基于分级信息融合模型的电力投诉工单分类研究
2023-12-13张莉王颖赵阳崔涵翔刘娟
张莉, 王颖, 赵阳, 崔涵翔, 刘娟
(1.国家电网有限公司客户服务中心, 天津 300306; 2.北京中电普华信息技术有限公司, 北京 100031)
0 引言
电力客服系统是供电企业与电力客户之间的重要纽带,用户投诉成了该系统亟待解决的核心挑战。用户在用电过程中提出的投诉内容对于提升用户体验和保障电力系统运行质量十分重要。目前,对于电力投诉工单数据的分析方法主要由专业人员对大量的电力投诉工单进行人工数据分析。这种人工分析方法在分析大量的投诉工单时存在效率不足和主观偏差的问题[1]。因此,需要提出一种基于人工智能技术的电力投诉工单分析模型,以自动、高效和准确地对投诉工单进行分类。
工单分类问题是文本分类问题的分支。近年来,文本分类问题得到了许多研究人员的关注[2]。周庆平等[3]提出了基于采用K最邻近(KNN)的文本分类算法,使用改进统计量方法对文本特征进行聚类分析。周源等[4]提出一种改进的TF-IDF(Term Frequency-Inverse Document Frequency)文本特征提取方法来解决文本结构信息忽略和特征词分布的问题。廖列法等[5]提出一种基于LDA(Latent Dirichlet Allocation)的文本分类模型,利用LDA模型对文本语料库建模来达到分类的目的。陈海红[6]提出基于多核支持向量机(SVM)的文本分类方法进行文本特征提取。以上基于浅层机器学习的文本分类方法虽然有训练快速的优点,但在面对长文本分析时,浅层机器学习模型往往欠缺特征学习能力和泛化能力。
为了解决浅层学习模型的限制问题,目前研究中广泛关注了深度学习模型,包括卷积神经网络(CNN)和长短时记忆网络(LSTM)实现文本分类成了研究热点。张云翔等[7]提出了基于LSTM的电网文本信息的分类模型。李洋等[8]提出了基于CNN和双向长短时记忆网络(BiLSTM)融合的文本分类模型,利用CNN提取文本信息再利用BiLSTM学习文本间的上下文关联。虽然基于深度学习模型的文本分类模型取得了优于浅层机器学习模型的性能,但对于长文本的分析仍是文本分类的难点。因此,本文提出了一种分级信息融合的电力投诉工单分类模型,来提升工单中长文本的分析能力。该模型首先利用BiLSTM来学习单词间的依赖关系,同时运用TextCNN学习句子间的相互关联,再将各级学习到的特征利用MLP实现特征层融合,最终得到电力投诉工单的分类结果。
1 算法概述
1.1 Word2vec词嵌入算法
文本的稀疏编码可以将众多的单词映射到一个共享的空间,但当词汇库中的单词类别众多时,会出现“维数灾难”的问题。为了应对这一挑战,BOJANOWSKI等[9]提出了Word2vec框架用于对单词进行编码,如图1所示。Word2vec不仅是一种有效的降维方法,有助于避免“维数灾难”问题,而且由于考虑了单词之间的上下文关联,还能够减轻语义鸿沟带来的问题。

图1 Word2vec词嵌入方法
1.2 TextCNN算法
TextCNN是由KIM[10]在2014年提出并应用至文本分类任务的。TextCNN的网络结构模型如图2所示。TextCNN通过不同大小的一维卷积核对输入矩阵进行不同尺度的语义学习。首先在输入数据的每个维度上进行不同尺度的一维卷积运算,得到不同尺度的特征图。对特征图进行第一次池化得到特征的向量表示以达到信息压缩的目的。接下来再对得到的所有向量再进行一次池化,并拼接得到包含所有尺度特征的一维特征向量。将得到的特征向量输入到输出层,得到当前句子的分类结果。

图2 TextCNN的网络结构模型
1.3 BiLSTM算法
在文本分类任务中,文本的上下文关联信息对于分类结果起着至关重要的作用[11]。因此,广泛应用了能够学习双向语义相关信息的双向长短时记忆网络(BiLSTM)在文本语义识别中[12]。BiLSTM的输入门Gi、遗忘门Gf、输出门Go、记忆细胞更新、t时间步的输出可被表示为
Gi=σ(WiYt-1+UiXt+bi)
(1)
Gf=σ(WfYt-1+UfXt+bf)
(2)
Go=σ(WoYt-1+UoXt+bo)
(3)
C′=tanh(WcYt-1+UcXt+bc)
(4)
Ct=Gf×Ct-1+Gi×C′
(5)
Yt=Go×tanh(Ct)
(6)
其中,σ(·)表示Sigmoid激活函数,Wi、Wf、Wo分别对应每个门的权重,tanh(·)表示tanh激活函数,Yt-1表示(t-1)时间步的输出,Xt表示t时间步的输入,Wi、Wf、Wo分别对应前一个时刻输出到每个门的权重,Ui、Uf、Uo分别对应当前时刻输入到每个门的权重,bi、bf、bo分别为每个门的偏置项,Xt表示t时间步的输入,C′表示状态变量,Ct-1表示(t-1)时间步的记忆细胞,Ct表示t时间步的记忆细胞。BiLSTM将文本序列两个方向的最后一个时间步的输出Yleft和Yright进行拼接,并进行最后的输出预测Y。
Y=Softmax(concatenate(Yleft,Yright))
(7)
其中,concatenate(·)表示拼接2个输出Yleft和Yright,Softmax(·)表示激活函数Softmax。
2 模型框架与算法设计

3 实验设计与分析
3.1 数据预处理
本文网络结构在CPU Intel Core i7-9700F和GPU NIVIDA GTX1060的平台上运行程序。数据集是从电网客服中心的记录中获取的,包含了3万个投诉工单样本。这些工单记录了客户对电网的反馈信息,共分为5类:服务投诉(C1)、营业投诉(C2)、停送电投诉(C3)、供电质量投诉(C4)和电网建设意见(C5)。在数据准备阶段,已经进行了句子分割、数据清洗等预处理操作。最后,将整个数据集划分成了训练集和测试集,比例为9∶1,以便进行模型的训练和评估。
3.2 网络的超参数设置
Word2vec词嵌入算法的隐含层神经元个数设置为200,词向量的维度设置为100。TextCNN的卷积核大小分别3×1、4×1和5×1,每一种卷积核的数量为100。BiLSTM隐含层为2,每层的神经元个数分别64和32。损失函数为交叉熵函数,优化算法选取adam,学习率为0.001,随机失活率设计为0.3,迭代次数设置为100,批训练样本数量为64。
3.3 实验结果分析
根据表1可知,本文提出的分级信息融合模型在测试集上对5类工单分类表现出了良好的性能。平均正确率达到0.922,宏-F1分数为0.930,这表明该模型能够相对准确地对投诉工单数据进行分类。此外,对于停送电投诉(C3)的分类正确率最高,达到0.960,显示出了在该类别上的出色性能。然而,对于营业投诉(C2)的分类正确率最低,仅为0.884。这可能是因为文本内容的复杂性和相似性,而造成一些举报被误分类为服务投诉(C1)或供电质量投诉(C4)等其他类别中。为了进一步提高对营业投诉的分类性能,可以考虑进一步优化模型或者增加更多的特征工程。
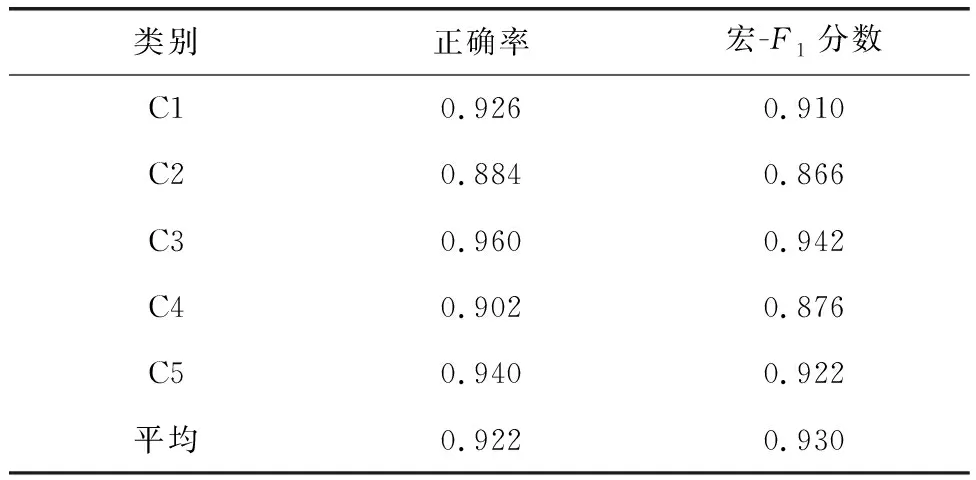
表1 分级信息融合模型的工单分类结果
在比较实验中,将本文提出的模型与TextCNN、BiLSTM和深度置信网络(DBN)等模型在分类性能上进行比较,根据表2可以看出,本文提出的分级信息融合模型在分类性能上表现出了明显的优势。相对于其他3个模型,该模型分别提升了1.9%、5.3%和13.5%。这个显著的性能提升可能是由于本文所提出的模型综合运用了多个策略,包括使用TextCNN有效地学习语句级的语义信息,使用BiLSTM对单词级的上下文关联进行了有效的学习,最后应用MLP实现了多级信息融合。这些策略的组合提高了对投诉工单的分类性能,使得模型在这项任务上表现出色。
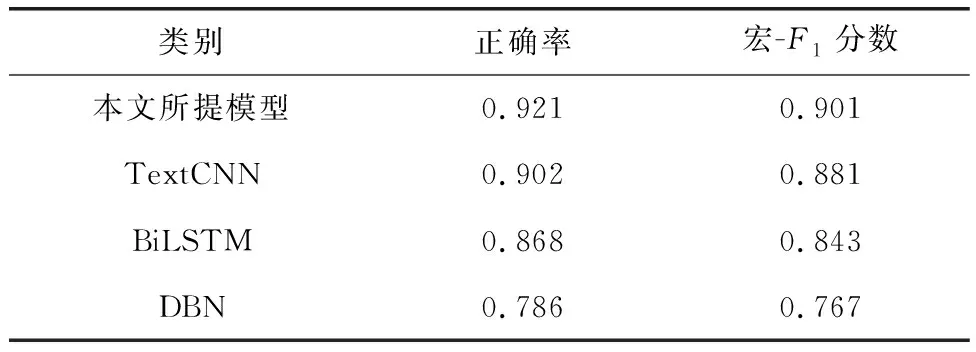
表2 不同网络模型的性能比较
4 总结
本文对电力投诉工单数据的分类进行了研究,针对投诉工单数据中的长文本提出了分级信息融合模型,有针对性地学习了单词级和语句级的语义特征并进行了分级信息的融合。首先通过Word2vec得到词向量和语义矩阵,再通过TextCNN学习语句级的语义特征,同时应用BiLSTM学习单词间的上下文关联,将语句级和单词级的深度特征进行特征层融合,最终输入至多层感知机,得到投诉工单的预测结果。
