基于Petri网工作流模型展开树的路径序列相似性算法
2024-02-18许山山史涯晴简开宇魏居尚张文焘
许山山 史涯晴 简开宇 魏居尚 张文焘


摘 要:在实际的数据迁移项目中,为了解决数据映射的问题,需要确定两个工作流模型之间的相似度。从工作流模型的相似性方面进行分析阐述,提出了基于Petri网的工作流模型展开树的路径序列相似性算法。首先采用深度优先搜索算法和动态规划算法对模型进行搜索;其次通过提出的算法获取展开树的所有路径序列;最后利用编辑距离算法计算两个模型序列之间的两两相似度,进而完成模型相似性计算;相较于其他的主流相似度算法,主要优点在于可以精确计算得到模型部分结构和行为相似度,可以更好地确定流程间映射,从而找到数据映射的解决方法。实验结果表明,该方法较主流的基于模型结构和行为相似性的算法,计算合理性和准确性有很大提升。
关键词:Petri网;相似性度量;展开树;路径序列
中图分类号:TP391 文献标志码:A 文章编号:1001-3695(2024)01-025-0170-07
doi:10.19734/j.issn.1001-3695.2023.05.0193
Similarity algorithm of path sequence based on Petri net workflow model unfolding tree
Abstract:In the actual data migration project,in order to solve the problem of data mapping,it is necessary to determine the similarity between the two workflow models.This paper analyzed and expounded the similarity of workflow model,and proposed a path sequence similarity algorithm for the unfolding tree of workflow model based on Petri net.Firstly,it used the deep-first search algorithm and dynamic programming algorithm to search the model,and then obtained all path sequences of the unfolding tree by the proposed algorithm.Finally,it used the edit distance algorithm to calculate the pairwise similarity between the two model sequences,and then completed the model similarity calculation.Compared with other mainstream similarity algorithms,the main advantage is that the partial structure and behavior similarity of the model could be accurately calculated,which could better determine the mapping between processes,so as to find a solution to data mapping.The experimental results show that the proposed method is more reasonable and accurate than the mainstream algorithms based on model structure and behavior similarity.
Key words:Petri net;similarity measure;unfolding tree;path sequence
0 引言
業务流程(business process)是由不同的人或机器为实现某种有价值的目标而共同完成的一系列活动的集合。活动与活动之间的顺序存在严格的先后限定,但是可以在时间或空间上有较大跨度的转移,且活动的内容、方式、责任等都必须有明确的安排和界定,以便确保不同活动在不同岗位角色之间能够进行正常地运转与转换。简单来说,业务流程就是用于描述组织提供的服务以及实现这些服务的内部流程[1]。业务流程管理(business process management,BPM)起源于软件工程和计算机科学[2],是将信息技术和管理科学的知识结合起来,并应用于运营和改善业务流程的学科[3,4]。BPM可以被视为工作流管理(workflow management,WFM)的扩展,因为工作流管理只在乎业务流程的自动化,而BPM不仅在乎流程自动化和流程分析,而且还在乎运用管理和工作组织,考虑了人为因素和管理因素[5]。
业务流程模型,一般简称流程模型,是BPM的基础,采用大量的符号来建模操作业务流程以达到处理流程实例[6]的目的,成熟的符号工具有Petri网[7]、BPMN[8]、UML[9]和EPC[10],使用这些工具可以将业务流程的过程节点和执行方式抽象成具体的符号,可以有序构造成工作流程模型,并且还可以利用仿真软件进行模型仿真。
近年来现代企业的快速发展离不开高效而无冗余的业务流程进行支撑,业务流程是企业的重要组成部分,更是企业的宝贵知识资产。结构良好的流程模型被广泛应用于办公自动化、企业信息化、电子政务和电子商务等领域。大型集团企业常常维护着非常大的流程模型库,其中包含成千上万个流程模型,这些模型涵盖了企业架构、产品周期、工程管理、网络服务和日常办公等众多业务领域[11]。如何有效地进行流程模型的比较、索引和搜索变得具有挑战性。业务模型的相似性变得非常重要,需要合理的算法保证模型的检索[12]。因此,在计算业务流程模型的相似度时,主要方法有结构相似度、行为相似度和语义相似度[13]。
然而,现有的相似性算法存在诸多问题,主要包括共同相似性性质不足、耗时成本高、存在非自由选择等特定结构不可用等。
文献[11]中提出相似性算法至少应该满足五个属性,分别是互斥结构漂移不变性、跨度负相关性、无关递减性、循环序列长度负相关性和顺序结构漂移不变性。现有的算法,如TAR[14]、PTS[15]、行为特征[16],不能满足所有属性。
Zha等人[14]提出了一种基于变迁紧邻关系(transition adjacency relation,TAR)的行为相似性度量算法,该算法关注成对变迁的紧邻关系,即变迁a和b是顺序执行的,a和b构成的元组〈a,b〉则称为TAR,但是该算法只关注两两变迁之间的TAR,利用TAR集合的Jaccard系数来评估流程模型的相似性。然而,TAR算法的不足之处在于其不能处理诸如非自由选择和不可见任务之类的特定结构,只能满足顺序结构漂移不变性。
Wang等人[15]使用主变迁序列(principal transition sequences,PTS)概念来计算相似度,即PTS算法,主要区分三种主变迁序列,分别是非循环结构、优先循环结构和无限循环结构,以此来计算模型行为相似度。PTS算法首先计算最长的公共子序列,然后用子序列百分比的加权和表示相似度。对于具有大量分支的并发结构,PTS非常耗时,而且在具有循环的业务流程中,PTS的使用效果并不理想,因此也不满足循环序列长度负相关性。
Kunze等人[16]介绍了基于行为特征(behavioral profile)的相似度算法,行为特征算法定义了一个弱序来扩展相邻关系的语义。弱序关系包括严格顺序关系、排他关系、交错关系,在此基础上,本文提出了五种基本相似性度量,分别是排他相似性、严格顺序相似性、交错顺序相似性、扩展严格顺序相似性和扩展交错顺序相似性。行为特征算法缺点在于其不能有效地处理不可见任务,也不能区分来自并行结构和循环结构的行为模式,也不满足跨度负相关性。
以上几种流程模型相似性度量方法都有着不同程度的缺陷,或者不能完整处理各种结构,或者计算效率低下,或者相似性计算结果难以直观理解。因此,有必要提出一种新的行为相似性度量方法来解决上述问题,从而直观、准确、高效地度量任意合理流程模型间的结构和行为相似性。
本文提出一种全新的流程模型行为相似性度量方法,路径序列相似算法(path sequence similarity algorithm,PSSA),通过流程模型展开树的路径序列来表达流程模型结构和行为,进而计算两个模型间的结构和行为相似度。通过实验证明:PSSA算法能够全部满足上述五个性质,优于TAR算法、行为特征算法和PTS算法。
1 相关知识
本章对本文使用的一些基本概念进行介绍,主要是表达业务流程模型的Petri网。
在建模中,采用条件和事件的概念,库所表示条件,变迁表示事件。变迁(事件)有一定数量的前置库所和后置库所,分别表示该事件的前置条件和后置条件。一个库所的令牌的存在被解释为持有与该库所相关条件的真实性。在另一种解释中,k个令牌被放置在一个库所,以表明k个数据项或资源是可用的。变迁及其输入库所和输出库所的一些典型解释[7]如表1所示,具体实例如图1所示。
下面给出Petri网的正式定义:
定义1 Petri网。Petri网是一个五元组,N=(P,T,F,W,M0),其中:P={p1,p2,…,pm}是一组有限的库所集,T={t1,t2,…,tn}是一个有限的变迁集,F(P×T)∪(T×P)→{0,1}是一组有向弧,W:F→{0,1,2,3,…}是权重函数,M0:P→{0,1,2,3,…}是初始标记,P∩T=,P∪T=。
简单Petri网是一个三元组,可以不考虑权重函数和初始标记,Ns=(P,T,F),其中:P={p1,p2,…,pm}是一组有限的库所集,T={t1,t2,…,tn}是一个有限的变迁集,F(P×T)∪(T×P)→{0,1}是一组有向弧,本文主要是针对简单Petri网进行研究和实验。
定义2 前缀集合和后缀集合。对于N中的一个节点x的前缀集合{y∈P∪T|F(y,x)=1},用·x表示,而x的后缀集合为{y∈P∪T|F(x,y)=1},用x·表示。
如果没有任何特定初始标记的Petri网结构Nw=(P,T,F,W)记为Nw,所以具有给定初始标记的Petri网可以用(N,M0)表示。通常库所和变迁可以称为节点,而F则是节点之间的有向弧,因此,Petri网可以被认为是一个有向图,而图中的路径通常是一个非空的节点序列,没有重复,从每个节点到下一个节点都有一条弧(不考虑首尾节点)[17]。
2 Petri网展开树
2.1 Petri网展开树的定义
定义3 树Petri网。如果存在一个简单Petri网Ns=(P,T,F),在忽略库所和变迁的差异时,弧从父节点到子节点,并且根节点和叶节点都是库所,可以将其称之为树Petri网[18],如图2所示。根节点称为根库所,叶节点称为叶库所。树Petri网的逆网称为逆树Petri网。
Winskel[19]给出了Petri网“折叠”和“展开”的定义,其考虑的映射是从网络到网络的同态,这里定义的同态在文章中称为“折叠”。直观地说,从网络N1到N2的同态,即N1可以折叠到N2的一部分上,或者换句话说,可以通过展开N2的一部分来获得N1。
对于一个有根库所和叶库所的Petri网N而言,可以将其“展开”成一棵树Petri网,如图3所示,图3(b)的展开树中路径的根节点是从图3(a)中根库所开始的,树Petri网的节点被标记为与之对应Petri网的节点。然而有向Petri网可能存在环状结构[17],如图4(a)所示,因此其展开过程可以在带环处无限循环,可以产生不同的树Petri网,但是最小标记树只有唯一一棵,对于所有带环的有向Petri網只考虑在环状结构处循环一次,如图4(b)所示。这种将原Petri网通过一定形式转换得到的树Petri网称为Petri网的展开树。
2.2 展开树的路径序列
定义4 展开树的路径序列。令Nt=(P,T,F)是Petri网展开树,Σ是其所有可能执行路径序列的集合。对于任意两个任务a,b∈T(a,b可能是同一个任务),与其相关的三个触发条件x,y,z∈P(x,y,z可能是同一个条件),表示因果关系的有向弧→∈F,Σ中所有形如…x→a→y→b→z…的执行路径序列,即为树Petri网的路径序列。
示例1 展开树的路径序列。图1所示的树Petri网路径序列集S如下所示。
性质1 结构差异大的两个业务流程模型,对应展开树的路径序列差异也越大。
性质2 采用展开树路径序列能够处理业务流程模型Petri网中包含的不可见任务、非自由选择结构、循环结构及各种基本控制流结构。
2.3 Petri网展开树的性质
性质3 Petri网展开树Nt=(P,T,F),对于根库所Proot,·Proot=和p∈P{Proot},|·p|=1。如果P是叶库所,p·=,否则|p·|≥1。对于t∈T,|t·|≥1和|·t|=1。对于两个标记M0、M1,M1可从N中的M0到达当且仅当M0可从N中的M1到达N-1。
性质4 展开树是Petri网业务流程模型结构的一种表示方法,与模型节点存在一对一关系。
3 Petri网展开树的路径序列相似度算法
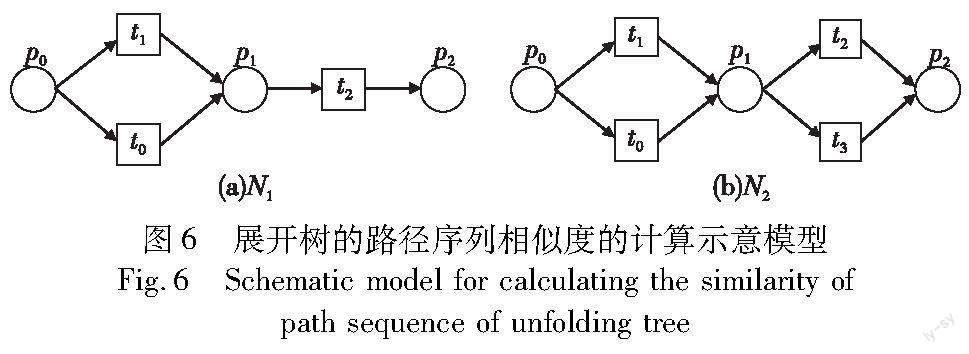
在现有的相似度算法中,并没有考虑到库所对于业务流程模型的影响,而是将变迁作为主要的研究对象,通过研究业务流程模型之间的变迁序列以及带有权重的变迁序列对,计算出彼此之间的相似度值。考虑到库所可能存在对于业务流程模型相似度的影响,提出了包含库所和变迁的展开树路径序列,通过展开树的路径序列算法获取业务流程模型的所有可能存在的路径序列,最后借助编辑距离公式对路径序列进行计算,算出两个业务流程模型之间的相似度值,下面进行详细说明。
3.1 展开树的路径序列算法
3.1.1 展開树的路径序列的算法步骤
对于无环Petri网,图3(b)展开树中路径的根库所是从图3(a)中根节点开始的,其余节点依次对应,根据展开树的路径序列算法,在图3(a)上构造一个开始变迁Ts和一个结束变迁Te,从Ts到Te开始进行顺向节点广度优先搜索,得到顺向最短路径S:Ts→p0→t0→p1→Te,从Te到Ts开始进行逆向节点广度优先搜索,得到顺向最短路径S′:Te→p1→t0→p0→Ts,得到一个复合主干路径S主:Ts→p0→t0→p1→Te,最终得到简单的残差网络G′:两条边和一个变迁t1,选取一条边E进行广度优先搜索,从起始边节点u到结束变迁Te得到一条最短路径S残:p1→Te,从结束边节点v到开始变迁Ts得到一条最短路径S′残:t1→p0→Ts,将最短路径S残、S′残和边E进行综合,得到一条完整路径S主:Ts→p0→t1→p1→Te,因此综上所述可以得到两条路径序列,分别是Ts→p0→t0→p1→Te和Ts→p0→t1→p1→Te。下面给出展开树的路径序列算法步骤过程如算法1所示。
算法1 获取展开树的路径序列
输入:Petri网G。
输出:Petri网展开树的路径序列。
a)在原网G上构造一个开始变迁Ts和一个结束变迁Te,并获取其位置;
b)从开始变迁Ts到结束变迁Te进行Petri网G的顺向节点广度优先搜索,得到顺向最短路径S;
c)从结束变迁Te到开始变迁Ts进行Petri网G的逆向节点广度优先搜索,得到逆向最短路径S′;
d)将最短路径S和S′进行综合,得到一个复合主干路径S主,从Petri网G中去除复合主干路径S主,得到一个残差网络G′,如果残差网络G′没有其他结构,则结束算法,否则继续下面步骤;
e)如果残差网络G′中仍然存在其他复杂网络结构,则重复进行步骤a)~d),直到得到最简单的顺序结构残差网络G′;
f)如在G′中选取边E节点对Petri网G进行广度优先搜索,从起始边节点u到结束变迁Te得到一条最短路径S残,从结束边节点v到开始变迁Ts得到一条最短路径S′残;
g)将最短路径S残、S′残和边E进行综合,得到一条完整路径S全;
h)重复循环步骤a)~g),直至找到所有路径。
然而对于存在环状结构的Petri网,如图4(a)所示,虽然其展开过程可以在带环处无限循环,但是在本文中,所有带环的Petri网只考虑在环状结构处循环一次,如图4(b)所示,根据展开树的路径序列算法可以得到8条路径序列,分别是
Ts→p0→t0→p2→t3→p5→t5→p0→Te
Ts→p0→t0→p2→t3→p6→t6→p1→Te
Ts→p0→t1→p3→t4→p5→t5→p0→Te
Ts→p0→t1→p3→t4→p6→t6→p1→Te
Ts→p1→t2→p4→t3→p5→t5→p0→Te
Ts→p1→t2→p4→t3→p6→t6→p1→Te
Ts→p1→t2→p4→t4→p5→t5→p0→Te
Ts→p1→t2→p4→t4→p6→t6→p1→Te
3.1.2 展开树的路径序列的算法理论证明
为了说明本文所提展开树的路径序列算法的有效性,本节从以下6个方面对其进行理论证明。
1)Petri网特点
定义5 存在一个或多个开始库所Ps,在Ps之前加入一个开始变迁Ts;存在一个或多个结束库所Pe,在Pe之后加入一个结束变迁Te,则整个Petri网业务流程图上只有一个开始变迁和一个结束变迁。
定义6 设Petri网G=(P,T,E),Petri网中存在业务流程节点V=(P,T),P为库所和T为变迁,存在P→T(或者T→P)的有向边,记为E=(P,T)(或者E=(T,P),E为有向边,则对于v∈V,存在路径Ts→Pv→Tv→P′v→Te都是可达的。
性质5 设有向边e=(m,n),e∈E,则m≠n,且m与n不能同时为库所或者变迁。
2)广度优先搜索
定义7 从Ts开始,按照广度优先搜索算法进行搜索,获得一颗广度优先生成树,Gπ=(Vπ,Eπ),设节点v∈V,则v与Ts的距离记为v.d,Ts至v的最短路径记为π(v)Gπ,v.d=length(π(v))。
定义8 从Te开始,按照边的逆方向进行广度优先搜索,获得一颗广度优先生成树,Gπi=(Vπi,Eπi),设节点v∈V,则v与Te的距离记为v.di,v至Te的最短路径记为πi(v)Gπi,v.di=length(πi(v))。
性质6 若有向边e=(m,n),e∈E,则m.d≠n.d,m.di≠n.di。
证明 若m.d=n.d,则Ts经过相同数量的边可达m和n,即m和n同为库所或变迁,与性质5矛盾;同理m.di≠n.di。
性质7 正向搜索距离Te.d,逆向搜索距离Ts.d,则Ts.di=Te.d都等于最短路径Vπ(Te)和Vπi(Ts)的长度D(常数)。
性质8 对于v∈V,则有v.d+v.di≥D。
性质9 若v.d+v.di>D,则π(v)∪πi(v)不是Ts至Te的最短路径;若π(v)∪πi(v)是Ts至Te的最短路径,则v.d+v.di=D;若v.d+v.di=D,则π(v)∪πi(v)是Ts至Te的最短路径。
证明 π(v)中v和Ts是连通的,存在e=(Ts,v),e∈E;πi(v)中v和Te是连通的,存在e=(v,Te),e∈E,则π(v)∪πi(v)中,存在变迁路径Ts→v→Te;又因为v.d+v.di=D,所以π(v)∪πi(v)是一条最短路径。
3)无环子图
定义9 设V={v|v∈V,v.d+v.di=D},E′={(m,n)|(m,n)∈E,m∈V′,n∈V′,m.d 4)動态规划算法 求得G′中Ts到业务流程节点v的所有路径π′(v)和节点v到Te的所有路径π′i(v),因此π′(Ts)=π′(Te)。每一次Ts到业务流程节点v的路径以及业务流程节点v到Te的路径会暂时存储起来,当具有重复路径时直接进行调用,大大降低了算法的时间消耗。 5)路径组合获取 定义10 设E″=E-E′,对(m,n),(m,n)∈E′,在π(m)中找到距离m最近的,∈V′,以及到m的路径(,n),在πi(n)中找到距离n最近的,∈V′,以及n到的路径(n,),获得路径(,)=→m→n→,记为π″。对(Ts,)∈π′(),(,Te)∈π′i()和(,)∈π″,构造路径Ts→→→Te,记为π。 虽然π在E″中只能保证所有的边经过一次,所有的环也只经过一次,不能保证组合是完全可能的,但是可保证G′的所有的可能组合。 6)路径遍历迭代 若对G″=(V,E″)有遍历全部可能路径的需求,可将3.2.5节中获得的π″,每一个相同的(,)构建成一个新的Petri网,继而重复前述步骤即可。 3.2 展开树的路径序列相似度算法 在相似度计算方面,存在语义相似度、行为相似度和结构相似度,由于本文在实际应用中主要针对的是业务流程的整体结构映射,主要研究的侧重点是结构相似度,为了找到最相似的路径序列,分别将两个业务流程模型的路径进行结构相似度比较,所以通过展开树的路径序列算法得到业务流程模型的Petri网路径序列。下面利用路径序列进行相似度值的计算,将这个过程称为展开树的路径序列相似度算法(path sequence similarity algorithm,PSSA)。为了比较两个模型的整体相似度,在路径两两相似度的基础之上,采用所有单条路径序列相似度求取平均值的结果作为整体相似度的一个参考值,具体如算法2所示,PSSA算法总体流程如图5所示。 算法2 业务流程模型相似度计算 输入:Petri网展开树的路径序列。 输出:业务流程相似度值。 a)利用算法2分别读取两个业务流程Petri网模型转换后的树Petri网的全部路径序列Si(i=1,2,…,n)和Sj(j=1,2,…,m); b)分别取Si中一条路径与Sj中每一条路径进行编辑距离计算得到Dij(i=1,2,…,n;j=1,2,…,m),求取路径的长度l=max(|Si|,|Sj|); 示例2 展开树的路径序列相似度的计算。计算图6中业务流程模型N1和N2的相似性。展开树的路径序列集S如下所示。 a)可以得到N1和N2的全部路径序列: b)取S(N1)中的路径序列Ts→p0→t0→p1→t2→p2→Te与S(N2)的四条路径序列进行编辑距离的计算,得到编辑距离分别为0,1,1,2;再取S(N1)中的路径序列Ts→p0→t1→p1→t2→p2→Te与S(N2)的四条路径序列进行编辑距离的计算,得到编辑距离分别为1,2,0,1;路径的长度l=max(|S(N1)|,|S(N2)|)=7; 因为路径序列是业务流程模型通过一定形式转换得到的,所以综上所述,可以等价地认为路径序列相似度值0.86即为业务流程模型N1和N2的相似度值。 4 实验设计与分析 4.1 实验环境 本文使用台式PC作为测试环境,电脑运行的是Windows 11 家庭中文版,配备了11th Gen Intel CoreTM i5-11320H @ 3.20 GHz 3.19 GHz的处理器和16 GB内存。在PyCharm中创建工程,采用Python语言实现路径序列算法以及相似性算法的功能,在此基础上,利用Tina软件构建了30个业务流程模型验证路径序列完整性,实验的具体数据和结论参看4.2.1节内容。在30个业务流程模型中抽取了部分典型的业务流程模型进行扩展用于相似度五种性质的比较实验,因为这个比较实验的模型与Wang等人[19]的相同,除了本文算法的数据是通过计算得到,其余相似性算法的对比数据均参考其文章中的数据,实验的具体数据和结论参看4.2.2节内容。 4.2 实验设计 4.2.1 路径序列完整性验证实验 利用Petri网构建30个业务流程模型,采用人工统计、普通广度优先搜索算法和展开树路径序列算法对业务流程模型的路径序列进行数量统计。利用节点和边的总数来表示业务流程模型的大小,一般而言,模型越大复杂程度越大,但是对于一些节点和边数量较多的顺序结构模型并不能反映结构的复杂度,因此需要考虑带环状结构的业务流程模型。在一些较小的业务流程模型中,带环状结构的模型利用展开树路径序列算法可以正确识别;在一些较大的业务流程模型中,展开树路径序列算法的平均识别准确率也达到了72.6%。 从图7中可以看出人工统计的路径序列数量是最多、最完整的,但是其缺点是在业务流程模型存在大量节点和边的情况下,其人工统计难度大且耗时巨大;从图中可以看出,在一些简单的模型中,主要是节点和边的数量约在20个以下时,采用普通广度优先算法可以获取完整的路径序列,在数量上几乎与人工统计数量以及路径序列算法相同,但是在處理一些复杂度较大的模型中,尤其是在节点和边的数量大量增加时,其路径序列获取能力差,根本达不到业务要求;在使用展开树路径序列算法的情况下,只要是简单的顺序结构的业务流程模型,即使存在大量的节点和边,获取的路径序列与人工统计的数量相同,在时间效率上明显要优于人工统计。随着节点和边的数量增加,人工统计将会变得难上加难,但是本文算法依然可以快速实现路径序列的统计。 4.2.2 五种属性的对比实验 在文献[11]中提到了相似性算法的五个属性。在本节中,使用这些属性对展开树PSSA算法和其他主流模型相似性算法进行对比。 属性1 互斥结构漂移不变性。如图8所示,给定导出的互斥结构的业务流程模型,无论在何处添加新的转换,新模型和旧模型的相似性都不会改变,即sim(N1,N2)=sim(N1,N3)=sim(N1,N4)。 如图8所示,假如N1中的变迁数为10个,然后在每个变迁处添加新的变迁分支,构成一种互斥结构模型,可以得到10个新的业务流程模型N2~N11。 相似度结果如图9所示,随着新添加的变迁位置的变化,相似性不会改变,因此证明了PSSA满足属性1。此外,行为特征算法和PTS也满足该属性,但是算法计算的相似度值的精度并没有PSSA高,唯一不满足属性的是TAR算法。 属性2 跨度负相关性。如图10所示,给定一个业务流程模型,随着新的互斥分支跨度的增大,新模型与旧模型的相似度逐渐减小,即sim(N1,N2)>sim(N1,N3)。假如N1中的变迁数为10个,然后在每个变迁处添加新的变迁分支,构成一种互斥结构模型,可以得到10个新的业务流程模型N2~N11。 相似度结果如图11所示,随着新添加的变迁位置的变化,相似性会呈递减状态,因此证明了PSSA满足属性2。此外,行为特征算法和PTS也满足该性质,但是随着跨度的变大,模型的相似程度肯定会越来越小,也就是说算法计算的相似度值的递减性并没有PSSA好,而TAR算法保持不变,最后还呈上升趋势,因此不满足此条属性。 属性3 无关递减性。如图12所示,给定一个业务流程模型,在原模型的同一个变迁上添加新的分支,添加的分支越多,新模型与旧模型的相似度越低,即sim(N1,N2)>sim(N1,N3)。在每个变迁处添加新的变迁分支,在变迁t2处添加一个变迁得到N2,在变迁t2处添加两个变迁得到N3,依此类推,添加10个变迁为止,可以得到10个新的业务流程模型N2~N11。 相似度结果如图13所示,随着新添加的变迁位置的变化,相似性会逐渐变小,因此证明了PSSA满足属性3。此外,TAR、行为特征算法和PTS也满足该性质。 属性4 循环序列长度负相关性。如图14所示,给定一个业务流程模型,在原模型上增加一个新的环路分支,该分支的跨度越大,新模型与旧模型的相似度逐渐减小,即sim(N1,N2)>sim(N1,N3)。 假如N1中的变迁数为10个,增加一个新的跨跃t1的环路分支,然后是t2、t3,依此类推可以得到10个新的业务流程模型N2~N12。 相似度结果如图15所示,随着新添加的变迁位置的变化,相似性会逐渐减小,因此证明了PSSA满足属性4。此外,行为特征算法满足该性质,但是TAR和PTS算法并不满足该条属性。 属性5 顺序结构漂移不变性。如图16给定了一个业务流程模型,无论在哪里插入新的变迁,新模型和旧模型的相似性都不会改变,即sim(N1,N2)=sim(N1,N3)=sim(N1,N4)。 假如N1中的变迁数为10个,然后在包括开始和结束这两个变迁的11个间隔中添加一个新的变迁,可以得到11个新的业务流程模型N2-N12。 相似度结果如图17所示,随着新添加的转换的位置变化,相似性不会改变,因此证明了PSSA满足属性5。此外,行为特征算法和PTS也满足该性质,但是算法计算的相似度值的精度并没有PSSA高,唯一不满足属性的是TAR算法。 综上所述,可以得出算法满足表2所示的结论。 4.3 实验小结 路径序列算法实现了对Petri网展开树路径序列的获取,实验中以节点和边的总数表示模型的复杂程度,在模型复杂度变高的情况下,路径序列算法在实现基本功能的同时,其性能明显优于一般的广度优先算法。在时间上面显著优于人工统计路径序列。 算法PSSA和主流的基于行为的模型相似性算法相比,在满足五个性质方面具有优势,只有PSSA能够满足全部五个性质;而在相似度计算精度方面,算法PSSA计算的相似度值要优于其他三种算法。 5 案例分析 以某航天发动机A、B两个信号处理业务流程为例具体说明Petri网模型,根据涉及的状态和产生的变化,将其相应地转换为库所和变迁;将这些库所和变迁按照Petri网的定义用有向弧进行连接,将起始点和第一个库所结合为带有起始条件令牌库所,可以形成一个与业务流程图对应的一个P/T_模型,如图18所示的是A信号处理业务流程Petri网。 利用Petri网创建工具Tina绘制如图18所示的图形,并对模型进行分析论证,如果模型正确,则可以将其导出为“.pnml”格式的文件,利用路径获取算法对“.pnml”文件进行解析,完成路径的提取,可以正确完整地获得12条路径序列,具体如表3所示。 B信号处理业务流程形成的P/T_模型,如图19所示。 可以正确完整地获得8条路径序列,具体如表4所示。 上文可知路径序列是业务流程模型通过一定形式转换得到的,利用本文的相似度计算方法可以确定两个模型的相似度,因此,可以等价地认为路径序列相似度值0.63即为信号业务流程模型A和B的相似度值。 6 结束语 本文提出了一种基于模型结构和执行语义的过程模型相似性度量算法。该算法建立在Petri网展开树的路径序列基础之上,利用展开树表示模型结构,其路径序列来表示过程模型的行为,可应用于包含循环结构的模型,并能够有效处理Petri网中的各类结构。本文通过实验衡量模型相似性算法是否满足五种相似性属性,通过实验可知该算法较其他基于行为的相似性算法计算结果更加合理且高效。最后将该模型相似性算法实际应用到具体项目中,结合相似度计算值,可以精确化确定模型的相似之处。本文方法还存在一些有待深入研究的问题:当业务流程模型十分巨大时,获取的路径序列耗时欠缺考虑,如何降低时间消耗是下一步需要考虑的问题。并且在下一步研究过程中,考虑将获取的路径序列转换为实际运用的测试用例或者作为某些问题的相似性参考,将有助于实施测试数据复用或者数据迁移等工作, 参考文献: [1]Leemans S,McGree J,Polyvyanyy A,et al.Statistical tests and association measures for business processes[J].IEEE Trans on Know-ledge and Data Engineering,2023,35(7):7497-7511. [2]Surkova E,Mazhaiskii Y.Management of business processes[J].Russian Engineering Research,2022,42(3):292-294. [3]Paolo B,Andrea D,Tommaso P.A model based framework for IoT-aware business process management.[J].Future Internet,2023,15(2):50-78. [4]Bubenik P,Capek J,Rakyta M,et al.Impact of strategy change on business process management[J].Sustainability,2022,14(17):11112-11135. [5]Lopez L,Guerrero S,Sierra E.Epistemic analysis of BPM business process management.[J].Webology,2022,19(6):321-329. [6]Schoknecht A,Thaler T,Fettke P,et al.Similarity of business process models-a state-of-the-art analysis[J].ACM Computing Surveys,2017,50(4):1-33. [7]徐穎蕾.无冲突Petri网系统活标识判定的结构化方法[J].计算机应用研究,2023,40(5):1447-1451,1458.(Xu Yinglei.A structured method for determining liveness of conflict-free Petri net systems[J].Application Research of Computers,2023,40(5):1447-1451,1458.) [8]Corradini F,Muzi C,Re B,et al.BPMN 2.0 OR-join semantics:glo-bal and local characterisation[J].Information systems,2022,105(5):101934-101957. [9]Carnevali L,German R,Santoni F,et al.Compositional analysis of hierarchical UML statecharts[J].IEEE Trans on Software Engi-neering,2022,48(12):4762-4788. [10]Van B,Dijkman R,Mendling J.Measuring similarity between business process models[J].Seminal Contributions to Information Systems Engineering,2013,5074:405-420. [11]汪抒浩,闻立杰,魏代森,等.基于任务最短跟随距离矩阵的流程模型行为相似性算法[J].计算机集成制造系统,2013,19(8):1822-1831.(Wang Shuhao,Wen Lijie,Wei Daisen,et al.Behavior similarity algorithm of process models based on task minimum following distance matrix[J].Computer Integrated Manufacturing Systems,2013,19(8):1822-1831.) [12]Rivas D F,Corchuelo D S,Figueroa C,et al.Business process model retrieval based on graph indexing method[C]//Proc of International Conference on Business Process Management.2010:238-250. [13]Saranya K G,Sadasivam G S.Modified heuristic similarity measure for personalization using collaborative filtering technique[J].Applied Mathematics & Information Sciences,2017,11(1):307-315. [14]Zha Haiping,Wang Jianmin,Wen Lijie,et al.A workflow net similarity measure based on transition adjacency relations[J].Computers in Industry,2010,61(5):463-471. [15]Wang Jianmin,He Tengfei,Wen Lijie,et al.A behavioral similarity measure between labeled Petri nets based on principal transition sequences(short paper)[C]//Proc of OTM Confederated International Conferences on the Move to Meaningful Internet Systems.2010:394-401. [16]Kunze M,Weidlich M,Weske M.Behavioral similarity-a proper metric[C]//Proc of Business Process Management International Confe-rence.Berlin:Springer,2011:166-181. [17]Esparza J,Rmer S,Vogler W.An improvement of McMillans unfolding algorithm[R].[S.l.]:Technische Universitat Munchen,1996:285-310. [18]Cui Huanqing.Tree Petri nets:properties and applications in logical problems[C]//Proc of the 2nd WRI Global Congress on Intelligent Systems.Piscataway,NJ:IEEE Press,2011. [19]Wang Shuhao,Yin Ming,Wang Zixuan,et al.TAR+:a new process model similarity algorithm based on the importance of TARs[J].Asia Pacific Business Process Management,2015,219:98-112. [20]Winskel G.Event structures[M].Berlin:Springer,1987.
