基于无人驾驶配送实验平台的封闭园区内动态环境视觉SLAM研究
2024-05-10薄孟德
薄孟德
(哈尔滨师范大学地理科学学院,黑龙江 哈尔滨 150025)
0 引言
SLAM(Simultaneous Localization And Mapping),即同时定位与建图,是指主体搭载特定传感器,在无环境先验信息的前提下,于运动过程中建立环境模型并估计自身运动状态[1]。在虚拟现实、自动驾驶和机器人技术等多个领域内,SLAM技术扮演了一个关键的角色。过去几十年间,众多研究人员不断推进技术创新,提出了诸如LSD_SLAM,ORB_SLAM等卓越的算法。尽管许多视觉SLAM算法的性能十分优越,但大部分算法都基于静态环境假设[2]。然而,静态环境并不能完全反映现实使用情况,现实环境往往是动态变化的。在这些动态场景下,这些SLAM算法可能会面临定位不精确和地图构建存在误差的问题。因此,优化SLAM系统在动态环境中的精准性和稳定性已成为研究的焦点。本研究提出的算法是,使用HRNet网络提取人体关键点,从而进行人体姿态估计,通过分析连续30帧图像来识别人体的实际行为状态,从而更有效地去除动态特征点,并在TUM数据集的动态序列上验证该算法的性能。
1 系统框架
ORB_SLAM2是一种为单目、双目和深度摄像头设计的高效SLAM系统,包含地图重建、闭环检测和重定位功能。此系统基于PTAM算法架构,采用了ORB特征来增强视角的不变性。ORB_SLAM2通过三个并行的主要线程实现功能:第一个线程利用局部地图的匹配特征和运动BA重投影误差最小化技术进行相机跟踪;第二个线程负责管理和优化局部地图,执行局部BA;第三个线程进行闭环检测,以识别大范围的循环并通过位姿图优化来修正累积误差。在位姿图优化完成后,启动第四个线程进行全局BA,以精确调整结构和运动参数。ORB_SLAM2作为一种基于特征的方法,对输入进行预处理以提取显著关键点位置的特征,并且所有系统操作都基于这些特征[3]。本研究提出的动态视觉SLAM以该系统为基础进行改进,完整流程如图1所示。首先,系统在接收到视觉相机捕获的图像之后,利用HRNet从场景中提取出人体的关键点。然后,采用ST-GCN分析连续30帧图像,从而识别场景中人的行为模式,判断他们是否在移动。基于这个分析,可以有效地区分哪些动态特征点应该被剔除。最后,仅将剩余的静态特征点送入ORB_SLAM2的后续处理流程,以进行进一步的优化和地图构建。
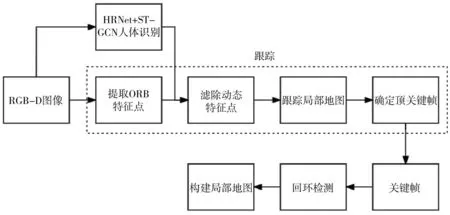
图1 系统框架图
1.1 基于HRNet的姿态估计
目前,大多数动态SLAM解决方案主要分为两类:一类是依赖于相机自身运动模型来处理动态环境下的视觉SLAM;另一类则不需要基于相机的运动模型,同样能够应对动态环境下的视觉SLAM。而在基于前者的这一类解决方案中,都需先计算相机运动状态再判断动态区域,而在计算相机运动状态这一过程中则需要滤除动态区域的静态路标点,存在着“是鸡生蛋,还是蛋生鸡”问题[4]。因此,本研究采用深度学习方法来判断封闭园区内动态目标的运动状态。通过深度学习的方法可以直接针对动态目标进行滤除,但不论是目标检测任务,还是分割类任务,都是通过对先验信息提前训练后得到的结果。此类任务只能判断出目标是否处于真实的运动状态,无法对目标的真实运动状态进行合理的判断。例如,场景中同时存在站立的人与运动的人,目标检测类任务与分割类任务无法完成对场景中人的真实运动状态的判断。
本研究选择通过行为识别任务完成对运动主体多为人的封闭园区的运动状态的判断,人体行为识别这类任务中,因为需要对人体关键点进行提取从而构建骨架,所以需要高分辨率的heatmap进行关键点检测。这与一般的网络结构要求不同,比如VGGNet,其最终得到的feature map分辨率较低,一定程度上损失了空间结构。为获取高分辨率feature map,大部分网络选择先降分辨率,然后再提高分辨率的方法,如U-Net,SegNet,Hourglass等。而在HRNet中,在不同分辨率的feature map间采用了类似“并联”的结构,并在此基础上在feature map间进行了交互。这种做法保证了在整个网络结构中高分辨率的表征都得以保持,并且以交互的形式提高了模型的性能。本研究在参数和计算量不增加的前提下使用COCO数据集中验证集部分对HRNet与其他同类网络人体关键点提取精度进行对比测试,结果显示,HRNet对人体关键点提取精度效果更加优秀。综合考虑,本研究使用HRNet进行人体关键点提取,使用ST-GCN进行人体行为识别。
1.2 基于姿态估计的行为识别
在2D或3D坐标下,动态骨骼模态可以通过人体关节位置的时间顺序表示,通过分析运动模式则可以做到行为识别。早期的动作识别技术主要通过在不同时间点捕捉关节位置,形成特征向量进行时序上的分析。但这种方法没有利用人体关节之间的空间关系。虽然有学者尝试利用关节间自然连接的方法进行行为识别,但大多数方法依赖手动设定规则来分析空间模式。因此模型泛用性较差,难以完成特定应用外的任务。ST-GCN是在骨骼图序列上指定的,其中每个节点对应一个关节。图中存在着符合关节的自然连接的空间边和在连续时间步骤中连接相同关节的时间边。在此基础上构建多层的时空图卷积,它使信息沿着空间和时间两个维度进行整合。ST-GCN的层次性消除了手动划分部分或遍历规则的需要,这增强了模型的表达能力并且提高了模型性能,本研究使用ST-GCN对场景中人物进行行为识别。
本研究使用NTU-RGB+D数据集进行训练,数据集由微软Kinect v2传感器采集,使用三个不同角度的摄像机采集数据深度信息、3D骨骼信息、RGB帧以及红外序列,包括60个种类的动作,共56 880个样本,其中包含日常行为动作40类,双人互动动作11类,健康相关动作9类[5]。这些几乎包括了封闭环境下所有常见的人体行为。本研究使用HRNet进行关键点提取后,利用ST-GCN进行人体行为识别,在HTU-RGB+D数据集上的cross-subject(X-Sub)与cross-view(X-View)两个基准测试中准确性分别达到了85.3%与89.8%。
2 测试与分析
本研究通过TUM数据集的多个序列进行实验分析。实验首先通过行为识别算法测试其对动态对象的识别能力,并移除对象区域内的动态特征点,以展示该算法的有效性;其次评估所提算法在轨迹偏差精确度方面的表现;最后评估该算法的处理速度。
TUM RGB-D数据集由慕尼黑工业大学(Technical University of Munich,TUM)的计算机视觉团队提供,其中包含RGB(彩色)图像和深度图像等39个序列,图像采集分辨率为640×480像素,频率为30 Hz[6]。数据集通常用于训练和评估计算机视觉算法,例如目标检测、物体识别、三维重建和SLAM等任务。本研究选用walking_xyz、walking_static、walking_half、sitting_static四个序列作为实验序列,其中因为拍摄时传感器的移动方式不同,使得walking_xyz、walking_static和walking_half序列呈现高度的动态性,由于sitting_static序列主要捕捉两个人坐在桌子前时手部的动态变化,因此sitting_static序列显示较低的动态性。文献[7-8]中关于动态场景下的视觉SLAM研究基本都建立在ORB_SLAM2的基础框架之上。同时,ORB_SLAM2算法已经被广泛应用,并且其内部参数经过了充分的优化。为了确保实验的一致性和有效性,本研究在使用ORB_SLAM2框架时,参数设置保持不变,使用了该算法的默认参数。
本研究采用相对位姿误差(Relative Pose Error,RPE)和绝对轨迹误差(Absolute Trajectory Error,ATE)对SLAM系统的定位精度进行评估。RPE衡量特定时间段内估计运动与实际运动的姿态差异,而ATE通过对比估计和真实轨迹的绝对差距,以评价系统的全局定位一致性。
RPE同时评估了平移和旋转误差,而ATE仅衡量平移误差。设时间步长为i,时间间隔为t,定义相对位姿误差如下:
其中,Qi为第i帧的真实位姿,Pi为第i帧的估计位姿。
定义绝对位姿误差为:
其中,S为估计位姿到真实位姿的转换矩阵。
2.1 实验平台
本研究使用封闭园区内的无人驾驶配送实验平台(图2)对所提算法进行测试。实验平台使用Apollo自动驾驶系统,该系统是国内应用广泛的自动驾驶开源系统。平台搭载轮式里程计、IMU、激光雷达、RGB-D摄像头等多种传感器。选用此平台对本研究所提算法进行实地验证,图3为本研究所提算法使用实验平台在封闭园区内的应用。本研究中的算法测试环境配置包括:显卡为NVIDIA RTX 3060,处理器为i7-10750H,操作系统为Ubuntu 18.04,使用了CUDA 11.0和Pytorch 1.8.0。

图2 无人配送实验平台

图3 本研究算法使用实验平台在封闭园区内的应用
2.2 效果对比
在TUM数据集的walking_xyz序列中选择一组图像进行比较,图4(a)展示了ORB_SLAM2在该场景下捕获的特征点,而图4(b)展现了本研究算法捕获的特征点。结果显示,本研究所提出的算法能够有效地识别两个人的动作,并且能够排除包含在人物上的动态特征点,仅保留静态特征点。

图4 动态特征点滤除效果
2.3 精度对比
实验对比了walking_xyz、walking_static、walking_half、sitting_static四种序列的精度,采用ATE和RPE进行量化评估,并提供了均方根误差(RMSE)和标准差(SD)两种度量指标。使用如下公式描述精度的增强程度:
其中,α为ORB_SLAM2的运行结果,β为本文所提算法的运行结果。
表1至表3展示了ORB_SLAM2与本研究提出算法在walking_xyz、walking_static、walking_half、 sitting_static序列中的性能对比及精度改进情况。结果表明,在活动强度较高的序列中,本研究的算法明显优于ORB_SLAM2,在各项指标上都有所提高。对于活动强度较低的序列,改进不太显著,这主要是由于动态变化不明显,而ORB_SLAM2能够利用其噪声消除算法较好地处理这些低动态环境。因此,在低动态场景中,本研究算法的性能改进并不突出。与DS_SLAM的比较结果见表4,DS_SLAM的相关性能数据可以在文献[9]中找到。从表中可以看出,本研究算法在各个序列中均可达到与DS_SLAM类似的精度水平。

表1 ATE对比
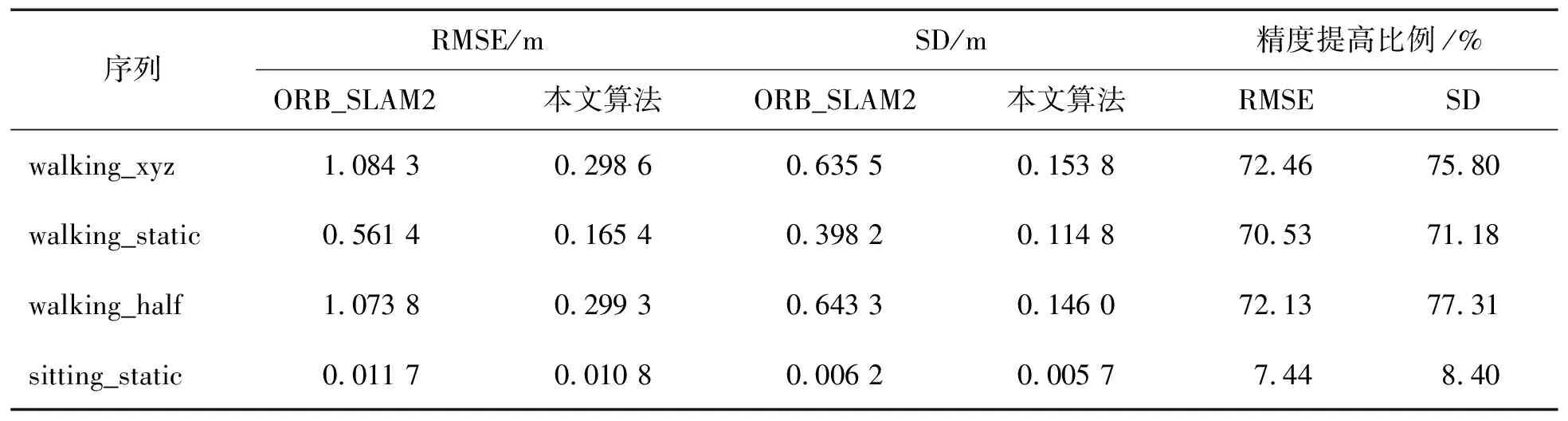
表2 RPE平移误差对比
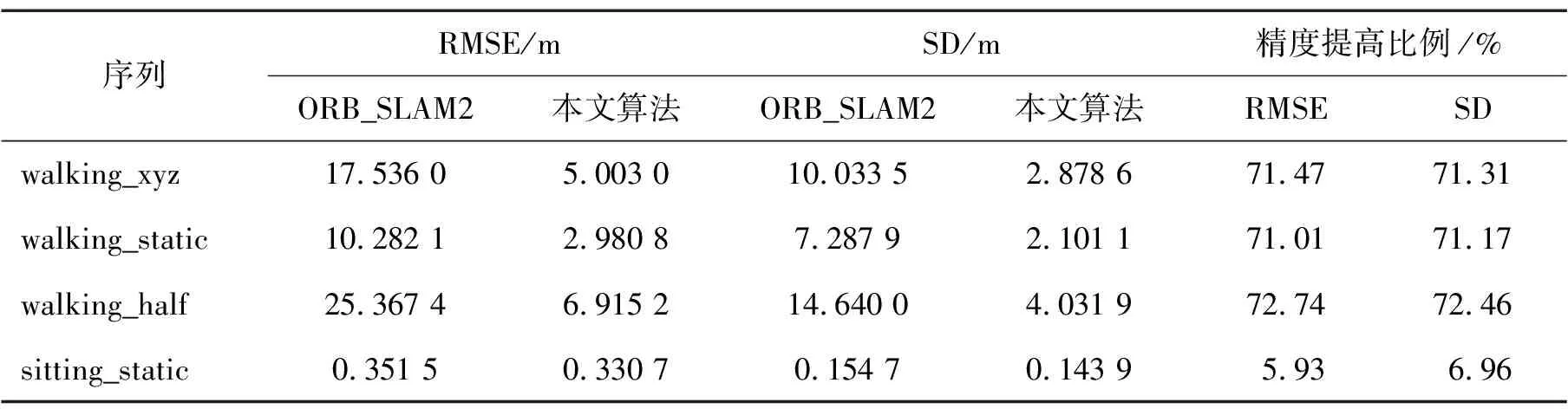
表3 RPE旋转误差对比

表4 动态环境下的SLAM算法RMSE对比
2.4 速度对比
在探讨动态环境下的视觉SLAM问题时,不能忽视算法运行速度的重要性。表5对本研究提出的算法、ORB_SLAM2以及DS_SLAM在同一硬件条件下的执行时间进行了比较。本研究算法在保持ORB_SLAM2架构的基础上,额外加入了一个识别人体行为的线程,因此其追踪处理时间略高于ORB_SLAM2。然而,与DS_SLAM相比较,本研究算法在执行速度上展现出了优势。
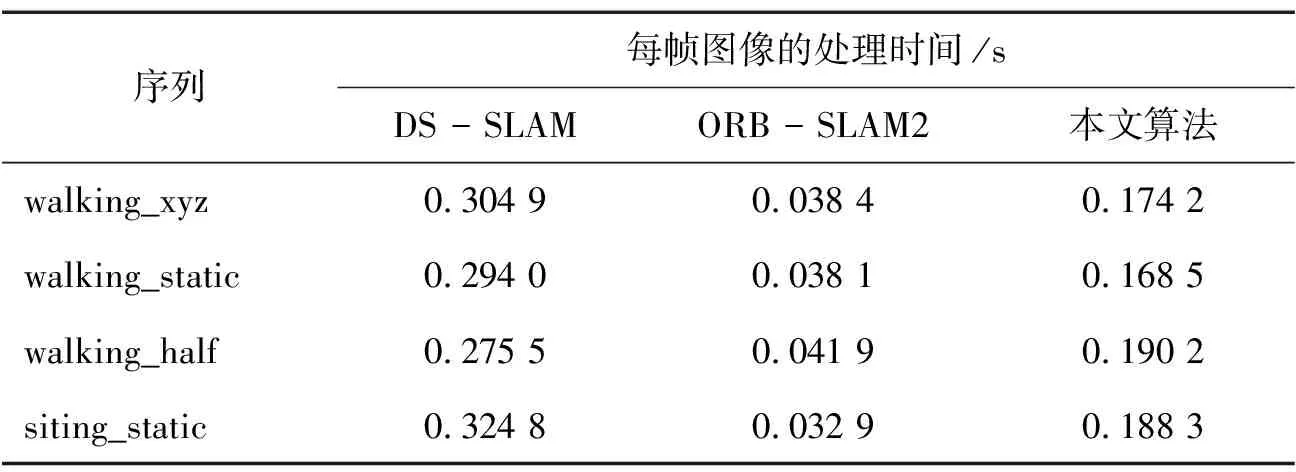
表5 动态环境SLAM算法速度对比
综上,综合各方面的对比数据,本研究提出的算法在保证性能的同时,也实现了速度与精度之间的有效平衡。
3 结论
本研究开发了一套针对封闭区域中动态环境的视觉SLAM系统,该系统在ORB_SLAM2框架上集成了一个人体动作识别模块。通过识别图像中人体的实际动作,该系统能够有效识别并去除动态特征点,确保了特征点的静态属性。
通过与其他主流SLAM算法进行比对,结果显示,本文算法对位姿估计的精度有所提高并保证了算法运行速度,实现了速度与效果的平衡。
本研究提出的方法在处理占较大比例的动态区域图像时,可能会导致过滤后剩余的特征点数量不足。接下来需着手解决如何平衡算法的速度和性能,并拓展其在不同应用场景中的适应性。
