基于知识图谱的多特征融合谣言检测方法
2024-06-01刘小洋李慧张康旗段迪文癸凌
刘小洋 李慧 张康旗 段迪 文癸凌


摘 要:为了解决谣言检测中由于缺乏外部知识而导致模型难以感知内隐信息,进而限制了模型挖掘深层信息的能力这个问题,提出了基于知识图谱的多特征融合谣言检测方法(KGMRD)。首先,对于每个事件,将帖子和评论共同构建为一个文本序列,并利用分类器从中提取情感特征,利用ConceptNet基于文本构造其知识图谱,将知识图谱中的实体表示利用注意力机制与文本的语义特征进行聚合,进而得到增强的语义特征表示;其次,在传播结构方面,对于每个事件,基于帖子的传播转发关系构建传播结构图,使用DropEdge对传播结构图进行剪枝,从而得到更有效的传播结构特征;最后,将得到的特征进行融合处理得到一个新的表示。在Weibo、Twitter15和Twitter16 三个真实数据集上,使用SVM-RBF等七个模型作为基线进行了对比实验。结果表明:对比当前效果最好的基线,KGMRD方法在Weibo数据集的ACC指标提升了1.1%;在Twitter15和Twitter16数据集的ACC指标上提升了2.2%,证明了KGMRD方法是合理的、有效的。
关键词:知识图谱;注意力机制;情感词典;谣言检测
中图分类号:TP399 文献标志码:A 文章编号:1001-3695(2024)05-012-1362-06
doi: 10.19734/j.issn.1001-3695.2023.10.0425
Knowledge graph based multi-feature fusion rumor detection
Abstract:In order to solve the problem that it is difficult for the model to perceive implicit information due to the lack of external knowledge in rumor detection, which limits the ability of the model to mine deep information, this paper proposed knowledge graph based multi-feature fusion rumor detection (KGMRD) method. Firstly, for each event, it constructed posts and comments together into a text sequence and used a classifier to extract the emotional features. This paper constructed a knowledge graph based on text using ConceptNet and aggregated the entity representation in the knowledge graph with the semantic features of text using the attention mechanism, so as to obtain the enhanced semantic feature representation. Secondly, in terms of communication structure, for each event, this paper built its communication structure diagram based on the propagation and forwarding relationship of the post, and used DropEdge to prune the communication structure diagram, so as to obtain more effective communication structure characteristics. Finally, it fused the obtained features to get a new representation and compared seven models including SVM-RBF on three real datasets of Weibo, Twitter15 and Twitter16. The experimental results show that compared with the current baseline with the best effect, the KGMRD method has the best ACC on the Weibo dataset and improves the ACC by 1.1%, and there is a 2.2% improvement on Twitter15 and Twitter16 dataset in ACC. The experiment proves that the KGMRD method is reasonable and effective.
Key words:knowledge graph; attention mechanism; emotion dictionary; rumor detection
0 引言
虛假信息是故意传播以误导或欺骗为目的的虚假或者不准确的消息,其无论是对社会还是个人都有极大的影响[1]。Vosoughi等人[2]将虚假信息与真实信息的传播结构进行了对比,发现虚假信息的传播范围更远、更快、更深、更广。虚假信息由于其巨大的负面影响而成为一个重要问题,引起了研究人员的广泛关注[3]。谣言多集中爆发于突发事件,在这种情况下,由于人们对事实的认知有限,在恐慌心理的影响下,民众更倾向于相信并传播谣言。因此,研究社交网络上虚假信息的传播特征,尽早识别出谣言,对社交网络的发展和治理有重大意义。
传统的谣言检测方法主要是利用深度学习或机器学习方法,从发布的帖子本身出发,特征工程集中在文本内容方面的挖掘,得到单纯基于内容特征的谣言检测方法[4],然而这些方法在谣言检测中不能取得较好的效果。Ma等人[5]从空间结构出发,考虑帖子在传播过程中的信息,提出基于传播结构特征的谣言检测方法,以获得模型更好的表现。现有研究基于传播结构特征和文本内容特征[6],提高了谣言检测模型的效果,但是仍存在局限性,包括:a)帖子自身的局限性,例如文本篇幅较短,现有的方法从中提取到的语义信息有限;b)网络用语存在缩写、别名等现象,例如:“特朗普”“川普”“特朗普先生”均表示同一个人,是对“唐纳德·特朗普”的特指,这些知识层面的提及和联系有助于提升判断帖子内容的可信度。然而,这些信息不能直接与文本中的实体相关联,因此需要引入外部知识来增强实体间的联系,将知识信息整合到知识图谱中,进而增强谣言检测的效果。
针对上述问题,本文提出了基于知识图谱注意力机制的多特征融合谣言检测方法。该方法充分挖掘文本中的语义信息,结合外部知识提取实体背景知识,并利用注意力机制将其进行聚合,得到外部知识增强的语义信息;利用情感词典和情感分类器抽取文本中的情感特征,构建传播结构图并提取传播结构特征,最终进行融合并分类。
本文的主要贡献有:
a)结合英文的Twitter 15、Twitter 16数据集和中文的Weibo数据集,结合社交网络中发帖与评论的信息;以帖子和其评论转发为节点,构建了谣言传播结构图,使用GCN提取了传播图的结构特征。
b)利用外部知识构建知识图谱,将其嵌入表达作为背景知识,通过注意力机制与文本语义特征进行聚合以获得语义特征的高阶表达,接着与情感特征以及结合传播结构特征进行特征融合,得到谣言检测更有效的表示,基于此提出了一种基于知识图谱的多特征融合谣言检测方法。
c)将KGMRD方法在Weibo、Twitter 15和Twitter 16三个真实数据集上进行大量实验,并与SVM-RBF等七种机器学习和深度学习模型进行了对比分析,以验证KGMRD方法的合理性與有效性。
1 相关工作
近年来,社交媒体的兴起加剧了谣言的产生与传播,谣言对社会稳定性的影响使得谣言检测吸引了大量研究者的注意。早期的谣言检测主要依赖于从文本内容、用户信息、传播结构等方面提取谣言的特征,以对带有标签的帖子进行分类。这些特征主要是通过人工提取的,属于劳动密集型。如Kwon等人[4]提出了基于文本特征的时间序列并融合了各种社会语境信息的谣言检测方法。Ma等人[5]用传播树模拟了微博帖子的传播方式,基于内核传播树Kernel,通过区分传播树结构之间的相似性以达到区分不同类型谣言的高阶模式。然而这些方法太依赖特征工程,需要大量的人力投入,费时费力。
随着数据量的攀升以及数据种类的多样性,人工提取特征的难度也逐渐加大,为了实破这个局限性并学习谣言的高级特征,更多深度学习方法被用于挖掘谣言的各种隐藏特征以用于自动谣言检测。谣言的传播结构和时间特征也被考虑以提高谣言检测的准确性。Bi等人[6]从微博信息传播网络的语义信息出发,构建其异构图,使用节点级注意力结合微博节点的邻居节点以生成具有特定语义的节点嵌入,再使用语义级注意力融合提取到的不同语义,进而得到更高级的语义表示。GCN能够更好地从图中或者树中捕获全局结构特征,注意力机制能更好地聚合文本内容以从中获得更加关键的隐藏特征。随着对谣言检测这一领域的不断深入研究,也有一些研究者将注意力放在外部知识上,希望借助外部知识来增强文本的语义表达,进而获得更高效的表达。如Castillo等人[7]依据情感词典提取了Twitter谣言文本和非谣言文本中的情感词,进而达到谣言检测的目的。还有学者引入知识图谱以补充帖子内容,以产生更好的表示用于谣言检测。Sun等人[8]使用双动态GCN对传播中的消息动态和背景知识进行融合建模。
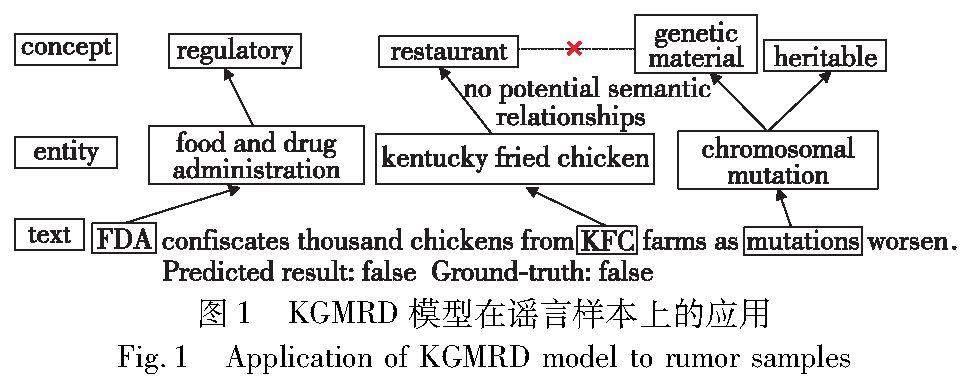
然而这些方法忽略了实体之间的知识级相关性,无法根据知识图谱中特定的背景语义来捕捉实体间的高阶语义信息,基于此提出了基于知识图谱的多特征融合谣言检测方法。图1是针对谣言案例结合本文提出的引用外部知识对谣言进行分析的结果。
2 KGMRD模型
知识图谱的多特征融合谣言检测模型的总体框架如图2所示。
图2中,首先对于帖子中的文本,利用知识蒸馏获得ConceptNet中关于文本中实体的背景知识,并利用GCN提取其嵌入式表达。接着,利用预训练模型BERT获得文本的语义特征。为了获得增强的语义表达,使用了多头注意力机制将实体与语义信息进行聚合;利用外部知识情感词典获得文本的情感特征表示,将其与增强的语义信息表达进行融合;传播结构的特征提取依赖于基于节点之间存在评论-转发关系,将源帖或者源微博(推文)、转发微博、评论的用户作为传播结构图中的节点,用于构造传播图。使用GCN提取传播结构图中的结构信息,由于原始的传播结构中包含大量无用或者冗余的节点或边,进而会干扰提取出的结构特征。这里使用DropEdge方法随机去除冗余的边和节点,以减少干扰,提取更有效的结构特征,进而提高谣言检测的准确度。
对于每一个事件Ei有相应的标签Yi与之对应,来表示事件的性质,yi∈{TR,FR} (TR 代表的是谣言,FR代表的不是谣言),在一些数据集中,yi还有其他取值(TR,true rumor;FR,false rumor;UF,unverified rumor;NR,non-rumor)。谣言检测的目的就是通过学习谣言数据中的特征并构造分类器,根据学习到的特征使用谣言分类器来区分真实性未知的微博或推文。
f:Ei→Yi(1)
其中:Ei是将要确定的事件;Yi是分类器给出的事件真实性标签。
2.1 知识蒸馏
知识图谱是结构化的数据模型,具有描述真实世界实体的数百万个条目,例如人、物、地点。知识图谱中的实体表示为图节点,实体之间的关系表示为边。知识图谱已经被广泛用于推荐系统[9]以及对话生成中。一些方法尝试将知识图谱引入到谣言检测中,利用从外部知识中提取背景知识信息,以补充语义相关性来达到更好的谣言检测效果[10~13]。
2.2 文本语义特征提取
BERT是一种基于Transformer构架的高级预训练词嵌入模型[12],本文使用BERT作为句子编码器以获得句子的上下文表示,将其作为文本的语义特征。
P=BERT-CLS(w1,…,wn)(4)
2.3 外部知识增强注意力
在获得文本语义特征以及实体表达后,为了表征外部知识的相对重要性,将文本语义特征序列Pt投影到注意力机制的Q、K、V向量中,即Q=PWQ,K=PWK,V=PWV。其中W(·)是可训练参数矩阵,通过这种方法可以得到语义特征和背景知识更加有效的聚合,其表示如下:
其中:[;]表示拼接;P′是通过注意力机制融合的具有更有效表达的结果。多头注意力机制被用于获得多头注意力层的输入结果:
Multihead(P′)=Concat(P′1,P′2,…,P′n)W(6)
其中:P′是每个注意力层的输出;n是注意力层的层数;W是可训练参数。
2.4 情感特征提取
对于帖子和评论的向量表示,将其长度控制为L,对于文本长度大于L的,将其裁剪为L,长度小于L的将其用0向量进行填充,使其长度为L。接着对于长度为L的文本序列C=[c1,c2,c3,…,ci,…,cL],其中ci是文本的第i个单词。将这些向量表示输入到提出的模型中,提取其中的情感特征。
为了使获得的情感特征更具有解释性,使用了情感分类器和情感词典从文本内容中提取特征。给定的文本输入序列为L,其中ci是文本中的第i个单词,目标是从文本C中提取情感特征。
1)情感分类
对于情感分类,使用公开的情感分类器去获得帖子文本的情感分类特征。给定情感分类器Femo和帖子文本C,假设输出的维度是df,因此对文本C的预测是Femo(C),从而能够获得文本的情感分类特征emocategoryT=Femo(C),其中emocategoryT∈Euclid ExtraaBpdf。
2)情感词典
为了更好地获得句子的情感表示以及充分利用情感词典信息,本文将情感词典加入到情感特征提取任务中,为模型提供额外的情感特征信息。将情感词典记为D={d1,d2,…,dm},其中情感词典D包含m种情感,对于情感d∈D,情感字典提供了一个包含L个情感单词的单词表Euclid Math OneFAp={f1,f2,…,fL}。
在给定文本C的情况下,逐渐将每个单词和完整文本在左右情绪中的得分进行汇总以丰富表示。
对于情绪d,首先计算单词级别的得分score(Ci,d),其中ci是文本序列C中的第i个单词,如果单词ci在词典Euclid Math OneFAp中,不仅考虑它的出现频率,还考虑其上下文中的程度词和否定词。
接着对文本分词,找出文档中的情感词、否定词以及程度副词,查看每个情感词之前有无否定词及程度副词,将它之前的否定词和程度副词划分为一个组。若有否定词,则将情感词的情感权值乘以否定词的值,若有程度副词就乘以其程度值,然后将所有组的得分加起来,大于0的归于正向情感,小于0的归于负向,得分的绝对值大小反映了文本的消极或积极的程度,通过这种方式获得每个单词的情感得分,其计算方式如下:
其中:s是左侧上下文的窗口大小;neg(cj)和deg(cj)分别是单词cj的负值和程度值,这些可以通过情感词典查找到。
将所有获得的单词得分score(ci,d)进行相加,得到基于文本的情感得分score(C,d),文本情感得分的计算如下:
将获得的文本级情感得分拼接得到基于情感词典的情感特征:
得到这两种特征后,将所有获得的不同种类的情感特征进行拼接,进而得到文本的情感特征emoC,如下所示。
2.5 傳播结构特征提取
基于帖子及其转发和评论关系,为其构造了帖子的传播结构图G〈V,E〉,其中V作为传播结构图的节点集,包含了帖子发布者和用户节点,E是传播结构图的边集表示节点之间有评论或者转发行为。由于近年来,卷积模型在图域中的应用越来越广泛,在现有的卷积模型中,GCN的表现是极有效的模型之一,所以,在模型中采用GCN,其计算消息传递架构的方式如下:
Hk=M(A,Hk-1;Wk-1)(14)
其中:Hk和Hk-1分别是由第k和第k-1层的卷积层计算得来的隐藏向量矩阵;M是信息传播函数;A是传播结构图的邻接矩阵;Wk-1表示可训练的参数。由ChebNet[14]对消息传播函数的定义可知,式(14)可写成如下形式:
由于传播图G的节点多且较为复杂,为了防止在GCN训练过程中出现过拟合现象,同时为了减少由于过平滑引起的信息缺失,采用了DropEdge机制在模型训练时随机删减掉原始图中的边。假设传播结构图的总共边数为Ne,弃边率为p,那么DropEdge后的邻接矩阵A′由以下方式计算得到:
A′=A-Adrop(16)
其中:Adrop是对G中的边集E进行随机采样后形成的邻接矩阵;邻接矩阵中边的数目为Ne×p。
GCN被用于提取谣言的传播结构特征,传播图G的隐藏特征矩阵H1可以由以下公式获得:
其中:Hk表示是GCN中的第k层特征;Wk表示参数矩阵;X是基于传播树构建的特征矩阵;模型中用ReLU函数作为激活函数。
2.6 分类预测
在获得了具有情感信息的语义特征和根节点增强的传播结构特征之后,将这些特征进行拼接,从而获得融合特征F:
F=concat(P′,emoc,H)(19)
3 实验设置
3.1 数据集
为了验证模型的有效性并使实验结果具有普遍性,在中文的Weibo数据集和两个英文的数据集Twitter 15、Twitter 16上进行实验。传播结构图中的节点表示用户的源帖子,边表示转发或者评论关系。在Weibo数据集中有两种标签,分别是true rumor(TR)和false rumor(FR), 在Twitter数据集中有四种标签,分别为true rumor(TR)、false rumor(FR)、unverified rumor(UF)和none rumor(NR)。数据集详细信息如表1所示。
3.2 实验设置
在实验环节,实验配置为Windows10、CPU Xeon Gold 6226R×2、128 GB内存、NVIDIA Quadro RTX A6000×2。在实验中用下面的模型作为谣言检测模型的基准,与KGMRD方法进行了比较分析。
a)SVM-RBF[15],一种基于SVM并结合了RBF内核的检测模型,它是使用了新浪微博的具体特征构建的分类器。
b)RvNN[16]是一种基于树状结构RNN的模型,该模型考虑了谣言传播结构的自上而下和自底向上两个方向的特征。
c)VAE-GCN[17]提出了基于GCN的图卷积编码解码的谣言检测模型,学习谣言的文本和传播结构特征以进行谣言检测。
d)Bi-GCN[18]是一种基于GCN的谣言检测模型,考虑谣言的传播和扩散结构,并通过根节点特征增强来增强节点表示。
e)PPC[19]结合循环神经网络和卷积神经网络的谣言检测模型,该模型考虑了用户特征在传播路径上的全局和局部变化。
f)HAGNN[20]提出基于图神经网络的谣言检测模型,捕获不同粒度文本内容的高级表示,融合传播结构进行谣言检测。
g)GCNFEM[21]使用图卷积网络表示谣言传播树,以源和响应帖子为图,并根据随时间推移发现的对谣言的响应来更新节点表示,进而达到检测谣言的目的。
采用accuracy(ACC)、precision(Prec)、recall(Rec)和F1-score(F1)对提出的KGMRD方法进行性能评估。在Weibo数据集上采用ACC、Prec、Rec和F1;在Twitter 15和Twitter 16数据集上采用ACC和F1进行评价。
3.3 结果分析
在Weibo数据集上,将KGMRD方法与经典的SVM-RBF等七种基线模型进行分析,其实验结果如表2所示。
表2中,KGMRD方法以94.6%的准确率(ACC)成为对比的七种模型中表现最好的模型,与最佳基准相比有1.1%的提升,其中 F1值达到了94.5%,与最佳基准相比有0.5%的提升,精确率(Prec)更是达到了95.9%。因此KGMRD方法整体来说优于其他模型。
在Twitter 15和Twitter 16数据集上将KGMRD方法与传统的SVM-RBF等七种基线模型进行了对比分析,实验结果如表3和4所示。
图3是KGMRD模型在Twitter16和Weibo数据集上的三条样本案例得到的结果,模型输出预测概率,经过分类器映射得到false或true的结果,将输出结果与真实标签对比,表明提出的模型对Text(1)~Text(3)的预测均准确。
表3、4中,KGMRD方法在Twitter 15和Twitter 16两个数据集上以88.7%和89.5%的准确率成为表现最好的模型,与基线中表现最好的HAGNN模型的准确率相比分别有2.2%和2.1%的提升。此外,从表3和4可以看到,KGMRD在两个数据集上的TR指标分别达到了89.3%和92.2%,在NR、FR和UR上的精确率也都能达到85%以上。
通过表2~4可以看出,与SVM-RBF等模型相比,KGMRD及GRU、PPC等模型在一系列评价指标上均有较大的提升,且都达到了88%以上的准确率,表明了基于神经网络的深度学习检测方法在原理上大幅优于基于传统机器学习的检测方法,证明了神经网络模型在不依赖于特征工程的同时,有着更好的谣言特征提取能力。在五个深度學习检测模型中, KGMRD、VAE-GCN和Bi-GCN等结合了GCN来提取谣言的传播结构特征,在检测精度上优于其他三个模型,表明了以图结构来对传播过程进行建模并以图卷积神经网络来提取谣言在传播过程中的结构特征是有效的。KGMRD利用外部知识增强文本的语义特征表达的谣言检测模型,在各项指标上优于其他模型,表明了通过外部知识增强文本语义对于提升谣言检测的精度是合理有效的。总体上,KGMRD方法在不同程度上均优于其他的传统机器学习及深度学习七种模型。
3.4 消融实验
为了验证KGMRD方法中各个模块的有效性,设计了相应的消融实验。消融实验的模型如下:
a)KGMRD/KGA:去掉模型中的知识图谱和注意力机制模块,即将语义特征、情感特征和传播结构特征相结合进行谣言检测。
b)KGMRD/GCN:去掉模型中的知识图谱和注意力机制模块,即不考虑帖子的传播结构,将使用注意力机制聚合了外部知识而获得的增强语义特征与情感特征融合进行谣言检测。
c)KGMRD/E:去掉模型中的情感特征提取模块,即增强的语义特征与传播结构特征相结合进行谣言检测。
在Weibo、Twitter 15、Twitter 16数据集上对以上三种模型进行验证,以衡量不同模块的性能和合理性,并与KGMRD模型进行对比,实验结果如图4所示。图4是四种模型在Twitter 15、Twitter16数据集上的结果。图5是以上四个模型针对两条不同的谣言样本案例Text(1)和Text(2)进行概率预测。从图4和5中可以看出,与其他三种模型相比,模型KGMRD有更好的表现,进而证实了模型各模块的有效性。
3.5 早期检测
由于随着时间的增加,谣言扩散的范围会越来越广,产生的负面影响也会越来越大,所以尽早地检测出谣言的存在并抑制其传播非常重要,对谣言的早期发现能力也成为衡量谣言检测效果的一个重要指标。为了验证该模型对谣言早期检测的有效性,在三个数据集上的实验过程中设置了一系列的检测截止日期,并对从释放时间到截止日期时间的数据进行了实验。早期检测结果如图6所示。
图6(a)~(c)分别显示了KGMRD方法与傳统的机器学习方法DTC、SVM-RBF等,以及深度学习方法PPC等模型在Weibo、Twitter 15和Twitter 16数据集上,当设置不同截至时间的情况下的性能对比。图6显示,KGMRD方法在源帖早期就达到了较高的准确率。此外,在每个截止时间,本文提出的模型都明显优于其他模型,表明KGMRD方法不仅有利于长期的谣言检测,而且有助于谣言的早期检测。
4 结束语
本文利用外部知识中的信息提出了一种自动谣言检测方法KGMRD。考虑了帖子中的实体信息与外部知识的链接,结合注意力机制将两者更好地聚合以得到增强的语义特征,提取帖子中的情感特征,考虑帖子传播结构特征;将增强的语义特征与情感特征以及结构特征融合,进而得到融合特征并进行谣言检测。为了评估KGMRD模型的合理性、有效性,在Weibo、Twitter 15和Twitter 16数据集上进行实验,对比SVM-RBF等七种不同的模型;为了验证各个模块的有效性,在三个数据集上进行了消融实验,实验结果表明,KGMRD方法综合来说优于传统的SVM-RBF等七种基线模型,全面论证了KGMRD方法的合理性与有效性。
下一步将考虑从源帖的图片、音频、视频等不同的模态信息中提取谣言特征,实现多模态谣言检测。
参考文献:
[1]Miró-Llinares F,Aguerri J C. Misinformation about fake news: a systematic critical review of empirical studies on the phenomenon and its status as a ‘threat [J]. European Journal of Criminology,2023,20(1): 356-374.
[2]Vosoughi S,Roy D,Aral S. The spread of true and false news online [J]. Science,2018,359(6380): 1146-1151.
[3]庞源馄,张宇山. 句子级状态下 LSTM 对谣言鉴别的研究 [J]. 计算机应用研究,2022,39(4): 2038-2041 (Pang Yuanhun,Zhang Yushan. Rumor identification research based on sentence-state LSTM[J]. Application Research of Computers,2022,39(4): 2038-2041.)
[4]Kwon S J,Cha M Y,Jung K M,et al. Prominent features of rumor propagation in online social media
[C]// Proc of the 13th IEEE International Conference on Data Mining. Piscataway,NJ:IEEE Press,2013: 1103-1108.
[5]Ma Jing,Gao Wei,Wong K F. Detect rumors in microblog posts using propagation structure via kernel learning [C]//Proc of the 55th Annual Meeting of the Association for Computational Linguistics (Vo-lume 1: Long Papers).Stroudsburg,PA:Association for Computational Linguistics,2017: 708-717.
[6]Bi Bei,Wang Yaojun,Zhang Haicang,et al. Microblog-HAN: a micro-blog rumor detection model based on heterogeneous graph attention network [J]. PLoS One,2022,17(4): 12-20.
[7]Castillo C,Mendoza M,Poblete B. Information credibility on Twitter [C]// Proc of the 20th International Conference on World Wide Web. New York: ACM Press,2011: 675-684.
[8]Sun Mengzhu,Zhang Xi,Zheng Jiaqi,et al. DDGCN: dual dynamic graph convolutional networks for rumor detection on social media [C]// Proc of AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press,2022: 4611-4619.
[9]Zhang Chengyang,Huang Xianying,An Jiahao. MACR: multi-information augmented conversational recommender [J]. Expert Systems with Applications,2023,213: 118981.
[10]郭秋實,李晨曦,刘金硕. 引入知识表示的图卷积网络谣言检测方法 [J]. 计算机应用研究,2022,39(7): 2032-2036. (Guo Qiu-shi,Li Chenxi,Liu Jinshuo. Rumor detection with knowledge representation and graph convolutional network [J]. Application Research of Computers,2022,39(7): 2032-2036.)
[11]Speer R,Chin J,Havasi C. ConceptNet 5.5: an open multilingual graph of general knowledge[C]//Proc of the 31st AAAI Conference on Artificial Intelligence. Palo Alto,CA:AAAI Press,2017:4444-4451.
[12]Dun Yaqian,Tu Kefei,Chen Chen,et al. KAN: knowledge-aware attention network for fake news detection [C]// Proc of AAAI Confe-rence on Artificial Intelligence. Palo Alto,CA:AAAI Press,2021: 81-89.
[13]Tseng Yuwen,Yang Huikuo,Wang Weiyao,et al. KAHAN: know-ledge-aware hierarchical attention network for fake news detection on social media [C]// Companion Proceedings of the Web Conference 2022. New York: ACM Press,2022: 868-875.
[14]Welling M,Kipf T N. Semi-supervised classification with graph convo-lutional networks [EB/OL]. (2017-02-22). https://arxiv.org/abs/1609.02907.
[15]Yang Fan,Liu Yang,Yu Xiaohui,et al. Automatic detection of rumor on Sina Weibo [C]// Proc of ACM SIGKDD Workshop on Mining Data Semantics. New York: ACM Press,2012: 1-7.
[16]Ma Jing,Gao Wei,Wong K F. Rumor detection on Twitter with tree-structured recursive neural networks [C]// Proc of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg,PA: ACL Press,2018:1980-1989.
[17]Lin Hongbin,Zhang Xi,Fu Xianghua. A graph convolutional encoder and decoder model for rumor detection [C]// Proc of the 7th IEEE International Conference on Data Science and Advanced Analytics. Piscataway,NJ:IEEE Press,2020: 300-306.
[18]Bian Tian,Xiao Xi,Xu Tingyang,et al. Rumor detection on social media with bi-directional graph convolutional networks [C]// Proc of AAAI Conference on Artificial Intelligence. Palo Alto,CA:AAAI Press,2020: 549-556.
[19]Liu Yang,Wu Yifang. Early detection of fake news on social media through propagation path classification with recurrent and convolutio-nal networks [C]// Proc of the 32nd AAAI Conference on Artificial Intelligence. Palo Alto,CA:AAAI Press,2018: 354-361.
[20]Xu Shouzhi,Liu Xiaodi,Ma Kai,et al. Rumor detection on social media using hierarchically aggregated feature via graph neural networks [J].Applied Intelligence,2022,53:3136-3149.
[21]Thota N R,Sun Xiaoyan,Dai Jun. Early rumor detection in social media based on graph convolutional networks [C]// Proc of International Conference on Computing,Networking and Communications. Piscataway,NJ: IEEE Press,2023: 516-522.
