基于粗糙集理论的“两型社会”发展评价
2011-12-14叶文忠欧婵娟
叶文忠 ,欧婵娟 ,李 林
(1.湖南科技大学 商学院,湖南 湘潭 411201;2.湖南大学 工商管理学院,长沙 411082)
基于粗糙集理论的“两型社会”发展评价
叶文忠1,欧婵娟2,李 林2
(1.湖南科技大学 商学院,湖南 湘潭 411201;2.湖南大学 工商管理学院,长沙 411082)
文章提出了基于粗糙集模糊聚类法的“两型社会”发展评价模型。该模型结合原始数据,通过粗糙集的可辨识矩阵挖掘出各项指标的权重,并在属性重要度的基础上进行属性约简,约去冗余指标,提高了评价方法的科学性。同时,文章以长株潭城市群的生态环境指标为例进行了实证分析,结果表明,该模型能准确有效地对该区域生态环境做出评价,具有一定的实用性和有效性。
两型社会;粗糙集;模糊聚类;评价模型
建立一个科学的“两型社会”评价模型,对相应的指标拟定科学的段性目标值,对“两型社会”建设进行客观评价,既是对“两型社会”建设发展战略的定位,也为推动政府加强宏观调控,有序地推进“两型社会”的建设提供了发展方向。传统的社会评价方法都是利用已有的信息建立函数或关系模型进行评价,而且在确定评价指标权重时,往往是根据经验进行主观赋权,具有一定的主观性,从而容易造成评价结果失真。本文拟在研究聚类和评价指标权重的问题上,提出适用处理大量不精确、不完全数据的粗糙集模糊聚类模型(RS-FCM)。该模型能够在原始数据的基础上挖掘出指标权重,以避免人工赋权的主观性,利用粗糙集的属性约简特性对指标进行筛选,约去冗余指标,保证评价结果的准确性。
1 两型社会的内涵
“两型社会”指的是“资源节约型和环境友好型社会”。其核心内涵是经济、社会、人的发展与自然生态系统协调、持续和和谐发展,将发展对资源的消耗和环境的损害降到最低限度。
“两型社会”是一个涉及产业发展、消费方式、文化定位、社区生活、日常行为等诸方面的综合、系统工程。资源节约型社会是指采取有利于资源节约的发展方式、生产方式、生活方式和消费方式,实现资源高效及持续利用,确保经济社会可持续发展的现代发展模式。环境友好型社会是在尊重自然规律的前提下,以环境资源的承载力为前提,经济社会系统与自然生态系统和谐发展和可持续发展模式。资源节约和环境友好的实质是在科学发展观指导下,坚持可持续发展与和谐发展的现代发展模式。资源节约型社会与环境友好型社会相辅相成,互为补充,所以我们将其统称为一个整体的概念,即“两型社会”。
2 基于粗糙集模糊聚类的“两型社会”发展评价模型(RS-FCM)
2.1 粗糙集理论(Rough Sets)
粗糙集(Rough Sets)理论最初是由波兰数学家Z.Pawlak于1982年提出的[1],它是研究不精确、不确定性和不完整数据的一种新的数学工具,是处理模糊空间的一种数学方法。粗糙集方法,是基于一个或一组关于一些现实的大量数据信息,以对观察和测量所得的数据进行分类的能力为基础,从中发现推理知识和分辨系统的某些特点、过程、对象等。粗糙集理论不仅为信息科学和认知科学提供了新的科学理论和研究方法,也为信息处理提供了有效的处理技术。
2.2 模糊聚类(FCM)离散化
在“两型社会”发展评价的研究中,无论是定性还是定量的指标,其指标值的值域都是连续的。粗糙集的数学基础是集合论,难以直接处理连续型的属性值,一般要求由实际数据构成的信息表中各个属性值必需用离散值表达。如果某些属性的值域为连续时,则在处理前必需经过离散化。
目前,对连续属性离散化的研究中已经提出了多种方法,比如:根据决策表的相容度[2]、微粒群算法[3]等方面进行的离散化方法。本文采用模糊均值聚类(Fuzzy C-Means Cluster,简称FCM)的方法对每一列的属性值进行聚类,通过聚类分析的方法达到离散化指标数据的目的。
设为元数据集合,如果确定分类数目,FCM聚类方法就是把划分为个模糊子集,首先对每类平均位置的聚类中心进行猜测,表示这个模糊子集的初始聚类中心,给每个数据点相对于每个聚类中心分配一个模糊隶属度(相似程度),隶属度可以表示数据点到聚类中心的距离,然后构造一个优化目标函数来对这些值进行评价,对每一个点在基于目标函数最小化的前提下重复更新聚类中心和隶属度,不断地把聚类中心移向一组数据的中间位置,其目标函数为:

约束条件为:

通过迭代算法,找到目标函数Jm的极小点(u*,z*):
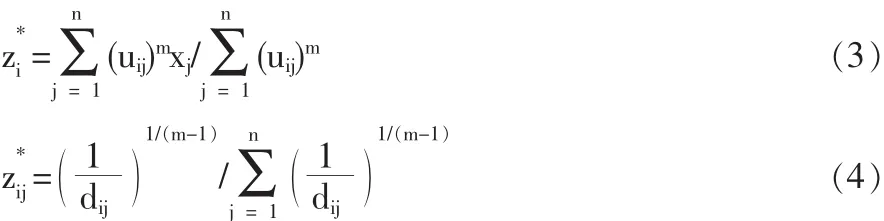
2.3 基于粗糙集的指标权重挖掘
传统的评价方法在确定指标权重的时候大多是通过设计问卷、专家打分来实现,这样确定的指标权重带有比较强的主观性,往往会影响评价结果的准确性。本文应用粗糙集对指标权重进行挖掘,通过可辨识矩阵计算属性重要度,根据属性重要度客观的提取指标的权重,就是为了避免人工赋权的主观性。
可辨识矩阵是由数学家Skowron提出的。可辨识矩阵可定义为信息系统中当决策属性不同且条件属性也不完全相同时,元素值为互不相同的属性组合[5];其定义为:
系统 S=(U,A),C,D⊂A 是两个属性子集,a∈C,a(x)是对象x在属性a上的值,可辨识矩阵C{cij}为

根据|cij|来对条件属性进行排序,可辨识矩阵中某项的长度越短,该项就对分类所起的作用越大,而且该项出现的越频繁,该项就越重要,因此,对可辨识矩阵排序时,除了按长度外,在长度相同的情况下,出现频率高的属性重要。在此基础上,提出一种新的基于可辨识矩阵的计算属性重要性的方法[6]:
在生成可辨识矩阵的时候,每个属性出现的频率被记录,以供以后使用。在计算属性的出现频率时,并不是简单地计数,而是加权的。加权的大小根据属性出现在可辨识矩阵中的长度。因此,对于一个可辨识矩阵C=(cij)m×n,相应的属性a的重要性的计算公式为:
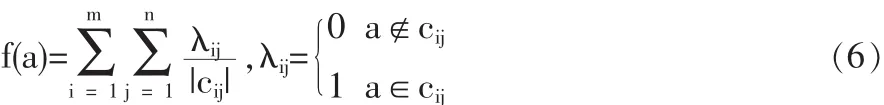
通过式(6)可以得出第 i个指标 ai的重要性 f(ai),将 ai的重要性作归一化处理即得到各指标权重,第i个指标ai的权重为:

2.4 基于粗糙集属性约简的指标筛选
本文采用的是基于可辨识矩阵的启发式属性约简,该方法在可辨识矩阵的基本约简方法上提出改进,能够有效解决基本约简算法中当决策表比较复杂、条件属性较多时对存储空间要求过大的缺点,而且操作简单,非常实用[7]。

表1 长株潭城市群“两型社会”建设综合配套改革试验区的生态环境指标体系
属性约简就是在保持知识库分类能力不变的条件下,删除其中不相关或不重要的知识。基于可辨识矩阵的启发式约简运算的详细算法如下:
(1)将所有属性按重要度排序;
(2)选择其中重要度最小的属性,将该属性约简;
(3)判定约简操作是否成立,若成立,删除因条件属性约简引入的冗余样本和不相容样本,约掉该属性,转(2);否则恢复约简该属性前的样本数据,结束约简。其中第(3)步的判定条件为:

式(8)中,N1为由于执行本次约简操作而引入的不相容样本数,N2为执行本次操作前知识表中样本的数量;N3为若执行本次约简操作,整个约简过程引入的不相容样本数;N4为执行任何操作前知识表中的总样本数量;α和β为两个阈值,一般取5%和10%。
3 实证研究
本文以长株潭城市群“两型社会”建设综合配套改革试验区的生态环境指标为例来说明该评价模型,选取2007年长株潭地区23个区县的实际数据通过粗糙集模糊聚类评价模型分析长株潭地区各个区县的生态环境。
3.1 建立长株潭城市群“两型社会”生态环境指标体系
建设成为具有国际品质的现代化的生态型宜居城市群是长株潭城市群“两型社会”建设综合配套改革试验区的目标定位中的一个重要方面。其主要指标是:社会文明、经济富裕、环境优美、服务完善的新型城市群。在这一目标的指导下,结合长株潭三市的生态资源现状,综合借鉴联合国可持续发展委员会(UNCSD)《可持续发展指标体系》[8]、国家环保总局《生态县、生态市、生态省建设指标(修订稿)》[9]等综合提出了长株潭城市群“两型社会”建设综合配套改革试验区的生态环境指标体系,如表1所示:
3.2 评价指标值的离散化
根据评价指标信息表的设定方法将原始数据填入信息表中,信息表中的行为样本对象和对象的各属性值,列为属性及各样本的属性值,限于篇幅,原始数据表和评价指标信息表没有列出。
用FCM进行信息表离散化的具体操作是:信息表中属性值离散化是根据属性逐个处理的,进行聚类的样本都是一维变量,即一列属性值,具体实现方法可以调用Matlab中的fcm工具箱及findcluster函数完成聚类的运算,根据聚类的结果将样本所属的序列号作为它的离散值[11]。根据聚类结果将信息表离散化。离散化部分结果如表2所示,ABC…R代表上述指标体系中的18个指标,x1x2…x23代表长株潭三地的23个区县。
3.3 评价指标的权重挖掘和指标筛选
根据可辨识矩阵的定义可以计算可辨识矩阵M中的元素Mij,其中i表示第i个区县,j表示第j个区县,因为可辨识矩阵是对称矩阵,因此我们只需计算一半的元素:

根据可辨识矩阵的启发式约简算法及其权重挖掘方法,前述指标属性重要度为:

根据属性重要性按照从大到小排列:


表2 FCM离散化后的信息决策系统

表3 长株潭三市生态环境评价结果
根据可辨识矩阵的启发式约简算法的属性约简规则依次约掉指标N、O,在对指标D约简的时候N3/N4=13.0%,不满足式(8)的约简条件,停止约简。我们可以去掉指标N和H。约去的评价指标为单位工业增加值新鲜水耗和工业用水重复率,这也基本符合现实。
将剩下的指标按照公式(7)计算权重,可以得出各指标的权重:

从上述指标权重我们可以看出森林覆盖率在所有指标中的权重是最高的,表明森林覆盖率是一个地区生态环境好坏最直观的反应。也提醒政府部门要注意林地的开发和水土的保持,优化林木结构,发展优质高效林业。权重仅次于森林覆盖率的是城镇垃圾无害化处理率,城市垃圾是对城市环境的一个大的挑战,加强城镇垃圾的处理对于美化城镇环境起着相对重要的作用。
3.4 综合评价
通过计算长株潭三地生态环境各项指标加权得分及其综合得分结果如表3所示。
从上评价结果来看长株潭三地的生态资源得分相对较高,表明该区域具有较丰富的生态资源。但是在污染控制和环境建设方面三地得分并不是很高,从而使得总体的生态环境状况不够优良。从综合排名来看长沙市位居第一,长沙市在环境建设方面的得分比其他两个地区要高出许多,作为省会城市,长沙市在环境建设方面的投入比株洲市和湘潭市要高,环境配套设施也相对较好。株洲作为工业城市综合得分相对较低,主要在污染控制方面得分较低。数字显示三地大气污染源在株洲市集中度较大,长沙和湘潭相对分散。株洲市内的清水塘工业区是三地大气污染最严重的地区,如何治理该地区的环境污染状况是当地政府部门亟待解决的问题。
在评价的过程中,我们发现长株潭地区在生态环境方面暴露出来的一系列问题:首先是资源分布不均,比如森林覆盖率,水资源等等。整个地区内森林资源和水资源都比较丰富,但是多集中在农村和城市偏远地区,人口密度集中的城区人均绿地面积和可用水资源远远低于农村;其次长株潭地区为湖南省经济集中地区,随着经济规模的扩大,外来人口增加,引起生活废水、生活垃圾规模增长,而城市相关配套设施没有到位从而引起城市环境面临巨大的压力,各城区的城市规划要综合考虑到经济扩张的要求,及时更新配套设施,在生态资源的建设方面也要扩大投资,加强建设;最后在生态控制方面,长株潭三地各区县的指标很多都达不到国家建设生态城市的标准,在今后的发展中各地在引进项目的同时要注意控制项目对环境的影响指标,严格把关、加强控制。只有严格按照国家的要求去控制把关才能在发展经济的同时不影响环境,才能真正建成“资源节约型、环境友好型”社会。
4 结语
长株潭城市群在建设“资源节约型、环境友好型”社会的过程中应该时刻把对生态环境的影响放在首位,对自身的生态环境状况进行评价是一项不可忽视的过程。本文提出的基于修正粗糙集模糊聚类法的社会评价方法,结合原始数据通过粗糙集的可辨识矩阵挖掘出各项指标的权重,克服了传统评价方法中的主观确定指标权重的缺点;在属性重要度的基础上进行属性约简约去冗余指标,有效地提高了评价方法的科学性,能够更加准确地对长株潭地区的生态环境做出客观地评价,而且本方法计算简单,操作方便,相信对于指导长株潭城市群“两型社会”建设综合配套改革试验区的建设有着非常实际的意义。
[1]Pawlak Z.Rough Sets[J].International Journal of Information and Computer Science,1982,11(5).
[2]苗夺谦.Rongh sets理论中连续属性的离散化方法[J].自动化学报,2001,27(3).
[3]张腾飞,王锡淮,肖键梅.基于微粒群优化的连续属性离散化算法[J].计算机工程,2006,32(3).
[4]付海燕,张诚一.基于FCM和粗糙集属性重要度理论的综合评价系统[J].计算机应用,2006,26(6).
[5]LashinE F,MedhaT T.TopologicalReductionofInformation Systems[J].Chaos,Solitons and Fractals,2005,25.
[6]芦晓红,陈世权,吴今培.基于可辨识矩阵的启发式属性约简方法及其应用[J].计算机工程,2003,29(1).
[7]肖健华,吴今培,杨舒子.基于启发式知识的属性约简方法及其在评价体系中的应用[J].系统工程,2002,20(1).
[8]United Nation's Sustainable Development Commission[Z].In:Proceedings of the First Session on Agenda 21,New York,1997.
[9]李乃炜,左玉辉.南京市可持续发展评价指标体系研究[J].上海环境科学,1999,18(6).
[10]杨香凤.基于粗糙集的港口竞争力评价模型的构建与应用[D].江西财经大学硕士论文,2006.
F224.9
A
1002-6487(2011)11-0034-04
湖南省软科学资助项目(2008ZK3068);湖南省哲学社会科学成果评审委员会资助项目(0808009A);湖南科技大学博士启动基金资助项目
(责任编辑/亦 民)
