LDA模型在微博用户推荐中的应用
2014-08-05杜永萍
邸 亮,杜永萍
(北京工业大学计算机科学与技术学院,北京 1 00124)
LDA模型在微博用户推荐中的应用
邸 亮,杜永萍
(北京工业大学计算机科学与技术学院,北京 1 00124)
潜在狄利克雷分配(LDA)主题模型可用于识别大规模文档集中潜藏的主题信息,但是对于微博短文本的应用效果并不理想。为此,提出一种基于LDA的微博用户模型,将微博基于用户进行划分,合并每个用户发布的微博以代表用户,标准的文档-主题-词的三层LDA模型变为用户-主题-词的用户模型,利用该模型进行用户推荐。在真实微博数据集上的实验结果表明,与传统的向量空间模型方法相比,采用该方法进行用户推荐具有更好的效果,在选择合适的主题数情况下,其准确率提高近10%。
主题模型;潜在狄利克雷分配;微博;用户模型;兴趣分析;用户推荐
1 概述
传统的主题挖掘是采用文本聚类的算法[1],通过向量空间模型(Vector Space Model, VS M)将文本里的非结构化数据映射到向量空间中的点,然后用传统的聚类算法,如基于划分的算法(如K-means算法)、基于层次的算法(如自顶向下和自底向上算法)、基于密度的算法等[2],实现文本聚类。聚类结果可以近似认为满足同一个主题。但是,这种基于聚类的算法普遍依赖于文本之间距离的计算,而这种距离在海量文本中是很难定义的;此外,聚类结果也只是起到区分类别的作用,并没有给出语义上的信息,不利于人们的理解。
LSA(Latent Semantic Analysis)是文献[3]提出的一种基于线性代数挖掘文本主题的新方法。LSA利用SVD(Singular Value Dec omposition)的降维方法来挖掘文档的潜在结构(语义结构),在低维的语义空间里进行查询和相关性分析,通过奇异值分解等数学手段,使得这种隐含的相关性能够被很好地挖掘出来。研究显示[4],当这个语义空间的维度和人类语义理解的维度相近时,LSA能够更好地近似于人类的理解关系,即将表面信息转化为深层次的抽象[5]。
PLSA(Probabilistic Latent Semantic Analysis)是文献[6]在研究LSA的基础上提出的基于最大似然法和产生式模型的概率模型。PLSA沿用了LSA的降维思想:在常用的文本表达方式(tf-idf)下,文本是一种高维数据;主题的数量是有限的,对应低维的语义空间,主题挖掘就是通过降维将文档从高维空间投影到了语义空间。PLSA通常运用EM算法对模型进行求解。在实际运用中,由于EM 算法的计算复杂度小于传统SVD算法,PLSA在性能上、在处理大规模数据方面也通常优于LSA。
潜在狄利克雷分配(Latent Dirichlet Allocation, LDA)在PLSA的基础上加入了Dirichlet先验分布,是PLSA的一个突破性的延伸。LDA的创始者Blei等人指出,PLSA在文档对应主题的概率计算上没有使用统一的概率模型,过多的参数会导致过拟合现象,并且很难对训练集以外的文档分配概率。基于这些缺陷,LDA引入了超参数,形成了一个文档-主题-单词三层的贝叶斯模型[7],通过运用概率方法对模型进行推导,来寻找文本集的语义结构,挖掘文本的主题。目前,LDA模型已经成为了主题建模中的一个标准,在多个领域中都有应用,特别是在社会网络和社会媒体研究领域最为常见[8],具有很好的研究与应用前景。在微博主题挖掘中具有很大的潜力[9-10],通过对其进行改进,可以很好地应用于社交网络应用中。
本文在LDA主题模型的基础上,通过分析微博用户的特点,给出了用以表示用户主题的模型,并提出一种基于该模型的用户推荐方法。
2 LDA主题模型
LDA模型是一个层次贝叶斯模型[11],它有如下3层:
(1)单词层:单词集V={w1, w2,…,wV}是从语料库中提取出来的去除停用词后的所有单词集合。
(2)主题层:主题集φ={z1, z2,…,zk}中的每一个主题zi都是一个基于单词集V的概率多项分布,可以被表示成向量φk=<pk,1,pk,2,…,pk, v>,其中,pk, j表示单词wj在主题zk中的生成概率。
(3)文档层:对于单词层,采用了词袋方法。每一篇文档被表示成一个词频向量di=<tfi,1,tfi,2,…,tfi, V>,其中,tfi, j表示单词j在文档i中出现的次数;就主题层而言,文档集可以表示成θ=<θ1, θ2,…,θD>,其中每一个向量θd=<pd,1,pd,2,…,pd, K>表示了一个文档的主题分布,pd, z是主题z在该文档d中的生成概率。
其图模型表示如图1所示。LDA模型采用Dirichlet分布作为概率主题模型中多项分布的先验分布。其中,D为整个文档集;Nd为文档d的单词集;α和β分别是文档-主题概率分布θ和主题-单词概率分布φ的先验知识。
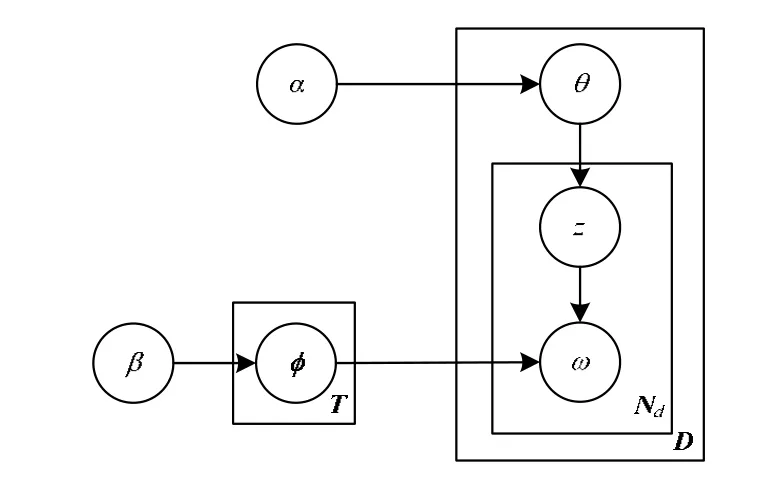
图1 L DA图模型
3 基于LDA模型的微博用户推荐
3.1 基于LDA模型的微博用户模型
标准的LDA模型是基于文档-主题-词的一个三层贝叶斯模型[11]。在构建用户的兴趣模型时,用户的兴趣可以被定义为用户对各个主题的喜好程度。因此,主题模型下用户-主题生成概率多项分布表示了用户的兴趣。
使用主题模型构建基于内容的微博用户兴趣模型时,需要将一个用户下的所有微博合并成一个文档进行主题生成,从而得到用户生成主题的概率多项分布,即用户的兴趣模型。该兴趣模型的用户层就对应到了LDA模型中的文档层,即将文档-主题-词的三层关系变为了用户-主题-词的关系,其矩阵表示如图2和图3所示。

图2 标准LDA模型的矩阵示意图
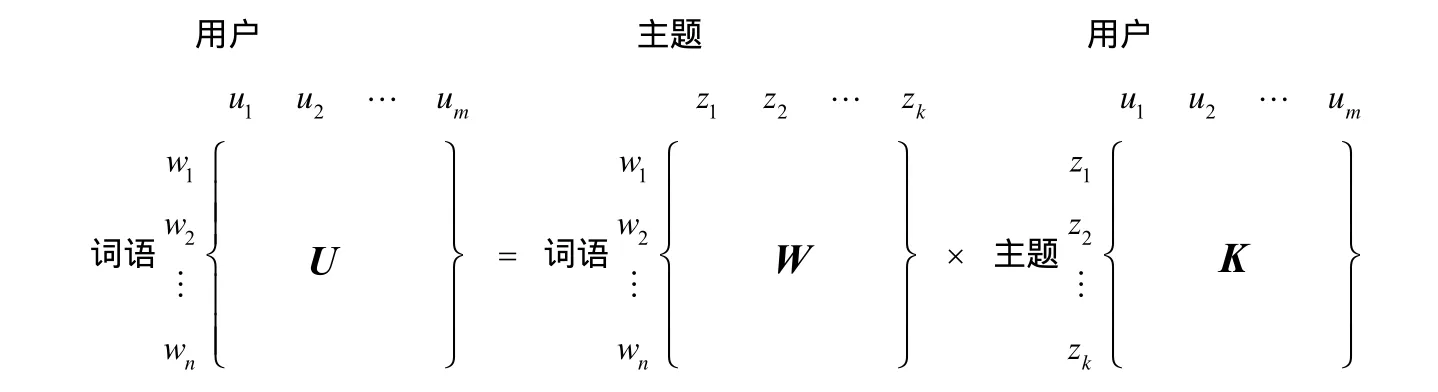
图3 基于LDA的微博用户模型的矩阵示意图
在用户层中,对于用户集合U={u1, u2,…,um},其中的每一个用户ui,都可以由该用户发布的所有微博得到一个词频向量fui=<tfi,1,tfi,2,…,tfi, V>。从主题层面而言,用户ui可以被表示成向量θui={pui ,1,pui,2,…,pui, k },其中,pui, z表示主题z在用户ui中的生成概率,用它来表示用户ui对主题z的喜好程度。从而,用户层构成了用户与主题的生成关系,生成主题用户模型,其矩阵表示如图4所示。

图4 用户主题矩阵
3.2 用户相似度计算
KL(Kullback Leibler)散度,俗称KL距离[12],常用来衡量2个概率分布的距离,其计算公式如下:

KL散度是不对称的,即DKL(P||Q)≠DKL(Q||P),可以将其转换为对称的,如下式:

在基于LDA的用户主题模型中,由主题的概率分布来表示用户的兴趣,如图4用户主题矩阵所示。因此,用户间的相似程度可以由用户主题分布间的KL距离来表示,用户相似度计算如下所示:

其中,Sij为用户ui和uj的相似度;Ui和Uj分别是它们的主题概率分布。该值越大,则两用户越相似。
3.3 用户推荐
假设同一个领域中的用户为兴趣相近的用户,且他们的微博也主要是围绕自己感兴趣的话题来发布。
U为用户集合,对用户ui和用户子集Ui,其中,ui∈U,且Ui=U-ui。按照式(3),对用户集合Ui中的每个用户分别与ui计算相似度,然后对Ui中的所有用户按照相似度值进行升序排列,这样排在前面的用户就和用户ui更相似,更有理由推荐给用户ui。
提取前t个用户作为推荐给用户ui的推荐列表,Uti= {u1, u2,…,uj,…,ut}。对推荐集合Uti中的每个用户uj,分别判断其是否与用户ui属于同一领域,若属于同一领域,则认为将uj推荐给用户ui是正确的。用户ui的推荐准确率计算公式如下:

其中,t≤Ni-1,Ni为用户ui所属领域下的用户数,t的取值不超过该领域下的用户总数减1(除去用户ui自身)。
某领域p下用户的推荐准确率计算公式如下:

其中,Np为领域p下的用户总数。
在系统中,所有用户的推荐平均准确率计算公式如下:
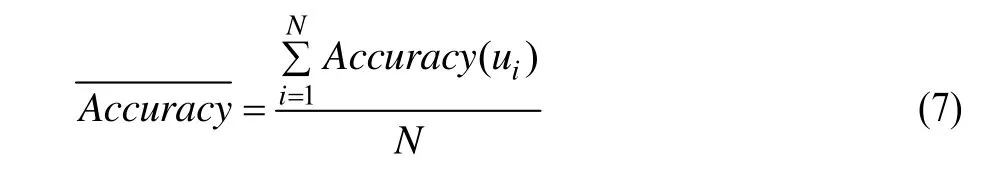
其中,N为用户总数。
3.4 用户推荐系统结构
基于上文介绍的用户兴趣模型,设计了微博用户推荐系统,主要由3个部分组成:
(1)数据采集层,负责微博数据的采集及预处理,预处理包括对部分字数过少微博的过滤。
(2)数据处理层,对过滤后的微博数据做进一步处理,包括分词、去停用词、词性过滤等,生成用户的词语向量,从而得到整个用户集合的向量表示,利用LDA用户模型进行求解,从而进行主题挖掘和用户推荐。
(3)数据展现层,展现数据处理层生成的结果,包括模型生成的主题的展示、用户推荐的关联图等。
系统结构如图5所示。

图5 用户推荐系统结构
在图5中涉及到的关键技术主要有:
(1)数据采集器使用开源的Java工具包HttpClient实现。调用新浪微博API后,获取到json格式的数据,需要将其解析为数据对象,然后存入数据库。
(2)微博及用户数据采用关系型数据库来保存。这里使用MySQL,因为其体积小、速度快,并且是开源的。
(3)数据处理过程中用到了哈工大的IRLAS分词器,对微博进行分词和词性标注。
(4)构造出主题模型后,将用户推荐结果存入NoSQL数据库,这里使用Neo4j,它是一个用Java实现、完全兼容ACID的图形数据库,数据以一种针对图形网络进行过优化的格式保存在磁盘上,它的内核是一种极快的图形引擎,具有数据库产品期望的所有特性。用Neo4j存储用户推荐结果可以方便快速地实现前台的展示。
(5)可视化主要通过js及其第三方开源库来实现,例如D3 js库可以实现主题关键词的标签云展示及用户推荐的关联散点图等。
3.5 算法流程
基于LDA模型的微博用户推荐算法如下:
(1)建立用户模型:将用户的所有微博合并到一起,微博数据已经经过了分词处理,得到代表每个用户的微博单词词频向量fu。对模型进行求解,得到每个用户的主题概率分布,如图4所示。
(2)用户相似度计算:借助于概率分布之间的KL散度计算方法,用户之间的相似度使用式(3)来计算,该值越大则表示用户间的主题概率分布越相似,也即用户间的兴趣越相似,双方可以相互作为被推荐给对方的候选用户。
(3)用户推荐:假设同一个领域中的用户为兴趣相近的用户,根据用户相似度获取用户的推荐列表,取前t个用户作为推荐用户,利用式(4)~式(7)计算推荐准确率。
4 实验结果与分析
4.1 数据采集与预处理
实验利用新浪微博API采集用户数据和微博数据。主要用到2个接口:获取系统推荐的热门用户列表接口和获取单个用户微博列表的接口。
根据推荐用户接口抓取来自不同领域的认证用户数据,获取了8个比较常见的领域,分别是科技、体育、房产、动漫、娱乐、健康、汽车和媒体。此外,利用用户微博列表接口采集每个用户的最新微博,最多不超过300条。
由于微博数据来自于互联网,噪声大,需要做一定的预处理,主要有以下4个步骤:
(1)将回复数和转发数低于10的微博去除。
(2)根据用户实际有效的微博数量,从每个领域中各选取80个用户。选取的过程会过滤掉有效微博数量小于10条的用户,最终实验数据集的总用户数为640个。
(3)去掉微博数据中特有的一些对主题挖掘无用的特征,如表情符号、@目标、分享目标以及URL网址等。
(4)对微博数据进行分词,过滤掉停用词,根据词性标注保留对主题挖掘提供有用的信息的名词、动词。
最终用于实验的数据组成如表1所示。

表1 实验数据分布
4.2 实验参数设置与对比实验
LDA模型的求解过程使用Gibbs抽样方法,模型参数值根据文献[11]取经验值:其中,α=50/T(T为主题数),β=0.01。主题的个数取经验值进行对比实验,由于用户来自于8个领域,实验中主题数设置为8~15。分词器采用哈工大IRLAS分词器,使用通用停用词词典,共1 24 1条停用词项。
为了进一步对比实验效果,把本文算法与下面2个算法进行比较:
(1)基于向量空间模型(VSM)的算法
使用传统的VSM方法建立用户模型,同样对于用户集U={u1, u2,…,um},将用户ui的所有微博数据进行预处理后得到其单词权重向量Ui=<wi,1,wi,2,…,wi, V>,其中,wi, j表示单词j在用户ui的微博数据中的权重。这里的权重计算采用TF-IDF值。用户间相似度的计算采用常规的向量夹角的余弦值来计算:
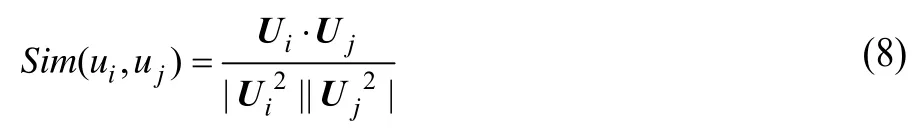
(2)基于隐马尔科夫模型(HMM)的算法
应用文献[13]中介绍的方法。使用HMM建立用户的模型,λ=(A, B,π,N, M),然后使用KL散度计算用户间的相似度,计算公式为:
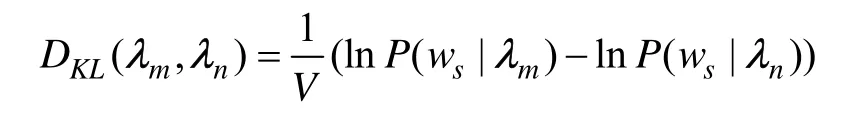
以上2种算法的用户推荐准确率的计算方法和LDA用户模型的计算方法相同,不再赘述。
4.3 评价结果
4.3.1 基于Perplexity指标的评价结果
Perplexity[9]是一种评估语言模型生成性能的标准测量指标。Perplexity值表示模型生成测试集中新文本的似然估计,它用来衡量模型对新文本的预测能力。Perplexity值越小,似然估计就越高,也就表示模型的生成性能越好。其计算公式如下:

其中,Utest为测试集用户;N为测试集用户总数;wui为用户ui的微博所包含的单词集合;p(wui)是用户ui的微博单词集合在用户模型下的生成概率;Nui为用户ui微博集合的单词总数。实验中选取了数据集的10%作为测试集。
实验结果如图6所示。

图6 用户兴趣模型的Perplexity评价结果
从图6中的数据可以看出,基于LDA的用户模型的生成能力要优于标准LDA,这说明将同一用户的微博合并为一条文本的方式是有效的。
4.3.2 主题分布
选取一些有代表性的主题分布生成的标签云图,如图7所示,可以很明显地看出,这些主题分布分别代表了科技、体育、房产、动漫、娱乐、健康、汽车、媒体相关的主题。

图7 主题分布词云图
4.3.3 用户推荐质量
用户推荐质量的衡量需要从实际的应用效果入手,由于该模型可以对具有相似兴趣的用户进行推荐,这里使用上述介绍的用户推荐准确率来衡量模型的质量。LDA用户模型和VSM方法在各领域下的准确率对比结果如表2~表5所示,分别对应式(4)中t取10,20,40,79时的结果。

表2 t=10时的实验结果

表3 t=20时的实验结果

表4 t=40时的实验结果

表5 t=79时的实验结果
分析以上实验结果得出结论:
(1)推荐性能与主题数相关。随着主题数的增加,推荐效果逐渐变好,在主题数为14时,推荐效果最好,当主题数进一步增加时,效果基本保持稳定甚至略微有所回落。主题数越大,模型的计算量也越大,耗时越久,综合可虑,在主题数取14时,无论是推荐效果还是计算效率都有着不错的结果。对比VSM模型的实验结果后还可以看出,当主题数大于10的情况下,基于LDA的用户兴趣模型的效果均比传统的VSM有所提高。而对比HMM模型的实验结果可以看出,当主题数达到12时,基于LDA的用户兴趣模型的效果和HMM模型相当,在主题数大于14的情况下,效果明显好于HMM模型。
(2)推荐性能在不同领域下有着较明显的差别。LDA用户兴趣模型对体育领域和科技领域的用户推荐效果较好,尤其是体育领域,K取10时其准确率甚至达到了82%,远好于其他领域。房产和汽车领域的效果略微偏差,分析这些领域用户的微博,发现这可能是由于这些领域用户发布的微博比较宽泛,涉及的内容和主题比较繁杂,对主题挖掘的干扰比较大;而体育领域和科技领域的用户发布的微博则相对更具有明确的主题,领域凝聚力更强,实用性更高,因此更有挖掘主题的价值。如何减少这类微博对用户推荐的干扰,是今后的工作重点。
5 结束语
本文针对微博数据这种短文本,结合LDA模型的文档-主题-词分层模型的特点,用微博数据的集合来代表用户,进而提出了用户-主题-词的用户兴趣模型,不仅能有效挖掘用户所关注的主题,并可进行用户推荐等社交网络应用。在今后的研究工作中将继续优化微博用户兴趣模型的效果和效率,减少无意义微博对主题挖掘的干扰,以适应于各种不同的领域,尝试结合更多的社交网络特征,并实现实时的微博数据处理。
[1] Kang J H, Lerman K, Plang prasopchok A. Analyzing Microblogs with Affinity Propagation[C]//Proc. of the 1st Workshop on Social Me dia An alytics. New Y ork, USA: ACM Press, 2010: 67-70.
[2] Xu Rui, Wunsch D. Survey of Clustering Algorithms[J]. IEEE Trans. on Neural Networks, 2005, 16(3): 645-678.
[3] Deerwester S, Dumais S, Landauer T, et al. Latent Semantic Analysis for Multiple-type Interrelated Data Objects[C]//Proc. of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. New York, USA: ACM Press, 2006: 236-243.
[4] Blei D. Probabilistic Topic Models[J]. Communications of the ACM, 2012, 55(4): 77-84.
[5] Zelikovitz S, Hirsh H. Using LSI for Text Classification in the Presence of Background Text[C]//Proc. of the 10th International Co nference o n Inf ormation and Knowledge Management. New York, USA: ACM Press, 2001: 113-118.
[6] K im Y M. An Extension of PLSA for Document C lustering[C]//Proc. of the 17th ACM Conference on Information and Knowledge Management. New York, USA: ACM Press, 2008: 1345-1346.
[7] Tang Xuning, Yang C C. TUT: A Statistical Model for Detecting Trends, Topics and User Interests in Social Media[C]//Proc. of the 21st ACM International Conference on Information and Knowledge Management. New York, USA: ACM Press, 2012: 972-981.
[8] Wei Xing, Croft W B. LDA-based Document Models for Ad
Hoc Retrieval[C]//Proc. of the 29th Annual International ACM SIGIR Confere nce on Research and Development in Information Retrieval. Ne w York, US A: ACM Pr ess, 2006: 178-185.
[9] 张晨逸, 孙建伶, 丁轶群. 基于MB-LDA模型的微博主题挖掘[J]. 计算机研究与发展, 2011, 48(10): 1795-1802.
[10] 张晓艳, 王 挺, 梁晓波. LDA模型在话题追踪中的应用[J].计算机科学, 2011, 38(Z10): 136-139.
[11] Blei D M, Ng A Y, Jordan M I. Latent Dirichlet Allocation[J]. The Journal of Machine Learning Research, 2 003, 3(3): 993-1022.
[12] 孙昌年, 郑 诚, 夏青松. 基于LDA的中文文本相似度计算[J]. 计算机技术与发展, 2013, 23(1): 217-220.
[13] Zeng Jianping, Zhang Shiyong, Wu Chengrong. A Framework for WWW User Activity Analysis Based on U ser Interest[J]. Knowledge-based Systems, 2008, 21(12): 905-910.
编辑 任吉慧
Application of LDA Model in Microblog User Recommendation
DI Liang, DU Yong-ping
(Institute of Computer Science and Technology, Beijing University of Technology, Beijing 100124, China)
Latent Dirichlet Allocation(LDA) model can be used for identifying topic informati on from large-scale document set, but the effect is not ideal for short text such as microblog. This paper proposes a microblog user model based on LDA, which divides microblog based on user and represents each user with their posted microbolgs. Thus, the standard three layers in LDA model by document-topic-word becomes a user model by user-topic-word. The model is a pplied to user recommendation. Experiment on real data set shows that the new provided method has a better effect. With a proper topic number, the performance is improved by nearly 10%.
topic model; Latent Dirichlet Allocation(LDA); microblog; user model; interest analysis; user recommendation
10.3969/j.issn.1000-3428.2014.05.001
国家科技支撑计划基金资助项目(2013BAH21B00);北京市自然科学基金资助项目(4123091);北京市属高等学校人才强教深化计划基金资助项目“中青年骨干人才培养计划”(PHR20110815)。
邸 亮(1988-),男,硕士研究生,主研方向:自然语言处理;杜永萍,副教授。
2013-09-22
2013-12-05E-mail:dltt67@163.com
1000-3428(2014)05-0001-06
A
TP311.13
