融合卷积与多头注意力的人体姿态迁移模型
2023-11-29杨红张贺靳少宁
杨红,张贺,靳少宁
融合卷积与多头注意力的人体姿态迁移模型
杨红*,张贺,靳少宁
(大连海事大学 信息科学技术学院,辽宁 大连 116026)( ∗ 通信作者电子邮箱yanghong@dlmu.edu.cn)
对于给定某个人物的参考图像,人体姿态迁移(HPT)的目标是生成任意姿态下的该人物图像。许多现有的相关方法在捕捉人物外观细节、推测不可见区域方面仍存在不足,特别是对于复杂的姿态变换,难以生成清晰逼真的人物外观。为了解决以上问题,提出一种新颖的融合卷积与多头注意力的HPT模型。首先,融合卷积与多头注意力机制构建卷积-多头注意力(Conv-MHA)模块,提取丰富的上下文特征;其次,利用Conv-MHA模块构建HPT网络,提升所提模型的学习能力;最后,引入参考图像的自我重建作为辅助任务,更充分地发挥所提模型的性能。在DeepFashion和Market-1501数据集上验证了基于Conv-MHA的HPT模型,结果显示:它在DeepFashion测试集上的结构相似性(SSIM)、感知相似度(LPIPS)和FID(Fréchet Inception Distance)指标均优于现有的HPT模型DPTN (Dual-task Pose Transformer Network)。实验结果表明,融合卷积与多头注意力机制的Conv-MHA模块可以提升模型的表示能力,更加有效地捕捉人物外观细节,提升人物图像生成的精度。
人体姿态迁移;图像生成;生成对抗网络;多头注意力;卷积
0 引言
图像生成是计算机视觉领域的一个重要分支,而人体姿态迁移(Human Pose Transfer, HPT)是图像生成任务的重要实例。HPT又可以称为姿态引导的人物图像生成(Pose-Guided Person Image Generation, PGPIG),它是指给定某个人物的参考图像作为外观条件,合成任意姿态下该人物的图像。HPT在虚拟现实、电影制作、数据增强等领域中具有极大的应用价值。例如,行人重识别问题中可以利用HPT获取更多人物数据。尽管生成对抗网络[1]、变分自编码器[2]等深度生成模型发展迅速,但HPT任务仍面临挑战。姿态变化会导致图像中人物的纹理细节和几何形状发生变化,特别是复杂的姿态变化,其中还存在人体自遮挡问题。成功的HPT要求模型具有很好的人物姿态与外观表示能力。为保持生成图像的逼真度,模型需要推测不可见区域,捕捉人物外观细节,比如形状、衣服纹理、面部。
早期研究[3-4]利用普通卷积网络构建生成器,难以执行复杂的姿态变换。为此,引入光流估计[5-6]、人体语义分割图[7-8]和注意力机制[9-10]以提升模型的转换能力,其中借助光流估计和人体语义分割图会大幅增加数据预处理和模型的复杂度,且光流估计和人体语义分割图的预测偏差会误导生成器。此外,这些方法仅仅聚焦于参考图像到目标图像的转换任务,这对于训练一个鲁棒的生成器较为困难。最近,Zhang等[11]提出利用一个辅助任务来提升参考图像到目标图像的转换效果,即让生成器以参考图像和参考图像本身具有的原始姿态为输入重构该人物的参考图像,并利用Transformer[12]块构建模块解析辅助任务与主任务之间的相关性以增强目标图像的生成效果。但是,此项工作使用普通卷积实现特征转换,在捕捉纹理细节、生成清晰准确的形状轮廓方面表现不佳。
注意力机制可以选择性地突出重要的特征信息,抑制不必要的特征。一些研究[13-16]在卷积神经网络加入注意力机制,提升模型的表征能力,在视觉识别任务中取得了不错的效果。随着利用注意力机制实现的Transformer在自然语言处理领域取得巨大成功,视觉Transformer(Vision Transformer, ViT)[17]提出将Transformer架构应用到计算机视觉任务中。并有一些研究[18-20]对ViT进行改进,提出了不同方式的局部自注意力机制,以降低自注意力机制导致的计算复杂度,但也一定程度上减弱了模型捕捉全局表示的能力。此外,Transformer未引入与卷积网络一样丰富的归纳偏置,它的泛化性比卷积网络差。Transformer的核心在于注意力机制,为了融合卷积与注意力机制的优点,CoTNet(Contextual Transformer Network)[21]提出将普通卷积与局部自注意力机制融合,但忽略了全局表示。普通卷积擅长局部特征提取,但是难以捕捉全局特征;全局注意力机制可以获取全局表示,但是可能会丢失特征细节。CoAtNet[22]和ACmix(a mixed model of self-Attention and Convolution)[23]分析卷积与自注意力机制的相似点,提出了卷积与自注意力机制的并行融合方式,提升了视觉识别效果;但这种并行融合方式不利于发挥二者的互补优势。
本文借鉴CoTNet[21]的思想,构建了一种新颖的网络模块——卷积-多头注意力(Convolution-Multi-Head Attention, Conv-MHA)模块,通过融合卷积与全局多头注意力机制来融合局部特征表示和全局特征表示,改善HPT模型的细节保留,提升生成图像的保真度。Conv-MHA模块利用普通卷积提取局部特征,利用多头注意力机制提取全局特征,二者以串行方式处理输入,并采用一种动态选择机制[14]融合局部特征与全局特征。考虑到全局注意力机制中全局交互导致的平方级计算复杂度,在模型构建中,本文采用普通卷积网络构建编码器和解码器,使用若干个Conv-MHA模块以级联的方式实现中间转换。进一步地,本文引入参考图像的自我重建作为辅助任务[11],并利用Conv-MHA构建解析模块解析辅助分支和主分支之间的相关性,以对主分支进行特征增强,提升图像生成质量。
1 相关工作
1.1 人体姿态迁移
Ma等[3]采用二阶段生成器以由粗到细的方式生成人物图像;Esser等[4]利用变分自编码器获得人物外观的潜在表示,以此作为U-Net[24]的条件输入进行图像生成。但是这些基于普通卷积网络的方法难以有效处理复杂姿态变换。为解决这个问题,Zhu等[10]提出了姿态注意力转移网络(Pose Attention Transfer Network, PATN),通过原始姿态与目标姿态的相关性渐进式地生成人物图像。此外,XingGAN[9]对PATN进一步改进,利用具有交叉连接的两个分支渐进式地生成人物形状与外观,并利用基于注意力的方法融合人物形状与外观以生成人物图像。尽管如此,这些基于注意力机制的方法仍不能有效建模不同姿态间的变换,会导致纹理细节的丢失与不恰当的形变。
为了改进姿态迁移效果,DIAF(Dense Intrinsic Appearance Flow)[5]、DIST(Deep Image Spatial Transformation)[6]提出借助光流估计更好地指导姿态转移。这种方式需要首先预测光流,但是对于复杂的姿态变换和存在遮挡的情况,这种方式难以产生准确的光流,进而误导图像生成。除此之外,SPIG(Semantic Person Image Generation)[7]、PISE(Person Image Synthesis and Editing)[8]借助人体语义分割图辅助HPT。这些是二阶段的方法,它们首先预测目标姿态下的人体语义分割图,然后以此提供语义信息,提升图像生成质量。但是预测目标姿态下的人体语义分割图通常是不稳定的,会误导人物图像生成;而且这些方法前期数据预处理更复杂,不利于此类模型的应用。DPTN(Dual-task Pose Transformer Network)[11]提出引入参考图像的自我重建作为辅助任务,并构建连体结构,利用Transformer模块探究辅助任务与主任务的相关性,以更好地建模不同姿态下的图像变换;但是,该模型的主干使用的是普通卷积网络,难以有效处理复杂的形变特征。
1.2 计算机视觉中的注意力机制
ViT提出将Transformer架构应用到计算机视觉任务中,但由于自注意力机制的平方级计算复杂度,原始Transformer架构难以处理高分辨率图像。为了降低复杂度,Swin-Transformer[18]、HaloNet[20]、CSwin-Transformer[19]借鉴普通卷积中的滑动窗口思想,构建局部自注意力机制,将注意力的计算限制在窗口内;但这在一定程度上削弱了模型捕捉全局特征表示的能力。对于图像生成任务,Jiang等[25]构建了一个基于纯Transformer架构的生成对抗网络;Hudson等[26]提出了GANsformer(Generative Adversarial Transformers),利用潜在变量中的信息细化图像特征。但是这两种方法并不适合复杂的有条件图像生成,比如HPT。DPTN[11]基于Transformer构建解析模块用于探究双任务的相关性,提升图像生成质量。然而,ViT未引入与卷积网络一样丰富的归纳偏置,导致泛化性比卷积网络差。因此,有研究者提出将二者融合。CoTNet融合了静态卷积与局部自注意力机制,但忽略了全局表示;CoAtNet和ACmix提出了卷积与自注意力机制的并行结合方法,在视觉任务上取得了不错的表现;但这种并行结合方式不利于发挥二者的互补优势,限制了模型性能。
综上所述,现有HPT方法在建模不同姿态间的变换、捕捉人物外观细节方面仍有不足,特别是对于复杂的姿态变换。与现有方法不同,本文借鉴CoTNet的思想,构建了一种新型的融合卷积与多头注意力机制的网络模块——Conv-MHA,并将它应用到HPT任务中,旨在提升模型的表示能力,以更好地捕捉人物外观细节,提升人物图像生成质量。最后通过实验验证了所提方法对于HPT任务的有效性。
2 模型设计
本文通过构建的Conv-MHA模块获得更加丰富的特征表示。为了充分发挥该模块的潜力,参考文献[11]构建生成器网络,引入参考图像的重建作为辅助,并构建相关性解析模块解析参考图像重建与目标图像生成之间的相关性,以生成更清晰、更高保真度的对应人物图像。模型的整体架构如图1所示。

图1 本文模型架构示意图
2.1 生成器网络
本文模型基于生成对抗网络框架构建,其中,生成器网络参考DPTN,除了生成目标图像的主分支外,额外构建了一个参考图像的自我重建作为辅助分支,并且在主分支中利用辅助分支的中间特征信息增强主分支的转换。与之不同的是,本文采用Conv-MHA模块实现特征转换和相关性解析模块构建。

2.1.1Conv-MHA模块
卷积和注意力机制是获取特征表示的两种有效方法,它们在本质上截然不同。普通卷积利用重要的归纳偏置,通过权值共享和局部感受域进行图像处理,擅长提取底层特征和视觉结构,但是难以捕捉远距离依赖信息,缺乏对数据本身的整体把握;而注意力机制通过全局交互可以挖掘远距离依赖关系,获取全局信息,对于高层语义特征的提取更具有优势。
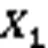
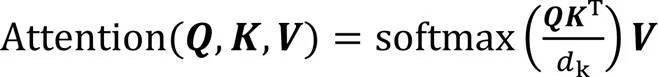


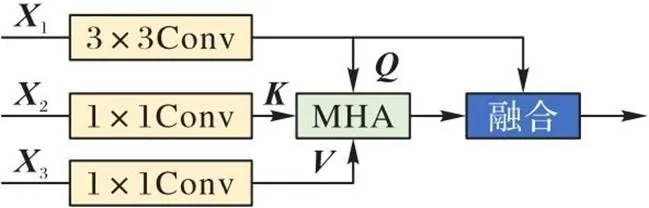
图2 Conv-MHA模块结构
2.1.2相关性解析模块
相关性解析模块在辅助分支与主分支之间起连接作用。与文献[11]的方法不同,本文采用Conv-MHA模块构建相关性解析模块,解析主分支与辅助分支的内在相互关联,并以此增强主分支中的特征转换。相关性解析模块如图3所示。

图3 相关性解析模块结构
2.2 损失函数
该模型的损失函数可以表述为:
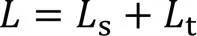

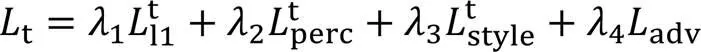
具体来说,L1损失利用L1距离惩罚生成图像和实际真实图像之间的差异:

感知损失[27]计算真实图像与生成图像之间的特征距离,惩罚内容差异:
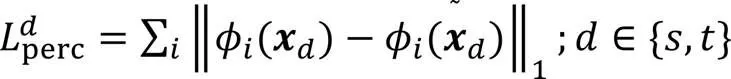
风格损失[27]比较真实图像与生成图像间的风格相似度,惩罚风格差异:

对抗损失利用判别器D惩罚生成图像与真实图像之间的分布差异,本文采用了PatchGAN[29]的方法,将图像输入全卷积网络得到一个概率矩阵,矩阵中的每一个值对应图像中的一块区域,这样可以更加细致地判别,使模型更关注图像细节。为了使训练更稳定,本文使用WGAN-GP[30]中的对抗损失函数:


3 实验与结果分析
3.1 数据集

3.2 评估指标
参考之前的工作[7,10-11],本文采用结构相似性(Structural SIMilarity, SSIM)指数[34]、峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)、FID (Fréchet Inception Distance)[35]、感知相似度(Learned Perceptual Image Patch Similarity, LPIPS)[36]作为评估指标。SSIM从结构、亮度、对比度三个方面评估生成图像与真实图像的相似程度;PSNR计算生成图像与真实图像的像素差异;FID计算生成图像与真实图像数据分布间的距离,衡量图像的真实程度;LPIPS衡量生成图像与真实图像在感知层面上的距离。
3.3 实验细节

本实验的硬件环境:CPU是AMD EPYC 7551P,GPU是RTX 3090-24G。软件环境是Ubuntu 20.04,CUDA 11.1,使用Python 3.8进行编程,采用PyTorch 1.8深度学习框架实现。
3.4 消融实验

此外,还分别用CoT[21]模块和Transformer模块替换模型中的卷积-多头注意力模块进行了对比,对比结果如表1和图5所示,最优和次优结果分别通过粗体和下画线表示。
依据评估结果对比,采用CoT的生成结果容易产生形变和细节缺失 ,并且衣服颜色存在略微的差别。CoT融合普通卷积与局部自注意力机制,虽然在图像分类上取得了不错的效果,但是并不适合HPT任务。采用Transformer模块取得了相较于CoT更优的指标,且能够生成更加准确的形状轮廓。结合卷积与多头注意力机制的方案,在量化指标上表现更优,生成结果中具有更完善的细节,表明将二者结合对于提升HPT是重要且有效的。方案(b)和(c)相较于方案(a)表现进一步提升,串行结构优于并行结构,基于动态选择机制的融合方式优于逐元素相加的融合方式。通过比较方案(b)和(c)可以看出,串行结构带来的性能提升明显大于基于动态选择机制的融合方式。方案(a)、(b)、(c)的生成结果存在一定程度的形变。而方案(d)通过串行结构和动态选择机制可以使卷积和多头注意力机制相互作用,互补短板,提升整体性能,使模型能够生成更加清晰准确的形状和轮廓,更加接近于真实图像的颜色和纹理图案。

3.5 与现有方法对比
将本文模型与几个先进的方法进行了比较,包括:PG2[3]、PATN[10]、ADGAN[38]、DIST[6]、PISE[8]、SPIG[7]和DPTN[11]。表3展示了对比结果,最优和次优结果分别通过粗体和下画线表示。由表3数据可知,在DeepFashion数据集上,改进后的模型在SSIM和LPIPS两项指标上均优于其他模型,相较于DPTN,SSIM指标提升了0.206%,LPIPS指标下降了1.073%,FID指标下降了2.882%,也取得了优于DPTN的表现,在PSNR指标上也有较优的表现。在Market-1501数据集上,本文方法在SSIM和PSNR两项指标上优于DPTN,且在PSNR指标上表现最优,在LPIPS指标上具有次优表现。上述结果对比验证了本文方法对于生成高质量图像的有效性,且更适合较高分辨率的图像生成。

图4 四种不同的Conv-MHA模块设计方案

图5 不同模块的定性比较
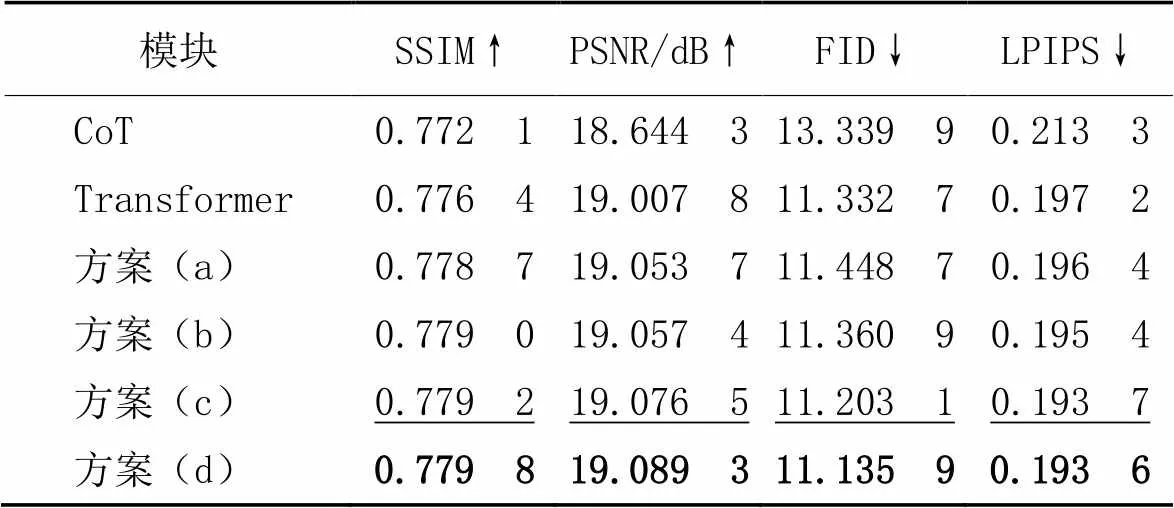
表1 不同模块的量化评估
定性比较如图6所示。PATN、ADGAN容易产生模糊扭曲的结果。DIST借助光流估计改善生成图像中的人物外观细节,但是对于复杂的姿态变换,容易产生细节丢失。PISE和SPIG通过预测语义分割图辅助HPT,但是语义分割图的预测容易产生误差,会误导人物图像生成,如图6中的前5行,生成图像中有与真实图像明显不符的衣服形状。DPTN借助辅助任务改进了HPT模型,但模型的上下文表示能力限制了图像生成质量。本文方法通过融合卷积与多头注意力机制的方式,能更好地捕捉上下文特征,生成更贴近真实图像的形状轮廓和纹理细节。

表2 注意力头数量的量化评估

表3 不同模型的结果对比

图6 不同模型的定性比较
4 结语
为了提高HPT模型的图像生成精度,本文构建了一种新颖的融合卷积与多头注意力机制的网络块,并利用该网络块参与实现了HPT模型。该网络块既可以提取局部上下文信息,也可以提取全局上下文信息,并以自适应的方式将二者融合。实验结果表明,本文方法可以更好地捕捉不同姿态下的外观映射,生成更加真实的人物细节。姿态的变换可能会导致人物图像发生较大的形状变化和纹理细节变化,特别是对于复杂的姿态变换。如果仅考虑局部范围内的特征交互,容易产生不恰当的形变和细节丢失,而融入全局特征交互可以解决这一问题。然而本文方法仍然存在一定的局限性,比如在生成较为复杂的衣服纹理方面表现出不足。未来的研究中,将寻求方法对生成图像中人物的不同区域部位进行细化处理。
[1] GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[C]// Proceedings of the 27th International Conference on Neural Information Processing Systems — Volume 2. Cambridge: MIT Press, 2014: 2672-2680.
[2] KINGMA D P, WELLING M. Auto-encoding variational Bayes[EB/OL]. (2022-12-10) [2023-03-17].https://arxiv.org/pdf/1312.6114.pdf.
[3] MA L, JIA X, SUN Q, et al. Pose guided person image generation[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 405-415.
[4] ESSER P, SUTTER E. A variational U-Net for conditional appearance and shape generation[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 8857-8866.
[5] LI Y, HUANG C, LOY C C. Dense intrinsic appearance flow for human pose transfer[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 3688-3697.
[6] REN Y, YU X, CHEN J, et al. Deep image spatial transformation for person image generation[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 7687-7696.
[7] LV Z, LI X, LI X, et al. Learning semantic person image generation by region-adaptive normalization[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 10801-10810.
[8] ZHANG J, LI K, LAI Y K, et al. PISE: person image synthesis and editing with decoupled GAN[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 7978-7986.
[9] TANG H, BAI S, ZHANG L, et al. XingGAN for person image generation[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12370. Cham: Springer, 2020: 717-734.
[10] ZHU Z, HUANG T, SHI B, et al. Progressive pose attention transfer for person image generation[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 2342-2351.
[11] ZHANG P, YANG L, LAI J, et al. Exploring dual-task correlation for pose guided person image generation[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 7703-7712.
[12] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 6000-6010.
[13] HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7132-7141.
[14] LI X, WANG W, HU X, et al. Selective kernel networks[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 510-519.
[15] WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11211. Cham: Springer, 2018: 3-19.
[16] SRINIVAS A, LIN T Y, PARMAR N, et al. Bottleneck Transformers for visual recognition[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 16514-16524.
[17] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: Transformers for image recognition at scale[EB/OL]. (2021-06-03) [2022-06-17].https://arxiv.org/pdf/2010.11929.pdf.
[18] LIU Z, LIN Y, CAO Y, et al. Swin Transformer: hierarchical vision Tansformer using shifted windows[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 9992-10002.
[19] DONG X, BAO J, CHEN D, et al. CSWin Transformer: a general vision Transformer backbone with cross-shaped windows[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 12114-12124.
[20] VASWANI A, RAMACHANDRAN P, SRINIVAS A, et al. Scaling local self-attention for parameter efficient visual backbones[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 12889-12899.
[21] LI Y, YAO T, PAN Y, et al. Contextual Transformer networks for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2004, 45(2): 1489-1500.
[22] DAI Z, LIU H, LE Q V, et al. CoAtNet: marrying convolution and attention for all data sizes[C]// Proceedings of the 35th Conference on Neural Information Processing Systems (2021) [2022-06-17].https://proceedings.neurips.cc/paper_files/paper/2021/file/20568692db622456cc42a2e853ca21f8-Paper.pdf.
[23] PAN X, GE C, LU R, et al. On the integration of self-attention and convolution[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 805-815.
[24] RONNEBERGER O, FISCHER P, BROX T. U-net: convolutional networks for biomedical image segmentation[C]// Proceedings of the 2015 International Conference on Medical Image Computing and Computer-Assisted Intervention, LNCS 9351. Cham: Springer, 2015: 234-241.
[25] JIANG Y, CHANG S, WANG Z. TransGAN: two pure transformers can make one strong GAN, and that can scale up[C]// Proceedings of the 35th Conference on Neural Information Processing Systems (2021) [2022-06-17].https://proceedings.neurips.cc/paper_files/paper/2021/file/7c220a2091c26a7f5e9f1cfb099511e3-Paper.pdf.
[26] HUDSON D A, ZITNICK C L. Generative adversarial transformers[C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 4487-4499.
[27] JOHNSON J, ALAHI A, LI F F. Perceptual losses for real-time style transfer and super-resolution[C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9906. Cham: Springer, 2016: 694-711.
[28] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. (2015-04-10) [2022-06-17].https://arxiv.org/pdf/1409.1556.pdf.
[29] ISOLA P, ZHU J Y, ZHOU T, et al. Image-to-image translation with conditional adversarial networks[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 5967-5976.
[30] GULRAJANI I, AHMED F, ARJOVSKY M, et al. Improved training of Wasserstein GANs[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 5769-5779.
[31] LIU Z, LUO P, QIU S, et al. DeepFashion: powering robust clothes recognition and retrieval with rich annotations[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 1096-1104.
[32] ZHENG L, SHEN L, TIAN L, et al. Scalable person re-identification: a benchmark[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 1116-1124.
[33] CAO Z, SIMON T, WEI S E, et al. Realtime multi-person 2D pose estimation using part affinity fields[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 1302-1310.
[34] WANG Z, BOVIK A C, SHEIKH H R, et al. Image quality assessment: from error visibility to structural similarity[J]. IEEE Transactions on Image Processing, 2004, 13(4): 600-612.
[35] HEUSEL M, RAMSAUER H, UNTERTHINER T, et al. GANs trained by a two time-scale update rule converge to a local Nash equilibrium[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 6629-6640
[36] ZHANG R, ISOLA P, EFROS A A, et al. The unreasonable effectiveness of deep features as a perceptual metric[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 586-595.
[37] KINGMA D P, BA J L. Adam: a method for stochastic optimization[EB/OL]. (2017-01-30) [2022-06-17].https://arxiv.org/pdf/1412.6980.pdf.
[38] MEN Y, MAO Y, JIANG Y, et al. Controllable person image synthesis with attribute-decomposed GAN[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 5083-5092.
Human pose transfer model combining convolution and multi-head attention
YANG Hong*, ZHANG He, JIN Shaoning
(,,116026,)
For a given reference image of a person, the goal of Human Pose Transfer (HPT) is to generate an image of that person in any arbitrary pose. Many existing related methods fail to capture the details of a person’s appearance and have difficulties in predicting invisible regions, especially for complex pose transformation, and it is difficult to generate a clear and realistic person’s appearance. To address the above problems, a new HPT model that integrated convolution and multi-head attention was proposed. Firstly, the Convolution-Multi-Head Attention (Conv-MHA) block was constructed by fusing the convolution and multi-head attention, then it was used to extract rich contextual features. Secondly, to improve the learning ability of the proposed model, the HPT network was constructed by using Conv-MHA block. Finally, the self-reconstruction of the reference image was introduced as an auxiliary task to make the model more fully utilized its performance. The Conv-MHA-based human pose transfer model was validated on DeepFashion and Market-1501 datasets, and the results on DeepFashion test dataset show that it outperforms the state-of-the-art human pose transfer model, DPTN (Dual-task Pose Transformer Network), in terms of Structural SIMilarity (SSIM), Learned Perceptual Image Patch Similarity (LPIPS) and FID (Fréchet Inception Distance) indicators. Experimental results show that the Conv-MHA module, which integrates convolution and multi-head attention mechanism, can improve the representation ability of the model, capture the details of person’s appearance more effectively, and improve the accuracy of person image generation.
Human Pose Transfer (HPT); image generation; generative adversarial network; multi-head attention; convolution
1001-9081(2023)11-3403-08
10.11772/j.issn.1001-9081.2022111707
2022⁃11⁃18;
2022⁃12⁃25;
杨红(1977—),女,辽宁葫芦岛人,副教授,博士,主要研究方向:数据挖掘、行为识别; 张贺(1998—),男,山东临沂人,硕士研究生,主要研究方向:图像生成、深度生成模型; 靳少宁(1996—),女,甘肃静宁人,硕士研究生,主要研究方向:步态识别、人工智能。
TP183
A
2022⁃12⁃28。
YANG Hong, born in 1977, Ph. D., associate professor. Her research interests include data mining, behavior recognition.
ZHANG He, born in 1998, M. S. candidate. His research interests include image generation, deep generative models.
JIN Shaoning, born in 1996, M. S. candidate. Her research interests include gait recognition, artificial intelligence.
