融合信任度和热门惩罚的协同过滤推荐算法
2024-05-10何进成刘其刚
何进成,王 浩,孙 刚,刘其刚
(阜阳师范大学计算机与信息工程学院,安徽 阜阳 236037)
0 引言
随着信息技术的高速发展,互联网上的信息资源不断扩充,文本、图片、视频等媒体资源数量迅速增长,推荐系统可以向不同用户推送用户可能喜欢的视频或商品。推荐系统包括基于内容的推荐。协同过滤算法的推荐和混合推荐[1]。协同过滤(Collaboration Filtering)算法[2]是推荐系统中常用的算法[3]。针对传统协同过滤算法存在的推荐精确率不高的问题,国内外学者基于该算法做过相关的研究和改进,ZARZOUR等[4]在协同过滤算法中引入场景相似度的概念,对相似度的计算步骤进行了改进,该算法解决了矩阵稀疏性问题,提高了算法的精度。AHLEM等[5]提出的模型分为两个阶段,前一个阶段根据用户的交互行为进行用户相似性计算,后一个阶段根据用户的专业水平向用户推荐所需要的服务,该模型有效地提高了算法的精度。WU等[6]提出的一种新的相似度计算方式,利用两个用户对相同物品的评价比值作为相似度的计算依据,使得新的算法模型能更好提升算法的精确性。李熠晨等[7]根据用户之间的共同评分数量和预测误差进行计算,从而提高推荐算法性能。姚亦飞等[8]提出学习推荐算法,结合学习者复习策略设计和调整学习序列,有助于学习者掌握学习重点和难点。刘国丽等[9]通过联合专家用户和属性相似用户共同为目标用户产生推荐,有效地解决了冷启动问题。
协同过滤算法对用户和项目的关系进行建模,通过计算用户之间的相似度或项目之间的相似度来为用户进行个性化推荐[10]。用户相似度计算的方法有余弦相似度[11]、Jaccard系数、Pearson相关系数[12]等。通过相似度找出与目标用户最相似的k个用户,使用k个近邻用户对当前用户尚未评分的项目来预测目标用户对某个项目的评分。但是,这种计算方式存在两个问题:第一,只通过相似度来衡量存在一定的局限性,在衡量用户之间的关系时,除了相似度还可以融合用户之间的信任度,故本文算法在此基础上增加信任度机制;第二,对于热门商品,如《新华字典》这类几乎人人都有的商品不需要向所有用户都推荐,可以减少推荐频率,故本文算法增加了对热门商品的惩罚机制。因此,本文主要工作如下:1)在用户相似度的基础上增加用户信任度,解决真实场景下的用户信任不对等问题;2)在协同过滤的基础上,增加对热门项目进行惩罚措施,弱化对热门项目的推荐,突出推荐系统的个性化推荐功能;3)在真实的数据集MovieLens上进行相关实验,其相关评价指标均比传统的协同过滤算法有所提高。
1 相关理论
1.1 协同过滤
协同过滤算法基于k近邻模型,利用相似度计算用户或项目的k近邻集合,再根据需要推荐集合中前k个元素。在使用k近邻模型进行推荐时,k值的选取需要在合适的范围,k过大或过小都会对推荐性能有所影响。协同过滤算法分为基于用户的协同过滤(UserCF)和基于物品的协同过滤(ItemCF)两类。基于用户的协同过滤算法流程如下:对于给定的用户集U和项目集I,矩阵R为一个|U|×|I|的评分矩阵,矩阵中的每一个元素r∈R,表示用户u对项目i的评分,矩阵的每一行是某个用户u对所有项目i的评分向量,矩阵的每一列表示某个项目i被所有用户u的评分向量[13]。在真实的数据集中,很多用户只对部分项目进行过评分,即矩阵R是一个稀疏矩阵,用户对已知项目的评分数量远小于矩阵中的未知项目评分数量,即矩阵的稀疏性问题。为了解决矩阵的稀疏性问题,可以构建user-item倒排表,由此得到物品与用户的交互信息,通过倒排表计算出相似度矩阵,进而计算出用户之间的相似度,根据相似度和相似用户对item的评分来估算出目标user对目标item的评分,根据评分的大小,为用户推荐前k个项目。
1.2 相似度计算
1.2.1 余弦相似度
余弦相似度的计算方式如下:
(1)
其中,m表示用户u和用户v之间的相似度,N表示用户u和用户v有过共同评分的项目集合,r表示用户u对项目i的评分,y表示用户v对项目i的评分。
1.2.2 Pearson相关系数
Pearson相关系数的计算方法是对余弦相似度的一种改进计算方法[14],其计算公式如下:
(2)
其中,m表示用户u和用户v之间的相似度,N表示用户u和用户v有过共同评分的项目集合,r表示用户u对项目i的评分,y表示用户v对项目i的评分,h表示用户u所有评分项目的平均值,g表示用户v所有评分项目的平均值。
1.3 评分预测
协同过滤算法在计算得出相似度后,根据用户之间的相似度和最近邻的k个相似用户的评分,计算出目标用户对未评价过的商品的预测评分,计算公式如下:
(3)
其中,Y表示用户u对项目i的预测评分,K表示与用户u相似度排名较高的前k个用户,U表示对项目i有过评分交互的用户集合,m表示用户u和用户v的相似度,r表示用户v对项目i的评分。
2 协同过滤算法改进
2.1 算法流程
本文算法(TrustUserCF-Based)流程如下:
步骤1 读取MovieLens数据集中电影评分文件,依次读取到UserId、ItemId、rating各字段的值;
步骤2 对原始数据集进行划分,划分75%的训练集和25%的测试集;
步骤3 使用训练集数据,构造user-item的评分矩阵,使用该评分矩阵,计算用户之间的相似度;
步骤4 对热门项目添加惩罚机制,减少热门项目的推荐;
步骤5 计算用户u对用户v的信任度;
步骤6 根据上述步骤3到步骤6的计算结果,计算用户之间的相似信任值S;
步骤7 根据步骤6的相似信任值结果,计算目标用户对item的评分;
步骤8 根据近邻值k进行item的推荐;
步骤9 对推荐的结果进行评估,计算出算法的各项评价指标。
2.2 融合信任度的协同过滤算法
传统的基于用户的协同过滤算法利用用户的相似度来计算目标用户对项目的预测评分。传统的基于用户的协同过滤算法认为,用户u和用户v之间只需要相似度来衡量相互之间的关系,用户u和用户v之间的信任度是对等的[15]。而在现实生活中,用户u和用户v之间的信任是有所差异的,如用户u因为有较多的人生阅历而被更多的人信任,而用户v的人生经历较少,所以两者之间的信任度是有所差异的,即在真实的数据集中用户u和用户v之间的信任度是不对等的。故本文在用户相似度的基础上添加用户信任度值来综合衡量用户之间的关系。信任度的计算公式如下:
(4)
其中,t表示用户u对用户v的信任度,N表示用户u有过评分的项目集合,M表示用户v有过评分的项目集合。
从上述计算公式可以看出,信任度考虑了用户u和用户v共同评分的项目在用户u的评分项目中的占比,以及用户u和用户v共同评分的项目在两个用户评分过的项目中的占比。当用户u和用户v共同交互项目越多,u对v的信任度越高,并且用户u对用户v的信任度与用户v对用户u的信任度是不同的。
在计算出用户之间信任度后,再结合用户之间的相似度,可计算出用户u和用户v的相似信任值S,其计算公式如下:
S=m×t,
(5)
其中,S为用户u对用户v的相似信任值,m为用户u和用户v的相似度,t为用户u对用户v的信任度。
2.3 对热门项目的惩罚
当某个商品非常热门时,很多用户都对该商品有过评分,如《新华字典》这类商品,在计算时该类热门商品权重会较大,在推荐时需要考虑对该类商品进行一定的惩罚措施,惩罚计算公式如下:
(6)
其中,m表示用户u和用户v的相似度,U表示对项目i有过评分的用户集合,N表示用户u有过评分的项目集合,M表示用户v有过评分的项目集合。
2.4 改进的评分预测
在计算出用户之间的信任相似值后,可计算目标用户对item的评分预测,其计算公式如下:
(7)
其中,Y表示用户u对项目i的预测得分,h表示用户u所有项目评分的平均值,U表示项目i有过评分的用户集合,K表示与用户u相似信任值最接近的k个用户,S表示用户u对用户v的相似信任值,r表示用户v对项目i的评分,g表示用户v对所有项目评分的平均值。
3 实验
3.1 实验数据集
本实验采用的是Movielens数据集,该数据集是由943名用户对1 682部电影的100 000个电影评分数据组成[16],其中评分范围为1分至5分,分值越高表示用户对电影的喜爱程度越高。数据主要由用户编号(userId)、电影编号(itemId)、电影评分(rating)字段组成。实验中,将数据集随机划分成训练集和测试集,分别用来完成训练和测试任务。
3.2 算法评价指标
本实验采用精确率(Precision)、覆盖率(Coverage)、F1值(F1-score)来评价算法推荐性能。
3.2.1 精确率
精确率为预测结果中符合实际值的比例,通过如下公式计算,Precision 的值越高,表明算法的性能越好[17]。
(8)
其中,P表示精确率,T表示实际为正样本,预测结果也为正样本,F表示实际为负样本,预测结果为正样本。
3.2.2 覆盖率
覆盖率为推荐成功的项目占总项目的比例,可预测项目对目标用户是否有效,其计算公式如下:
(9)
其中,C表示覆盖率,n表示用户u所推荐成功的项目数目,N为所有项目数量。
3.2.3 F1值
F1值为精确率和召回率的调和均值[18],其计算公式如下:
(10)
其中,F1表示F1值,P表示算法的精确率,R表示算法的召回率。
3.3 实验结果与分析
与本文算法(TrustUserCF-Based)对比的算法分别为传统的基于用户的协同过滤(UserCF)、基于物品的系统过滤(ItemCF)、融合惩罚热门项目的用户协同过滤算法(CF-P)和融合信任度的用户协同过滤算法(CF-T)。
为了直观展示本文算法的各项指标,在实验中通过选取不同的k近邻值进行实验,其实验结果精确率、覆盖率和F1值通过折线图的方式展现(图1、图2、图3)。

图1 不同算法在k值为10至150之间的精确率
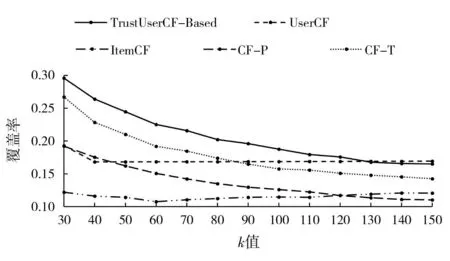
图2 不同算法在k值为30至150之间的覆盖率
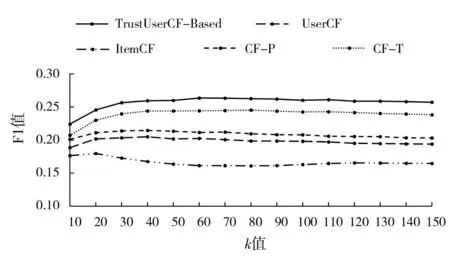
图3 不同算法在k值为10至150之间的F1值
由图1可知,k值在10至150范围时,本文算法(TrustUserCF-Based)精确率均优于比较的基于用户的协同过滤算法(UserCF)和基于物品的协同过滤算法(ItemCF)。k值为70时,本文算法的精确率比协同过滤算法(UserCF)提升16%,比只融合热门惩罚的用户协同过滤算法(CF-P)提升13%,比只融合信任度的用户协同过滤算法(CF-T)提升9%。
由图2可知,k值位于30至150的范围时,本文算法(TrustUserCF-Based)覆盖率优于比较算法UserCF和ItemCF,在k值为30时,其覆盖率比UserCF算法提升10%,比ItemCF算法提升17%,比CF-P算法提升10%,比CF-T算法提升3%。随着k值的提高,覆盖率呈下降趋势,原因是随着k值的上升,推荐了更多相似信任值较低的用户,导致了整体预测正确的项目个数有所减少。
由图3可知,k值位于10至150的范围时,本文算法TrustUserCF-Based的F1值优于比较算法UserCF和ItemCF。k值为100时,本文算法比传统的UserCF算法提升6%,比ItemCF算法提升10%,比CF-P算法提升5.6%,比CF-T算法提升2%。k值位于10至150的区间时,F1值呈现先递增后递减的趋势,所以在项目中可以选择适中的k值以保证推荐系统的性能。
本文算法与对比算法的精确率、覆盖率和F1值的实验结果如表1所示。由表1可以看出,本文算法的精确率、覆盖率和F1值相较于传统的协同过滤算法在三项指标上均有所提高。
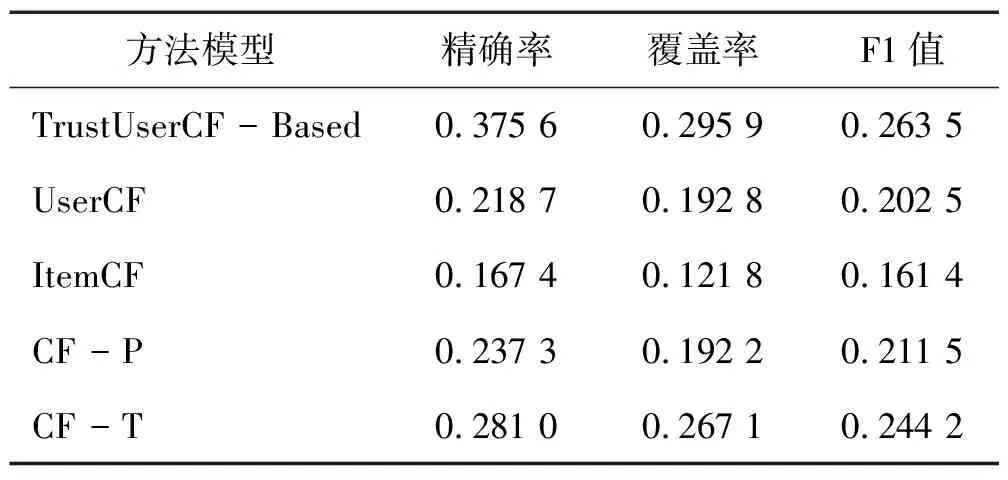
表1 本文算法与对比算法的实验结果
通过对上述实验结果的分析可知,传统的协同过滤算法在没有考虑对热门项目添加惩罚机制时,会影响到推荐的结果。同时,在没有考虑用户之间不对等的信任度时,也会对实验的结果产生影响。并且从实验结果来看,在UserCF上单独添加热门惩罚和用户信任度时,用户信任度对推荐的评价指标影响更大,只添加热门惩罚的算法比传统的协同过滤算法的精确率、覆盖率和F1值能提升2%~4%,只添加用户信任度的算法比传统的协同过滤算法的精确率、覆盖率和F1值能提升5%~7%,故可看出,用户信任度比热门惩罚对算法的性能影响更大。
4 结语
推荐系统是针对解决当前信息过载问题常用的处理方式,传统的协同过滤算法由于在评分预测时只根据user-item的评分矩阵计算用户之间的相似度,而导致算法精确率不高。针对此弊端,本文提出的融合信任度的协同过滤算法(TrustUserCF-Based)不仅考虑了用户之间的相似度,同时考虑用户之间不对等的信任度,在真实数据集MovieLens上的实验表明,本文算法的TrustUserCF-Based算法对推荐系统性能的提升有积极的作用,在电商和短视频推荐等常用的推荐场景下均有一定的适用性。在今后的工作中,将继续研究推荐系统中用户和项目的交互问题,挖掘交互过程中更多的有效信息,挖掘用户、项目、交互记录和用户的自身属性中的隐式反馈信息,将user和item之间的交互通过图的连通性来进行建模。
