基于孪生自适应图卷积算法的点云分类与分割
2023-11-29李维刚陈婷田志强
李维刚,陈婷,田志强
基于孪生自适应图卷积算法的点云分类与分割
李维刚1,2,陈婷1*,田志强1
(1.武汉科技大学 信息科学与工程学院,武汉 430081; 2.武汉科技大学 冶金自动化与检测技术教育部工程研究中心,武汉 430081)( ∗ 通信作者电子邮箱chenting_myself@163.com)
点云数据具有稀疏性、不规则性和置换不变性,缺乏拓扑信息,导致它的特征难以被提取,为此,提出一种孪生自适应图卷积算法(SAGCA)进行点云分类与分割。首先,构建特征关系图挖掘不规则、稀疏点云特征间的拓扑关系;其次,引入共享卷积学习权重的孪生构图思想,保证点云的置换不变性,使拓扑关系表达更准确;最后,采用整体、局部两种结合方式,将SAGCA与各种处理点云数据的深度学习网络相结合,增强网络的特征提取能力。分别在ScanObjectNN、ShapeNetPart和S3DIS数据集上进行分类、对象部件分割和场景语义分割实验的结果表明,相较于PointNet++基准网络,基于同样的数据集和评价标准,SAGCA分类实验的类别平均准确率(mAcc)提高了2.80个百分点,对象部件分割实验的总体类别平均交并比(IoU)提高了2.31个百分点,场景语义分割实验的类别平均交并比(mIoU)提高了2.40个百分点,说明SAGCA能有效增强网络的特征提取能力,适用于多种点云分类分割任务。
点云数据;拓扑关系;孪生;自适应图卷积;分类;分割
0 引言
随着激光雷达、深度相机等扫描设备的普及与发展[1],获取3D点云数据越来越便捷,分析和处理3D点云数据可以帮助计算机更好地理解真实世界[2],在机器人、虚拟现实、自动驾驶、智慧城市等应用领域[3-4]具有十分重要的研究价值。近年来,随着深度学习技术的不断发展,基于深度学习的3D点云数据处理方法越来越流行,在分类[5-8]、对象部件分割[9-11]和场景语义分割[12-13]等任务上均取得了不错的进展。
基于深度学习的点云数据处理方法大致分为三种,分别为基于体素、基于多视图与基于点的方法。2018年Zhou等[14]提出了基于体素的VoxelNet,通过将3D点云划分为体素后进行处理;然而转换后的数据离散运算量较大,分辨率偏低,导致计算复杂度高、内存开销大等问题。2022年Sheshappanavar等[15]提出了基于多视图的MVTN(Multi-View Transformation Network)+SimpleView++,使用邻域投影和对象投影来学习更细小的结构信息;然而将点云投影得到多视图图像的过程中易丢失一些真实点云对象的相对位置信息,存在几何信息丢失的问题。Qi等[16]首次提出了基于点的PointNet,直接使用不规则的点云数据作为输入,能保持点云的结构完好无损,打破了以上两种方法的局限性,为后续基于点的点云处理研究提供了理论支撑。在此基础上,Qi等[17]又提出层次网络PointNet++,将3D点云划分为多组邻域,再逐层提取点云的局部信息,解决了PointNet无法提取局部特征的问题,但未充分获取局部特征。为了更好地提取局部特征,DGCNN(Dynamic Graph Convolutional Neural Network)[18]采用了一种新颖的EdgeConv算法,通过聚合每个点及其个邻域点的特征来提取局部特征,侧重于学习采样中心点与其邻域点间的特征关系,但忽略了邻域点相互结构特征的学习。虽然上述网络在点云的分类、分割任务上都取得了不错的成绩,但它们均忽略了以下两种潜在的拓扑关系,进而限制了它们提取点云有效特征的能力:1)忽略了邻域内点间的拓扑关系,缺乏对局部上下文信息的充分探索;2)忽略了邻域与邻域间的拓扑关系,对整体邻域间关系的把握也不够充分。针对这些问题,本文的主要工作如下:
1)提出自适应图卷积算法(Adaptive Graph Convolutional Algorithm, AGCA),通过构图,将稀疏、不规则点云数据的点与点相互连接起来,用图结构表示点云间潜在的拓扑关系,解决稀疏性导致的信息丢失以及不规则性带来的特征提取困难问题;
2)引入共享卷积学习权重的孪生构图思想,保证点云的置换不变性,提出了一种新的孪生自适应图卷积算法(Siamese Adaptive Graph Convolutional Algorithm, SAGCA),确保特征关系图的对称性,更准确地表达点云数据特征间的拓扑关系,消除不考虑点云置换不变性对特征提取带来的不良影响;
3)采用局部、整体两种结合方式,将SAGCA与现有基于点的深度学习网络相结合,深入挖掘上述忽略的两种拓扑关系,从而增强网络的特征提取能力,以便更好地完成点云分类、对象部件分割以及场景语义分割任务。
1 相关工作
1.1 基于点的点云处理方法
近些年,越来越多的深度学习网络尝试基于点直接处理3D点云,其中最具代表性的是PointNet++,通过下采样和分组将点云数据划分为多组邻域,再递归处理每组邻域,并简单地使用最大池化层聚合本地特征;然而,它在局部邻域内单独处理每个点,因此没有充分探讨点与点之间的拓扑关系。Qian等[19]在2022年重新审视PointNet++后,提出了一种新的点云训练框架,即将PointNet++与Transformer[20]相结合,提出了PointNeXt,有效提升了网络的性能。但是,Transformer的引入会产生巨大的计算负荷,对设备要求极高,为了避免超大的计算负荷,同年Ran等[21]提出了RepSurf网络,使用三角面和伞面构建一种新的点云表示方法,在有效简化计算过程的同时,增强了网络的表征提取能力。然而,以上方法仍没有充分挖掘点云数据特征间潜在的拓扑关系,笔者认为:构建点云特征间的拓扑关系是解决难以提取点云有效特征问题的关键。
1.2 图卷积神经网络
对于无序不规则的数据,传统的卷积神经网络(Convolutional Neural Network, CNN)难以构建数据间的拓扑关系,但不规则数据仍存在许多潜在的关系,且大多可以用图结构表示,由此,Scarselli等[22]提出了图神经网络(Graph Neural Network, GNN),解决了CNN无法处理无序数据的问题。但对于较复杂的图结构,难以构造有效的深层图神经网络,于是Kipf等[23]将图与CNN相结合,提出了图卷积神经网络(Graph Convolutional neural Network, GCN),利用切比雪夫多项式逼近算法,使得双线性模型近似代替图卷积操作,从而能够构造有效的深层GCN。自此,GCN被广泛应用于不同领域[18,24]。Shi等[25]提出自适应图卷积层,根据不同的人体骨骼样本生成相对有效的图模型,解决了固定图模型泛化能力差的问题。本文受到文献[25]工作的启发,并考虑到点云数据的无序性、不规则性以及置换不变性,提出了一种新的孪生自适应图卷积算法SAGCA,以构建点云特征间的关系连通图,充分挖掘点云潜在的拓扑关系,避免丢失稀疏点的特征信息,从而增强网络的特征提取能力。
2 本文算法

2.1 自适应图卷积算法
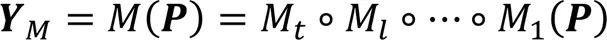
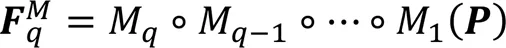
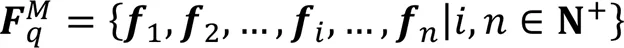
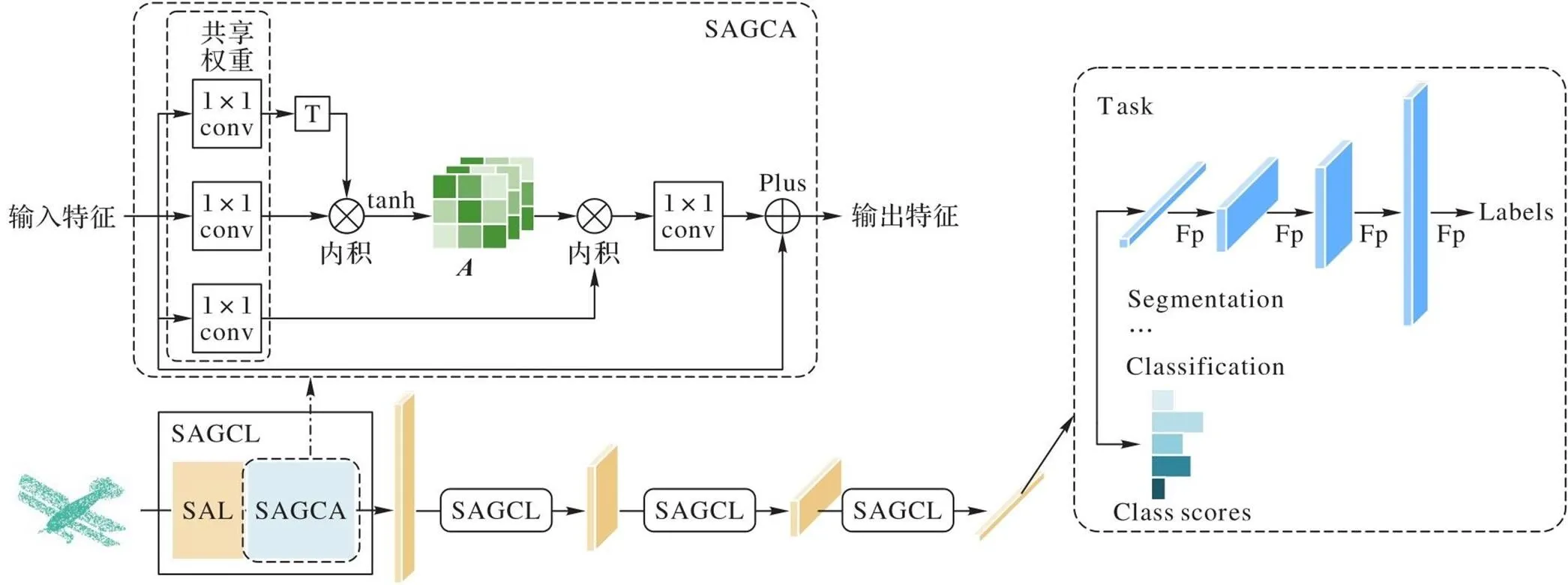
图1 SAGCA的结构及其与现有网络结合的框架
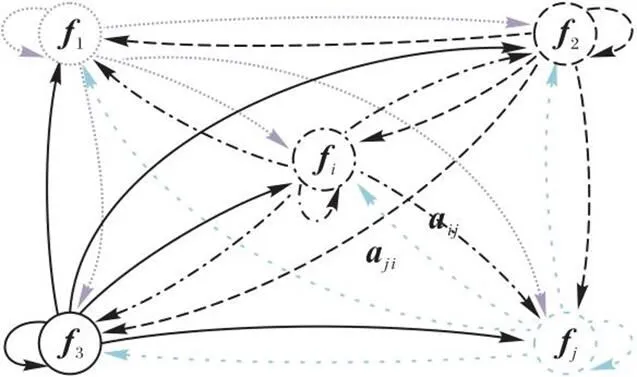
图2 有向的特征关系图
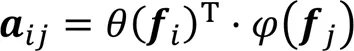

进一步地,将式(5)写成卷积操作的形式:
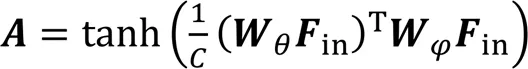
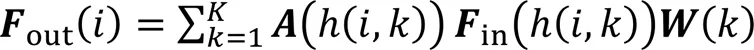
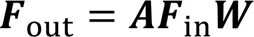
2.2 孪生自适应图卷积算法


图3 无向的特征关系图

2.3 与现有网络的两种结合方式


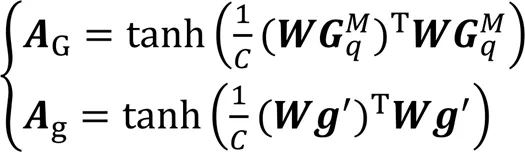
其中:表示整体特征关系图,表示局部特征关系图,分别对应图4(a)、图4(b)。
本文分别从整体、局部两个角度将SAGCA与现有网络相结合,以检验算法的有效性。根据式(9),可得到整体、局部两种结合方式下的输出矢量:
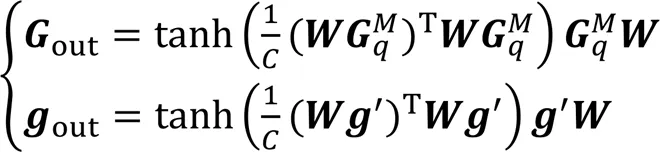
本文通过将SAGCA与现有网络的每一个特征提取层相结合,挖掘整体/局部特征间的拓扑关系,通过特征间的自适应加权融合运算,增强网络的特征提取能力。
3 实验与结果分析
为了验证SAGCA的有效性与通用性,在3个公开数据集上进行实验,使用ScanObjectNN数据集[26]进行三维物体分类实验,使用ShapeNetPart数据集[27]进行对象部件分割实验,使用S3DIS数据集[28]进行场景语义分割实验。实验均在PyTorch[29]深度学习框架上进行,所用GPU为NVIDIA GeForce RTX 2080 Ti。为保证实验的公平性,本文实验的训练参数均与基准网络的训练参数相同。
3.1 分类实验
采用香港科技大学提出的ScanObjectNN进行点云分类实验。该数据集包括15个类、15 000个室内真实物体的扫描对象,本文使用文献[26]中划分好的训练集和测试集。
本文算法在网络RepSurf-U‡、PointNet++上分别采用局部和整体两种结合方式,形成局部孪生自适应图卷积算法(Local Siamese Adaptive Graph Convolutional Algorithm, LSAGCA)和整体孪生自适应图卷积算法(Global Siamese Adaptive Graph Convolutional Algorithm, GSAGCA),使用每个类别的平均准确率(mean Accuracy, mAcc)和所有类别的整体准确率(Overall Accuracy, OA)作为评价指标,并使用每秒10亿次的浮点运算数(Giga FLoating-point Operations Per Second, GFLOPs)衡量模型的复杂度,以每秒处理样本数(sample/s)衡量网络推理速度。输入点数均为1 024(看作一组样本)。RepSurf-U‡批处理大小为64,epoch为250;PointNet++批处理大小则为24,epoch为200。实验对比对象为SpiderCNN[5]、PointCNN[6]、DRNet(Dense-Resolution Network)[7]、MVTN+SimpleView++[15]、PointNet、PointNet++、DGCNN、RepSurf-U‡、Point-MAE(Mean Absolute Error)[30]和PointMLP(MultiLayer Perceptron)[31],实验结果如表1所示。由表1可知:
1)两种结合方式均能提升PointNet++、RepSurf-U‡的分类精度。对于PointNet++,两种拓扑关系均未充分挖掘,但对于无需上采样的分类任务,未充分探究邻域内点与点之间的拓扑关系,相较于未探索邻域间拓扑关系影响更大,故LSAGCA效果更佳;对于RepSurf-U‡,局部点云已使用三角面或伞面表征方法表示,已构建邻域内点间拓扑关系,而忽略了挖掘邻域间潜在的拓扑关系,故SAGCA效果更佳。
2)LSAGCA-PointNet++学习构建了局部特征关系图,充分挖掘了邻域内点间特征的拓扑关系,故相较于PointNet++,能更好地捕获局部特征的上下文关系,OA和mAcc指标分别提升了1.99和2.80个百分点。
3)LSAGCA、GSAGCA均采用了图卷积操作,与网络相结合,均增加了网络的卷积核数量以及网络的卷积乘运算复杂程度,故两种结合方式均会增大PointNet++、RepSurf-U‡的GFLOPs,而LSAGCA卷积核大小比GSAGCA大,导致乘运算更复杂,故与LSAGCA结合后的网络GFLOPs更大。
4)网络模型越复杂,推理速度便越慢,即每秒处理样本数与GFLOPs成反相关,两种结合方式均会造成推理变慢,但相较于分类效果的提升,速度的降低幅度在合理范围内,且测试模型预测速度受使用设备影响较大。
5)GSAGCA-RepSurf-U‡融合了组与组全部的邻域特征信息,充分挖掘了邻域间潜在的拓扑关系,增强了网络对整体特征的学习能力,OA和mAcc指标高达86.50%和85.69%,比RepSurf-U‡分别提升了0.50和2.59个百分点,与对比网络相比,性能保持最优。
6)本文算法适用于不同网络,两种方式均能构建点云特征的拓扑关系图,获取更显著的上下文特征信息,增强网络对点云的分类能力,证明了本文算法具有通用性,在分类任务上是可行、有效的。
3.2 对象部件分割实验
点云对象部件分割是一项比点云分类更困难的任务,本文在普林斯顿大学等构建的ShapeNetPart数据集[27]上进行对象部件分割实验。该数据集包含16个类,每个类别2~6个部件,共有50个部件标签;共16 881个样本,其中训练集12 137个,验证集1 870个,测试集2 874个。
分别采用整体、局部两种方式与基准网络PointNet++结合,使用总体类别的平均交并比(mean Intersection over Union, mIoU)和所有实例平均IoU作为评价指标,并使用GFLOPs衡量模型的复杂度,以每秒处理样本数衡量网络推理速度。网络输入点数为2 048(将1 024个点看作一组样本),批处理大小为16,epoch为251。实验对比对象为SpiderCNN、SPLATNet(SParse LAttice Network) 3D[9]、SSCNN(Synchronized Spectral Convolutional Neural Networks)[10]、Point-PlaneNet[11]、PointNet、PointNet++(msg)[17]、DGCNN和3D-GCN[24],实验结果如表2所示。

表1 ScanObjectNN数据集上不同方法的分类性能对比
注:由于官方的PointNet++和RepSurf‑U‡并未给出推理速度的实验结果,表1中带*数据为本文复现结果。
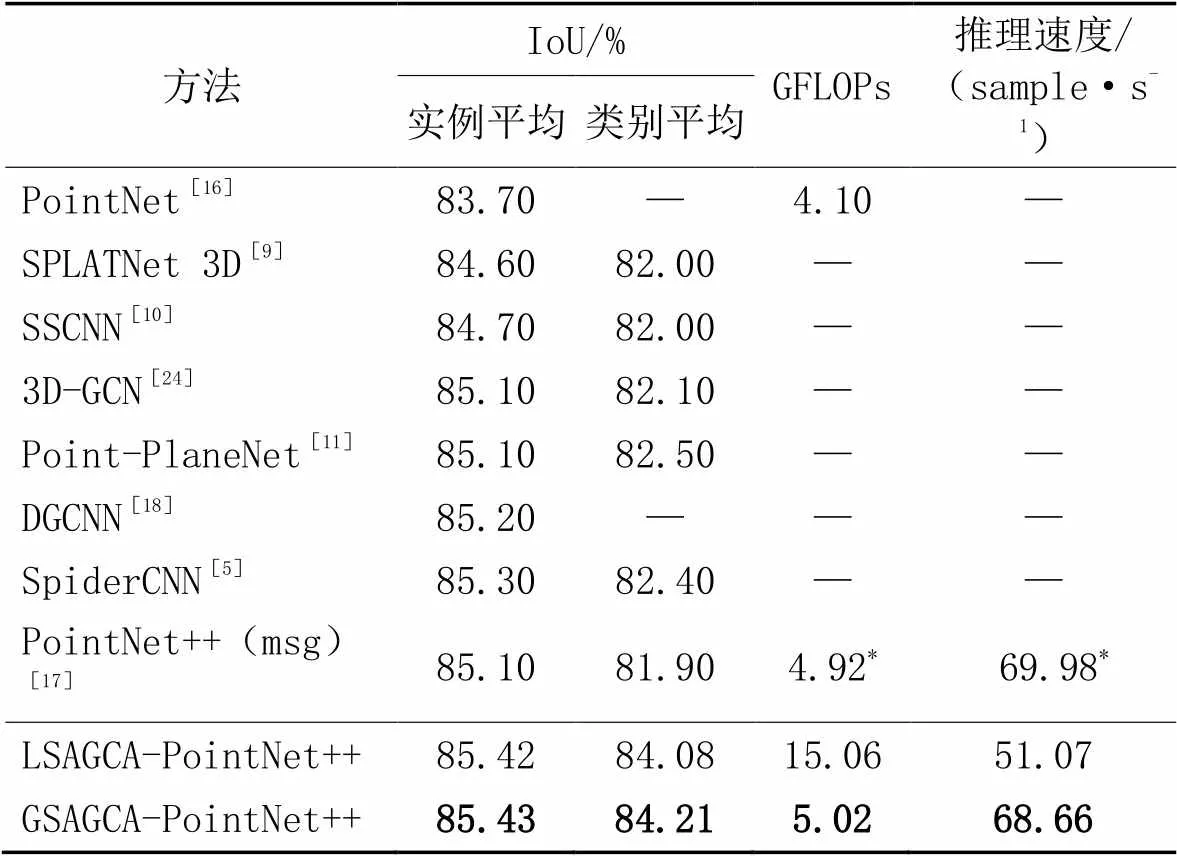
表2 ShapeNetPart数据集上不同方法的对象部件分割性能对比
注:由于官方的PointNet++(msg)[17]没有给出GFLOPs、推理速度的实验结果,表2中带*数据为本文复现结果。
由表2可知:
1)两种结合方式均能提升PointNet++(msg)[17]的对象部件分割精度,由于GSAGCA构建了整体组间的拓扑结构图,相较于LSAGCA构建的局部特征关系图,GSAGCA学习到的语义信息更强,故效果更佳;
2)GSAGCA-PointNet++充分挖掘了邻域间潜在的拓扑关系,学习到的整体上下文信息更丰富,使类别平均IoU(class average IoU)提高了2.31个百分点,虽然实例平均IoU (instance average IoU)提高并不明显,但两种指标与表中列举的其他方法相比,性能保持最优;
3)本文方法可以更好地分割物体对象的连接点,对类别信息之间的关系更敏感,故类别平均IoU指标提高更明显;
4)由于LSAGCA卷积核大小比GSAGCA大,导致网络模型卷积乘运算更复杂,故与GSAGCA结合后的网络GFLOPs更小,网络推理速度更大,且GSAGCA-PointNet++分割效果更好,两种算法相比,PointNet++(msg)与GSAGCA相结合更适合对象部件分割任务;
5)两种结合方式均降低了基准网络的推理速度,但与提高的分割性能相比,速度的降低程度在合理范围内。
图5给出了ShapeNetPart[27]数据集中耳机(Earphone)、吉他(Guitar)和摩托车(Motorbike)3个类别的对象部件分割可视化结果。由图中圆圈部分可知,基准网络忽略了点云数据特征之间的拓扑关系,对于类别对象细小部件的识别不够敏感,采用LSAGCA、GSAGCA均可以更好地分割物体部件的连接点,得到与原始数据更加接近的分割结果。

图5 ShapeNetPart数据集上的对象部件分割可视化结果
3.3 场景语义分割实验
大型室内场景点云数据的复杂程度高,且存在异常值和噪声,因此,场景语义分割任务更具挑战性。为了验证本文算法在此任务上的有效性,使用斯坦福大学构建的大规模场景数据集S3DIS[28],在PointNet++基准网络上分别采用两种结合方式进行实验。该数据集包含13类对象、11个场景,按文献[28]的方式使用Area-5作为测试场景,以便更好地衡量本文方法的泛化能力,其他区域均用于训练。
采用类别mIoU作为评价指标,并使用GFLOPs衡量模型的复杂度,以每秒处理样本数衡量网络推理速度。网络输入点数为4 096(将1 024个点看作一组样本),批处理大小为16,epoch为32。实验对比对象为SegCloud[12]、PointNet、PointNet++(msg)、3D-GCN和DeepGCN[25],实验结果如表3所示。
由表3可知:
1)两种结合方式均能提升网络的场景语义分割精度,但由于场景点云数据包含点量庞大,且对象类别较多,整体点云特征的拓扑关系对场景语义分割任务影响更大,故GSAGCA效果更佳;
2)与基准网络相比,GSAGCA-PointNet++学习获取整体组间的特征关系图,学习到的整体上下文信息更丰富,对于稀疏部分的点,构图能够更好地避免信息丢失,增强了网络对整体特征的学习能力,mIoU指标提高了2.40个百分点;
3)两种结合方式均降低了基准网络的推理速度,但均在合理范围内,两种算法相比,GSAGCA-PointNet++的GFLOPs更小,网络推理速度更大,更适合场景语义分割任务;
4)本文算法具有较强的描述能力和自主学习能力,对大型场景点云数据集也有不错的效果。
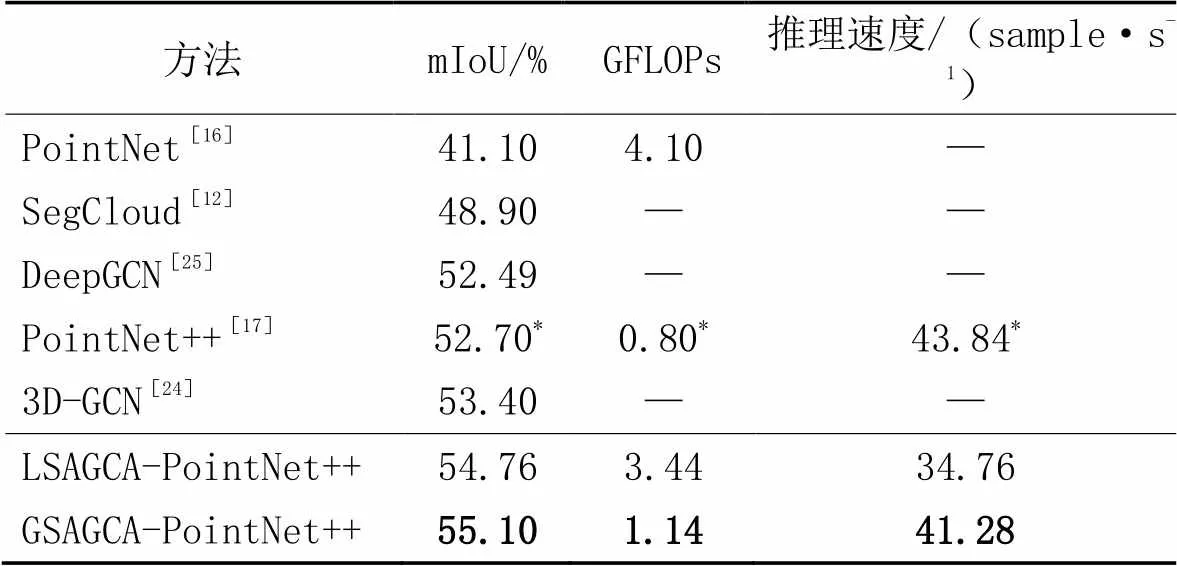
表3 S3DIS-Area5数据集上不同方法的场景语义分割性能对比
注:由于官方的PointNet++[17]并没有给出S3DIS‑Area5[28]实验结果,也没有给出GFLOPs、推理速度的实验结果,表3中带*数据为本文复现结果。
图6从正面(Front)、反面(Reverse)两个角度,依次给出了测试区域Area-5中WC1场景输入原始图、真实语义分割结果图以及场景语义分割的可视化结果图。由图中圆圈部分可知,PointNet++[17]基准网络对于部分区域的识别不准确,使用本文算法后,由于构建了点云特征间的拓扑关系图,增强了网络对于不规则的点云数据和分布稀疏的部分数据特征提取能力,可以更好地识别对象类别,得到与原始数据更加接近的分割结果,验证了本文算法的有效性。
3.4 消融实验
为了验证本文将孪生构图思想引入自适应图卷积算法(AGCA)的合理性,以PointNet++为基础网络,在S3DIS[28]数据集上进行场景语义分割实验,分别设计了局部点间的自适应图卷积算法(Local Adaptive Graph Convolutional Algorithm, LAGCA)和整体组间的自适应图卷积算法(Global Adaptive Graph Convolutional Algorithm, GAGCA),根据是否添加孪生(Siamese)思想,即是否共享卷积的权重矩阵,对AGCA进行消融实验。用Area-5作为测试场景,实验结果如表4所示。

表4 S3DIS-Area5数据集上的消融实验结果 单位: %
注:由于官方的PointNet++并没有给出S3DIS‑Area5实验结果,表4中带*数据为本文复现结果。
由表4可知:
1)非孪生LAGCA的mIoU指标降低了0.40个百分点,非孪生GAGCA的mIoU指标仅提高了0.76个百分点,可见构建有向的特征关系图,不能准确描述无序点云特征间的拓扑关系,分割效果提高不明显甚至可能起到反效果;
2)引入孪生构图思想后两种算法的mIoU指标分别提高了2.06和2.40个百分点,故LAGCA、GAGCA搭配孪生构图思想,分割效果均更佳;
3)本文提出的孪生自适应图卷积算法SAGCA通过引入共享卷积学习权重的孪生构图思想,能更好地学习表达点云数据特征间的拓扑关系,因此引入孪生构图思想是合理的。

图6 S3DIS-Area5数据集上的场景语义分割可视化结果
4 结语
本文引入共享卷积学习权重的孪生构图思想,提出了一种新的孪生自适应图卷积算法,通过整体、局部两种方式与多种网络的各个特征提取层相结合,从而学习构建无序点云特征间的自适应特征关系图,增强网络对特征的提取能力。将本文算法从整体、局部两个角度与基准网络结合,分别构建得到两种特征关系图,在网络提取特征方面均能发挥正面作用。针对三个公开数据集的实验结果表明,点云数据的分类、对象部件分割及场景语义分割精度均能得到提高。
由于两种特征关系图发挥作用的机制有所不同,今后可将两种方式同时与现有网络相结合,对两者的结合方式进行深入研究,并对更大的点云数据集或更具有挑战性的任务开展实验,进一步测试本文算法的有效性。
[1] 李朝,兰海,魏宪. 基于注意力的毫米波-激光雷达融合目标检测[J]. 计算机应用, 2021, 41(7): 2137-2144.(LI C, LAN H, WEI X. Attention-based object detection with millimeter wave radar-lidar fusion[J]. Journal of Computer Applications, 2021, 41(7): 2137-2144.)
[2] 付豪,徐和根,张志明,等. 动态场景下基于语义和光流约束的视觉同步定位与地图构建[J]. 计算机应用, 2021, 41(11): 3337-3344.(FU H, XU H G, ZHANG Z M, et al. Visual simultaneous localization and mapping based on semantic and optical flow constraints in dynamic scenes[J]. Journal of Computer Applications, 2021, 41(11): 3337-3344.)
[3] FAN T, ZHANG R. Research on automatic lane line extraction method based on onboard lidar point cloud data[C]// Proceedings of the SPIE 12306, 2nd International Conference on Digital Signal and Computer Communications. Bellingham, WA: SPIE, 2022: No.123060P.
[4] MIRZAEI K, ARASHPOUR M, ASADI E, et al. 3D point cloud data processing with machine learning for construction and infrastructure applications: a comprehensive review[J]. Advanced Engineering Informatics, 2022, 51: No.101501.
[5] XU Y, FAN T, XU M, et al. SpiderCNN: deep learning on point sets with parameterized convolutional filters[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11212. Cham: Springer, 2018: 90-105.
[6] LI Y, BU R, SUN M, et al. PointCNN: convolution on-transformed points[C]// Proceedings of the 32nd International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2018: 828-838.
[7] QIU S, ANWAR S, BARNES N. Dense-resolution network for point cloud classification and segmentation[C]// Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2021: 3812-3821.
[8] 史怡,魏东,宋强,等. 基于动态图卷积和离散哈特莱转换差异性池化的点云数据分类分割网络[J]. 计算机应用, 2022, 42(S1): 292-297.(SHI Y, WEI D, SONG Q, et al. Point cloud data classification and segmentation network based on dynamic graph convolution and discrete Hartley transform different pooling[J]. Journal of Computer Applications, 2021, 42(S1): 292-297.)
[9] SU H, JAMPANI V, SUN D, et al. SPLATNet: sparse lattice networks for point cloud processing[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 2530-2539.
[10] YI L, SU H, GUO X, et al. SyncSpecCNN: synchronized spectral CNN for 3D shape segmentation[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6584-6592.
[11] PEYGHAMBARZADEH S M M, AZIZMALAYERI F, KHOTANLOU H, et al. Point-PlaneNet: plane kernel based convolutional neural network for point clouds analysis[J]. Digital Signal Processing, 2020, 98: No.102633.
[12] TCHAPMI L, CHOY C, ARMENI I, et al. SEGCloud: semantic segmentation of 3D point clouds[C]// Proceedings of the 2017 International Conference on 3D Vision. Piscataway: IEEE, 2017: 537-547.
[13] LIN Z H, HUANG S Y, WANG Y C F. Convolution in the cloud: learning deformable kernels in 3D graph convolution networks for point cloud analysis[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 1897-1806.
[14] ZHOU Y, TUZEL O. VoxelNet: end-to-end learning for point cloud based 3D object detection[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 4490-4499.
[15] SHESHAPPANAVAR S V, KAMBHAMETTU C. SimpleView++: neighborhood views for point cloud classification[C]// Proceedings of the IEEE 5th International Conference on Multimedia Information Processing and Retrieval. Piscataway: IEEE, 2022: 31-34.
[16] QI C R, SU H, MO K, et al. PointNet: deep learning on point sets for 3D classification and segmentation[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 77-85.
[17] QI C R, YI L, SU H, et al. PointNet++: deep hierarchical feature learning on point sets in a metric space[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 5105-5114.
[18] WANG Y, SUN Y, LIU Z, et al. Dynamic graph CNN for learning on point clouds[J]. ACM Transactions on Graphics, 2019, 38(5): No.146.
[19] QIAN G, LI Y, PENG H, et al. PointNeXt: revisiting PointNet++ with improved training and scaling strategies[EB/OL]. (2022-10-12) [2022-12-29].https://arxiv.org/pdf/2206.04670.pdf.
[20] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 6000-6010.
[21] RAN H, LIU J, WANG C. Surface representation for point clouds[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 18942-18952.
[22] SCARSELLI F, GORI M, TSOI A C, et al. The graph neural network model[J]. IEEE Transactions on Neural Networks, 2008, 20(1): 61-80.
[23] KIPF T N, WELLING M. Semi-supervised classification with graph convolutional networks[EB/OL]. (2017-02-22) [2022-08-24].https://arxiv.org/pdf/1609.02907.pdf.
[24] LI G, MÜLLER M, QIAN G, et al. DeepGCNs: making GCNs go as deep as CNNs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(6): 6923-6939.
[25] SHI L, ZHANG Y, CHENG J, et al. Non-local graph convolutional networks for skeleton-based action recognition[EB/OL]. [2022-08-24].https://arxiv.org/pdf/1805.07694v2.pdf.
[26] UY M A, PHAM Q H, HUA B S, et al. Revisiting point cloud classification: a new benchmark dataset and classification model on real-world data[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 1588-1597.
[27] CHANG A X, FUNKHOUSER T, GUIBAS L, et al. ShapeNet: an information-rich 3D model repository[EB/OL]. [2022-08-25].https://arxiv.org/pdf/1512.03012.pdf.
[28] ARMENI I, SENER O, ZAMIR A R, et al. 3D semantic parsing of large-scale indoor spaces[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 1534-1543.
[29] PASZKE A, GROSS S, CHINTALA S, et al. Automatic differentiation in PyTorch[EB/OL]. [2023-01-01].https://openreview.net/pdf?id=BJJsrmfCZ.
[30] PANG Y, WANG W, TAY F E H, et al. Masked autoencoders for point cloud self-supervised learning[C]// Proceedings of the 2022 European Conference on Computer Vision, LNCS 13662. Cham: Springer, 2022: 604-621.
[31] MA X, QIN C, YOU H, et al. Rethinking network design and local geometry in point cloud: a simple residual MLP framework[EB/OL]. [2023-01-01].https://arxiv.org/pdf/2202.07123.pdf.
Point cloud classification and segmentation based on Siamese adaptive graph convolution algorithm
LI Weigang1,2, CHEN Ting1*, TIAN Zhiqiang1
(1,,430081,;2(),430081,)
Point cloud data has sparsity, irregularity, and permutation invariance, and lacks topological information, which makes it difficult to extract features of point cloud. Therefore, a Siamese Adaptive Graph Convolution Algorithm (SAGCA) was proposed for point cloud classification and segmentation. Firstly, the topological relationships between irregular and sparse point cloud features were mined by constructing feature relationship graph. Then, the Siamese composition idea of sharing convolution learning weights was introduced to ensure the permutation invariance of point cloud data and make the topological relationship expression more accurate. Finally, SAGCA was combined with various deep learning networks for processing point cloud data by both global and local combination methods, thereby enhancing the feature extraction ability of the network. Comparison results with PointNet++ benchmark network of the classification, object part segmentation and scene semantic segmentation experiments on ScanObjectNN, ShapeNetPart and S3DIS datasets, respectively, show that, based on the same dataset and evaluation criteria, SAGCA has the class mean Accuracy (mAcc) of classification increased by 2.80 percentage points, the overall class average Intersection over Union (IoU) of part segmentation increased by 2.31 percentage points, and the class mean Intersection over Union (mIoU) of scene semantic segmentation increased by 2.40 percentage points, verifying that SAGCA can effectively enhance the feature extraction ability of the network and is suitable for multiple point cloud classification and segmentation tasks.
point cloud data; topological relationship; Siamese; adaptive graph convolution; classification; segmentation
1001-9081(2023)11-3396-07
10.11772/j.issn.1001-9081.2022101552
2022⁃10⁃20;
2023⁃02⁃03;
湖北省重点研发计划项目(2020BAB098)。
李维刚(1977—),男,湖北咸宁人,教授,博士,主要研究方向:工业过程控制、人工智能、机器学习; 陈婷(1999—),女,湖北孝感人,硕士研究生,主要研究方向:深度学习、模式识别、点云数据处理; 田志强(1996—),男,湖北武汉人,博士研究生,主要研究方向:计算机视觉。
TP391.4
A
2023⁃02⁃08。
This work is partially supported by Key Research and Development Program of Hubei Province (2020BAB098).
LI Weigang, born in 1977, Ph. D., professor. His research interests include industrial process control, artificial intelligence, machine learning.
CHEN Ting, born in 1999, M. S. candidate. Her research interests include deep learning, pattern recognition, point cloud data processing.
TIAN Zhiqiang, born in 1996, Ph. D. candidate. His research interests include computer vision.
