一种改进的视网膜脱落图像分割算法研究
2024-05-10王艳梅张佳良张艳珠史铭宇
王艳梅,张佳良,张艳珠,史铭宇,李 妍
(1.沈阳理工大学信息科学与工程学院,辽宁 沈阳 110159; 2.沈阳理工大学自动化与电气工程学院,辽宁 沈阳 110159;3.中国医科大学附属第四医院,辽宁 沈阳 110005)
0 引言
视网膜脱落是一种常见的眼科疾病,是视网膜与眼球后壁之间的色素上皮层发生分离,导致视网膜功能障碍或丧失的病理过程。视网膜脱落的原因有多种,如外伤、近视、糖尿病、老年性黄斑变性等。视网膜脱落的临床表现主要有视力下降、视野缺损、闪光、飞蚊等。视网膜脱落如果得不到及时诊断和治疗,可能导致视网膜萎缩、眼球萎缩、失明等严重后果。因此,视网膜脱落的早期发现和确诊断对于保护患者的视力和眼球健康具有重要意义。眼底超声是一种利用超声波探测眼球内部结构的检查方法[1],具有无创、快速、廉价、可重复等优点,适用于各种眼科疾病的诊断,尤其是对于不能直接观察眼底的情况,如白内障、玻璃体混浊、眼球出血等。眼底超声可以分为B超和彩超两种模式,B超是黑白的二维图像,显示眼球内部的反射强度,彩超是彩色的二维图像,显示眼球内部的血流速度和方向。眼底超声可以用于视网膜脱落的诊断,通过观察视网膜的位置、形态、活动度等,判断视网膜是否脱落,以及脱落的范围、程度、类型等。然而,眼底超声图像的质量通常较低,存在噪声、模糊、伪影等问题,且其他模型无法充分提取图像特征,存在特征提取不充分、信息丢失等问题[2]。以往主要通过医生的眼睛动态判断,人工分割视网膜脱落区域较为困难。
本文基于U-Net[3]进行改进,提出一种基于深度学习的眼底图像疾病分割方法,将残差网络和可变性卷积加入到主干网络,利用注意力机制对现有的深度学习网络架构进行优化改进,将这个改进模型称为RDFA-Net(Residual and Deep-scale Feature Fusion Attention Network),可以有效地对病灶部位进行分割。本文主要工作有以下四个方面:第一,对眼底超声图像的病灶进行图像分割;第二,在U-Net网络的基础上,引入了空间注意力和通道注意力两种注意力机制,分别用于增强图像的局部特征和全局特征,提高网络的感受野和表征能力,并加在网络的深层部位;第三,在残差主干网络中提出可变形残差卷积组成特殊的残差网络;第四,设计深层信息传递结构,将深层特征中的信息送到浅层网络中进行堆叠,使得网络模型可以联系上下文提取多尺度特征信息。并在自建的视网膜脱落的彩超数据集上进行了实验,与其他几种常用的深度学习分割方法进行了对比。
1 RDFA-Net模型
本文提出了一种新的网络结构(RDFA-Net结构),如图1所示,用以分割视网膜脱落超声图像的病灶部位。新模型保留传统U-Net的主干特征提取网络和加强特征提取网络的编码器解码器结构。原U-Net主干特征提取部分由卷积和最大池化组成,整体结构与VGG类似,本文使用改进的ResNet50[4]特征提取网络作为主干网络,由于视网膜脱落病灶部位目标比较大,但是形状不一,传统的特征提取方法使用固定的卷积视野较小,效果不佳,所以在主干网络第四阶段使用可判定可变形卷积DCNV2[5],为网络提供更大的灵活性,可以选择具有信息量的区域,提高对细节的捕捉能力,使模型的效果能得到提升。在解码器部分参考多尺度特征网络在深处提取特征进行8倍上采样拼接到浅层特征中,不进行过多拼接,使得深层特征得到展现,有效地将多尺度信息进行特征高效化传递,为解码器提供深层层次的特征信息,以此提高分割精度。同时在深层解码器中引入通道注意力模块和空间注意力模块CBAM以提高对目标的关注度,产生更好的分割结果[6]。

图1 RDFA-Net结构图
1.1 可变形残差卷积模块
在超声图像分割任务中,由于目标形状的特征是立体动态变化的,且区域较大,普通的特征提取方法难以提取到有效的特征,且随着网络层数的加深,正确率会变得增长缓慢或是下降,模型的准确率会降低。为了解决这一问题,将原来U-Net中的主干特征提取网络Vgg网络结构替换为Resnet50残差结构,ResNet50结构在输入Input经过Resnet50到输出Output,分为5个阶段(STAGE0~STAGE4),如图2所示。共经过了50个层,STAGE0中的2层(conv7×7、max pooling),STAGE1中9层(3×3),STAGE2中的12层(3×4),STAGE3中的18层(3×6),STAGE4中的9层(3×3)。其中STAGE0可以看作数据的预处理,后面的STAGE1至STAGE4都由数个Bottleneck模块组成,结构相似,图2虚线框中为各Bottleneck的结构,其中CONV是卷积,BN是Batch Normalization的缩写,即BN层,RELU指ReLU激活函数。

图2 可变形残差卷积模块结构
传统的残差结构虽然动态性较好,对于深层网络的补偿性较好,但是对于网络性能的正面提升没有帮助。为了加强效果,将第四个Bottlenet中的残差通道判定部分的原卷积Conv,替换为动态的可变形卷积DCNV2,在判定通道数输出不等于输入时,或残差通道起作用时,可通过可变形卷积进行下采样,提高特征提取能力,将新的结构命名为Bottleneck3模块。
可变形卷积DCNV2是可变形卷积DCNV1的改进版,在传统卷积单元(卷积核)中对输入的特征图在固定的位置进行采样。所带来的问题是卷积核权重的固定导致同一CNN在处理一张图不同位置区域时感受野尺寸都相同,这对于编码位置信息的深层卷积神经网络是不合理的。因为不同的位置可能对应不同尺度或者不同形变的物体,这些层需要能够自动调整尺度或者感受野的方法。DCN卷积模块的结构如图3所示,偏差通过一个卷积层conv获得,输入特征图,输出偏差。生成通道维度是2N,其中的“2”分别对应X和Y这两个2D偏移,N是通道数。一共有两种卷积核:卷积核和卷积核学习offset对应的卷积层内的卷积核,这两种卷积核通过双线性插值反向传播,同时进行参数更新。这种实现方式相当于比正常的卷积操作多学习了卷积核的偏移。在DCNV2中,每个样本不仅需要学习DCNV1中的偏移量,而且还要通过学习到的特征幅度进行调制。这个网络模块因此能够改变其样本的空间分布和相互之间的影响,特征幅度的表达如下:
(1)
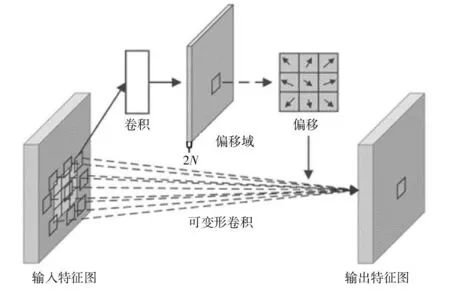
图3 可变形卷积模块结构
其中,Δmk是第k个位置的调制标量(k是卷积网格的表示位置的数字)。
调制标量Δmk的取值范围为[0,1]。Δpk和Δmk可在相同的输入特征图x上,分别通过一个单独的卷积得到。该卷积层与当前卷积层具有相同的空间分辨率和膨胀度。输出通道数为3K,其中前面的2K通道对应学习到的偏移Δpk,剩下的K个通道再送到Sigmoid层[7],得到调制标量Δmk。将之后得到的Δmk加入到输入特征上,用来在学到的偏移位置上调制特征的幅度。
本文提出的可变形残差卷积模块残差结构和可变形卷积相结合,形成互补的效果,可以动态地提升特征提取能力,提升模型的精度效果。
1.2 深层信息传递结构
为了解决原U-Net网络横向融合特征而忽略深层特征的问题,提高病灶分割的效果,将深层的横向融合后的特征,通过深尺度特征提取,并入浅层特征融合中,之后进行预测。如图1所示,在特征提取部分第一次拼接操作后,将拼接后的深层特征p2直接进行8倍上采样后提出,生成具有深层语义信息的特征图,与第四次拼接的结果再次拼接,用以同时捕捉深层的深尺度特征信息和浅层的空间几何特征信息,之后进行两次卷积操作和Relu激活函数运算,将通道数同步为与第四次拼接处结果相同的通道数。
令O∈R(H×W×C),P∈R(H×W×C),O表示编码器在第二层的输出特征图,P表示解码器在第二层的输出特征图,其中H,W,C分别表示特征图的高度、宽度和通道数。因此深尺度信息传递结构可表示为:
V=Ct(Ct(C1∶Up(C2))∶Up(C3))·Cv·R,
(2)
其中,C1为解码器第一层输入特征,C2为编码器第二层输入特征,C3为第四层编码器输入特征,Ct(1∶2)表示将通道1和通道2进行特征通道融合操作,Up表示上采样操作,Cv表示卷积,R为Relu激活函数。
1.3 CBAM注意力机制
本研究使用空间和通道结合的注意力机制CBAM(Convolutional Block Attention Module)来提取病灶特征,CBAM同时将空间注意力和通道注意力相结合,其结构如图4所示。将图像特征的输入分别进行通道注意力和空间注意力的处理,拥有良好的信息获取能力,在输入的单层特征后依次进行全局平均池化和全局最大池化。之后对上述操作得到的结果,利用共享的全连接层进行处理,将处理后的两个结果相加,通过Sigmoid激活函数得到输入特征层每一个通道的0到1之间的权值。在获得这个权值后,将这个权值乘以原输入特征层。空间注意力机制对输入进来的特征层,在每一个特征点的通道上取最大值和平均值,之后将这两个结果进行一个拼接,利用一次通道数为1的卷积调整通道数,同样使用Sigmoid激活函数得到输入特征层每一个通道的0到1之间的权值之后乘以原输入特征层。由于深层特征较为抽象,本文将此注意力机制加在特征提取网络部分中的第三层输入之后,在经过特征提取后与上采样的结果进行拼接。
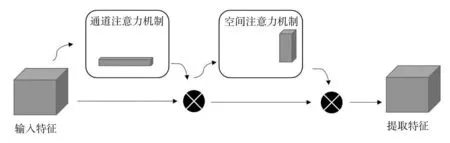
图4 通道和空间注意力机制
2 实验与结果分析
2.1 实验环境
实验所用的环境为CPU:R7 5800,GPU:RTX3060,16 G内存,Windows11系统,Python3.6,在相同的环境下进行网络训练。
2.2 数据集
本研究所用的数据集来自合作医院长期收集的视网膜脱落患者的彩色超声视频,将患者检测的超声视频逐帧截取筛选,手工截取相关区域,用Yolov5深度学习网络检测眼眶统一数据集尺度,再进行镜像翻转扩充数据集的数量。通过Labelme软件标注病灶区域,之后交给医生修改并确认正确后,得到最终数据集。最终处理成224×224的图像129张。将数据集的80%划分为训练集,20%划分为测试集,进行深度学习网络的训练。
2.3 评价指标
对视网膜脱落的视网膜病灶部分进行语义分割,实际是对图像中的每个像素点进行分类。图像中的每个像素点被分为病灶部位和非病灶部位两类[8]。评价指标有真阳性(TP)、假阳性(FP)、真阴性(TN)、假阴性(FN)。通过计算可得到准确率(PA)、类别平均像素准确率(MPA)、交并比(IoU)、召回率(RECALL)、平均交并比(MIoU)。
2.4 实验结果
在自制的数据集上进行实验,使用RDFA-Net对相应病灶部位进行分割,分割结果如图5所示,其中(a)(c)为原始图片,(b)(d)为前一张对应的分割结果。RDFA-Net正确地确定到视网膜脱落的视网膜位置,并未错误识别附近相邻不相关的非病灶区域,且由第二个病变的分割结果可知,分割的边缘表现结果也较为准确。
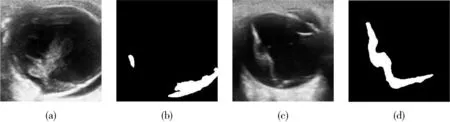
图5 RDFA-Net的分割结果
将RDFA-Net与HRNet[8]、ResNet、U-Net、Deeplabv3[9]方法进行比较(表1)。RDFA-Net模型的准确率达到了0.978 3,相较于U-Net提升了0.004 3;IoU值达到了0.692 5,相较于U-Net提升了0.022 6,相较于HR-Net提升了0.113 2;MPA值达到了0.917 9,均优于其他方法。

表1 RDFA-Net与其他方法的评价指标
2.5 消融实验
为了进一步证明本文提出的可变形残差卷积模块和深层信息传递结构,进行消融实验,分别保留可变形残差卷积模块(表2),去除CBAM注意力机制模块(表3),去除深层信息传递结构(表4),与基线网络U-Net和RDFA-Net进行对比。

表2 保留可变形残差卷积模块对评价指标的影响

表3 去除CBAM注意力机制模块对评价指标的影响

表4 去除深层信息传递结构对评价指标的影响
由表2可以看出,在保留可变形残差卷积模块后,网络性能相较于U-Net准确率提升了0.002 6,MPA值提升了0.013 1,IoU值提升了0.016 0,MIoU值提升了0.011 5。由此可见,可变形卷积模块动态卷积对于分割是有提升效果的。
由表3可以看出,在去除CBAM注意力机制后,RDFA-Net的各项性能指标都有所下降,说明CBAM在第二层连接处可以有效地提取病变的空间和通道特征,CBAM模块拥有优秀的特征提取能力。
由表4可以看出,在去除深层信息传递结构后,保留其他模块,IoU值下降了0.029 1,其他性能指标也均有所下降,由此验证了保留深层提取信息的有效性,深层信息传递结构可以有效地保留深层信息,提升分割精度。
3 结语
本文针对视网膜脱落超声图像的病灶分割问题,以U-Net为基础,在优化为残差主干特征网络的同时加入可变性卷积,可以动态卷积提取特征,引入通道和空间注意力机制,加强网络的信息获取能力,改进了加强特征提取网络部分的结构,使网络能兼顾深层尺度信息,实现了对超声图像视网膜脱落病灶的分割工作,实现了较好的性能,优于其他方法。视网膜脱落病灶与其他部位的超声图像是相似的,RDFA-Net也可以应用到其他病灶分割任务。
