基于数据挖掘技术的SF6气体分析和故障诊断研究
2013-09-22张鑫
张鑫
(广西省电力公司柳州供电局,广西 柳州 545005)
1 引言
目前,国内状态检修主要还是利用状态监视和诊断技术获取设备的状态和故障信息,进而做出检修决策的阶段。状态检修的重点在于预测故障发展趋势,在故障发生前,根据设备状态决定对其检修。因此,在电气设备的状态监测与故障诊断中,寻找设备故障与其外在表象之间的相关关系是很重要的。当建立故障与表象之间的相关关系越全面、越准确,进行故障诊断准确性就越高。
在生产实践中比较常用的判断方法是利用统计方法,从大量的现场检修记录中,总结出一些存在于故障状态与表现之间的相关关系,从而为故障的判定提供依据,但其具有一定的局限性[1],统计方法的本质是一种归纳总结的方法,因此很难发现隐含在大量数据中的结构。在日常的检修试验中,基层单位积累了大量的试验数据,这本身就是个巨大的资源,如何利用这个资源并发挥其巨大的作用显得越来越重要。
数据挖掘就是为了满足大量数据的处理,并从中抽取有价值的潜在知识,而应运而生的。它可以利用计算机技术对大量数据进行自动处理,从而发现其中隐含的关系或规律[2,3]。数据挖掘作为信息处理的一个新领域,发展很快,在科学技术领域也发挥着越来越大的作用。本文对数据挖掘技术在SF6气体分析和故障诊断做一尝试研究,通过探索希望对数据挖掘技术在在线监测上的发展上做一努力。
2 数据挖掘
2.1 数据挖掘
数据挖掘是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的,但又是潜在有用的信息和知识的过程[4]。数据挖掘需要明确的是:数据源必须是真实的、大量的、可能含噪声的:从数据源中可发现用户感兴趣的知识;发现的知识是可接受、可理解、可运用的;并不需要发现放之四海而皆准的知识,仅支持特定的发现问题(即支持特定主题的知识发现);它主要以数据库或数据仓库作为工作对象,但是也可以直接从操作数据中挖掘信息。
2.2 基于粗糙集的模糊神经网络
进行数据挖掘可采用许多不同的算法,如神经网络、决策树、遗传算法和粗糙集等。模糊神经网络一方面可以对专家描述的事件直接编码,跟踪推理过程,使网络中的权值具有明显的含义;另一方面,它也具有学习功能,可以通过学习提高代码精度。模糊神经网络一般有5层,分别是输入层,模糊化层,规则控制层,或神经元,输出层,如图1所示。

图1 模糊神经网络结构
粗糙集理论是一种刻划不完整性和不确定性的数学工具,能有效地分析和处理不精确、不一致、不完整等各种不完备信息,通过发现数据间隐藏的关系,揭示潜在的规律,从而提取有用信息,简化信息的处理[5]。理论中应用决策表描述论域中对象。它是一张二维表格,每一行描述一个对象,每一列描述对象的一种属性。属性分为条件属性和决策属性,论域中的对象根据条件属性的不同,被划分到具有不同决策属性的决策类。表1为一张决策表,论域U有8个对象,编号1~8,{a,b,c}是条件属性集,d为决策属性。对于分类来说,并非所有的条件属性都是必要的,有些是多余的,去除这些属性不会影响原来的分类效果。约简是为不含多余属性并保证分类正确的最小条件属性集。一个决策表可能同时存在几个约简,这些约简的交集定义为决策表的核,核中的属性是影响分类的重要属性。“约简”和“核”这两个概念很重要,是粗糙集方法的精华。粗糙集理论提供了搜索约简和核的方法。计算约简的复杂性随着决策表的增大呈指数增长,引入启发式的搜索方法如遗传算法有助于找到较优的约简,即所含条件属性最少的约简[6]。

表1 原始决策表
本文选择基于粗糙集的模糊神经网络理论,它能充分发挥粗糙集和模糊神经网络各自的优点。一般神经网络结构不易理解,各条连接,各层节点,各个输出输入含义不清晰;模糊神经网络虽然结构易于理解,但连接复杂,学习时间长,而基于粗糙集理论的模糊神经网络则克服了上述缺点,结构清晰简单,易于理解,训练时间大大缩短。粗糙集理论特别适用于处理模糊和不精确性问题。模糊神经网络优异的逼近和分类能力可实现SF6气体分析和故障故障诊断。粗糙集方法能有效地对样本数据进行约简,去除冗余属性、简化规则集,在保证分类能力的前提下,优化了模糊神经网络的拓扑结构,使网络更清晰、简单,大大降低了网络规模,提高了学习速度。如图2所示,为基于粗糙集的模糊神经网络。
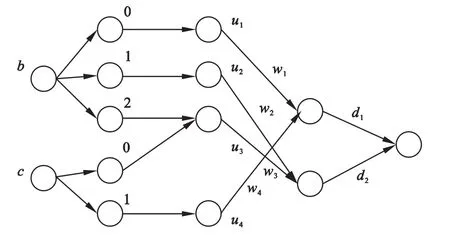
图2 基于粗糙集理论的模糊神经网络结构
第1层为输入层,输入变量为b,c(a为冗余条件属性,已被约简掉)。
第2层为规则的前件,实现输入变量的模糊化。
第3层的各节点分别表示各条规则。第2层与第3层之间的连接方式由粗糙集最终约简规则决定。图2 中,u1=b0,u2=b1,u3=b2c0,u4=c1。
第4层为各条规则的后件,与第5层之间的连接由粗糙集最终约简规则决定。图2中,wi为有权系数,d1=u1w1+u4w4,d1=u1w1+u4w4。
3 数据挖掘过程及知识发现
3.1 建模准备
数据挖掘的过程如图3所示。

图3 数据挖掘过程
SF6气体分析和故障诊断是一个多输入多输出系统,SF6气体成分分析是判断SF6设备故障的主要方法。通过分析各种气体的含量,判断其故障类型。本文收集了某些变电站SF6设备历史数据,共100个样本。考虑到SF6气体成分分析较全面地反映了SF6设备的运行状态。因此,选择了“SF6、SO2、CO、HF、H2S、气体湿度体积分数、露点、故障原因、故障否”作为预测变量。确定数据挖掘的主题为:(1)该研究以SF6设备故障状态与故障表现(SF6气体分析结果)之间的关系作为挖掘处理的目标:(2)选择“故障否”作为因变量。
3.2 建立模型
利用基于粗糙集的模糊神经网络理论建模需要构建一个7输入,7输出的模糊神经网络,输入为SF6、SO2、CO、HF、H2S、气体湿度体积分数和露点,输出为导电金属对地放电,悬浮电位放电,导电杆连接接触不良,互感器匝间和套管电容屏短路,及影响值,频率和联合。首先要随机选择80个样本训练,另外20个用来测试模型。
模型建立之后,就可以检查有关模型的信息。其中频率和影响值是用来表明输入和输出元素之间存在着密切的联系。Freq说明各分组数据中故障记录占当前记录的百分比。Impact用以说明一个记录值对预测的重要性,其值在0~100之间。对于有两个结果的研究,若Impact值超过60或70,预测准则将随之产生。一般来说,Impact为100表示非常具有预测性。中间值50表示没有预测性,Impact在0~30之间表明有很大的负面影响。
联合指的是有两个或者更多的共同影响某个输出结果的输入元素的集合,只要联合中的一个元素出现在包含特殊输出结果的记录中,其余的元素也总会同时出现。Conjunction为l并不重要,它代表的规则是多余的。
3.3 理解模型
首先对80个训练样本进行数据模糊化处理,形成原始决策表,然后根据前面介绍的约简方法,可以方便地将这些规则精简35%,得到最终决策表,获得相关模型,有利于得出SF6中各种气体成分含量与故障之间的直观联系,为判断SF6设备的运行状态提供了有力的依据。生成的模型对 SO2、CO、HF、H2S比较敏感,都得到了与SF6设备发生故障密切相关的各种气体含量的范围,见表2,结果与电力设备预防性试验规程的规定相差不大,很有利用价值。

表2 与故障密切的各种气体含量范围
4 运用模型进行预测
选择历史数据中的某一数据进行单例预测,并选择相关数据进行批预测。单例预测根据发现的模型,以交互的方式预测某一情况的结果;批预测一次性获得一系列情况,在没有用户干预的情况下直接进行预测。
选择表3的记录值作为预测的输入。预测结果是104CT,水分超标,故障。作出故障判断的主要原因是湿度体积分数和SO2含量,这两个分类对的Impact值都为100。
批预测的结果是104CT,故障,其余均无故障。将预测结果与实际记录逐条分析比较,因变量“故障否=否”时,有个记录预测失败;“故障否=是”时,预测准确度是100%;为“无法判断”时,仅有条记录预测失败。这样的预测准确度是可以接受的。
5 结语
通过对SF6设备故障和检修记录中的SF6气体成分数据进行挖掘,建立了SF6设备运行状态与各种气体含量之间的直观联系,所建立的模型具有较高的预测准确度,可以作为SF6设备运行状态诊断的判断依据。而且,数据量越大,数据越复杂,数据挖掘模型的适应性越强,预测结果也越有实际价值。
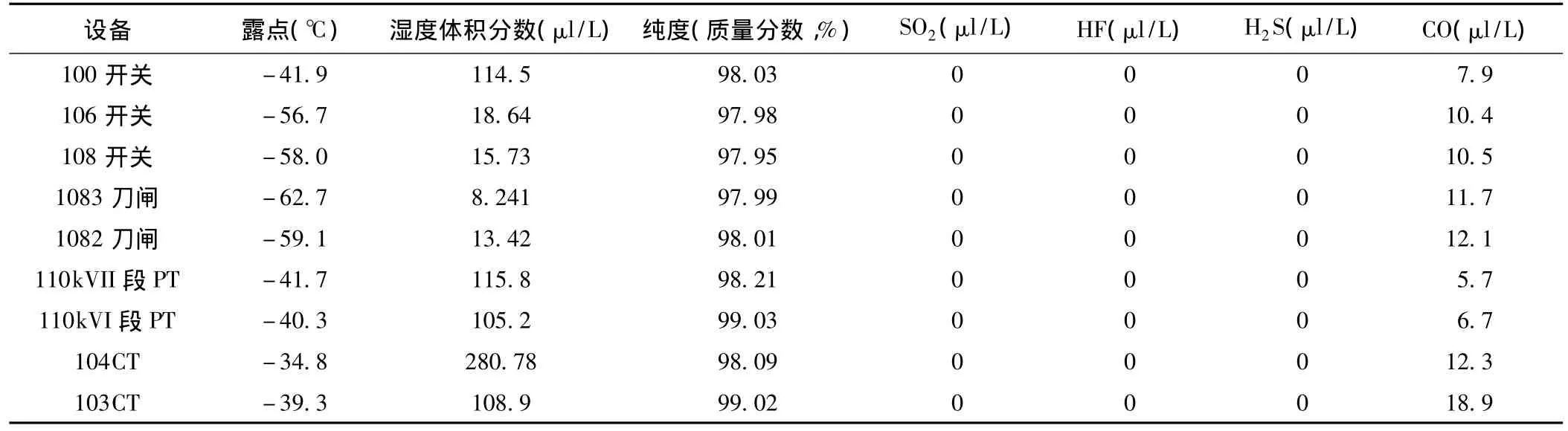
表3 某变电站SF6测试数据
研究说明,数据挖掘技术具备在电力设备故障诊断中应用的前景,SF6气体分析是现在SF6设备故障分析的主要方法,且在不断发展中,更多的成分分析被引入其中,数据的分析量也在不断增大,因此对于应用于此的数据挖掘技术还需要更多的研究和补充。
[1]Hand D J.Data Mining:Statistics and More[J].The American Statistician,l998,52(1):112 - l18.
[2]Groth R.Data Mining:Building Competitive Advantage[M].New York:Prentice-Hall Inc,1997.
[3]D.Hawkins.Identification of Outliers[M].Chapman and Hall,London,1980.
[4]Anand T,Kahn G.Opportunity Explorer:Navigation Large Datable U-sing Knowledge Discovery Templates[A].Proc.AAAI-93 Workshop Knowledge Discovery in Databases[C].Washington DC,1993.
[5]刘璨,陈统坚,彭永红,等.基于粗集理论的模糊神经网络建模方法研究[J].中国机械工程,2001,12(11):1256 -1259.
[6]Jelonek J.,Krawiec K.,Slowinski R.Rough set reduction of attributes and their domains for neutral networks[J].Computational Intelligence,1995,11(2):339 -347.
