基于生成逆推的大气湍流退化图像复原方法
2024-02-18崔浩然苗壮王家宝余沛毅王培龙
崔浩然 苗壮 王家宝 余沛毅 王培龙
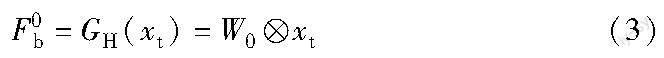
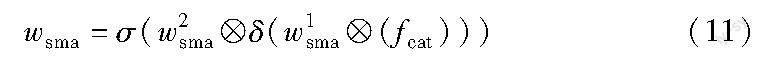

摘 要:大氣湍流是影响远距离成像质量的重要因素。虽然已有的深度学习模型能够较好地抑制大气湍流引起的图像像素几何位移与空间模糊,但是这些模型需要大量的参数和计算量。为了解决该问题,提出了一种轻量化的基于生成逆推的大气湍流退化图像复原模型,该模型包含了去模糊、去偏移和湍流再生成三个核心模块。其中,去模糊模块通过高维特征映射块、细节特征抽取块和特征补充块,抑制湍流引起的图像模糊;去偏移模块通过两层卷积,补偿湍流引起的像素位移;湍流再生成模块通过卷积等操作再次生成湍流退化图像。在去模糊模块中,设计了基于注意力的特征补充模块,该模块融合了通道注意力机制与空间混合注意力机制,能在训练过程中关注图像中的重要细节信息。在公开的Heat Chamber与自建的Helen两个数据集上,所提模型分别取得了19.94 dB、23.51 dB的峰值信噪比和0.688 2、0.752 1的结构相似性。在达到当前最佳SOTA方法性能的同时,参数量与计算量有所减少。实验结果表明,该方法对大气湍流退化图像复原有良好的效果。
关键词:大气湍流; 退化图像复原; 深度学习; 注意力机制
中图分类号:TP391 文献标志码:A 文章编号:1001-3695(2024)01-045-0282-06
doi:10.19734/j.issn.1001-3695.2023.07.0267
Restoration method for atmospheric turbulence degraded images based on generative inversion
Abstract:Atmospheric turbulence is a crucial factor that affects the quality of long-distance imaging. Though current deep learning models can effectively suppress geometric displacement and spatial blurring caused by atmospheric turbulence, such models require a large number of parameters and computational resources. To tackle this problem, this paper proposed a lightweight atmospheric turbulence degraded image restoration model based on generative inversion that entailed three core mo-dules: the DeBlur module, the remove shift module, and the turbulence regeneration module. The DeBlur module used high-dimensional feature mapping blocks, detail feature extraction blocks, and feature compensation blocks to suppress image blurring caused by turbulence. The remove shift module compensated for pixel displacement caused by turbulence using two convolutional layers. The turbulence regeneration module regenerated turbulence degraded images through convolutional operations. In the DeBlur module, it designed an attention-based feature compensation module that integrated the channel attention mechanism and the spatial mixed attention mechanism to focus on essential detail information in the image during training. The proposed model achieved peak signal-to-noise ratios of 19.94 dB and 23.51 dB, and structural similarity values of 0.688 2 and 0.752 1 on publicly available dataset Heat Chamber and self-built dataset Helen, respectively. Furthermore, it reduced the number of parameters and computational resources, compared to the current state-of-the-art (SOTA) method. The experimental results demonstrate the effectiveness of this method in restoring atmospheric turbulence degraded images.
Key words:atmospheric turbulence; degraded image restoration; deep learning; attention mechanism
0 引言
大气湍流产生的原因主要受温度与距离的影响,由于空气中气流的温度、海拔、风速、雾等因素的变化,使得大气折射率产生时空上的随机波动,该现象导致捕获的图像内容出现形变扭曲和模糊[1,2]。图像分类、目标检测、目标跟踪等计算机视觉领域的下游任务以及远距离光学成像、激光雷达成像等应用都受到大气湍流的严重困扰。相比于雾化、噪声等干扰因素,大气湍流引起的图像几何失真和空间模糊更难修复,亟待提出更高效的大气湍流退化图像复原方法。
现有针对大气湍流退化图像信息复原的方法可以分为基于光学处理的方法[3~5]和基于图像处理的方法[6~11]。基于光学处理的方法通过实时监测大气湍流的影响,利用变形镜或变焦镜对光线进行实时调整,从而补偿大气湍流对光线的扰动,并改善成像质量,但是该类方法大多需要昂贵的光学硬件设备,同时计算量大且操作复杂。现有的大部分基于图像处理的方法都是基于幸运帧的思想[7~10],通过利用拍摄获取多帧图像中受影响较小的帧(幸运帧)来抑制湍流影响。但是幸运帧在长曝光与存在运动目标的场景下出现的概率十分低,所以这些方法很难在实际中应用。比如卷积去模糊的计算方法[6,11],都假设物体和照相机处于静止的状态,但在存在物体运动应用场景中的效果不理想。现有基于图像处理的深度学习方法[12~15]针对大气湍流引起的人脸图像退化问题取得了很好的效果,但未能推广到一般的场景之中。基于Diffusion[16]和Transformer[17~19]的方法在图像复原任务中往往表现出很好的性能,但需要消耗大量的内存与计算资源。
针对以上问题,设计了一种轻量化的基于生成逆推的图像复原模型来加速处理湍流引起的图像退化问题,从湍流生成的角度出发来消除其对图像质量的影响。该模型包括去模糊模块、去偏移模块和湍流再生成模块。同时设计了基于注意力的特征补充模块,该模块融合了通道注意力机制与空间混合注意力机制,在训练过程中关注图像中重要的细节,达到更好的湍流退化图像复原效果。实验结果表明,该方法在主观的视觉感受和定性评价指标上与当前SOTA方法相比,达到了同样的性能,同时减少了参数量与计算量。
1 相关工作
1.1 大气湍流图像复原方法
光学界和计算机视觉领域在关于大气湍流退化图像复原方法上的研究已经有几十年。光学界对于大气湍流图像复原处理主要基于自适应光学元器件的补偿方法,如相干光自适应(coherent optical adaptive)[3]和基于波前时域谱(wave-front temporal spectra)[4]方法。但是此类方法大多需要昂贵的物理器件,成本很高。计算机视觉领域的传统方法大多基于幸运区域多帧成像的策略[6~11],这些方法利用每帧中被湍流影响最小的区域来融合一张干净锐利的图像,但是在长曝光的情况下,运动模糊使得幸运区域减少,这些方法就不再适用了。现阶段随着人工智能的发展,出现了许多基于深度学习方法的大气湍流退化图像复原方案。Yasarla等人[12,13]利用基于CNN的方法来重建湍流退化的图像,提出了Monte Carlo[13]的手段帮助网络训练。Lau等人[14]采用GAN的方法,设计了三个生成器分别用来去模糊、去变形、融合图像,并配有判别器来帮助重建图像。最近,Mao等人[17]提出一种基于Transformer模型的大气湍流图像复原网络架构,同时利用湍流的物理特性来训练网络,但是该模型需要大量的参数参与计算,将消耗大量计算资源。同样地,文献[15,16,18,19]中也存在计算量大,难以训练的问题。
1.2 用于图像处理的注意力
注意力机制的思想是关注神经网络训练过程中更重要的信息。Hu等人[20]最早提出SENet(squeeze-and-excitation networks),针对特征通道的关系,根据损失来学习特征权重。Woo等人[21]进一步提出了通道融合空间的注意力机制。为了提升文本序列中的交互关系,Vaswani等人[22]提出了多头注意力机制,同时该方法在计算机视觉上也有所应用。图像复原任务中,邬开俊等人[23]在UNet中的每一层编码器和解码器之间增加了改进之后的注意力机制来更好地复原大面积破损区域。Qin等人[24]设计了融合通道与像素注意力机制模块实现去雾任务。Li等人[25]基于Transfomer的架构提出条纹自注意力来实现特征全局依赖,但在Transfomer所提及的结构中,对图像进行自注意力操作时,需要大量的参数量进行计算。Chen等人[26]发现在图像复原领域,简单的通道注意力机制就可以实现Transfomer长程依赖的效果。因此本文提出了基于注意力的特征补充模块,训练时主要关注图像中重要的细节信息,对背景等低频信息赋予较小的权重。
2 基于生成逆推的大气湍流图像复原方法
2.1 湍流退化過程建模
大气湍流造成图像内容产生几何形变与模糊,在假设场景与成像传感器为静止的情况下,由大气湍流所引起的图像退化建模过程可表示为
xt=f(xc)+n(1)
f(·)=bg(2)
其中:f(·)表示湍流退化函数;n表示噪声。湍流退化函数f由像素几何位移函数g(·)和模糊卷积函数b(·)联合构成。给定一幅干净图像xc,经过函数f操作(依次经过像素几何位移函数g的操作和模糊卷积函数b的操作),再叠加噪声n,则生成大气湍流退化后的图像xt。根据上述退化建模过程可知,要想将退化后的xt还原为退化前的xc,则需要构建像素几何位移函数g(·)和模糊卷积函数b(·)的逆函数g-1(·)和b-1(·),并通过xc=g-1(b-1(xt-n))将湍流退化图像xt复原为干净图像xc。不幸的是,现实中几何位移函数g(·)和模糊卷积函数b(·)的操作虽然可以数学建模,但是逆过程的操作很显然无法实现唯一复原,因此拟采用深度卷积神经网络手段近似拟合逆函数g-1(·)和b-1(·)的过程,并基于大数据学习这一映射过程参数。
2.2 基于生成逆推的大气湍流退化图像复原模型
为了有效地抑制大气湍流在成像过程中对图像造成的退化,基于2.1节的分析,设计并提出了一种基于生成逆推的大气湍流退化图像复原模型(atmospheric turbulence degraded ima-ge restoration model based on generative inversion propagation,ATDIR)。如图1所示,该模型主要包括去模糊模块(deblur module,DBM)、去偏移模块(remove shift module,RSM)和湍流再生成模块(turbulence regeneration module,TRM)。其中,DBM模块用于近似拟合模糊卷积函数b(·)的逆操作b-1(·),RSM模块用于近似像素位几何移函数g(·)的逆操作g-1(·),TRM模块利用逆推的思想来模拟大气湍流生成的过程,辅助神经网络的学习。给定一幅湍流退化图像xt,经过DBM和RSM模块可以得到复原图像x′c,其中经过DBM模块的中间结果经过TRM模块,可以再次生成模拟湍流退化的图像x′t。通过在x′c与xc、x′t与xt之间增加监督损失,可监督模型从数据中进行参数的有效学习。
2.2.1 去模糊模块DBM
去模糊模块的目的就是让受湍流影响的图像细节更清晰,该模块采用已有的图像去模糊方法[24]进行设计,利用基于CNN的深度残差网络结构,其中局部的残差连接允许低频信息传输至深层,与经过神经网络去模糊重构的信息融合得到干净图片。不过,为了处理这种不同于一般情况下导致的模糊,本文设计了能更有效适配湍流的去模糊模块,且与后续去偏移模块联合进行湍流的抑制。如图1所示,该模块包括一个基本的高维特征映射块(high-dimensional feature mapping block,HFMB)、三组由残差模块构建的细节特征抽取块(fine-grained feature extraction block,FFEB),以及一个基于注意力的特征补充块(attention-based feature compensation block,AFCB)。给定一幅湍流退化图像xt,依次经过HFMB、FFEB和AFCB的处理,输出模糊图像补充特征Fb。
1)HFMB 如图1所示,高维特征映射模块GH仅由一个卷积层组成。给定图像xt∈RAp3×H×W,则输出高维特征F0b∈RApC×H×W,计算过程为
其中:W0∈RAp3×C×3×3为卷积操作的卷积核参数; C为特征通道数;H为图像高度;W为图像宽度。为了保持处理前后图像尺寸不变,3×3卷积核步长为1,且padding为1。
2)FFEB 如图1所示,该模块由三个具有跳接结构的基本组块构成,前一个组块的输出作为后一个组块的输入,依次计算,对应输出的特征为
Fib=GiF(Fi-1b) i=1,2,3(4)
其中:每个组块GiF又由六个类似残差块结构{gij}6j=1组成,前一个结构的输出作为后一个组块的输入,依次计算。具体地,每个结构如图2所示,给定输入特征Fi,j-1b,先经过一个卷积层和ReLU激活层,与输入特征加和后,再经过一个卷积层和一个基于注意力的特征补偿块GA,对应输出的特征Fi,jb,整个计算过程如下:
其中:Wi,j1∈RApC×C×3×3、Wi,j2∈RApC×C×3×3分别为两个卷积操作的卷积核参数;C为特征通道数;δ(·)表示ReLU激活函数;GA(·)表示AFCB模块操作过程。通过上述类似残差模块结构的跨层连接,可以使得模型直接学习退化图像的细节,降低模型参数学习训练难度。
3)AFCB 如图1所示,该模块由通道注意力(channel attention,CA)和空间混合注意力(spatial mixed attention,SMA)联合构成。
2.2.2 基于注意力的特征补充块AFCB
图3展示了AFCB模块的内部结构,该模块提高了深度残差网络的表现力和处理不同信息时的灵活性。该模块主要分为通道注意力与空间混合注意力两个步骤。
1)通道注意力计算过程 CA将每个通道特征图压缩为一个值作为通道的注意力权重,并与原通道特征图进行乘积加权。给定输入特征Fin∈RApC×H×W,首先,对特征图的每个通道执行全局均值池化操作:
其中:Fin(c,a,b)表示Fin在通道c、位置(a,b)上的值;输出fmid∈RApC×1×1为一个通道数为C的一维特征。
然后,计算权重:
其中:w1ca∈RAp3×1×1和w2ca∈RAp3×1×1为一维卷积核参数,卷积步长和padding均为1;δ(·)表示ReLU激活函數;σ(·)表示sigmoid函数;输出wca∈RApC×1×1表示为不同通道赋予不同的权重。
最后,对输入特征Fin进行元素级点乘操作,得到通道加权的输出为
2)空间混合注意力计算过程 SMA将每个空间位置上不同通道的特征值压缩为一个权重,并与原通道特征图进行乘积加权。给定输入特征Fmid∈RApC×H×W,首先,对Fmid分别在通道维执行最大值池化与平均值池化的操作:
其中:Fin(c,a,b)表示Fin在通道c、位置(a,b)上的值;输出favg∈RAp1×H×W和fmax∈RAp1×H×W为二维特征。
然后,计算权重:
其中:fcat=[favg;fmax]∈RAp2×H×W为通道级的平均值特征favg和最大值特征fmax拼接后的特征;w1sma∈RAp2×1×3×3和w2sma∈RAp1×1×3×3为二维卷积核参数,卷积步长和padding均为1;δ(·)表示ReLU激活函数;σ(·)表示sigmoid函数,输出wsma∈RAp1×H×W表示为不同空间位置赋予不同的权重。
最后,对输入特征Fmid进行元素级点乘操作,得到空间加权的输出为
2.2.3 去偏移模块RSM
RSM模块的目的是用来抑制大气湍流对图像造成的像素偏移,用卷积神经网络的手段来近似拟合像素几何位移函数的逆变换g-1(·)。如图1所示,RSM模块由两个卷积层和残差连接传输的低层图像信息组成。湍流退化图像xt经过DBM后输出模糊图像补充特征Fb∈RApC×H×W,再经过RSM模块后得到最终的干净图像xc。具体计算过程为
其中:Wr∈RApC×3×3×3为第一层卷积操作的卷积核参数;Wf∈RAp3×3×3×3为第二层卷积操作的卷积核参数;C为特征通道数;H为图像高度;W为图像宽度。为了恢复原始通道大小且保持图像尺寸不变,3×3卷积核步长为1,且padding为1。在ATDIR训练的过程中,网络通过学习不断地更新卷积参数,以矫正几何像素位移给图像带来的影响,从而达到去偏移的效果。
2.2.4 湍流再生成模块TRM
为了逆推湍流形成的过程,如图1所示,利用自监督学习的思想设计了湍流再生成模块TRM。TRM模块由通道恢复卷积和湍流抑制后的干净图像x′c组成。湍流退化图像xt经过DBM后输出模糊图像补充特征Fb∈RApC×H×W。首先,经过一层通道恢复卷积得到模拟湍流效应的特征图xfm:
接着,与经过DBM与RSM后得到的重建干净图像x′c进行像素相乘操作,再次生成模拟湍流退化的图像x′t:
最后,模拟湍流退化图像与真实场景中的湍流退化图像xt之间增加监督损失,逆推真实湍流生成的过程,辅助ATDIR的训练。
2.2.5 湍流退化图像复原模型的监督学习损失
假设输入湍流退化图像xt,其对应的无湍流图像xc,经模型输出的复原图像x′c和生成的模拟湍流退化图像x′t,则在x′t与xt、x′c与xc之间增加监督学习损失,具体损失采用平滑L1损失[27],计算过程如下:
LAp=αLApsupervised_loss+(1-α)LApself_loss(16)
其中:LApsupervised_loss=LApsmooth_L1(xc,x′c)计算的是复原的x′c与ground truth xc之间的损失,最小化该损失的目的是使湍流退化图像可以逼近真实无湍流的图像;LApself_loss=LApsmooth_L1(xt,x′t)负责计算模拟湍流退化图像x′t与真实湍流退化图像xt之间的损失,最小化该损失的目的是让模型学习到可有效逆推建模湍流生成过程。实验中,平衡两种损失的权重α设为0.9。
3 实验结果及分析
3.1 实验设置
1)数据集 在公开的Heat Chamber[17]数据集和自制的Helen[28]数据集上评估本文方法。自制的Helen数据集包含2 300张干净的人脸数据,使用文献[29]的方法来合成湍流退化后的人脸图像。Heat Chamber数据集是真实场景下拍摄的,包含200个场景的18 000张图像。该数据集通过改变温度与距离两个因素来拍摄真实的湍流退化图像。
2)参数设置 在两块NVIDIA RTX 3090 GPU上使用PyTorch 1.11.0实现ATDIR。采用Adam优化器[30]优化网络参数,其参数设置为默认值。将初始学习率设置为0.000 1,使用余弦退火策略对学习率进行调整。训练与测试时将批量大小设置为2,在合成人脸数据集上训练20代,在合成的52 700对真实场景数据集中训练50代。
3)对比方法与评估指标 将ATDIR与基于CNN的方法(TDNR[12]、MPRNet[31]、MTRNN[32]),和目前主流的基于Transformer的方法(Restormer[18]、UFormer[19]、TurbNet[17])相比较。采用图像评估中的指标峰值信噪比(peak signal-to-noise ratio,PSNR)和结构相似度(structural similarity index,SSIM)。PSNR是基于像素點之间的误差,数值越大代表失真的效果越小。SSIM是两张图像之间相似性的度量,其数值为[0,1],数值越大表示图像之间相似性越高,在此可用于反映复原后的图像与干净图像的结构相似性。
3.2 实验结果分析
为了验证本文方法的优越性,在Heat Chamber数据集上进行评估,结果如表1所示。表1展示了基于CNN与基于Transfomer的几种主流图像复原方法的PSNR与SSIM值,同时对比了不同方法之间的参数量和乘加累积操作数(multiply-accumulate operations,MACs)。
从结果可以发现,基于CNN的方法中,PSNR与SSIM指标中最优方法的MPRNet为18.68 dB与0.657 7,较TDNR分别提升了0.26 dB和0.015 3。在总参数量与GMACs的评估指标中,基于CNN的最优方法的TDNR分别消耗了0.992 M的参数量与72.91 G的计算量,较MPRNet分别减少了2.648 M与17.76 G。ATDIR与上述基于CNN的方法相比,PSNR、SSIM和GMACs指标均有所提升。ATDIR与MPRNet相比,PSNR与SSIM分别提升了1.28 dB与0.030 5,并且在总参数量与GMACs上分别减少了2.17 M与31.76 G。同时,ATDIR较参数量取得最优的TDNR,PSNR与SSIM分别提升了1.54 dB与0.045 8,MACs减少14.00 G,而总参数量仅多出了0.478 M。
在基于Transfomer的几种主流图像复原方法中,TurbNet在PSNR与SSIM指标中取得了最优效果,分别为19.94 dB与0.693 4,较其中的次优方法UFormer分别提高了0.82 dB与0.009 4,比Restormer分别提高了0.93 dB与0.007 7。Restormer在基于Transfomer的方法中消耗了最少的总参数量与MACs,分别为26.13 M与86.05 G,较UFormer分别减少了24.75 M与3.41 G,较TurbNet分别减少了0.47 M与18.91 G。
与所有方法对比中,在PSNR指标上,ATDIR取得了最好的性能19.96 dB。在SSIM指标上,ATDIR取得了次优性能,比TurbNet仅仅低了0.005 2。在总参数量上,ATDIR消耗了1.47 M的内存容量,比最优方法TDNR仅多出了0.478 M,但是在PSNR、SSIM和GMACs指标中远高于TDNR和其他基于CNN的方法。在计算量上,本文方法也取得了最优性能。虽然TurbNet在SSIM和PSNR指标中分别取得了最优与次优的效果,但是其开销所需的参数量是ATDIR的18倍,计算量是ATDIR的1.8倍。综合来看,ATDIR在湍流抑制的同时,在性能上也表现出了很好的效果。
为了验证ATDIR对图片中重要信息的恢复能力,本文对比了在PSNR上表现最优的TurbNet和ATDIR,部分结果如图4所示。其中第一行代表干净的图像,第二行代表湍流退化后的图像,第三行是TurbNet对湍流退化图像复原效果,第四行是ATDIR对湍流退化图像复原效果。由图4中方框所选部分的细节可知,在第一列飞机图片的车轮阴影处和第三列飞机的尾翼处,ATDIR明显比TurbNet有着更好的去模糊与去偏移效果。在第二列和第四列图的建筑中方框所选部分,ATDIR复原了建筑物关键细节信息。尽管TurbNet有着很好的全局图片复原效果,但是在细节处复原的图像信息并没有ATDIR多,例如在第五列图片中的风车扇叶中,ATDIR在红框中所复原的细节信息比TurbNet多(参见电子版)。
为了验证ATDIR的鲁棒性,本文在自制的Helen与Heat Chamber 数据集上进行测试。图5中给出了本文方法对湍流退化图进行复原的效果图,其中第一行代表湍流扰动后的图片,第二行表示经过ATDIR复原后的湍流退化图像。在前三列的建筑物场景中,ATDIR很好地抑制了由湍流引起的模糊与像素位移,复原的图像中突出了建筑的边缘轮廓与关键信息细节。在后三列的人脸湍流图像中,ATDIR复原了人脸中的五官特征和面部表情信息,整体提高了图片的视觉质量。ATDIR可以更准确地复原湍流模糊图像中的细节和纹理,从而使修复的图像质量更高。此外,ATDIR对于噪声和其他图像伪影也更具鲁棒性。因此,ATDIR是一种非常有潜力的图像复原方法,适用于各种湍流环境下的图像复原和相关领域的研究。
为了验证本文AFCB与TRM的作用,在自制的Helen与Heat Chamber数据集中进行了消融实验。第一个实验,ATDIR-AFCB表示在残差结构中去除AFCB模块,第二个实验,ATDIR-TRM表示去除湍流再生成模块TRM。实验结果如表2所示。
在去除这两个模块后,模型的性能均有所下降。在第一个实验ATDIR-AFCB中,在自制的Helen与Heat Chamber数据集中,PSNR分别下降了0.19 dB、0.28 dB,在SSIM上分别下降了0.003、0.006 2,这说明AFCB模块使网络聚焦图像中的重要信息更好地复原了湍流退化后的图像。在第二个实验ATDIR-TRM中,在自制的Helen与Heat Chamber数据集中,PSNR分别下降了0.1 dB、0.13 dB,在SSIM上分别下降了0.001 3、0.009 5,实验结果表明TRM对网络的训练必不可少,该模块通过模拟湍流生成来提高模型的泛化能力。
4 结束语
针对大气湍流对成像的影响,提出了一种轻量化的基于生成逆推的大气湍流退化图像复原模型。为了使模型在训练过程中更加聚焦图像中的关键信息,设计了一个基于注意力的特征补充模块。同时利用湍流再生成模块辅助训练,进一步提升了模型抑制湍流的性能。实验表明,本文方法能减轻图像的像素几何位移和空间模糊,提高了复原后图像的视觉质量。今后的工作中,希望在提升网络复原湍流退化图像性能的同时获得分辨率更高的图像。
参考文獻:
[1]徐斌,葛宝臻,吕且妮,等.基于二次二维经验模态分解去噪的湍流退化图像复原算法[J].计算机应用研究,2020,37(5):1582-1586.(Xu Bin, Ge Baozhen, Lyu Qieni, et al. Turbulence-degraded image restoration algorithm based on twice bi-dimensional empirical mode decomposition denoising[J].Application Research of Computers,2020,37(5):1582-1586.)
[2]Tatarski V I. Wave propagation in a turbulent medium[M].[S.l.]:Courier Dover Publications,2016.
[3]Pearson J E. Atmospheric turbulence compensation using coherent optical adaptive techniques[J].Applied Optics,1976,15(3):622-631.
[4]Conan J M, Rousset G, Madec P Y. Wave-front temporal spectra in high-resolution imaging through turbulence[J].Journal of the Optical Society of America A,1995,12(7):1559-1570.
[5]Diament P, Teich M C. Photodetection of low-level radiation through the turbulent atmosphere[J].Journal of the Optical Society of America A,1970,60(11):1489-1494.
[6]Metari S, Deschenes F. A new convolution kernel for atmospheric point spread function applied to computer vision[C]//Proc of the 11th International Conference on Computer Vision.Piscataway,NJ:IEEE Press,2007:1-8.
[7]Lau C P, Lai Y H, Lui L M. Restoration of atmospheric turbulence-distorted images via RPCA and quasiconformal maps[J].Inverse Problems,2019,35(7):074002.
[8]Hirsch M, Sra S, Schlkopf B, et al. Efficient filter flow for space-variant multiframe blind deconvolution[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2010:607-614.
[9]Anantrasirichai N, Achim A, Kingsbury N G, et al. Atmospheric turbulence mitigation using complex wavelet-based fusion[J].IEEE Trans on Image Processing,2013,22(6):2398-2408.
[10]Mao Z, Chimitt N, Chan S H. Image reconstruction of static and dynamic scenes through anisoplanatic turbulence[J].IEEE Trans on Computational Imaging,2020,6:1415-1428.
[11]Zhu X, Milanfar P. Removing atmospheric turbulence via space-invariant deconvolution[J].IEEE Trans on Pattern Analysis and Machine Intelligence,2012,35(1):157-170.
[12]Yasarla R, Patel V M. Learning to restore a single face image degra-ded by atmospheric turbulence using CNNs[EB/OL].(2020-07-16).https://arxiv.org/abs/2007.08404.
[13]Yasarla R, Patel V M. Learning to restore images degraded by atmospheric turbulence using uncertainty[C]//Proc of IEEE International Conference on Image Processing.Piscataway,NJ:IEEE Press,2021:1694-1698.
[14]Lau C P, Castillo C D, Chellappa R. ATFaceGAN: single face semantic aware image restoration and recognition from atmospheric turbulence[J].IEEE Trans on Biometrics,Behavior,and Identity Science,2021,3(2):240-251.
[15]劉洪瑞,李硕士,朱新山,等.风格感知和多尺度注意力的人脸图像修复[J].哈尔滨工业大学学报,2022,54(5):49-56.(Liu Hong-rui, Li Shuoshi, Zhu Xinshan, et al. Face image restoration with style perception and multi-scale attention[J].Journal of Harbin Institute of Technology,2022,54(5):49-56.)
[16]Nair N G, Mei K, Patel V M. AT-DDPM:restoring faces degraded by atmospheric turbulence using denoising diffusion probabilistic models[C]//Proc of IEEE/CVF Winter Conference on Applications of Computer Vision. Piscataway,NJ:IEEE Press,2023:3434-3443.
[17]Mao Zhiyuan, Jaiswal A, Wang Zhangyang, et al. Single frame atmospheric turbulence mitigation:a benchmark study and a new physics inspired transformer model[C]//Proc of European Conference on Computer Vision.Berlin:Springer,2022:430-446.
[18]Zamir S W, Arora A, Khan S, et al. Restormer: efficient Transfor-mer for high-resolution image restoration[C]//Proc of IEEE/CVF Confe-rence on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2022:5728-5739.
[19]Wang Zhendong, Cun Xiaodong, Bao Jianmin, et al. UFormer: a general U-shaped transformer for image restoration[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2022:17683-17693.
[20]Hu Jie, Shen Li, Albanie S. Squeeze-and-excitation networks[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Re-cognition.Piscataway,NJ:IEEE Press,2018:7132-7141.
[21]Woo S, Park J, Lee J Y, et al. CBAM: convolutional block attention module[C]//Proc of European Conference on Computer Vision.Berlin:Springer,2018:3-19.
[22]Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Proc of the 31st Conference on Neural Information Processing Systems.Red Hook,NY:Curran Associates Inc.,2017:6000-6010.
[23]鄔开俊,单宏全,梅源,等.基于注意力和卷积特征重排的图像修复[J].计算机应用研究,2023,40(2):617-622.(Wu Kaijun, Shan Hongquan, Mei Yuan, et al. Image restoration based on attention and convolution feature rearrangement[J].Application Research of Computers,2023,40(2):617-622.)
[24]Qin Xu, Wang Zhilin, Bai Yuanchao, et al. FFA-Net:feature fusion attention network for single image dehazing[C]//Proc of AAAI Conference on Artificial Intelligence.Palo Alto,CA:AAAI Press,2020:11908-11915.
[25]Li Yawei, Fan Yuchen, Xiang Xiaoyu, et al. Efficient and explicit modelling of image hierarchies for image restoration[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2023:18278-18289.
[26]Chen Liangyu, Chu Xiaojie, Zhang Xiangyu, et al. Simple baselines for image restoration[C]//Proc of the 17th European Conference on Computer Vision.Berlin:Springer,2022:17-33.
[27]Girshick R. Fast R-CNN[C]//Proc of IEEE International Conference on Computer Vision.Piscataway,NJ:IEEE Press,2015:1440-1448.
[28]Le V, Brandt J, Lin Zhe, et al. Interactive facial feature localization[C]//Proc of the 12th European Conference on Computer Vision.Berlin:Springer,2012:679-692.
[29]Mao Zhiyuan, Chimitt N, Chan S H. Accelerating atmospheric turbulence simulation via learned phase-to-space transform[C]//Proc of IEEE/CVF International Conference on Computer Vision.Piscataway,NJ:IEEE Press,2021:14759-14768.
[30]Kingma D P, Ba J. Adam: a method for stochastic optimization[EB/OL].(2017-01-30).https://arxiv.org/abs/1412.6980.
[31]Zamir S W, Arora A, Khan S, et al. Multi-stage progressive image restoration[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2021:14821-14831.
[32]Park D, Kang D U, Kim J, et al. Multi-temporal recurrent neural networks for progressive non-uniform single image deblurring with incremental temporal training[C]//Proc of the 16th European Confe-rence on Computer Vision.Berlin:Springer,2020:327-343.
[33]He Kaiming, Zhang Xiangyu, Ren Shaoqing, et al. Deep residual learning for image recognition[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2016:770-778.
