起始位置,进入历史数据文件的各个历史数据块读取符合时间条件的历史数据和相对时间,然后再根据不同位号数据类型进行插值。开关量位号某时刻的插值为上一个保存时刻的值;对于浮点型数据,需要根据查询时刻前后2个保存时刻的值进行线性插值,并根据压缩偏差进行适当的微调。对于字符串数据,要根据压缩算法(一次压缩或者二次压缩)进行解压。
4.2 实验结果及分析
使用客户端程序TagMonitor分别请求100个、500个、1 000个、1 500个、2 000个和2 500个位号在某一时刻的实时数据值(在程序请求数据前和请求数据成功后都记录时间,以这2个时刻的差值作为查询时间),系统反馈查询结果的时间如表1所示。

表1 系统反馈查询结果的时间 ms
可以看出,随着位号数量的增加,服务器返回位号数据的时间也在逐次增加,基本呈线性增长态势,并没有出现随着位号数量的增加而突然出现查询时间激增的问题,完全可以满足一般小型应用系统的要求。
5 结束语
本文设计的历史数据库模型,有效利用了传统的开源关系数据库。对于位号在30 000个以下的小型历史数据库系统提供了一种低成本的解决方案。存储方案中引入的三重二级缓存机制不但减少了访问磁盘的频次,也使得查询效率非常高。但由于采用了SDT算法,其压缩比随着数据量的变化波动较大,因此今后将对压缩算法进行改进,使数据压缩比保持较高水平。
[1] 毛国君, 段立娟, 王 实, 等. 数据挖掘原理与算法[M].北京: 清华大学出版社, 2005.
[2] 高宁波, 金 宏, 王宏安. 历史数据实时压缩方法研究[J].计算机工程与应用, 2004, 40(28): 167-170.
[3] 许贵平, 蔡博克. 支持实时内存数据库不间断服务的恢复技术[J]. 计算机工程, 2008, 34(6): 70-71.
[4] 陆会明, 周 钊, 廖常斌. 基于实时数据库系统的历史数据处理[J]. 电力自动化设备, 2009, 29(3): 127-131.
[5] 刘云生. 实时数据库系统[M]. 北京: 科学出版社, 2012.
[6] Sch wartz B. High Perfor mance M ySQL[M]. 宁海元, 译.北京: 电子工业出版社, 2013.
[7] 赵利强, 于 涛, 王建林. 基于SQL数据库的过程数据压缩方法[J]. 计算机工程, 2008, 34(14): 58-59.
[8] 嵇月强, 王文海. 工业历史数据库的研究[J]. 工业控制计算机, 2007, 20(8): 43-44.
[9] 文水英. 实时数据库中历史数据压缩算法的研究[D]. 长沙:中南大学, 2008.
[10] Kao B, Garcia-Molina H. An Overview of Real-time Database Systems[M]. Stanford, USA: Stanford University, 1993.
[11] 曲奕霖. 流程工业历史数据的压缩策略与压缩方法研究[D].杭州: 浙江大学, 2010.
[12] 张景涛, 王 华, 王宏安. 实时数据的存取与压缩[J]. 化工自动化及仪表, 2003, 30(3): 47-50.
[13] 徐 慧. 实时数据库中数据压缩算法的研究[D]. 杭州:浙江大学, 2006.
[14] 纳永良. 大型实时数据库关键技术及应用研究[D]. 北京:北京化工大学, 2010.
编辑 陆燕菲
Research on a Disk History Database Model
LING Xiao-ming1,2, HAO Yu-sheng1
(1. Key Laboratory of Opto-Technology and Intelligent Control, Ministry of Education, Lanzhou Jiaotong University, Lanzhou 730070, China; 2. National Engineering Research Center of Green Coating Technology and Equipment, Lanzhou 730070, China)
In order to solve th e problem of stor ing process history data and fastly querying lar ge amounts, this paper proposes a disk history database model based on relational database. In the storage design, static information about the tags and data collect interfaces are stored in relational database. History data is stored in files, and a mechanism named triple secondary cache is used in RAM, thus the frequency of disk access is re duced. Meanwhile, the S DT algorithm is also used in data processing to reduce storage cost. In order to improve the efficiency of query, three-level index file structure which consists of a total index file, secondary index file and tag number index file is adopted in the data query scheme. The first version of the model is implemented. Applications result shows that the storage and query scheme is reasonable, and it returns the results of 100 tag numbers in about 500 ms.
real-time database; memory database; process history data; tag number data; triple secondary cache mechanism; SDT algorithm
10.3969/j.issn.1000-3428.2014.05.006
国家“863”计划基金资助项目(2012AA04027)。
令晓明(1975-),男,副教授,主研方向:计算机控制技术,实时操作系统,数据库技术;郝玉胜,硕士研究生。
2013-09-24
2013-12-05E-mail:daryhao@126.com
1000-3428(2014)05-0026-05
A
TP392
