结合模糊控制的深度强化学习交通灯控制策略
2024-02-18秦侨杨超杨海涛黄旭民张斌杨海森
秦侨 杨超 杨海涛 黄旭民 张斌 杨海森
摘 要:现有交通信号灯控制策略大多针对单一交叉口展开分析,该策略仅考虑车流量的单一因素,难以适应动态的路网状态。对此,提出了一种结合模糊控制的深度强化学习交通灯控制策略,利用SAC(soft actor critic)深度强化学习对两交叉口的交通信号灯相位选择及配时进行联合优化,同时考虑车辆速度、路段车辆排隊长度等因素,利用模糊控制对SAC的惩罚函数进行处理。实验结果表明,与固定循环周期策略、SAC控制策略和DDPG(deep deterministic policy gradient)控制策略相比,提出的交通信号灯控制策略能获得更快的车辆通行速度,车辆的油耗和尾气排放情况也得到了改善。
关键词:智能交通;交通信号灯控制;深度强化学习;模糊控制;VISSIM
中图分类号:TP273.1 文献标志码:A 文章编号:1001-3695(2024)01-024-0165-05
doi:10.19734/j.issn.1001-3695.2023.04.0187
Deep reinforcement learning traffic light control strategy combined with fuzzy control
Abstract:Most of the existing traffic light control strategies consider a single factor such as traffic flow,which is difficult to adapt to the dynamic states of the road networks.In order to solve this problem,this paper proposed a deep reinforcement lear-ning traffic light control strategy combined with fuzzy control,used SAC deep reinforcement learning to jointly optimize the phase selection and timing of traffic lights at two intersections,while considering multiple influencing factors,used fuzzy control to process the penalty function of SAC.The experimental results demonstrate that compared with the fixed cycle strategy,SAC control strategy and DDPG control strategy,the proposed traffic signal control strategy can obtain faster vehicle speed,and the fuel consumption and exhaust emissions of the vehicle are also improved.
Key words:intelligent transportation;traffic signal control;deep reinforcement learning;fuzzy control;VISSIM
0 引言
高效的交通系统是提升社会经济竞争力和环境可持续发展的关键基础设施。对城市道路交叉路口的交通灯进行有效的控制,可以提升路段的通行效率,减少道路交通拥堵。在交叉口,路面交通流实时变化,路面车辆的到达具备不确定性。当前,大部分交叉路口的交通信号灯仍然采用传统的单段或多段定时固定循环周期控制,导致延误和高昂的通勤成本[1,2]。同时,交通灯设置不当导致的交通拥堵会增加碳排放,对环境和社会造成不良影响[3]。
随着5G通信网络技术的快速发展,车与车(vehicle-to-vehicle,V2V)、车与路侧设施(vehicle-to-infrastructure,V2I)之间的数据传输速率加快[4,5]。依托交通物联网技术,智能交通系统可以设计一类交通信号灯自适应控制策略,其能够及时感知复杂路网的交通状态变化,选择最优相位动作和配时。然而,已有的部分交通灯自适应控制策略对动态变化的路网状况难以在线进行调整,特别是面对多交叉路口的交通信号灯联合控制场景效果不佳。基于强化学习(reinforcement learning,RL)的交通信号控制策略根据长期观察的离线数据对交叉路口进行建模[6],同时根据策略的实测效果和路面的交通流在线调整交叉路口信号灯的控制策略,取得了较好的效果。文献[3]提出基于深度Q-learning的单路口交通灯配时控制策略。文献[4]设计了一类利用深度增强学习的交通信号灯配时和相位优化策略,然而其惩罚函数只考虑了车流量这一单一因素。文献[7]利用Q-learning同时对路口的交通灯相位和配时进行优化。文献[8] 通过LSTM循环神经网络预测未来的交通信息,并使用DDPG深度强化学习模型进行决策。文献[9]构建了新的基于相邻采样时间步实时车辆数变化量的奖励函数,明显提高了交叉口通行效率。文献[10]基于改进Webster方法,设计一类高效的单交叉路口交通信号灯配时策略。文献[11]将雾计算和强化学习理论相结合,提出了一种FRTL交通灯控制模型,有效地调控了红绿灯时间,达到了缓解交通拥堵的目的。文献[12]设计了一种基于模糊控制的交通信号灯控制策略。然而,上述工作是针对局部区域单个交叉口路网系统展开研究,没有对大范围内多交叉路口联合交通灯控制进行分析。文献[13]针对多交叉口的红绿灯相位控制,提出了一种基于多智能体的TR-light模型,有效地改善了多交叉口的交通状况。文献[14]在基于多智能体强化学习的基础上,利用图卷积网络构建了一个参数共享的NCCLight模型,实现了交叉口之间的信息交换,有效地提高了模型的性能。然而,上述方法没有全面考虑影响控制决策的多方面因素,缺乏针对惩罚函数的优化设计。
强化学习中,惩罚函数的设计决定着系统的学习性能,而交通信号灯控制决策受到多方面因素的影响,具体包括车流量、行车时间、碳排放等,因此如何在惩罚函数中平衡各个因素动态变化情况,是提升控制策略效率的关键。为了更精确地描述各个因素对控制决策的影响,提高系统的鲁棒性,本文基于SAC(soft actor critic) [15]深度强化学习方法,将模糊控制引入构建惩罚函数。针对两交叉口路网场景交通信号灯管理需求,提出了一种基于改进SAC深度强化学习的交通信号灯控制策略。具体地,利用模糊函数对各个路口的车辆速度、排队车辆数量等因素进行处理,改写SAC的惩罚函数,并基于此重点对两交叉路口交通信号灯8相位选择及配时进行联合优化。除去传统的路口通行时间和交通流量外,通过车辆的碳排放和油耗,本文对信号灯交叉口进行建模仿真分析,以验证本文所提优化策略的有效性。
1 系统模型
1.1 交通信号灯控制模型
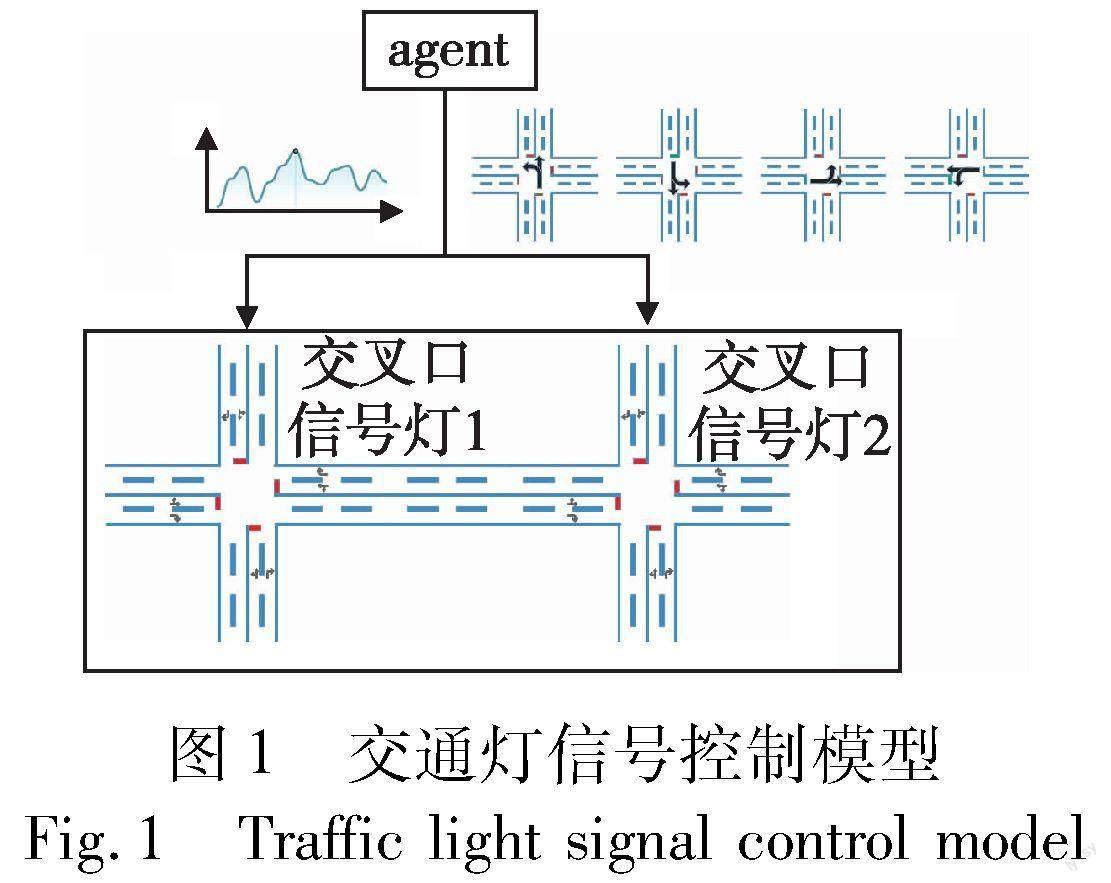
基于SAC的两交叉路口交通信号灯控制模型如图1所示。智能交通系统决策中心使用结合模糊逻辑的SAC深度RL方法对agent进行训练,环境为两交叉口道路,状态表示为所有车辆的位置和速度。动作状态空间包括两个交叉路口交通灯8个相位及配时量。在固定周期T内,对于每一个交叉口信号灯,agent能够根据环境状态,自适应地从动作空间中选择一个最优动作作为决策,从而提高所有车辆的整体行驶速度,减少行程时间及碳排放量。
本文使用VISSIM对两交叉路口的路网状况进行建模。在优化目标函数方面,除了传统的车流量和车速外,本文还采用了车辆的碳排放和油耗进行建模,具体模型如下所述。
1.2 尾气排放与油耗模型
车辆的尾气排放与车瞬时速度、加减速度密切相关[16]。常规地,可以使用比功率法确定车辆的尾气排放量。本文的研究对象为城市路网交叉路口,VSP(vehicle specific power)[16,17]计算如式(1)所示。
VSP=v(1.1a+0.132)+0.000302v3(1)
其中:v、a分别为车辆的速度、加/减速度。在获得车辆的VSP后,可以采用碳平衡法确定车辆的油耗和各类排放的平均值[18],包括CO2、CO、HC、NOx。具体地,可以对车辆的VSP划分区间,然后确定不同区间内的油耗。采用碳平衡法计算车辆在不同VSP区间下的油耗率,如式(2)[19]所示。
其中:ERFC表示油耗率;ERCO2、ERCO、ERHC分別表示CO2、CO、HC的排放率;C%=86.6%,表示燃油的碳含量比重。
下面给出一个简单案例,车辆的发动机排量小于3.5 L、行驶里程大于50 km,计算此类车辆在不同
VSP区间的油耗率平均值和CO2、CO、HC、NOx的排放率平均值(g·s-1)如表1所示,其中,ERNOx表示NOx的排放率平均值。
2 基于改进SAC的控制策略
强化学习主要由智能体(agent)、环境(environment)、状态(state)、动作(action)、奖励(reward)组成。环境定义为马尔可夫决策过程(MDPs),智能体与环境进行交互,通过奖励值rt评估判断作出的动作,使得奖励的加权和最大化。目前主流的RL算法分为基于价值的方法(value-based)和基于策略的方法(policy-based)两大类。
2.1 SAC算法
SAC算法由四个critic网络与一个actor网络组成,前者用于预测状态-动作元组的Q值,后者用于预测动作概率分布参数。相较传统的Actor-Critic算法,SAC算法的特点是引入了最大熵模型(maximum entropy model),能在获得足够多收益的同时,对未知状态空间进行合理探索,学到更多近优策略,同时加快训练速度。在SAC中,目标函数同时包含了reward和策略熵,如下:
其中:π*表示最优策略;α为温度系数,用于控制目标函数关注最大熵的程度;r(st,at)表示状态st下执行动作at获得的收益;E(st,at)~ρπ表示服从策略π时,未来总收益的期望。
图2表示两交叉口的智能体-环境交互图,通过对环境的状态进行采样,获得t时刻的状态值st,作为策略网络的输入,同时得到该时刻动作的概率分布π(st)。为保证在离散动作空间下进行梯度下降,SAC算法经过重参数化(reparameterization)对动作的概率分布进行采样,得到具体动作at。将得到的状态-动作元组(st,at)作为Q网络的输入,得到状态-动作价值Q(st,at),同时为了降低Q值的过度估计,使用了两个Q网络进行预测,选择其较小的值执行优化策略。
2.2 状态空间
本文定义的状态空间包括当前所有车辆的位置及速度。在传统的RL训练过程中,对于一个状态可视化环境,由于当前帧画面包含所需的各种状态元素,通常将经过压缩后的当前帧画面图像用于状态输入[20]。本文使用VISSIM构建的路网画面图像中,车辆所占像素点较小,很难表现车辆的位置变化,这会使得状态描述不精确。因此,本文将VISSIM路网的整体画面图像离散化为一个84×84的二维向量,即在交叉口的每一条道路上,进入的车辆在这7 056个单元中被离散化,以识别其中是否有车辆,最终得到一个84×84的二维向量,使得agent能够获得车辆的位置信息[21]。车辆的速度可通过VISSIM接口获取,状态的速度定义为路网中所有车辆的平均速度。
2.3 动作空间
为保证仿真符合真实交通状况,所有可用的相位选择仅由兼容的车流组成。本文研究的仿真环境为两交叉口,对于任意一个交叉口,动作空间由相位选择和相位配时两部分组成,相位选择为离散空间{0,1,2,3},如图3所示,相位配时为连续空间,为[3 s~10 s]中的连续值。如果任意一个交叉口信号灯的相位发生改变,则交通灯必须经过一个固定时间3 s的全红灯相位,以符合交通法规。
2.4 结合模糊逻辑的奖励函数改进
环境提供的奖惩值是对控制决策效果的评价,通过环境的奖惩反馈指导agent的学习过程,奖惩值定义了agent努力实现的目标,会对下一次控制决策的选择产生影响。传统的RL方法建立单一的显式数学模型来描述奖励函数。文献[3]将当前时间步骤与前一步骤中所有车辆等待时间作为奖励函数;文献[4]考虑了平均速度、平均流量(即移动的车辆总数的百分比)、二氧化碳排放量等参数,并进行权重相加形成奖励函数。在交通信号灯控制中,影响控制效果的优劣因素是多方面的,此外,各类因素之间关系较为复杂,一般属于非线性关系。为了更好地建立准确的非线性系统模型,同时最大化多影响因素下所选动作的效果,本文通过专家知识建立模糊规则,并利用模糊逻辑构建奖惩反馈信号。奖励值reward产生器共有两个输入,为路网当前所有车辆的平均速度Av和路网当前车辆排队长度Lq。输入与输出的论域根据具体仿真环境确定,在本文中,Av的取值为17~35,Lq的取值为0~60,reward取值为0~30。模糊集根据输入值由小至大分成NB、NM、NS、Z、PS、PM、PB七部分,三种变量的隶属度函数均采用三角形隶属度函数,如式(4)所示。以Av为例,最终得到输入与输出的隶属度函数曲线,如图4所示,模糊规则一共49条,反模糊化方法为质心法(centroid)。
其中:x表示输入值;a、c分别表示该部分模糊集有效输入的最大值与最小值;b表示函数输出峰值时的输入。
3 仿真分析
3.1 交通仿真环境
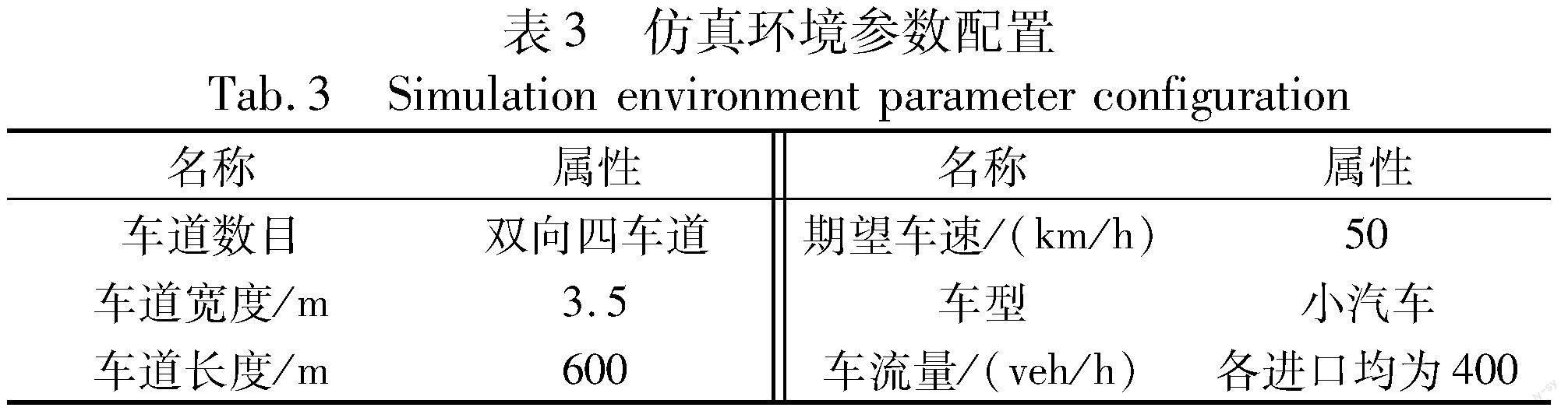
本文使用VISSIM软件进行仿真平台搭建,并利用该软件交通控制COM接口,通过Python实时获取交通流数据及修改交通控制状态。本文使用的VISSIM跟驰模型为改进版Wiedemann 74模型,主要适用于城市内部道路交通。所用参数如表2所示。在VISSIM中建立的两交叉口运行路网界面如图5所示,仿真环境参数配置如表3所示。
3.2 结合模糊逻辑的SAC算法收敛分析
3.2.1 训练网络参数设置
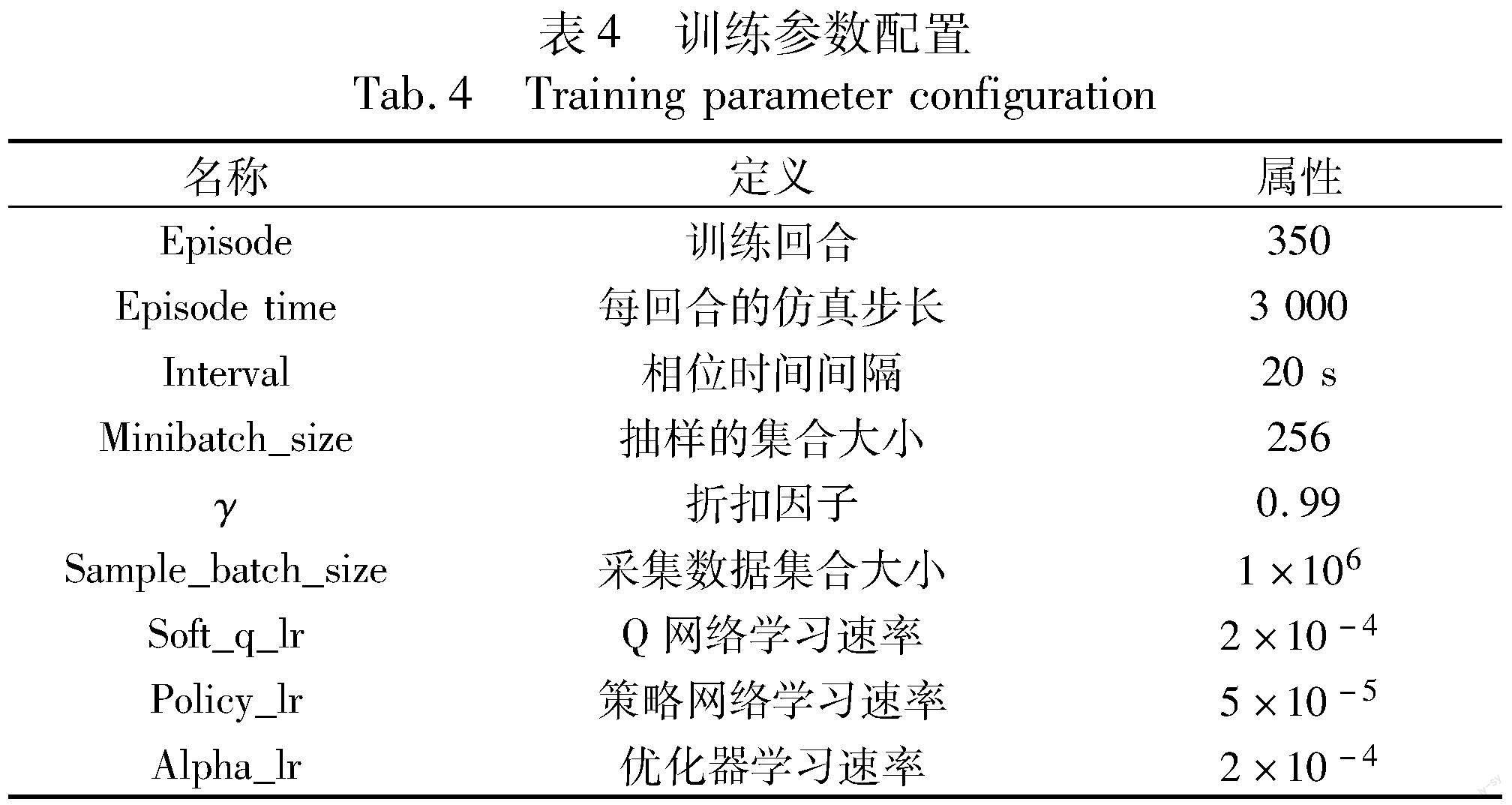
结合模糊逻辑SAC算法的两交叉口信号优化控制模型的训练参数配置如表4所示。所有的网络都使用Adam优化器进行训练。critic网络使用固定的学习速率,actor网络学习速率随着epoch的增加而变化,以加快收敛速度。为了得到更好的梯度参数并使模型学习稳定,本文使用n步Bootstrapping方法(n=5)来训练critic網络。
3.2.2 训练结果
图6表示结合模糊逻辑的SAC算法的收敛效果图。由图6可以看出,在训练前期,由于神经网络的初始参数为随机化参数,得到的reward较小。随着episode的增加,agent通过与环境进行交互获得经验,即由当前状态、当前动作、reward、动作后的下一状态组成的(st,at,rt,st-1)四元组,最后通过经验回放机制(experience replay)更新网络参数,以时序差分值(TD-error)由大到小排名的倒数作为优先级指标。为了减小引入优先级后产生的采用数据的分布偏差,采取了重要性采样方法(importance sampling)进行纠错。训练中期,由于SAC算法加入了最大化熵以鼓励agent探索,所以reward偶尔会下降,最终趋于稳定。
3.3 交通信号灯控制策略性能比较
为了验证结合模糊控制的SAC深度强化学习(SAC-FL)交通灯控制策略的合理性和有效性,以及在恶劣交通环境下的适应能力,本文设计了不同车流量和车流突然涌入两种不同的仿真场景对所提方法进行测试。设置了三个对照实验策略:
a)固定循环策略(FIX):交通灯的相位和配时是固定周期的,本文中设置周期为120 s。
b)传统DDPG深度强化学习控制策略(DDPG)[8]:未使用结合模糊逻辑的奖励函数,采用传统的多元素线性加权奖励函数。交通灯配时控制采用DDPG算法,交通灯相位控制是离散动作空间,因此采用DQN算法。
c)传统SAC深度强化学习控制策略(SAC):未使用结合模糊逻辑的奖励函数,采用传统的多元素线性加权奖励函数。
3.3.1 不同车流量下
图7~9表示各个交叉路口进口车道的车流量在200~600 veh/h时,四种控制策略的效果,进行比较的性能指标分别为车辆平均速度、平均排队车辆数、车辆平均行程时间。如图所示,在车流量较低时,四种策略效果并没有太大差距。但在中高车流量时,本文提出的改进SAC强化学习策略相较于另外三种策略,均有较好的效果,性能提升结果如表5所示。其主要原因是改进的RL控制策略通过对经验的学习后,能够利用模糊控制对奖励函数值进行改进,有助于作出增加reward的下一决策动作,从而提高整体系统内车辆的速度和减少排队车辆数。
基于第1章对车辆的排放和油耗的建模,结合仿真所获取的数据,本文研究分析四种控制策略对两交叉路口通行车辆节能减排效果的影响[22]。由于控制效果更好,可能会导致车辆的到达率增加,进而使得油耗和尾气排放量增加,会造成得到的总油耗和排放量不准确。所以本文采用车辆油耗比RC和车辆尾气排放比RE作为比较依据。
ERFC表示油耗率,ERCO2、ERCO、ERHC分别CO2、CO、HC的排放率。
3.3.2 车流突然涌入
为了测试交通灯控制策略(SAC-FL)的鲁棒性,本文对四种控制策略在车流突然涌入的情况下,车流平均速度恢复到稳定状态的效果进行了比较。图10所示为四种控制策略下应对车流突然涌入时的车辆平均速度比较结果。在第1 100仿真秒时各进车道车流量增加为500 veh/h,第1 700仿真秒时恢复车流量至300 veh/h,即图中红色区域(参见电子版)所示。由图可以看出,在应对车流突然涌入的状况时,基于RL的三种控制策略相较于固定配时策略,都能够较快地恢复到稳定的车辆平均速度。
4 结束语
在城市路网中,对交叉路口的交通灯进行有效管理,可以有效地提升交叉路口的车辆通行效率。本文提出了一种结合模糊逻辑的SAC深度强化学习两交叉口交通灯控制策略,对交通灯的相位和配时进行联合优化,并利用模糊函数对SAC的奖励函数进行处理。最后,在VISSIM仿真平台上对不同交通需求的状况进行了仿真分析。实验结果表明,SAC-FL与FIX、DDPG及传统SAC相比,能够显著地减少交叉口的拥堵状况,同时减少油耗及废气的排放量,并且在应对突然涌入的车流时也具备良好的鲁棒性。今后的研究工作拟从以下两方面展开:考虑更复杂的交通路网,将模糊控制引入多智能体RL方法以更好地解决复杂路网问题;为更符合现实的交通车流组成,考虑对电动汽车展开研究,将电动汽车加入车流组成,并建立数学模型等。
参考文献:
[1]张立立,王力,张玲玉.城市道路交通控制概述与展望[J].科学技术与工程,2020,20(16):6322-6329.(Zhang Lili,Wang Li,Zhang Lingyu.Urban road traffic control overview and prospect[J].Science Technology and Engineering,2020,20(16):6322-6329.)
[2]Liu Hao,Carlos E F,John S,et al.Field assessment of intersection performance enhanced by traffic signal optimization and vehicle trajectory planning[J].IEEE Trans on Intelligent Transportation Systems,2022,23(8):11549-11561.
[3]赵纯,董小明.基于深度Q-Learning的信号灯配时优化研究[J].计算机技术与发展,2021,31(8):198-203.(Zhao Chun,Dong Xiaoming.Research on signal timing optimization based on deep Q-learning[J].Computer Technology and Development,2021,31(8):198-203.)
[4]Busch J V S,Latzko V,Reisslein M,et al.Optimised traffic light ma-nagement through reinforcement learning:traffic state agnostic agent vs.holistic agent with current V2I traffic state knowledge[J].IEEE Open Journal of Intelligent Transportation Systems,2020,1:201-216.
[5]余辰,张丽娟,金海.大数据驱动的智能交通系统研究进展与趋势[J].物联网学报,2018,2(1):56-63.(Yu Chen,Zhang Lijuan,Jin Hai.Research progress and trend of big data-driven intelligent transportation system[J].Chinese Journal on Internet of Things,2018,2(1):56-63.)
[6]徐东伟,周磊,王达,等.基于深度强化学习的城市交通信号控制综述[J].交通运输工程与信息学报,2022,20(1):15-30.(Xu Dongwei,Zhou Lei,Wang Da,et al.Overview of reinforcement lear-ning-based urban traffic signal control[J].Journal of Transportation Engineering and Information,2022,20(1):15-30.)
[7]Liu Junxiu,Qin Sheng,Luo Yuling,et al.Intelligent traffic light control by exploring strategies in an optimised space of deep Q-learning[J].IEEE Trans on Vehicular Technology,2022,71(6):5960-5970.
[8]陈树德,彭佳汉,高旭,等.基于深度强化学习的交通信号灯控制[J].现代计算机,2020(3):34-38.(Chen Shude,Peng Jiahan,Gao Xu,et al.Traffic signal control based on deep reinforcement learning[J].Modern Computer,2020(3):34-38.)
[9]劉智敏,叶宝林,朱耀东,等.基于深度强化学习的交通信号控制方法[J].浙江大学学报:工学版,2022,56(6):1249-1256.(Liu Zhimin,Ye Baolin,Zhu Yaodong,et al.Traffic signal control method based on deep reinforcement learning[J].Journal of Zhejiang University :Engineering Science,2022,56(6):1249-1256.)
[10]马琳,陈复扬,姜斌.交通物联网中基于改进Webster方法的单点信号配时研究[J].物联网学报,2018,2(4):49-55.(Ma Lin,Chen Fuyang,Jiang Bin.Research on timing method for single intersection in transportation Internet of Things based on improved Webster algorithm[J].Chinese Journal on Internet of Things,2018,2(4):49-55.)
[11]安萌萌,樊秀梅,蔡含宇.基于雾计算和强化学习的交通灯智能协同控制研究[J].计算机应用研究,2020,37(2):465-469.(An Mengmeng,Fan Xiumei,Cai Hanyu.Research on intelligent coordinated control of traffic light based on fog computing and reinforcement learning[J].Application Research of Computers,2020,37(2):465-469.)
[12]刘佳佳,左兴权.交叉口交通信号灯的模糊控制及优化研究[J].系统仿真学报,2020,32(12):2401-2408.(Liu Jiajia,Zuo Xingquan.Research on fuzzy control and optimization of traffic lights at single intersection[J].Journal of System Simulation,2020,32(12):2401-2408.)
[13]吴昊昇,郑皎凌,王茂帆.TR-light:基于多信号灯强化学习的交通组织方案优化算法[J].计算机应用研究,2022,39(2):504-509,514.(Wu Haosheng,Zhen Jiaoling,Wang Maofan.TR-light traffic organization plan optimization algorithm based on multiple traffic signal lights reinforcement learning[J].Application Research of Computers,2022,39(2):504-509,514.)
[14]Kong Yang,Cong Shan.NCCLight:neighborhood cognitive consistency for traffic signal control[J].Sensors and Materials,2022,34(2):545-562.
[15]Haarnoja T,Zhou A,Abbeel P,et al.Soft actor-critic:off-policy maximum entropy deep reinforcement learning with a stochastic actor[C]//Proc of International Conference on Machine Learning.New York:PMLR Press,2018:1861-1870.
[16]Tang Tieqiao,Zhi Yanyi,Qing Fenglin.Effects of signal light on the fuel consumption and emissions under car-following model[J].Physica A:Statistical Mechanics and Its Applications,2017,469:200-205.
[17]Abou-Senna H,Radwan E,Westerlund K,et al.Using a traffic simulation model(VISSIM) with an emissions model(moves) to predict emissions from vehicles on a limited-access highway[J].Journal of the Air & Waste Management Association,2013,63(7):819-831.
[18]Song Guohua,Yu Lei,Wang Ziqianli.Aggregate fuel consumption model of light-duty vehicles for evaluating effectiveness of traffic management strategies on fuel[J].Journal of Transportation Engineering,2009,135(9):611-618.
[19]Frey H C,Unal A,Chen J,et al.Methodology for developing modal emission rates for EPAs multi-scale motor vehicle & equipment emission system[R].Ann Arbor,Michigan:US Environmental Protection Agency,2002:13.
[20]Wan C H,Hang M C.Value-based deep reinforcement learning for adaptive isolated intersection signal control[J].IET Intelligent Transport Systems,2018,12(9):1005-1010.
[21]Mousavi S S,Schukat M,Howley E.Traffic light control using deep policy-gradient and value function based reinforcement learning[J].IET Intelligent Transport Systems,2017,11(7):417-423.
[22]劉皓冰,熊英格,高锐,等.基于微观仿真的交叉口车辆能耗与排放研究[J].城市交通,2010,8(2):75-79,24.(Liu Haobing,Xiong Yingge,Gao Rui,et al.Investigating vehicular energy consumption and emissions at intersections with micro-simulation models[J].Urban Transport of China,2010,8(2):75-79,24.)
