微博数据通用抓取算法
2014-08-05卢体广刘任任
卢体广,刘 新,刘任任
(湘潭大学信息工程学院智能计算与信息处理教育部重点实验室,湖南 湘潭 4 11105)
微博数据通用抓取算法
卢体广,刘 新,刘任任
(湘潭大学信息工程学院智能计算与信息处理教育部重点实验室,湖南 湘潭 4 11105)
目前常用的网络爬虫和基于微博API抓取数据的算法很难满足舆情系统对微博数据的需求。为此,提出一种模拟浏览器登录微博抓取网页数据的算法,以方便地获取任意微博用户网页上的所有数据。通过微博用户之间的关系构建用户网络,并通过该网络发现新用户。为获取微博上有质量的数据,建立一个完整的数学模型,根据用户的发帖数、发帖频率、粉丝数、转发数、评论数等因素来计算用户影响力,以影响力为主要因子构建优先队列,使得影响力越大的用户数据采集频率越高,同时计算时间间隔以兼顾非活跃用户的数据获取。实验结果表明,该算法具有通用性强、完全无需人工干预、获取信息的质量高、速度快等优点。
微博数据;模拟登录;用户网络;用户影响力;网络舆情;优先队列
1 概述
随着互联网的迅猛发展,网络舆论也逐渐被人们关注。近几年来,微博用户呈现出几何式的增长(如新浪微博的用户已经超5亿[1]),为舆论的产生和传播提供了良好的平台。从近期各级地方政府、事业单位、企业等纷纷开通官方微博的动作不难看出微博在当前网络舆论中的重要地位。微博的崛起使得舆论阵地逐渐的从各大贴吧、论坛转向微博。对政府而言,第一时间掌握网络上的各种舆论消息,并及时疏通、引导和处理是十分重要的。
目前市场上的各种舆情监测系统都是针对传统社交网络的,针对微博的非常少。这是因为微博出现的时间较短,研究较少,加上微博数据获取存在不小的技术障碍,所以要对微博进行自动化的舆情监测还比较困难。但近几年的很多舆情大事件都由微博首先爆料并迅速发酵,所以对微博进行舆情监测是必不可少的。为解决这一问题,本文对此展开了深入的研究,并较好地解决了微博舆情监测中的一些难点问题。
传统网络舆情监测系统的工作流程大致如下:首先从被监测社交网络平台上不断抓取数据;然后对数据进行统计分析;最后对分析结果进行评判,形成舆情报告。和传统的社交平台不同,微博(包括新浪、腾讯、搜狐、网易等主流微博)上的数据抓取是非常困难的。普通的网络爬虫在获取网页数据时,首先会检查该网站根目录下的Robots.txt文件,按照该文件的要求来抓取网页,这些被抓取的网页必须以静态的文件形式存在[2-3]。一般的网站为了被搜索引擎检索,会专门为爬虫提供一套静态文件。而以新浪为首的微博网站均未提供静态数据(这可能是与微博数据更新太快有关,系统同时提供动态和静态2套数据负担太大,也很难同步),所以正常的网络爬虫无法获取微博中的数据。目前谷歌、必应、搜狗、即刻搜索等商业搜索引擎都无法提供微博数据搜索服务;唯一能提供微博数据的是百度,但它所提供的微博数据是向微博运营商购买的,时效性并不太好。
由于以上原因,微博数据的获取成为了微博舆情监测的一个难点。要解决这一问题,有3种思路:(1)利用系统提供的推送功能来获取用户所发表的微博。推送功能是所有的微博运营商都提供的一项功能:用户只要注册为微博用户并称为其他用户的粉丝,当用户登录微博之后,那些被关注的用户所最新发表的微博就会有选择地被推送到该用户的首页上。(2)利用微博平台提供的API接口来完成这项工作[4]。(3)如同网络爬虫的基本思路一样,对获取的网页信息进行分析,从中发现新的链接,然后再从新的链接处获取新的信息。
以上3种算法各有优劣。第(1)种算法只适合小规模的数据抓取,其优势在于信息获取的效率较高,实现起来也比较容易;缺点是系统对单一用户关注的人数和推送的微博条数都有限制,若想全面获取微博上的新数据,需要大量的手工劳动(即注册多个用户名,并为每个用户添加大量的关注对象),另外无法即时获知新注册的用户。第(2)种算法能及时获取有效数据,但在获取的速度、调用次数、Oauth2.0过期时间等多方面都有诸多限制[4];并且不同的微博平台提供的API不一样,如新浪微博与腾讯微博所提供的API不同,所以该算法的通用性不强。第(3)种算法最为灵活,但实现难度比较大,目前还没有成熟的解决方案。为此,本文提出了模拟登录来抓取网页、并通过微博之间的关系来发现新用户的算法。
2 单个微博网页数据的获取
通过对上述3种算法的分析,可见如果能解决单个微博网页的抓取问题,那么就能采用同样的算法抓取微博上其他用户的网页,再辅以一定的用户发现和合适的数据抓取策略,就能完成整个微博数据的抓取,因此,第3种算法是最有前景的方案。
由于目前的微博系统都需要用户登录才能浏览,采用模拟浏览器向服务器发送数据包的方式模拟登录,然后通过请求数据的方式来实现单个微博网页信息的获取。这种算法所受限制较少,可以比较自由地采集数据。该算法的基本过程如下:
(1)利用cookie来实现微博的身份认证(即登录,cookie定义于RFC2109中,是为了辨别用户身份而储存在用户本地终端上的数据)[3]。
(2)将cookie添加到请求网页的数据包的头部。
(3)将构造的数据包通过HTTP协议发送给服务器,然后接收服务器的反馈信息。
通过上述3步就能实现完成单个网页的抓取(其中有些具体的技术障碍需要克服,限于篇幅在此不展开论述)。使用Java编制了模拟登录程序,顺利地完成了单个网页抓取任务。
在解决单个网页数据获取的问题之后,为完成整个微博数据的抓取需要制定合适的抓取策略。这里有2个最主要的问题需要解决:
(1)新用户的发现。因为本文编制的爬虫预先并不知道微博中有哪些用户存在,需要有一种算法自动获得这些用户的有关信息。
(2)不同微博用户的活跃程度不一样,怎样能获取到最新的、最有价值的微博数据。
对于问题(1),通过构建微博用户网络加以解决。对于问题(2),采用优先队列来加以解决。
3 微博用户网络的构建
定义 一个图G是一个有序三元组G=<V,E,ϕ>,其中,V是非空顶点的集合;E是边的集合,且E和V交集为空;ϕ是E到V中某2个顶点的映射[5]。当图中的边具有权值时,这种带权的图称为网,如图1所示。

图1 顶点和边构成的网络
和网络爬虫的工作原理一样,可以通过某一个微博用户页面上的链接来不断地挖掘新的微博用户,然后访问新的用户,如此重复,就能形成一个微博用户网络。在这个网络中,以微博用户为顶点,用户与用户之间的关系作为边,边上的权值是用户关系的一种量化,这样就能构建出微博用户网络,并能通过这个网络发现新微博用户[6]。在微博中,活跃用户(后文中有解释)与其他用户的联系比较多,在所构造的微博用户网络中表现为该顶点的度相对比较大;反之,如果某个顶点的度相对较小甚至为0,那么表示该顶点对应的用户在微博上不活跃,即僵尸粉。
假定:任何一个微博系统中的绝大多数正常用户之间都存在直接或者间接联系,也即他们在同一个连通分量g 中[5]。通过遍历这个连通分量可以找到绝大多数的正常用户。僵尸粉对应的是孤立节点k,无法通过g找到该孤立节点k;同样,k节点所产生的信息也无法通过联通分量g传播出去。因此,类似k这样的点是不能产生或传播信息的。因为这类用户在舆情系统中没有多少研究价值,所以可以忽略掉那部分未处于用户网络中的用户。
在这个用户网络中,用户之间的关系用边来描述。由于每种关系的重要程度不一样,因此选择用向量V= <A,D,R,C>来表示,向量V中的每个分量分别代表一种关系的权值。微博用户之间的关系主要有4种:(1)关注:当A 对B感兴趣时,可以关注B,这样B所发表的微博就能自动地显示在A的主页上,用字母A来表示,其权值为固定值。(2)被关注:即表示粉丝,其意思和关注相反,A关注B,那么A称为B的粉丝,用字母D来表示,其权值为固定值。(3)引用:即转发某人发表的微博,用字母R来表示,引用次数即为对应的权值。(4)评论:对某人发表的微博加以评论,用字母C来表示,评论次数即为对应的权值。这几种关系因用途不同而拥有不同的权值,所以需要分别记录,在做数据挖掘时这些权值有很大的作用。
和一般的静态网络不同,这个用户网络是一个动态的网络,它需要在网络遍历的过程中不断加入新顶点,采用的算法如下:
Step1随机选取一顶点为种子。
Step2抓取该顶点URL的网页内容,并分析其内容,提取其中的链接,将其放入队列linkQueue中。
Step3linkQueue中是否还有链接,如果有,转Step4;否则转Step5。
Step4检查该链接是否为微博用户,如果是,转Step6;否则转Step3。
Step5分析该网页内容是否有微博,如果有,将微博存入数据库,转Step9;如果没有,转Step9。
Step6检查该用户是否已经在网络中存在,如果存在,转Step7;否则转Step8。
Step7根据链接的性质,修改其权值向量中的对应分量,然后转Step3。
Step8在这两点之间建立新的边,并赋上相应的权值,再转到Step3。
Step9判断网络中是否还有未访问的点,如果有,进入下一顶点,转Step2;否则转Step1。
因为新用户的加入过程是永远不会终止的,所以该算法是一个无限循环。通过上述算法,就能不断地扩充微博用户网络,从而能抓取到微博上绝大部分的正常用户。一般静态网络的访问有深度优先遍历和广度优先遍历[7]。根据用户网络的实际情况,选取广度遍历算法来访问该用户网络。
在不断扩充网络的同时,还需要将这些微博用户按照一定的规则放到队列中。如果发现的是新用户,则放入新用户队列。对于每个用户,都用唯一的一个数字表示。这样用二分法查找很快能确定该用户是否访问过。对于任何一个新用户,一旦被访问一次之后,即变为老用户,按照预先确定的规则放入另外一个专用于存放老用户的优先队列。
考虑到算法的通用性,采用单线程来访问这2个不同的队列。为了能并行地访问这2个队列,采用按照比例访问的算法,即在新队列中访问了n个用户之后,就在老用户队列中访问k×n个用户。在实验中,n和k分别取值为1 和100。
新用户队列的建立和访问都比较简单,有很成熟的算法,在此略过。
4 优先队列的构建以及优先级的计算模型
由于微博用户数目十分庞大,为及时更新微博数据,因此需要在带宽、时间均有限的条件下尽量获取有质量的数据。所谓有质量的数据有2种:(1)内容上具有爆炸性或者与普通网民利益密切相关,能迅速吸引网民的注意。例如7.23动车事故、转基因的争论等。(2)拥有庞大粉丝数的用户所发的每条微博都能被大量粉丝看到,也极易被转发。这2类信息的共同点是容易吸引网民注意,并迅速传播从而形成网络舆情。所以,针对整个微博网络上的信息,更关注那些被用户转发、评论的次数多的数据。
在保证数据质量的前提下还要尽量抓取更多的数据,这就需要对不同用户采用不一样的访问频率,本文选择了优先队列。因为可以通过优先队列中的优先级来控制出队的顺序。
4.1 优先队列
队列即先进先出(first in first out)线性表,只允许在队尾添加数据,在头部删除数据。优先队列是队列的一种扩展,它将队列中的元素赋予不同的优先级,然后按照优先级次序出队列。优先队列的计算算法有基于binary heaps的改进算法[8]、基于reduce number of comparison的算法[9]、基于self-adjust的算法[10]、基于double-ended的算法[11]和基于Distribution se nsitive的算法[12]等。按照优先权值的大小不同,分为最小优先队列和最大优先队列,本文选择的是最大优先队列。能否达到预期的抓取效果,其关键在于队列中优先级的设计是否合适。而优先级的设计需要从实际情况来考虑各方面的因素,并且不断地调整各个因素所占的比重,以达到期望的效果。
4.2 优先级的计算模型
显而易见,对于内容相同的微博,影响力[13]越大的用户所发表的微博产生的影响也越广泛。新浪微博对用户影响力的定义如下:衡量一个用户在微博中影响力的大小,可以通过该账号的发微博情况、被评论、转发的情况以及活跃粉丝的数量来综合评定,其公式如下:

其中,X为用户的影响力;H表示活跃度;C是传播力;F表示覆盖度。活跃度代表该账号每天主动发微博、转发、评论的有效条数;传播力与该账号的微博被转发、被评论的有效条数和有效人数相关;覆盖度的高低则取决于该账号微博的活跃粉丝数的多少[14];wi为权重,其和为1。
根据式(1),在设计优先级计算公式时主要考虑以下因素:(1)微博用户的粉丝数目。(2)发言量,指发表、评论、转发微博的有效条数。(3)传播力,为微博被转发、评论的次数。(4)关注其他用户的数目。(5)时间间隔,表示距离上次抓取的时间,这个是为防止优先级较小的用户没机会被抓取。
将优先级分为2类,除了时间因素外的其他数值的和称为活跃值;时间因素需要单独考虑。下面是优先级的计算公式:

其中,Y为该用户最终的优先级值;F为粉丝数;H为发言量;C为传播力;G为关注数;T为抓取该用户的时间间隔。
4.2.1 粉丝数
在新浪微博中,粉丝的数量是相差较大的,一些人的粉丝能到千万级,而有些人的粉丝数目只有几个,两者之间的数值相差较大,离散程度很高,数据的可比性不强。对粉丝数取对数,减少两者之间的离散程度,具体计算公式如下:

其中,F表示该用户的粉丝值;f为该用户所拥有的粉丝数目;n表示从众多用户中随机选取的n个用户;fj是第j个用户的粉丝数目。如果真数为0,则将其变为1,这样变换对后面计算影响非常小。
4.2.2 发言量
发言量为用户在一段时间内所发表、评论、转发的微博条数,其计算公式如下:
其中,hi表示第i个用户在最近一段时间内平均每天所发表、评论、转发的微博数目;H是第i个用户的发言量,随机选择的n个用户,对其平均一天发表、评论、转发微博条数取平均。hi的计算公式如下:

其中,N为固定值,表示所发表、转发、评论微博的数目;Te表示最后一条微博发表的时间;Ts表示最初发表时间。
4.2.3 传播力
因为舆情在很大程度上是因传播而形成,所以传播力是本文计算的重点。在微博中,传播力主要由微博的转发和评论来决定。其计算公式如下:

其中,C表示用户的传播力;a表示a条最新微博;cm则是该用户所发表的第m条微博的转发数目;cn则为该用户所发表的第n条微博的评论数目;wf和wc为转发数目与评论数的权重,其和为1;Cforword是随机选取n个人所求的平均转发数目;Ccomment即平均的评论数目,其计算公式如下:
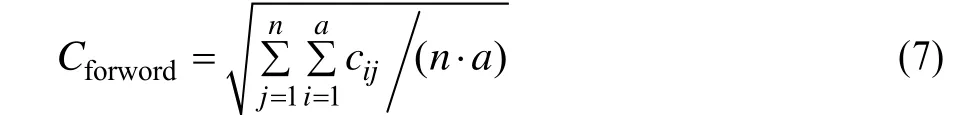
其中,cij表示第j个人的第i条微博的转发数。Ccomment的计算公式和式(7)相同,只是其中的cij表示的是第j个人的第i条微博的评论数。
4.2.4 关注数
G代表用户所关注的其他用户的数目,其计算公式与式(3)类似,如下:

其中,gj表示第j个用户所关注的人数;n表示从众多用户中随机选取的n个用户。
4.2.5 时间间隔
时间间隔是为那些影响力较小的用户而设计的。在待抓取的优先队列中,当优先级最高的元素出队列之后,会重新计算其优先级,然后再加入到队列中,由于其优先级较高,因此插入的位置会比较靠前,从而导致队列后面的元素没有机会移动到队头。为防止这种情况出现,引入了时间间隔这个因子来降低高优先级元素的优先级值。其计算公式如下:

其中,j表示抓取该用户的第j次;k为权值。y是前文中提到的活跃值,是粉丝数、关注数、发言量和传播力的综合体现,其计算公式为:

而Ys是随机选取n个样本并计算其y值然后求平均得到的平均值。J为一常数,表示连续计算的最大次数,当j的值不小于J时,就将其归零。
以上就是各个因子对优先级的影响以及计算公式。至于系数的确定,主要通过逻辑推理和多次实验来确定。最终得到如表1所示的权值表。

表1 权重的取值
优先级的大小主要从粉丝值、发言量、传播力、关注值4个方面来考虑;同时为防止队列中影响力小的用户没有被抓取的机会,又辅以时间间隔这个因素来定时调节队列中靠后的用户。这样就在保证数据质量的情况下抓取更多数据。
5 实验结果
在采集速度方面,新浪微博API和模拟浏览器登录抓取有较大的差别,表2是以上2种算法的实验结果。
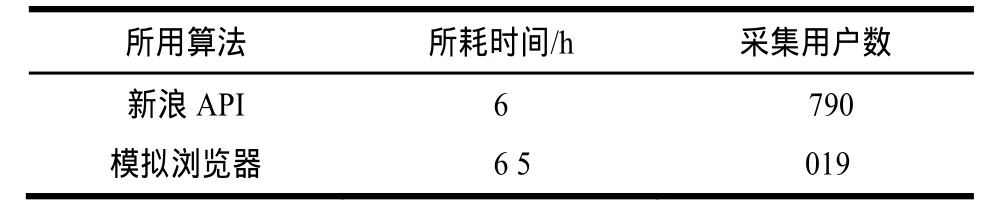
表2 2种采集方式的性能对比
从表2中可以看出,模拟浏览器登录抓取的算法在采集用户上有较大的优势。具体原因是新浪微博API的限制,每个用户最多每小时爬取150次。模拟浏览器算法的速度瓶颈在于新浪微博对IP的限制,每个小时最多只允许同一个IP访问1 000次。
根据以上算法设计了Java程序,在一台普通PC机连续运行12 h,以新浪微博的大V用户李开复为种子开始,共抓取了10 043个用户的数据,获取了92 363条微博,并同时发现了2 000 115个新的微博用户。将这些已抓取的用户按照式(10)计算其活跃值。将用户按照活跃值的大小划分为4个等级,分别是非常活跃、比较活跃、一般活跃、不活跃,其活跃值的范围如表3所示。

表3 微博用户按活跃值的分类
在表3中,Avg是随机选取的N个样本,然后按照式(10)计算出的活跃值再取平均的值。从实验结果来看,非常活跃的用户大概200个左右,占总人数的2%,计算出最高值是32.384 5;这些人拥有如下特点:(1)粉丝比较多,通常在千万级以上;(2)发表的微博多,平均一天有5条以上的微博。(3)微博被转发评论的次数也很多,平均都在千次左右。而较活跃的用户则相对较多,达到1 400人左右,占总人数的14%,这部分人的粉丝在百万级别,发表的微博也比较多,但这些微博被转发、评论的次数则明显较小,一般在1 000以内。一般活跃的用户则更多,约有2 600人,占总人数的26%左右,这部分用户的粉丝数大多在一万到十万之间,并且评论、转发别人的微博相对较多,而原创的相对较少,并且这些原创的微博被转发、评论的次数相当小,都在100以内。最后一部分用户最多,大约6 000人,这部分人基本上就是所谓的僵尸粉,即发表、转发、评论的微博数目都很少,几乎为0。
优先队列的抓取方式在数据质量上有比较大的改进,实验结果如表4所示。

表4 非优先和优先的性能对比
从表4中可以看出,优先队列非常适合于采集频率不同的情况,实验结果说明同优先级的计算模型比较成功,能在相同条件下抓取更多有质量的数据。
6 结束语
本文主要介绍如何灵活地抓取微博数据,并在一定时间内更新具有较大影响力用户的数据,重点分析了微博用户网络的构建过程以及更新数据时需要用到的优先队列算法,并对其优先级的设计进行了详细阐述。从实验结果可以发现:(1)这种算法能不断发现新用户,并抓取该用户的有用信息,是一种行之有效的算法;(2)优先队列的优先级的设计比较合理,获取的数据质量较高,即时性比传统算法的性能更好,能较好地适应舆情网络监测的要求。但是该算法还有很多值得研究的地方。比如,在构建用户网络时,如何来降低存储空间的需求;对于影响力不大的用户,是否更好的更新方式。另外算法设计时只考虑了单机单线程的情况,而在实际应用中,需要将其并行化处理来加快速度。这些问题都是后续研究的重点。
[1] 新华网. 新浪微博用户数超5亿[EB/OL]. (20 13-02-21). http://news.xinhuanet.com/newmedia/2013-02/21/c_12436989 6.htm.
[2] 新浪网. 新浪微博API开放平台[EB/OL]. (2013-0 3-12). http://open.t.sina.com.cn/wiki/index.hph.
[3] 李晓明, 闫宏飞, 王继民. 搜索引擎: 原理, 技术与系统[M]. 北京: 科学出版社, 2005.
[4] 周立柱, 林 玲. 聚焦爬虫技术研究综述[J]. 计算机应用, 2005, 25(9): 1965-1969.
[5] 刘任任. 离散数学[M]. 2版. 长沙: 湖南科学技术大学出版社, 2001.
[6] 戴月卿, 钟 玲, 林柏钢, 等. 基于微博的人物关系网络挖掘系统[J]. 信息网络安全, 2013, (2): 83-86.
[7] 严蔚敏, 吴伟民. 数据结构[M]. 北京: 清华大学出版社, 2009.
[8] Liu Y ujie, Spear M. A Lock-f ree, Ar ray-based Pr iority Queue[J]. ACM SIGPLAN Notices, 2012, 47(8): 323-324.
[9] Elmasry A, Jens en C, Kat ajainen J. M ultipartite Pri ority Queues[J]. ACM Transactions o n Algorithms, 2008, 5(1): 1-19.
[10] Elmasry A. Pairing Heaps with Costless M eld[M]. B erlin, Germany: Springer, 2010.
[11] Cho S, Sahni S. Mer geable Double-ended Priority Queues[J]. International Journal of Foundations of Comp uter Science, 1999, 10(1): 1-17.
[12] Elmasry A, Farzan A, Iacono J. A Priority Queue with the Time-finger Property[J]. Journal of Discrete Algorithms, 2012, 16(1): 206-212.
[13] 于 洪, 杨 显. 微博中节点影响力度量与传播路径模式研究[J]. 通信学报, 2012, 33(Z2): 97-102.
[14] 新浪网. 新浪微博中影响力的定义[EB/OL]. (2013-03-1 2). http://data.weibo.com/top/help.
编辑 任吉慧
Universal Crawling Algorithm for Microblogging Data
LU Ti-guang, LIU Xin, LIU Ren-ren
(Key Laboratory of Intelligent Computing and Information Processing, Ministry of Education, Institute of Information Engineering, Xiangtan University, Xiangtan 411105, China)
Currently, Web crawler and microblog API which are used to grab data f rom the microblog are difficult to satisfy the public opinion system demands for microblog data. To settle the problem, this paper presents a feasible solution which is the similar as the browser login microblog to capture data from Web p ages. It can easily get all data from any microblog users. On this basis, it construc ts a microblogging network through interconnections among users, and discovers new users through it. In order to get high quality data, it builds mathematical models to calculate the user’s influence index by using posting number, posting frequency, fans number, forwarding number and comments number. Moreover, it builds priority queue according to the calculated influence factor, which let those that have bigger influence index have high acquisition frequency. Finally, it calculates time interval to balance the lower frequency of non-active microblog user. The experimental results sh ow that this method not only processes easily and has higher speed but also can o btain high qu ality information and have huge versatility.
microblogging data; analog login; user network; user influence; Internet public opinion; priority queue
10.3969/j.issn.1000-3428.2014.05.003
湖南省自然科学基金资助项目(12JJ3066);湖南省高校科技成果产业化培育基金资助项目(11CY018);湖南省重点学科基金资助项目。
卢体广(1988-),男,硕士研究生,主研方向:社会计算,信息安全;刘 新,副教授;刘任任,教授、博士生导师。
2013-10-31
2014-01-27E-mail:lutiguang7@163.com
1000-3428(2014)05-0012-05
A
TP311.13
