基于改进ORB-SVM的工件识别方法研究
2024-03-13仝保国刘凌云
仝保国,刘凌云
(湖北汽车工业学院 电气与信息工程学院,湖北十堰 442002)
0 引言
随着视觉技术的发展,机器视觉已广泛应用于物体检测、目标识别、图像匹配、跟踪、SLAM、姿态估计、三维重建和增强现实等领域,极大地提高了运行效率和处理效果[1-3]。机器视觉的核心是通过对图像进行处理分析,提取图像特征信息,从而实现目标图像的识别分类[4-5]。
在经典的图像特征提取算法(如SIFT,SURF和ORB)基础上,相关学者不断提出一些改进方法来对特征提取算法进行优化,如鹿志旭等[6]使用DAISY特征描述符替换SURF特征描述算子,并采用随机抽样一致算法删除误匹配点,提高算法运行效率及匹配精度;谭光兴等[7]采用十字形对SIFT特征点邻域进行分区,简化特征描述子并降低描述子的维度,并结合余弦相似度约束条件过滤伪匹配;钟鹏程等[8]在ORB算法的特征描述中添加SURF方向信息,并采用快速近似最近邻搜索算法对特征点进行匹配。
然而,针对相似度较高的小工件,现有算法存在识别精度不高,对图像尺度或旋转、光照强度或角度等外部因素的鲁棒性较差等问题。本文提出改进ORB-SVM的工件识别方法,即在ORB特征提取的基础上引入SIFT进行特征描述,并通过词袋模型(bag word model,BoW)进行降维处理,最后采用支持向量机(support vector machine,SVM)实现多品种工件的识别。通过试验表明,该方法具有良好的识别效果。
1 改进ORB-SVM算法
改进ORB-SVM的算法流程如图1所示。

图1 改进的ORB-SVM算法流程图Fig.1 Flowchart of improved ORB-SVM algorithm
1.1 ORB特征检测
ORB算法是在FAST(features from accelerated segment test)角点和BRIEF(binary robust independent elementary features)描述子的基础上做了改进和优化[9]。FAST算法通过周围邻域其他像素点的像素值大小来判断是否为特征点。FAST特征点检测示意如图2所示。

图2 FAST 特征检测示意图Fig.2 Schematic diagram of FAST feature detection
在以像素点P为中心,半径为3的圆上,取邻域圆上16个像素点(P1,P2,…P16)并设置阈值T,通过计算像素点P1,P5,P9,P13与点P的像素差。若至少有3个像素差的绝对值超过阈值,则点P可能为特征点,否则直接排除。接着对点P分别与P1~P16计算像素差,若至少有9个绝对值的像素差超过阈值,则点P认定为特征点,否则排除。ORB算法中采用定向FAST(oriented-FAST,oFAST)进行特征点检测。oFAST算法是在FAST的基础上通过灰度质心法为特征点添加方向。计算特征点以r为半径图像矩的质心,图像矩的定义如下:
其中,f(x,y)为像素(x,y)处的像素值,该图像矩的质心为:
特征点与质心的夹角作为特征点的方向,计算如下:
1.2 SIFT特征描述
对ORB检测出的特征点,使用SIFT为其添加方向信息,计算特征点的梯度和方向。特征点梯度大小表示为:
特征点的梯度方向表示为:
其中,L为特征点所在的尺度,(x,y)为特征点所在的位置。梯度方向为0°~360°,以每45°为1个柱,共8个柱。通过对特征点邻域梯度方向对应梯度大小进行累加,得到如图3所示的特征点梯度直方图,以峰值的方向作为特征点的主方向。

图3 特征点的梯度直方图Fig.3 Gradient histogram of feature points
上述的特征点检测只是确定特征点在图像中的位置,使用SIFT算法添加方向后需将其进一步转化为特征描述,以充分反映任意1张图像在特征点处的梯度及方向。以特征点为中心选取大小为8×8的窗口,计算每个像素的梯度大小和方向,在每4×4的子块上绘制8个方向的梯度直方图,并得到1个种子点,因此用2×2×8=32维向量对特征点进行描述,如图4所示。为了增加后续特征点匹配的鲁棒性,LOWE[10]建议特征点描述窗口大小取16×16,因此每个特征点由4×4=16个种子点组成,即对于任意1个特征点可由16×8=128维的特征向量进行描述。

图4 特征点SIFT描述符生成过程Fig.4 Signature SIFT descriptor generation process
1.3 基于BoW模型的图像特征直方图
由于每张图像能够检测到大量的特征点,而每个特征点由128维的向量进行描述,因此在对特征点进行相似度计算时,计算量十分庞大。BoW模型最初主要应用于信息检索和自然语言处理,将文本看成无序词汇的集合,通过统计文本中的词汇信息来对文本进行检索和分类[11]。目前,BoW模型已经开始在视觉领域得到应用,通过将图像特征转化为统计词频的问题,提取图像集中所有特征向量,若图像集一共有N张图像,每张图像Mi个特征,共计∑Mi,i=1,2,3,…,N。对∑Mi个特征点构建视觉词典,使用K-means聚类算法将所有图像提取的特征点分成K个分类,每个聚类中心代表1个视觉词汇,所有视觉词汇构成K词袋。通过计算图像中每个特征点与视觉词汇之间的欧式距离,决定此特征点属于哪个词汇,通过统计每个视觉词汇出现的频率,从而生成图像的直方图数据表示。对于任意1张图像均可由[1×K]的向量来进行描述,降低图像的维度,提高识别的运行效率。

表1 SVM常用核函数Tab.1 Common kernel functions of SVM
1.4 构建SVM分类器
SVM是一种基于统计学习理论的机器学习算法[12-14],在针对小样本、高维模式及非线性分类问题具有突出优势。目前,SVM已经广泛应用于图像识别、回归分析等领域,其主要思想是寻找1个超平面,使分割间隔最大化。对于给定的样本空间(xi,yi),i=1,2,3,…l。xi∈Rn,Rn为n维实数空间;yi∈{±1}。最优超平面可定义:
其中,w为垂直于超平面的向量,w∈Rn;b为截距,b∈R,R为实数空间。
若样本空间线性可分,则SVM的数学模型可表示为如下所示的凸二次规划问题,即:
其中,ξi为松弛因子,表示该样本不满足约束的程度;C为惩罚系数,表示对总误差的容忍度。
通过引入拉格朗日乘子αi,将其转化为相应的对偶问题,即:
通过求解对偶问题得到分类函数:
在实际情况中,更多的是样本空间线性不可分的情况,SVM可利用核函数将样本空间映射到更高维空间,并构建超平面完成分类:
其中,K(xi·yi)为核函数。常见的核函数如表1所示。
1.5 识别效果的评价指标
为了客观评价对工件图像识别分类的性能,选取准确率(Accuracy),精确率(Precision),召回率(Recall)和F1分数对识别模型进行评估。其中Accuracy表示识别正确的个数占总体的比例;Precision表示识别结果为正样本中的实际正样本数量占识别结果为正样本数量的比例,体现该模型对负样本的区分能力;Recall表示识别结果为正样本中的实际正样本数量占全样本中正样本数量的比例,体现该模型对正样本的识别能力;F1分数是精确率和召回率的加权平均,F1分数越高,说明模型越稳健。其计算如下式所示:
其中,TP为正确预测的正例,即数据的真实值为正例,预测值也为正例的情况;TN为正确预测的反例,即数据的真实值为反例,预测值也为反例的情况;FP为错误预测的正例,即数据的真实值为反例,但被错误预测成正例的情况;FN为错误预测的反例,即数据的真实值为正例,但被错误预测成反例的情况。
2 试验结果与分析
实验平台基于PyCharm2020,Python3.6.13及OpenCV3.4.2视觉库进行开发,操作系统为Windows10,处理器为Intel(R)Core(TM)i7-10510U CPU 2.30 GHz,RAM 16GB,使用实际生产的气门嘴图像进行验证分析。随机抽取6种型号进行试验,不同型号气门嘴的改进ORB特征如图5所示。

图5 改进ORB特征Fig.5 Improved ORB features
2.1 特征提取的鲁棒性分析
为了验证改进ORB特征提取的稳定性,在不同的环境下分别与传统的SIFT,SURF,ORB算法进行对比试验,并对不同环境下的特征进行相似度计算,即利用FLANN算法对提取的特征点进行特征匹配,匹配的准确率越高,表示提取的特征越稳定。在旋转尺度变换下的效果如图6所示,在光照变化且含有噪声下的效果如图7所示。对应的特征匹配平均正确率及时间如表2所示。

表2 特征匹配结果Tab.2 Feature matching results

图6 旋转尺度下的特征匹配Fig.6 Feature matching at rotation scale

图7 光照变化及含有噪声下的特征匹配Fig.7 Lighting variations and feature matching with noise
从图7,8的特征匹配效果图中可以看出,SIFT和SURF算法检测到的特征数量较多,但很多特征点的检测并不准确,对噪声比较敏感,并且存在大量的误匹配;而ORB算法较前2种算法,特征检测的数量明显较少,特征大多数集中在拐角处,同样存在大量特征的误匹配。从统计的匹配正确率中可以看出,改进的ORB算法相比SIFT,SURF,ORB算法分别提升48.74%,49.08%,53.10%,充分反映改进的ORB算法在特征提取方面的稳定性。
2.2 基于SVM的工件识别分析
每种型号的图像各采集100张,随机选取70%的图像作为训练集,剩下30%作为测试集。通过改进的ORB算法提取特征,使用BoW模型得到图像最终的特征向量,其中词袋数量为100。不同核函数对应不同的线性变换和特征空间,所以选择合适的核函数对SVM分类效果影响巨大[15-17]。分别构建不同核函数下的SVM分类器,其识别结果如表3所示。

表3 不同核函数下的SVM识别结果Tab.3 SVM recognition results under different kernel functions
高斯核函数下的SVM分类器识别准确率最高,为98.89%,且识别时间为0.43 s。在分类器方面,将高斯核函数下的SVM与K邻近算法、决策树、朴素贝叶斯进行对比试验,结果如表4所示。
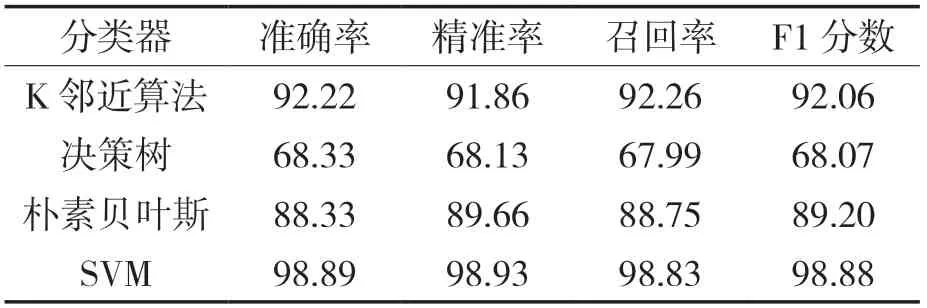
表4 不同分类器的分类结果Tab.4 Classification results of different classifiers %
在各个性能指标中,SVM均优于其他分类器。为了进一步验证改进ORB-SVM方法在工件识别分类中的有效性,分别与SIFT-SVM,SURF-SVM,ORB-SVM在Accuracy,Precision,Recall和F1分数对分类效果进行评估[18-20]。随机选取不同的训练集与测试集,分别进行20次测试,测试结果如图8所示。

图8 不同评价指标下的测试结果Fig.8 Test results under different evaluation indicators
改进ORB-SVM方法较SIFT-SVM,SURFSVM,ORB-SVM方法,在识别准确率上分别提升2.08%,6.91%,1.59%;在识别精准率上分别提升1.98%,6.71%,1.51%;在召回率上分别提升2.09%,6.95%,1.58%;在F1分数上分别提升2.11%,7.03%,1.56%。且不同评价指标均值均超过98%,验证本文方法可以有效地对工件进行识别分类。
3 结语
本文基于改进的ORB-SVM方法,针对多品种工件的识别分类问题进行研究和试验验证。首先,改进的ORB-SVM方法在旋转变换、光照变换和尺度变换等方面表现出更好的鲁棒性;通过引入SIFT算法获得旋转尺度不变性的图像特征描述,从而提高工件识别的准确性和稳定性。其次,通过BoW模型将图像特征转化为特征直方图,能够得到更高层次的特征表示,有助于区分和分类不同的工件,这种特征表示的改进提高工件识别的精确度和效率。最后,通过构建SVM的分类模型,改进ORB-SVM方法能够有效地实现工件的识别分类。试验结果表明,在识别准确率和时间效率方面,改进的ORB-SVM方法明显优于传统算法。
在多品种工件的识别分类问题上,基于改进ORB-SVM的工件图像识别方法表现出良好的性能和实用性,不仅具有较高的识别准确率,还能够快速地处理工件识别任务。因此,对于工件识别技术的发展具有重要的意义,并可为实际应用中的自动化生产、智能安防、医学图像处理和工业检测等提供有力支持和指导。
