浅谈Intel CPU架构相关指令及其运用
2023-12-12彭茜珍余朝晖
彭茜珍,余朝晖
(湖北科技学院 学报编辑部,湖北 咸宁 437100)
Intel处理器的超标量流水线设计是使用微架构(Microarchitecture)实现的[1],这种实现技术的主要思路是先打造一条坚实基础的超标量流水线,规划好大致的段数和每一段的基本任务,再在之后的升级换代中,根据芯片工艺的不断进步和应用需求,实时增添新的功能和更新旧的功能机制,壮大处理器的性能和效能,同时保持指令代码的兼容性。它除了提供常规的指令外,还提供针对微架构的特殊指令,借助于这些特殊指令可以充分发挥超标量流水线的潜力,提高指令代码的效率。本文针对Intel CPU的微架构提供的一些特殊指令进行分析和探究,给出了在指令代码设计中,利用它们以提高流水线的效率和能力的一些有用的可以借鉴的思路。
一、引言
处理器的微架构是CPU实现的基石,它是在计算机工程中,将一种确定的指令集架构ISA在微处理器中执行的框架。一种给定的指令集可以在不同的微架构中执行。实施中可能因应不同的设计目的和技术提升而有所不同。在CPU的开发历史中,涌现出许多优秀的微架构,比较著名的有Alpha 21264处理器的微架构[2]、MIPS32处理器的微架构[3]、ARM处理器的微架构[4]等,它们的设计思路和技术线路图都为后世各大公司的CPU开发提供了丰富的思想和借鉴。1996年,Intel 公司在其开发的Pentium Pro微处理器中首次引入微架构P6,之后又陆续地推出了NetBurst微架构(Pentium 4,2000年)、Nehalem微架构(Core i7900系列,2008年)、SandyBridge微架构(2011年)、Haswell微架构(2013年)、Skylake微架构(2015年)、Coffee Lake微架构(2017年)、Ice Lake微架构(2019年)、Tiger Lake微架构(2020年)、Alder Lake微架构(2021年)和Raptor Lake微架构(2022年)[5],每次推出的处理器微架构或多或少地都会加入与架构相关的特殊指令,随着时间的推移,这些特殊指令中一些已经成为各个处理器微架构的标准配置指令,借助这些指令或可以对已有的程序进行优化,或在开发新的程序中运用它们,这些都可以充分挖掘处理器流水线的能力,提高程序的运行效率。
本文后面重点探究的特殊指令包括Cache控制指令、内存一致性模型相关的指令、线程同步指令和流水线运行提示指令,深入分析它们在微架构中的运行机理和作用,并通过在汇编级代码如何运用它们,给出一些指导意见。
二、Intel CPU架构相关指令简述
下面对Intel CPU微架构引入的一些经典的与架构相关的特殊指令,做一简要的论述[6]。
(一)Cache控制指令
分为两类,一类是减少Cache污染的指令,另一类是Cache预取指令。
1.减少Cache污染的指令
MASKMOVQ mm1,mm2,把从目标数据mm1中选择的字节写到64位内存单元中,选择那些字节由mm2(掩码操作数)确定,内存位置由寄存器DI/EDI和DS给出。
MASKMOVDQU xmm1, xmm2,把源数据xmm1中选择的字节写到128位内存单元中,选择那些字节由xmm2(掩码操作数)确定,内存位置由寄存器DI/EDI和DS给出。
MOVNTPS m128, xmm,使用非临时提示(Non-Temporal hint),把打包的单精度浮点数直接存入内存,并且,在写入内存期间,尽量减小对缓存的污染。
MOVNTPD m128, xmm,使用非临时的提示,将源中打包的两个双精度浮点数直接存入内存,尽量减小对缓存的污染。
MOVNTQ m64, mm,使用非临时的命中,把64位整数直接存入内存,并且,在写入内存期间,尽量减小对缓存的污染。
MOVNTDQ m128, xmm,使用非临时的提示,将源中打包的两个64位整数直接存入内存,尽量减小对缓存的污染。
MOVNTI m32, r32,使用非临时的提示,将32位整数直接存入内存,并且,在写入内存期间,尽量减小对缓存的污染。
2.Cache预取指令
PREFETCHT0 m8/PREFETCHT1 m8/PREFETCHT2 m8/PREFETCHNTA m8
使用T0、T1、T2、NTA提示,从m8内存中预取数据到规定的处理器的缓存层次中。取出的数据量是一个Cache行的内容(32个或更多的字节)。
T0(临时数据),预取数据,并将它送入到缓存层次架构中的各级cache 中;T1(与1级缓存相关的临时数据),预取数据,并将它送入到除第1级以外的各级缓存中;T2(与2级缓存相关的临时数据),预取数据,并将它送入到除第1级和第2级以外的各级缓存中;NTA(与所有缓存级相关的非临时数据),预取数据进入非临时缓存结构,并将它仅送入到离处理器最近的cache中,最小化对缓存的污染。
(二)内存一致性模型相关的指令
提供了三条栅栏指令:LFENCE,SFENCE和MFENCE。它们的功能是在CPU访问存储器时提供内存栅栏,以保证内存一致性模型的实施。
1.LFENCE指令,串行化Load操作。对于在LFENCE指令前面发出的所有Load指令执行序列化操作。
2.SFENCE指令,串行化Save操作。对在SFENCE 指令之前发出的所有Save指令执行序列化操作。
3.MFENCE指令,串行化存储操作。对于在MFENCE指令前面发出的所有Load与Save指令执行序列化操作。
(三)线程同步指令
包括MONITOR和MWAIT指令,目的是提供多个线程之间的同步,系统软件可以利用它们提供更有效的线程同步手段。
1.MONITOR指令,设置监控地址。MONITOR 指令使用在RAX/EAX/AX中指定的地址对所包含的监控硬件的地址进行监视。
2.MWAIT指令,向处理器提供了一些提示,允许处理器进入实现-依赖-优化状态。这有两个主要的目标用途:地址范围监控和高级电源管理。MWAIT的这两种用途都要求MONITOR指令配合。
(四)流水线运行提示指令
PAUSE指令,提升了自旋等待循环(spin-wait loop)的性能。当执行一个循环等待时,有些架构的处理器会因为检测到一个可能的内存顺序违规(memory order violation)而在退出循环时使处理器的性能大幅下降。它给处理器一个提示:这段代码序列是个循环等待。处理器利用这个提示可以避免在大多数情况下的内存顺序违规,这将大幅提升性能。另一个功能就是降低了处理器在执行循环等待时的耗电量。
三、Intel 架构相关指令的实现机理探究
这里,对这些特殊指令在微架构中运行实现的机理做深入的探究[7],以便充分掌握它们的功能,更好地把它们运用在代码的开发中。
(一)流水线指令解码段的特殊分解
在流水线的指令解码阶段,把X86指令分解成微op,但对于减少Cache污染的指令,其微op有特殊的格式,如图1,当中Locality Hint域给出了non-temporal data的数据标识。通过这个数据标识,对Cache的分配采用新的机制。
(二)基于non-temporal data和temporal data数据标识的Cache分配机制
在Intel CPU架构中,每个核都有L1和L2两级Cache(由此核线程共享),以及一个统一的L3(3级Cache)由CPU内所有核共享的[8]。在Cache分配时,被缓存的数据应该是短时间内频繁使用的数据,即temporal data,所以分配Cache line时,应保证尽量避免分配给那些短时间内不常用的数据,即non-temporal data,以及避免被这些数据覆盖掉原有的Cache line。图2展示的是采用共享的Cache 结构数据访问路线图。
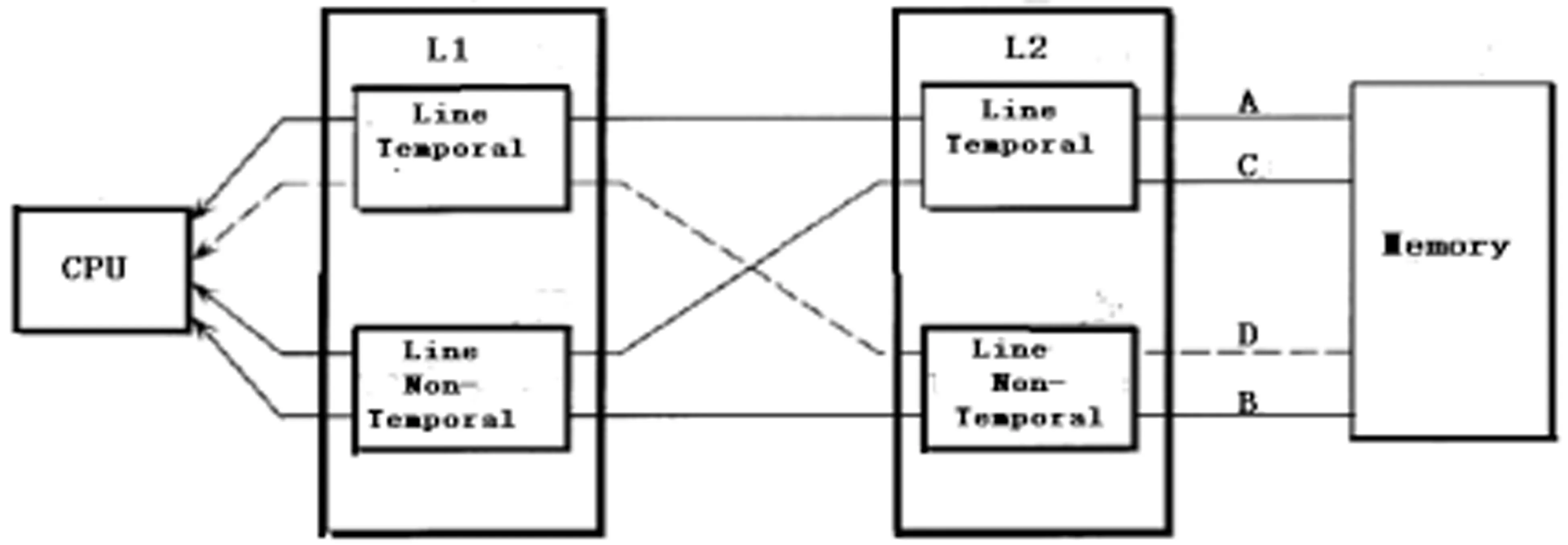
图2 数据访问路线图
图中L1(一级)和L2(二级)Cache中分别有记录non-temporal和 temporal的数据信息的Cache line,根据处理器指令中的Locality Hint信息,以决定Cache line的分配。temporal数据line按照通常的Cache机制处理;而non-temporal的数据line按照WC内存协议处理,以减少对Cache的污染。这样,当处理器与Cache进行数据交互时,所需要的信息可能在共享Cache中,也可能不在其中。处理器通过指令中的Locality Hint信息确定要访问的数据性质。同时,整个共享Cache层次系统都按照non-temporal和temporal组织数据。处理器只需判定指令中的数据Hint信息并与共享Cache中的上述两种数据类型进行比较就进而决定数据应该采用何种规则放在Cache中来进行存取。
(三)弱一致性和强一致性存储器模型的保证
流水线由于实现了分支预测、乱序执行、指令并行执行等技术,从而提高了处理器的运行效率。但是,存储器读/写次序影会响程序的执行结果。应用程序可通过栅栏指令保证内存模型的弱一致性和强一致性。
指令LFENCE强制内存加载(读)排序,所有在LFENCE之前的内存加载操作将跟随指令LFENCE完成。内存装载不能围绕指令LFENCE重排序。指令SFENCE强制内存存储(写)排序,所有在SFENCE之前的内存存储操作将跟随指令SFENCE完成。内存存储不能围绕指令SFENCE重排序。指令MFENCE强制所有内存访问(读和写)排序。所有在MFENCE之前的内存访问操作将跟随指令MFENCE完成。内存访问不能围绕指令MFENCE重排序。
(四)线程同步指令机制的探讨
当OS调度程序没有工作要做时,它通常会进入空闲的自旋等待循环,直到有事情要做。空闲线程一般做无用功,但处理器的分区资源仍会然被分区。如果在物理处理器上所属执行的多个线程都应该处于空闲状态时,则将处理器处于低功耗状态。这时必须有一种方法来唤醒处于低功耗状态这些逻辑处理器,并在唤醒后使其再次工作(即线程)而退出空闲状态的执行。MONITOR指令与MWAIT指令的配合就可以实现这类机制,借助于这2条指令使系统软件通过它们提供高效的线程级同步原语。
(五)流水线性能下降深入剖析
自旋锁在获取锁失败后,会在较短时间内频繁地判断循环条件是否成立,这会导致流水线严重的性能下降。原因是:(1)当为读取锁变量而执行Load时,它被放置在逻辑核的某个Load Buffer中,以等待所读数据的返回。(2)在自旋等待循环中,逻辑核对在多个加载缓冲器中每个等待完成的这些连续地读取锁变量进行排队。处理器可以比访问cache更快的速度调度这些重复加载以提取锁变量。(3)当在另一个逻辑核上的线程最终执行完存储锁变量时,它被寄发到分配到该逻辑核的某个Store Buffer中。(4)处理器必须确保由其他逻辑核发出的这些Load优先于接收预存储数据的Load。(5)必须保证在自旋锁循环中执行的Load紧跟在从其核的Store Buffer接收的更新数据的Store之后。(6)逻辑核执行锁变量的Store是不允许的,直到所有预存储的Load已经从流水线退出。(7)只有这样,该Load才允许完成。(8)最终,寄发Store的加载被允许完成。
PAUSE指令可以解决此问题。把它放置在一个自旋等待循环中时,该指令导致读取锁变量的每个Load发出之间有一个小的延迟。这样的结果是,在这些未完成的Load中只会有一个未完成的Load将由Store提供服务,当它发生时,这有助于线程执行Store的性能,因为该Store可以非常快速地完成。
四、Intel CPU架构相关的指令在程序设计中的运用
Intel CPU架构相关的指令是基于处理器硬件设施的,使用之前需要做一些准备工作,需要检测CPU是否支持这些指令,通过检测后才可以使用,否则会产生#UD 异常。另外,某些指令还需要在使用它们之前,按要求开启这些指令。下面给出这些指令在汇编级代码中的运用举例及指导[9]。
(一)减少Cache污染指令的使用:
下面的伪代码片段做数组计算c[i]=sqrt(a[i]*a[i]+ b[i]*b[i])
for(i = 0; i movaps xmm0,a[i] ;提取数组元素 movaps xmm1,b[i] ;提取数组元素 mulps xmm0,xmm0 mulps xmm1,xmm1 addps xmm0,xmm1 sqrtps xmm0,xmm0 movntps c[i],xmm0 ;存储数组元素 } 由于存储结果时使用了movntps指令,减少了Cache污染,性能很高。 下面的代码片段实现4x4矩阵m和4维向量的v的乘积,由于使用预取指令,速度很快。 这就是所谓的价值互联网,是互联网的又一次延展。区块链的核心是做数据管理和价值传递,只是信息技术的一个“区块”,还必须与其他信息技术和场景“链”起来,才可能占据互联网世界的一个生态位。 for(i = 0; i { double row1, row2, row3, row4; row1 = m[0] * v[i] + m[1] * v[i+1] + m[2] * v[i+2] + m[3] * v[i+3]; // 前一行执行完后,整个4 维向量已经加载到 cache 中。 // 所以,现在用 prefetch 指令加载下一个 4 维向量。 prefetch(v + i * 4); // 继续进行计算 row2 = m[4] * v[i] + m[5] * v[i+1] + m[6] * v[i+2] + m[7] * v[i+3]; row4 = m[12] * v[i] + m[13] * v[i+1] + m[14] * v[i+2] + m[15] * v[i+3]; v[i] = row1; v[i+1] = row2; v[i+2] = row3; v[i+3] = row4; } 3条栅栏指令强制内存访问次序,确保内存访问按程序的次序进行。 下面的代码片段展示从一个设备适配器中的三个内存映射IO端口中读取,假定这些端口是在UC内存范围。该示例适配器的正确操作是请求这三个存储器数据读事务被严格地按程序顺序来执行。 mov eax,10 mov ebx,memioport1 ;从内存映射IO端口1中读取 lfence mov edx,memioport2 ;从内存映射IO端口2中读取 xor eax,edx lfence mov ecx,memioport3 ;从内存映射IO端口3中读取 下面的代码片段执行在一个设备适配器中存储三个内存映射IO端口,并假定端口在UC内存范围。该例子的设备驱动程序的正确操作要求存储到端口1,2和3必须是在该设备的任何跟在这些写操作之后的指令被执行之前可以看见的。 mov eax,10 mov memioport1,ebx ;写入内存映射IO端口1中1 mov memioport2,edx ; 写入内存映射IO端口2中 xor eax,edx mov memioport3,ecx ; 写入内存映射IO端口3中 sfence mfence指令作为一个栅栏防止处理器执行该栅栏之后的任何读或写,直到该栅栏之前的所有读和写已经完成,同时处理器的存储缓冲区和WCBS已被写入到内存,代码片段如下: mov eax,10 mov ebx,memioport1 ; 从内存映射IO端口1中读取 mov edx,memioport2 ; 从内存映射IO端口2中读取 mov memioport3,eax ; 写入内存映射IO端口3中 xor eax,edx mfence mov ecx,memioport4 ; 从内存映射IO端口4中读取 MONITOR/MWAIT指令的目标是使系统软件用于提供更有效的线程同步手段。MONITOR 定义监视写回存储的地址范围。MWAIT指示软件线程正在等待着对地址范围(MONITOR 指令定义)的写回存储操作。 下面给出了MONITOR/MWAIT指令的典型用法。 //trigger[MONITORDATARANGE]确定触发的数据范围的内存地址范围,trigger[0] = 0。 If ( trigger[0] != TRIGERRDATAVALUE) { EAX = &trigger[0] ECX = 0 EDX = 0 MONITOR EAX, ECX, EDX If (trigger[0] != TRIGERRDATAVALUE ) { EAX = 0 ECX = 0 MWAIT EAX, ECX } } 代码序列确保在触发器的第一次检查和monitor指令的执行之间不会发生触发存储的动作。如果没有第二次检查,触发存储的动作就不会被注意到。因此,MONITOR和MWAIT的典型用法是在一个循环中包含上述代码序列。 在构造自旋锁时使用PAUSE指令,它应放置在一个自旋等待循环中,以提示处理器的流水线规避性能下降。 下面是一个构造自旋锁的代码片段,一个已锁的定RMW(读/修改/写)被用来检查同步变量。 get_lock: mov eax, 1 xchg eax, mem ;读当前值并设置它 cmp eax, 0 ;判断当前值是否已经设置? jne spin_loop ;如果设置就自旋 critical_section: <临界区代码> mov mem, 0 ;清除 jmp continue spin_loop: pause ;提示流水线 cmp mem, 0 jne spin_loop jmp get_lock continue: … 充分运用CPU超标量流水线的微架构实现所提供的这些特殊指令,这在开发嵌入式软件代码、仿真与实时监控代码、OS的系统代码、电脑游戏关键处的代码、针对处理器设计的编译软件以及程序的优化都带来了极大的好处。因此,深入探究处理器微架构相关的特殊指令功能和工作机制,使程序员能够写出更好的程序代码,实现更高的流水线运行效率打下坚实的基础。(二)Cache预取指令的使用
(三)内存一致性模型相关的指令
(四)线程同步指令的使用
(五)流水线运行提示指令的使用[8]
五、结语
