基于图注意力网络的小样本知识图谱补全
2024-01-26闵雪洁王艳娜周子力董兆安
闵雪洁, 王艳娜, 周子力, 王 妍, 董兆安
(①曲阜师范大学网络空间安全学院,273165,曲阜市;②曲阜师范大学计算机学院,276826,山东省日照市)
0 引 言
一些大规模知识图谱如Freebase[1],Wikidata[2]等,将每一条信息表示为三元组形式(h,r,t),这种结构化知识是问答系统、推荐系统和信息检索等众多下游人工智能应用中至关重要的一部分.
尽管大规模知识图谱包含了大量的事实,但仍然存在不完整的问题,需要对知识图谱进行补全. 在知识图谱补全任务中,人们提出了各种嵌入模型,将知识图谱中实体和关系的表示嵌入到低维向量空间中,例如TransE[3]、ComplEX[4]等. 近年来,深度神经网络也在这些嵌入模型中广泛应用. 例如,ConvE[5]利用卷积神经网络对嵌入模型进行进一步改进. 尽管这些嵌入模型在学习实体和关系的嵌入表示中表现出了很强的性能,但它们通常需要为每个关系提供大量的三元组作为训练数据. 然而,在现实世界中,知识图谱存在着长尾关系,也就是说,很大一部分关系只有很少的训练实例. 对于稀疏的长尾关系,由于缺乏足够的训练三元组,知识图谱嵌入模型的性能受到极大限制.
近年来,针对小样本知识图谱补全(few-shot knowledge graph completion,FKGC)[6]的问题引起了广泛的研究. 小样本知识图谱补全是仅根据给出目标关系的几个参考实体对来预测补全三元组中缺失的部分. 为了更好地引用参考实体对的语义表示,提出了许多针对小样本学习任务的方法. 这些方法尽管在小样本知识图谱补全任务上做出了重大贡献,但仍存在许多问题. 近年来,图神经网络(graph neural network,GNN)在自然语言处理任务上应用广泛,在小样本学习任务上也发挥了优越的性能,但是,使用R-GCN[7]来编码局部图结构通常是将目标实体的邻居贡献进行平均,限制了模型的性能. 而图注意力网络(graph attention network,GAT)[7]在编码每个实体的局部图结构时采用注意力机制,根据邻居节点的重要性决定其是否应占有较高权重,从而生成更准确的实体表示. 因此,本文利用图注意力网络(GAT)来解决小样本知识图谱补全任务中编码局部邻域邻居权重相同的问题.
本文采用基于匹配度量[8]的框架,提出通过解决邻居实体权重相同问题的图注意力网络,建模局部邻域的上下文信息. 在NELL-one和FB15k237-one 2个数据集上验证了图注意力网络在小样本知识图谱补全任务上的有效性. 实验结果表明,图注意力网络可以提高小样本知识图谱补全任务的性能.
1 相关工作
1.1 知识图谱补全
由于知识图谱是不完整的,知识图谱中可能缺少部分实体和关系. 知识图谱补全任务的目的是为了使知识图谱包含更多的知识,以提高下游任务的准确性. 根据知识图谱不完整三元组中缺失的部分,可以分为3种任务:头、尾实体预测和关系预测,其形式分别表示为(?,r,t)、(h,?,t)和(h,r,?). 根据三元组中实体和关系是否从外界知识中抽取得到,知识图谱补全可以分为2类:(1)静态知识图谱补全(static knowledge graph completion),其作用是不涉及外界知识,仅补全包含在知识图谱G中不完整的三元组;(2)动态知识图谱补全(dynamic knowledge graph completion),其作用是从外界中抽取知识补全到知识图谱G的不完整三元组中,从而扩大知识图谱的三元组集,提高知识图谱的完整性[9].
1.2 小样本知识图谱补全
小样本知识图谱补全学习的目的是在仅参考很少的训练实例的情况下获得可观的补全性能. 小样本知识图谱补全示例如图1所示. 一般来说,小样本知识图谱补全学习方法可以分为2类:基于匹配度量的方法和基于元优化的方法. 前者的目标是学习一个合适的匹配度量函数来度量查询实例与每个参考实例之间的相似性;后者的目标是在小样本任务中通过梯度优化模型参数,使模型快速推广到新的任务.
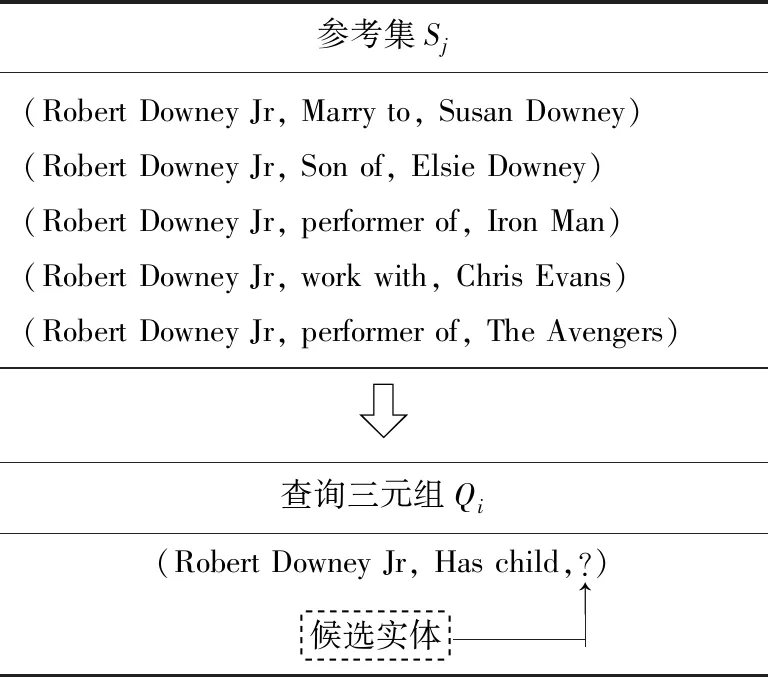
图1 小样本知识图谱补全示例
近年来,在知识图谱补全领域,提出了一些针对小样本学习的模型,其中包括基于匹配度量的模型:GMatching[6]模型和FSRL[10]模型. GMatching[6]模型是首次提出小样本知识图谱补全任务的模型. 模型仅参考目标实体的一个邻居进行预测,通过邻居编码器编码实体的邻居嵌入,并通过循环匹配处理器对参考实例和查询实例的嵌入进行匹配. FSRL[10]模型是在GMatching[6]模型的基础上对邻居编码器和匹配网络进行联合优化,参考目标实体的多个邻居,编码邻居实体时使用注意力机制,通过循环自动编码器聚合网络聚合关系,循环匹配网络将查询实例与参考实例进行匹配. MetaR[11]模型是基于元优化的模型,引入了关系元和梯度元,通过重点传递特定于关系的元信息来解决小样本知识图谱补全问题,使模型学习最重要的知识,通过梯度元更新梯度,加速模型的学习.
2 基于图注意力网络的小样本知识图谱补全方法
为更好地建模局部图结构,本文提出一种基于图注意力网络的小样本知识图谱补全方法. 该方法基于匹配度量的方法[12],通过邻居编码器部分编码实体的局部图结构,匹配网络匹配查询集和参考集,选择排名最高的候选实体作为预测到的正确尾实体,其整体框架如下页图2所示.

图2 本文方法的模型结构
模型左边是邻居编码器,右边是匹配网络. 直观上,实体局部邻域信息在小样本知识图谱补全任务中起着关键作用. 模型利用参考目标实体的局部邻域结构,在邻居编码器阶段得到更准确的实体表示;然后将从邻居编码器得到的新实体表示输入到匹配网络,通过查询集与参考集进行相似性度量,得到相似度得分.
2.1 邻居编码器
随着图神经网络在知识图谱补全任务中的应用,图卷积网络(graph convolutional network,GCN)[13]将实体的局部邻域结构考虑进来. GCN简单地将所有的邻居贡献假设为相同,但在实际知识图谱中,各邻域的重要性是不同的. 例如,在补全三元组(小罗伯特唐尼·孩子)时,参考三元组(小罗伯特·唐尼,同事,克里斯·埃文斯)是工作关系,(小罗伯特·唐尼,父亲,罗伯特·唐尼)是家庭关系,明显家庭关系应该占有较高权重. 为解决GCN的缺点,Velickovic Peter等提出了图注意力网络. GAT通过其注意力机制为目标节点的参考邻域根据其重要性分配不同的权重,而不是像GCN那样以同等重要性对待所有相邻节点.
对于将要预测的小样本任务关系r的三元组(h,r,?),将其邻居表示为(hi,r,ti). 目标实体e的邻居(hi,ri,ti)∈Ne编码表示为
ci=(hi;ri;ti),
其中hi、ri、ti分别为与目标实体e链接的关系和头尾实体,ci为邻居的向量表示.
注意力值di为不同邻居对实体e的重要性. 对于实体e,计算每个邻居的注意力系数
di=σ[UTW[hi;ri;ti]],
其中W为可学习的线性变换权重矩阵,U为激活函数LeakyReLU的权重矩阵,σ(·)为由LeakyReLU实现的非线性激活函数.
通过softmax函数实现注意力系数的归一化
2.2 匹配网络
对于同一个任务关系,在不同的三元组中所含语义表示可能不同[14],因此为了进一步提高预测的准确性,本文采用一个添加注意力机制的匹配网络. 图3给出了匹配网络的架构.
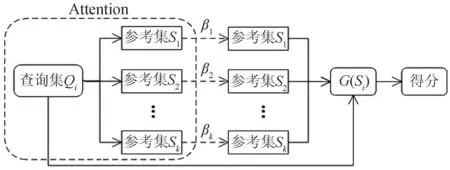
图3 匹配网络结构图
如图3所示,将由GAT编码后的向量输入匹配网络,度量查询三元组和参考三元组之间的语义相似度,得到查询集与参考集的注意力值
其中Qi为需要预测的查询三元组,Sk为查询三元组头实体的k个参考三元组. 由注意力值,得到适应不同任务关系的表示
为了进行预测,定义了一个点积度量函数
f(Qi·Si)=Qi·G(Si),
用于度量查询集Qi和参考三元组Si之间的语义相似度. 通过度量函数得到得分最高的候选三元组,作为所预测的正确三元组.
3 实验与分析
3.1 实验设置
本文在2个数据集上进行了实验:NELL-one和FB15k237-one. 这2个数据集来源于NELL数据集和FB15k237数据集,选择原数据集中包含同一关系的且数量在50到500之间的三元组作为小样本学习任务. 数据集的统计信息如下页表1所示. 2个数据集中任务数分别为67和45,将任务数划分设置51/5/11,32/5/8个任务关系分别作为训练集、验证集和测试集.

表1 实验数据集
实验中的网络模型采用Pytorch深度学习框架实现. 通过TransE初始化实体嵌入,将数据集中的最大邻居数设置为50,NELL-one数据集和FB15k237-one数据集的嵌入维度为50,参考集数量K设为5,学习率为5×10-5,使用Adam optimizer优化器优化模型参数,并进一步使用L2范式避免过拟合.
3.2 实验分析
本文采用链接预测的2个传统的评估指标评估不同方法在这2个数据集上的效果,即MRR和Hits@N. MRR表示平均倒数排名,Hits@N是在前N个关系预测任务中排名正确的实体的比例.在本文实验中,将N设置为1,5和10.
将本文提出的GAT-FKGC模型在NELL-one和FB15k237-one这2个数据集上使用相同的实验环境,与现有的小样本补全模型进行比较,实验结果如表2和表3所示.
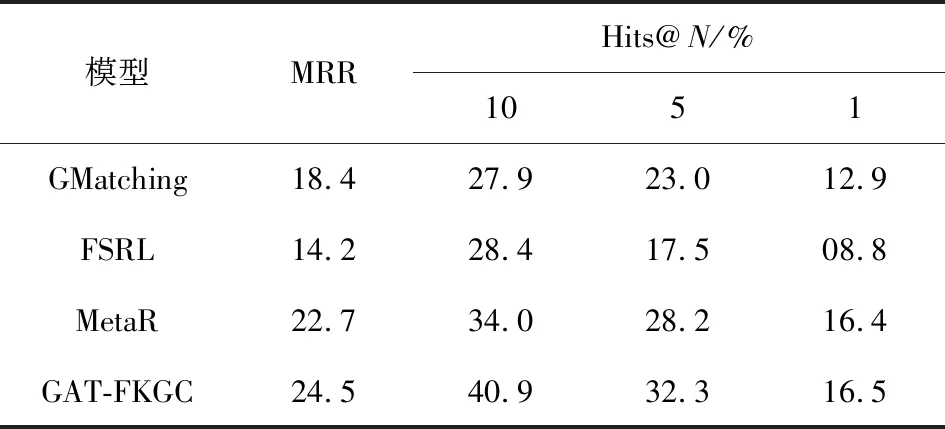
表2 NELL-one数据集上链接预测结果

表3 FB15k237-one数据集上链接预测结果
可以看出,本文方法的小样本知识图谱补全任务的MRR值比其他基线模型的高. 这是因为G-Matching模型,FSRL模型和MetaR模型都是采用R-GCN来编码局部图结构. 而且在同样属于基于匹配度量的模型GMatching模型和FSRL模型中,GMatching模型没有使用注意力机制,简单假设所有邻居三元组权重相同;FSRL模型在邻居编码器部分使用了注意力机制,但在匹配网络部分与GMatching相似,仅通过点积度量函数匹配查询三元组与参考三元组的相似性. 但是本方法采用了图注意力网络编码局部图结构,并且在匹配查询集和参考集时添加了注意力机制. 由此可见,图注意力网络比图卷积网络能够捕获更多的实体信息,能够有效提升小样本知识图谱补全的性能.
4 结 语
为提高小样本知识图谱补全任务的性能,本文提出一种基于图注意力网络的匹配度量方法. 该方法使用图注意力网络对实体的局部邻域进行建模,融合更为准确地实体邻域结构信息;使用匹配网络匹配查询三元组与其参考集的相似性. 在2个数据集NELL-one和FB15k237-one上验证了本文方法的有效性. 实验结果表明,使用图注意力网络编码局部图结构的匹配度量方法对于小样本知识图谱补全任务具有重要意义.
在未来的工作中,将考虑增强实体表示,通过挖掘知识图谱中更深层次的链接,进一步提升小样本知识图谱补全任务的性能.
