基于改进注意力机制的声音事件定位与检测算法
2024-06-27杨雄雷帮军徐文发
杨雄 雷帮军 徐文发
摘要:在三维声音事件检测任务中,不同的声音事件相互影响,难以从复杂声音信号中提取出全局特征。基于注意力机制的声音事件定位与检测算法,能够将特征提取加强模块进行降采样操作和卷积操作,捕获声音特征,利用卷积注意力模块对序列数据中所有特征建模,利用全连接层输出声音事件的位置信息。方法结果预测值为0.616,相较L3DAS22 Challenge Task2中第二名预测值提升1.6%。
关键词:深度学习;声音事件检测;注意力机制
一、前言
智能语音处理广泛应用于声音事件定位与检测,其主要目的在于检测到声音事件的类型以及所在的空间位置。随着智能语音处理的发展,声音事件定位与检测应用更加广泛。声音作为人们获取信息的重要途径之一,常常应用于工业生产以及平常的生活中。但是,声音事件的定位与检测(Sound Event Localization and Detection,SELD)在机器学习中越来越受人们关注,用于检测和定位产生的异常声音,不仅在于对其他传感器检测的补充,而且在检测精度上有所提升。SELD常常在多媒体、游戏开发及设备故障检测等领域有所应用和发展。
SELD由两个子任务组成,分别是声音事件检测(Sound Event Detection,SED)和声源定位(Sound Source Localization,SSL)。SED能够在不同环境下的音频序列中识别出各个声音事件的开始和结束时间。文献[1-2]中的算法只能检测出部分音频序列中置信度最高的一种事件,无法在真实声音环境下同时反映出可能出现的多个声音事件。当前较为主流的SED是基于深度学习的方法,针对卷积神经网络(Convolution Neural Networks,CNN)不能捕捉音频段中的长时依赖性的问题,文献[3-4]将循环神经网络(Recurrent Neural Network,RNN)捕获时序信息以及分析语义信息的能力和CNN特征提取相结合的卷积循环神经网络(Convolution Recurrent Neural Network,CRNN)可以有效提取时序数据的特征,从而实现多声音时间检测。文献[ 5]利用多尺度卷积网络引入了特征融合模块,针对特征图信息弱和目标漏检率大的问题,多尺度卷积神经网络通过特征金字塔组件在CRNN中提高SED的精度。
常见SSL算法在波束的基础上生成定位算法、在高分辨谱的基础上估计定位算法,以及基于到达时延差(Time Difference of Arrival,TDOA)。例如:端到端TDOA估计,基于深度学习高分辨谱估计算法。本文基于深度学习高分辨谱估计算法。传统循环卷积神经网络的声音事件定位与检测方法对于长时间序列数据特征提取能力有限,导致定位和检测精度较低。本文利用改进注意力机制来提取时间序列模型的局部特征和全局特征,改进网络中结构从而减少数据冗余。
二、算法原理及网络结构
(一)注意力机制的声音事件与定位算法架构
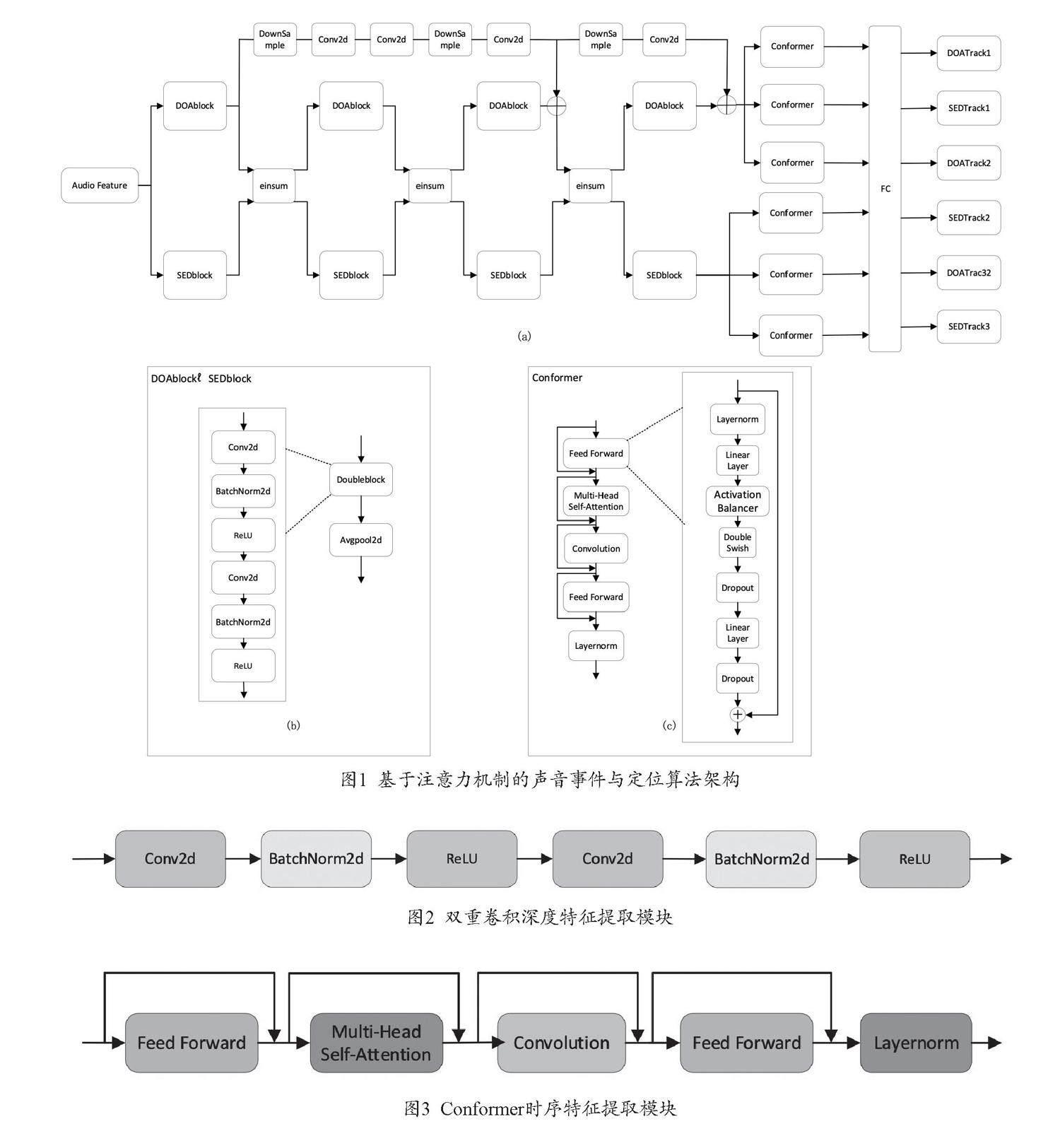
将Log-Mel谱图作为SED任务的输入和Log-Mel四通道信号的短时间傅里叶变换谱图,计算Log-Mel谱图。通过运算作为DOA估计的输入特征,再将两种类型的特征用于集成模型,如图1(a)模块所示。
图1是本实验声音事件与定位算法的架构示意图,它主要包含深层特征提取模块、时序特征提取模块和输出模块。其中,深层特征提取模块由双重卷积模块组成。
(二)双重卷积深度特征提取模块
系统将得到的两种特征分别送入Conv-Conformer网络中进行训练,提取的特征IIV输入四个双重卷积块中再和降采样块进行拼接,最终得到深层特征FC,如图1(b)模块所示,其过程可以表示为:
Fc=Conv23x3(Conv23x3(Conv23x3(Conv23x3(IIV)))+
Fdown1(IIV))+Fdown2(IIV) (1)
其中,Conv23x3(·)表示大小为3×3的双重卷积核,Fdown1(·)为第i个降采样块,如图2所示。
图2是双重卷积深度特征提取模块示意图,包含卷积层、归一化和激活函数三个模块。
其中,降采样块结构平均池化大小为1×2、步长为1×2,表示为:
Fdown2=Conv(Avg1*2 (Conv(Avg(Conv(Conv(Avg(IVI))))))) (2)
(三)坐标注意力
在图1(c)模块中Conformer时序特征提取网络包含Feed Forward模块、卷积模块、自注意力模块和第二个Feed Forward模块等四个模块,如图3所示。
图3是Conformer时序特征提取模块示意图,包含Feed Forward、多头自注意力机制模块、卷积层和层归一化四个模块。
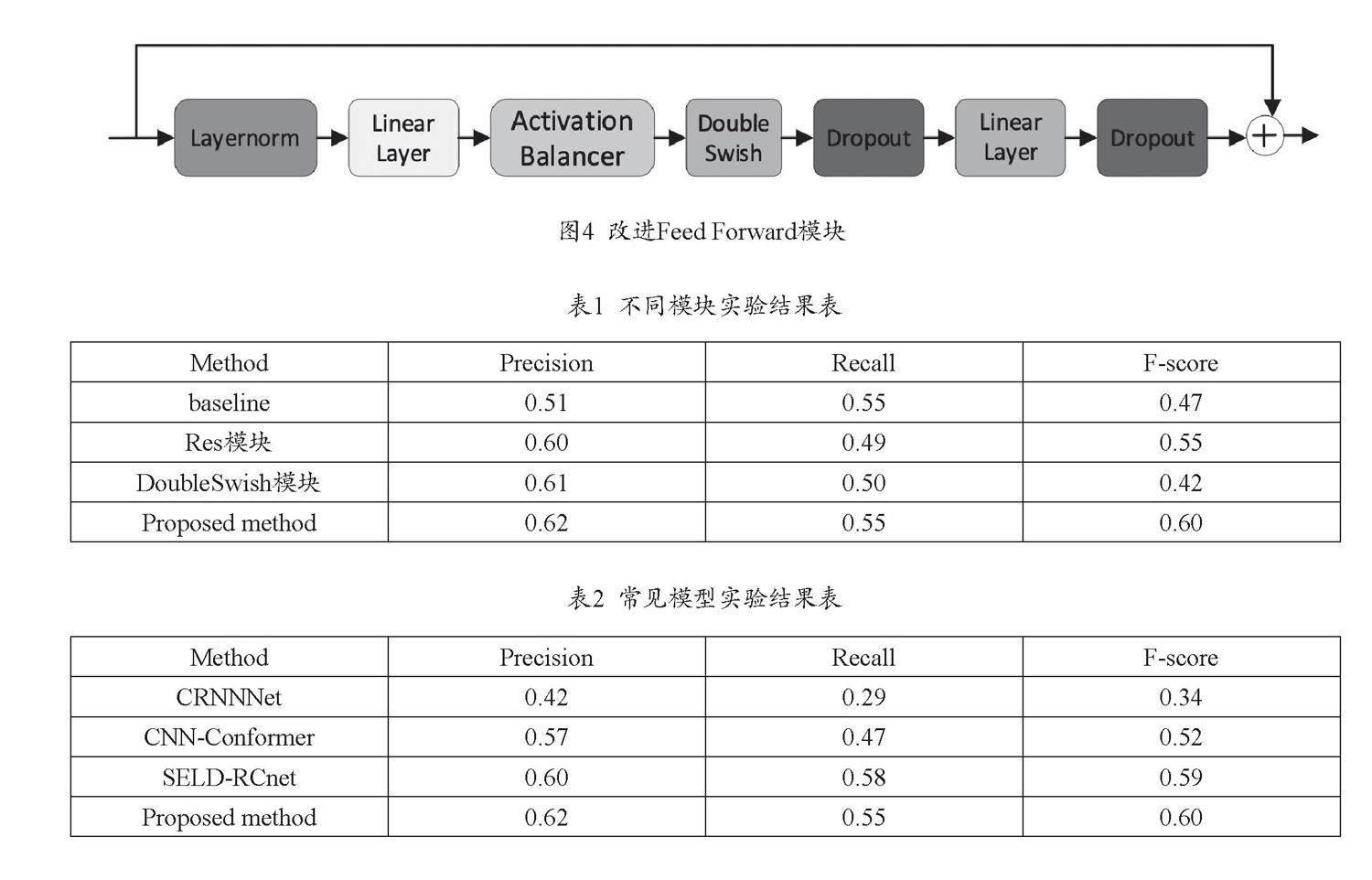
在Feed Forward模块中,通过层归一化维度为512的输入特征,再经过线性层,引入Activation Balancer和激活函数Doubleswish,其中Activation Balancer在特征提取的前向计算过程中,统计特征激活值的范围包括其中正数比例以及绝对值大小。在反向求梯度的过程中,根据前向统计结果,对应地放缩梯度大小,从而降低激活函数Doubleswish中产生的激活值异常,降低参数的浪费,如图4所示。
在卷积模块中,首先,通过一个点向卷积,点卷积的膨胀系数为2,再经过一个门控线性单元(GLU)维度为1,接下来是一个一维深度卷积层,卷积核大小为31。Batchnorm层在卷积层之后帮助训练深度模型,在得到FC深层特征后输入时序,将输出深层时序特征输入全连接层分别得到DOA位置坐标向量和SED结果,最后通过线性层将SED特征宽度减小到14,将DOA特征宽度减小到3,再分别将SED和DOA时序特征进行拼接输出,得到输出结果。
三、实验与结果分析
(一)实验数据集及评价指标
本文采用L3DAS22 Challenge Task2官方提供的数据集。罗马萨皮恩扎大学负责汇总数据集,采样的频率为16kHz。其中,600个长为一分钟的录音文件也包含在内,从FSD50K中选择了1440个噪音文件。数据集包含了大约98小时的MSMP b格式音频录音。在一个近似尺寸为6米(长度)、5米(宽)和3米(高度)的真实办公楼的声场进行了采样,房间里有典型的办公家具、木制拼花地板、油漆过的混凝土墙壁和天花板。数据集分为一个训练集和一个测试集,训练集有5个小时的音频,测试集有2.5个小时的音频。OV1、OV2和OV3分别表示为最大重叠声音事件为1个、2个和3个。本文对声音事件类别进行识别时运用两种数据,第一是标准度量F分数(F-Score),第二是精度(Precision),使用召回率(Recall)来评估声源位置信息作为本文算法的评价指标。
(二)实验环境及参数设置
实验过程中,运行环境方面运用的硬件设施包含CPU主频为3.6GHz、显卡型号为NVIDIA RTX 3060、内存大小为16G。操作系统为Windows10的软件环境,深度学习框架为 PyTorch=1.8.0,编程语言采用Python3.7。SED、DOA估计的损失权重分别设置为λ=0.3和γ=0.7,训练数据集过程中运用Adamw算法,进一步完善模型收敛速度。实验的学习率具体数值设置为3×10?3,训练的总和数量为 200个epoch。
(三)实验结果分析
一般来说,声音事件不一样,持续时间也不一样。所以,训练环节中使用时间的长短对模型的性能会产生一定的影响。 L3DAS22 一般来说,Challenge Task2 数据集上的声音事件时间保持在0.2到40.0秒,中位数的数值为3.2秒,平均数的数值为8.3秒。本文在4秒、8秒、12秒、16秒输入时间长度不一样的情况下对注意力机制模型进行训练,得出的模块数据见表1。
为了验证本文提出的算法的有效性,进行不同模块的消融实验。由表1可知在相同baseline下,相较于其他模块,本文所采用的模型在Percision分别提高了0.11、0.02、0.01,在Recall上分别提高了0.06、0.05, 在F-sore上提升了0.13、0.05、0.18。因此,本文提出的算法在结合不同模块上具有更好的效果。
为对本文提到的算法有效性进行验证,对比本文算法和其他先进的网络模型,对两种算法展开对比实验工作,最终确定 CRNNNet、CNN-Conformer、SELD-RCnet作为网络模型。从表2能够观察到,本文算法比其他模型 Precision以及F-score有所增强,Recall只略低于SELD-RCnet模型 0.03%,优于其他模型。
四、结语
关于 SELD 定位面临难题且效果不好等问题,本文采用的基线模型为CNN-Conformer,与残差以及改进Conformer注意力机制设计模型相结合。这种网络模型具备一定的优势,将高效注意力和降采样融入其中,进而能够对特征图以及时间序列上的信息进行汇总,使得SELD 的指标性能得到显著提升。
参考文献
[1]A. J. Eronen et al., Audio-based context recognition[/OL], in IEEE Transactions on Audio, Speech, and Language Processing, vol. 14, no. 1, pp. 321-329, Jan. 2006.
[2]HEITTOLA T,MESAROS A,VIRTANEN T,et al. Sound event detection in multisource environments using source separation[C]// First International Workshop on Machine Listening in Multisource Environments ( CHiME 2011 ) .Florence: CHiME,2011: 36-40.
[3]Turpault N , Serizel R , Salamon J , et al. Sound Event Detection in Domestic Environments with Weakly Labeled Data and Soundscape Synthesis [C]// 4th Workshop on Detection and Classification of Acoustic Scenes and Events (DCASE 2019). 2019.
[4]RSANet: Towards Real-Time Object Detection with Residual Semantic-Guided Attention Feature Pyramid Network[J]. Mobile Networks and Applications, 2021, 26(01):77-87.
[5]Iqbal T, Xu Y, Kong Q, et al. Capsule routing for sound event detection[C].2018 26th European Signal Processing Conference (EUSIPCO). Rome, Italy, 2018: 2255-2259.
作者单位:杨雄、雷帮军,三峡大学计算机与信息学院、水电工程智能视觉监测湖北省重点实验室;徐文发,武昌首义学院信息科学与工程学院
■ 责任编辑:张津平、尚丹
