融合特征选择的随机森林DDoS攻击检测
2023-11-29徐精诚陈学斌董燕灵杨佳
徐精诚,陈学斌*,董燕灵,杨佳
融合特征选择的随机森林DDoS攻击检测
徐精诚1,2,3,陈学斌1,2,3*,董燕灵1,2,3,杨佳1
(1.华北理工大学 理学院,河北 唐山 063210; 2.河北省数据科学与应用重点实验室(华北理工大学),河北 唐山 063210; 3.华北理工大学 唐山市数据科学重点实验室,河北 唐山 063210)( ∗ 通信作者电子邮箱chxb@qq.com)
现有基于机器学习的分布式拒绝服务(DDoS)攻击检测方法在面对愈发复杂的网络流量、不断升维的数据结构时,检测难度和成本不断上升。针对这些问题,提出一种融合特征选择的随机森林DDoS攻击检测方法。该方法选用基于基尼系数的平均不纯度算法作为特征选择算法,对DDoS异常流量样本进行降维,以降低训练成本、提高训练精度;同时将特征选择算法嵌入随机森林的单个基学习器,将特征子集搜索范围由全部特征缩小到单个基学习器对应特征,在提高两种算法耦合性的同时提高了模型精度。实验结果表明,融合特征选择的随机森林DDoS攻击检测方法训练所得到的模型,在限制决策树棵数和训练样本数量的前提下,召回率相较于改进前提升21.8个百分点,F1-score值提升12.0个百分点,均优于传统的随机森林检测方案。
分布式拒绝服务;特征选择;基尼系数;平均不纯度算法;随机森林算法
0 引言
分布式拒绝服务(Distributed Denial-of-Service, DDoS)攻击[1]是一种常见的网络攻击方式,具有发动成本低、溯源难度高的特点。近年来DDoS勒索攻击频频出现,据绿盟科技联合腾讯安全发布的《2021年全球DDoS威胁报告》[2]统计,2019年至今,全球DDoS每年攻击次数翻倍并仍在持续增长,攻击带宽也在不断提高,峰值瞬时流量甚至可以达到2.4 TB。愈加频繁的DDoS攻击已经成为企业无法忽视的一大威胁。
当今国内外提出的DDoS攻击检测方法主要可以分为以下几种:基于数理统计进行检测、根据流量特征进行匹配和利用机器学习算法建模检测[3]。前两种方式需要预先制定规则,面对突发流量时识别率较低,对瞬息万变的网络环境适应性较差,而基于机器学习算法的DDoS攻击检测方法具有识别率高、适应性强等优点,吸引了众多学者从事相关研究。Suthaharan[4]使用多层感知机(MultiLayer Perceptron, MLP)算法对自主采集的DDoS攻击数据集进行检测,达到了98.6%的准确率;但因算法本身复杂度过高,无法保证实时性。Jia等[5]提出混合随机森林(Random Forest, RF)、K-最近邻(K-Nearest Neighbor, KNN)算法的集成学习DDoS攻击检测模型,再次提升了准确率;但模型结果趋向于中值而非最优解,模型稳定性有待提升。Najafimehr等[6]提出了一种混合聚类算法和分类算法的检测策略,使用CICIDS 2017作为训练集构建模型,在CICIDS 2019数据集上取得了良好的预测准确率,为DDoS攻击检测方向提供了一个新思路;但算法本身复杂度较高,实时性难以保证。孟曈[7]提出了一种基于机器学习与可逆sketch的DDoS攻击检测方法,明显提高了攻击检测的实时性,但模型识别精度仍有待提升。
作为一种数据预处理方法,特征选择可以提高对高维小样本数据集的预测精度,防止“维度灾难”和过拟合。基于机器学习的DDoS攻击检测通常需要在复杂网络环境下实时训练模型,采样获得的数据往往符合高维小样本这一特征,因而整个检测流程中十分依赖特征选择,国内外也有很多相关研究。Osanaiye等[8]使用多种评估器对DDoS攻击流量进行特征排序,取前1/3作为训练用特征,这一方法显著提高了训练效率和模型精度;但选取的特征并不通用,鲁棒性较差。Gu等[9]提出了一种基于混合特征选择的半监督DDoS攻击检测算法(Semi-supervised weighted K-means Method using Hybrid Feature Selection algorithm, SKM-HFS),将K-means算法与混合特征选择算法(Hybrid Feature Selection, HFS)相结合,对流量特征进行排序以获得特征子集,提高了预测精度;但算法复杂度较高,实时性较差。
随机森林(RF)是一种主流的集成学习算法,具有简单、泛化能力强、抗过拟合能力强等优点,被广泛应用到异常流量检测领域。Pande等[10]提出了一种基于改进RF算法的DDoS攻击检测模型,分类准确率达到了99.76%,验证了该算法的可行性与高效性。Cheng等[11]提出了一种基于流相关度特征的遗传算法优化的增强RF方法,根据不对称和半定向交互特征定义了流相关度特征,进行了特征升维;但是该算法较为复杂,训练成本较高。
本文提出了一种基于融合特征选择的随机森林DDoS攻击检测方法,与常规随机森林[12-13]模型训练流程中先进行特征选取再进行Bootstrap采样[14]不同,本文方法采用了先采样再根据具体采样数据集本身特点进行特征选择的策略,从纵向的数据和横向的特征两个角度出发,提高了攻击检测的实时性与模型的精确度。
本文的主要工作包括:1)在RF算法的基础上提出了一种改进的特征选择策略,将特征选择步骤细化到单棵决策树,提高了模型训练精度;2)将两种基于平均不纯度的特征选择算法分别与RF融合,构建了性能较好的DDoS攻击检测模型;3)提出的融合特征选择的随机森林算法收敛速度大幅提升,相比改进前,能够以更低的训练成本得到高精度模型。
1 相关知识
1.1 DDoS攻击原理
DDoS攻击由拒绝服务(Denial of Service, DoS)攻击演化而来,恶意人员首先需要操作控制大量僵尸主机集群,向目标服务器或者目标网络发送大量的攻击流量,消耗网络的带宽资源或者目标主机的计算资源,使目标网络在攻击流量下发生拥塞或无法向正常的用户提供服务甚至宕机。它是一种简单高效的攻击方式,能够十分轻易地对目标网络或者主机造成严重的影响,且攻击迅猛,防御与溯源追踪都很困难。DDoS攻击方式如图1所示。

图1 DDoS攻击示意图
DDoS攻击类型多种多样,主要有泛洪攻击、挑战黑洞(ChallengeCollapsar, CC)攻击、分布式反射(Distributed Reflection Denial Of Servie, DrDOS)攻击等。泛洪攻击通常分为传输控制协议(Transmission Control Protocol, TCP)泛洪和用户数据报协议(User Datagram Protocol, UDP)泛洪两种。TCP泛洪攻击是指利用TCP的握手流程发起虚假连接请求,以消耗目标主机资源的攻击方式,可再次分为SYN泛洪攻击和ACK泛洪攻击。CC攻击也称挑战黑洞攻击,是基于应用层的攻击,通过不断向目标主机发送POST/GET请求,引发巨量瞬时数据库操作,消耗主机资源;但CC的攻击模式明显,相对易于防御。DrDOS攻击是通过向攻击主机发送带有目标主机IP的少量数据包,攻击主机根据收到请求向目标主机返回大量数据包,以小流量换取大流量,也称之为放大攻击,一直是攻击流量的主力军。根据《2021年全球DDoS威胁报告》,100 GB以上的大流量攻击手法除了主流的SYN大包和UDP反射,ACK泛洪、TCP反射、SYN小包等攻击手法占比也逐渐上升,大流量攻击手段逐渐呈多元化趋势。
1.2 随机森林算法
RF算法是一种基于决策树的组合分类器,属于集成学习中Bagging的一个变体,它选取分类与回归树(Classification And Regression Tree, CART)[15]作为基学习器,引入Bagging算法[16]对数据集和特征从横向纵向两个角度进行Bootstrap采样,横向采样可以获得特征相同且互有交集的多个训练子集,减少了单个决策树的样本数量,进而训练多个单独决策树分类器,最终构建组合模型,大幅提升了模型的准确率和稳定性,算法伪代码如下:
算法1 RF算法。
5) end for
9) end for
1.3 特征选择算法
特征选择作为机器学习中一种重要的数据预处理手段,能够有效提升高维小样本数据集的训练效果。本文模型采用集成学习中Bagging的训练方案,单个树模型中样本量大幅减少,而特征数量维持不变,使用特征选择算法缩小RF算法对特征的Bootstrap采样范围,能够明显提升模型训练精度。
常规的特征选择算法[17]主要分为四种:过滤式、封装式、嵌入式和集成式。过滤式也称fliter,又可以分为基于特征排序和基于搜索策略两类:前者通过算法计算特征权重进行特征排序,常见算法有Relief[18]、Fisher得分[19]、Person相关系数等;后者则是通过搜索算法进行特征子集筛选,相比前者更易获得全局最优解,但训练成本更高。封装式也称wrapper,是将特征选择与机器学习算法结合,以一种黑盒模型的形式进行特征选择,通过训练的方式调整策略并最终输出能够进行特征选择的机器学习模型。嵌入式也称embedded,通过将评价标准和机器学习算法相结合的方式构建黑盒模型,相较于wrapper中使用搜索算法和机器学习算法相结合,时间复杂度更低。集成式特征选择借鉴了集成学习思想,训练多个特征选择算法并整合结果,可以有效提高算法稳定性,多适用于小样本数据。
2 DDoS攻击检测方法
本文提出了一种融合特征选择的随机森林DDoS攻击检测方法,具体流程如图2所示,主要由数据预处理模块、特征选择模块、模型训练模块和攻击检测模块四部分组成。

图2 DDoS攻击检测流程
数据预处理模块负责对原始攻击流量数据进行数据建模,使用特征提取工具cicFlowmeter提取出五元组(源IP地址,源端口,目的IP地址,目的端口,传输层协议)、网络流间隔、正反向窗口字节数等共计78个攻击流量特征,汇总建模形成可以用于训练集成学习模型的初始数据集,进行拆分后供后续模块使用。
特征选择模块需要辅助RF模型训练部分提前完成Bootstrap自主抽样,从预处理得到的训练集提取多个子训练集,每个子训练集对应RF中的一棵树。同时该模块会对每个子训练集使用多种特征选择算法进行特征排序,不同子训练集中样本有差异,因此特征重要性也有所不同,这种先采样后排序的策略所得到的数据子集可以更好地凸显样本特征,更易达到好的训练效果。完成各个子集的特征排序后,该模块会根据给定比例输出最终子训练集用于后续集成学习的模型训练。
模型训练模块基于改进的RF算法,且RF中的决策树与特征选择模块得到的子训练集一一对应,模型根据输入的子训练集生成多棵决策树,并使用加权投票的方式进行集成,同时可以基于测试集进行验证并辅助模型进行参数调整。
攻击检测模块用于进行最后的预测,可以对实时的流量数据进行样本提取并判断是否属于DDoS攻击流量,判断为真后可以基于样本中的源IP参数进行IP封禁等防御操作。
2.1 针对DDoS攻击数据集的特征选择
DDoS攻击数据集有维度高、数据量大等特征。过高的样本维度往往意味着大量的冗余特征,这些冗余特征会淡化样本特点,提高分类难度,导致模型训练精度降低与“维度诅咒[20]”。同时样本的升维也会导致指数级的计算量增长,大幅提高了运算成本,不利于DDoS攻击检测的实时性。因此对DDoS攻击检测模型进行特征选择是非常必要的预处理流程。
本文选用基于平均不纯度的集成式特征选择算法进行特征排序。平均不纯度算法是一种依据决策树中的评价指标实现的算法,在决策树算法中,每个节点都包含一个判断条件,根据特征值产生分支,而分支的依据就是不纯度,常用的不纯度评判依据有信息熵、信息增益、信息增益率和基尼(Gini)系数等[21]。使用树的集成算法进行模型训练时可以根据平均不纯度计算各个特征的重要程度。
本文基于RF和梯度提升决策树(Gradient Boosting Decision Tree, GBDT)两种算法进行平均不纯度减少量的计算,两种算法共同点均为基于决策树的集成学习算法,同时有以下差异:
1)RF算法面向并行的决策树进行计算,而GBDT算法是面向每轮迭代后产生的新决策树的串行计算。
2)RF算法基于Bootstrap抽样,每棵决策树构建的特征各不相同,因此需要多棵决策树才可以覆盖所有特征集合,进而计算特征权重;而GBDT则是基于所有特征构建决策树,并通过Boosting进行迭代优化,因此最少只需要进行一次迭代就能完成所有特征的平均不纯度计算。
两种算法各有优劣:基于RF的特征选择算法运算量更大,但参考对象更多,多样性好,从模型训练的角度来看泛化性更强,能够抗过拟合,对应的特征筛选结果更适用于样本量大、特征数量多的训练集;基于GBDT的特征选择算法需要的运算量相对较小,参照样本数量较少,但单个样本更全面,适用于欠拟合的情况,对应的筛选结果更适用于样本量小、特征维度低的数据集。
2.1.1基于平均不纯度减少的RF特征选择算法


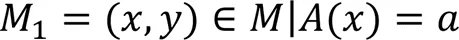


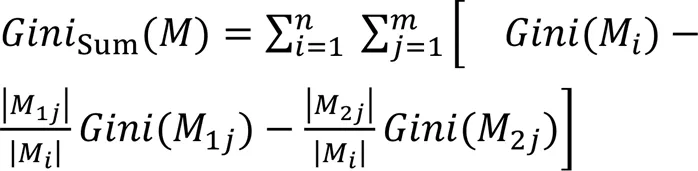
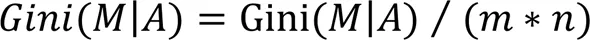
RF包含多棵CART决策树,每棵决策树对应的特征均为对原始特征集进行Bootstrap抽样选取得到的特征子集。因此在RF中平均不纯度降低值的计算方式也有所不同,需要对每棵树进行特征的存在判定,最终在一个更大的范围下计算平均不纯度降低值。具体算法伪代码如下:
算法2 基于平均不纯度减少的RF特征选择算法。
6) end for
7) end for
2.1.2基于平均不纯度减少的GBDT特征选择算法
除了RF算法,同样基于决策树的GBDT算法[22]也可以通过计算决策树中非叶子节点的平均不纯度减少量来评判特征的重要程度。基于平均不纯度减少的GBDT特征选择算法伪代码如下:
算法3 基于平均不纯度减少的GBDT特征选择算法。
4) end for
本文采用两种特征选择算法分别与集成学习算法融合,一种是基于Boosting的GBDT算法,一种是基于Bagging的RF算法,两者均为基于决策树的集成学习算法,同时本文仅仅利用算法特性进行特征的计算,并不进行最终预测结果的集成,因此训练成本远低于这两类算法的常规方案。
2.1.3性能分析
本文使用两种基于平均不纯度的特征选择算法与RF算法进行融合,通过计算决策树生成时的不纯度下降比例进行特征排序,本文主要从时间复杂度来进行性能分析。
两种排序算法时间复杂度较为接近,但实际情况中,RF的多个决策树可以并行构建,而GBDT只支持串行,因此前者的实际运行耗时低于后者。
2.2 融合特征选择的随机森林算法
本文结合基于平均不纯度的特征选择算法与RF算法,提出了一种融合特征选择的随机森林算法。传统RF算法与特征选择算法结合时,通常会先对训练集进行特征排序,根据排序结果进行特征降维,然后对降维后的数据集进行Bootstrap采样以及模型训练。但Bootstrap采样获得的数据子集各有差异,统一的特征排序方法不能适用于每一个特征子集的内部特征,因此本文提出了一种先采样后排序的结合方式,实现步骤如下:
1)先对原始训练数据集基于给定比例进行Bootstrap采样,获得多个训练子集,每个子训练集对应RF中的一个决策树分类器。
2)使用基于平均不纯度的特征选择算法对每个子训练集进行特征排序,根据特征排序结果对每个子集单独进行特征降维,降维后的子训练集将用于单棵决策树的训练。
3)基于每个子训练集进行特征上的Bootstrap采样,以此为训练集构建多棵决策树,使用委员会投票方法对结果进行集成,构成RF模型。
算法伪代码如下:
算法4 融合特征选择的随机森林算法。
输出 预测结果
10) end for
14) end for
相较于传统的先特征选择后训练模型的RF算法,该方法将特征选择步骤融合到单个决策树训练中,考虑到Bootstrap抽样下不同决策树的训练样本特征有所不同,训练样本对应的特征选择的结果也会有所差异。改进方法扩展了特征选择算法的使用范围,细化了特征选择这一步骤,能够有效提升整体模型精度。
3 实验设计
本文基于CICIDS 2017数据集模拟真实环境下的DDoS攻击流量,实验主要分为个三部分:1)数据预处理;2)分别选用两种集成式特征选择算法与RF算法进行融合,生成DDoS攻击检测模型;3)使用预测集验证模型,设立评判指标并与其他算法进行横向对比。
3.1 数据预处理
CICIDS 2017数据集标签流量分类总数较多,但实际上对异常流量的处理方式大同小异,通常为溯源后进行IP封禁。因此本文将基于不同攻击方式构建的多分类数据集转化为只区分异常流量和正常流量的二分类数据集,同时对部分特征中无意义的空值和INF值置0进行数据清洗,以保证模型能够正常进行训练,最后以7∶3的比例将数据集划分为训练集和测试集。
3.2 模型对比方案
本文实现的是一个融合特征选择算法和RF算法的预测模型,其中RF算法用于基本的模型训练,特征选择算法用于对Bootstrap抽样后生成的子数据集进行特征排序,以缩小它对特征进行二次抽样时的选择范围。主要选取了GBDT和两种基于平均不纯度降低的特征选择算法进行对比,包括:
1)原始的随机森林算法(RF);
2)通用的特征选择算法与RF算法结合方法,即先使用特征选择算法对原始数据集进行预处理后再使用RF算法进行训练(Feature_RF);
3)融合特征选择算法的RF算法,包含基于RF和梯度提升决策树(GBDT)的两种特征选择方法GBDT_RF和RF_RF。
模型主要从两个角度进行对比,首先是模型本身的预测精度,通过计算对DDoS攻击样本预测结果对应的评价指标,来判断模型本身的精度提升程度。
其次考虑到模型复杂度有所提高,模型训练与预测所用的时间成本也会有所提升,但模型精度的提升也会加快收敛,因此本文对不同决策树棵树下模型训练时间进行测量,并结合预测精度进行实时性分析。
3.3 评判标准
使用准确率()精确率()、召回率()和F1-score (1)对DDoS攻击检测效果进行算法性能评估,它们均基于混淆矩阵中的4个评价指标:真阳性,表示被模型正确识别的DDoS恶意攻击流量数;真阴性,表示被模型正确识别的普通流量个数;假阳性,表示被错误分类为恶意流量的普通流量个数;假阴性,表示被错误分类为普通流量的恶意流量个数。
1)准确率表示模型正确分类样本占总样本比例。
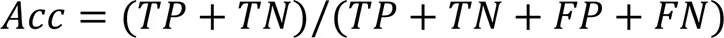
2)精确率表示被预测为恶意流量的所有流量中恶意流量的占比。

3)召回率表示恶意流量被模型正确分类的比率。

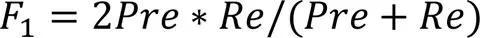
4 实验与结果分析
4.1 数据集
本文选择CICIDS 2017入侵检测评估数据集作为验证对象,它包含良性数据和最新的常见DDoS攻击数据,提供类真实世界的PCAPS格式数据。数据集包含6类攻击方式:Brute Force Attack(暴力攻击)、Heartbleed Attack(心跳攻击)、Botnet(僵尸网络)、Dos Attack(拒绝服务攻击)、Web Attack(网络攻击)和Infiltration Attack(渗透攻击)。实际上这些攻击方式均可以看作DDoS攻击的分支。因此数据集预处理过程中会将数据集转化为二分类,即异常流量和正常流量两类。
4.2 实验环境
实验用服务器配置如下:CPU使用Intel Xeon CPU E5-2640,运行内存256 GB,运行环境基于Python3.9,使用scikit-learn 0.24.1、numpy、pandas等模块构建模型。其中基于梯度提升决策树及RF的特征排序算法基于scikit-learn中的软件包,而训练模型使用的RF算法则基于numpy和pandas编写。
4.3 结果分析

从图3可知,四种特征选择方法的精确率和准确率均能迅速达到阈值,准确率值均达到了98%以上,而精确率则均达到99.6%以上,所有模型对正常流量的预测准确率都很高。但考虑到数据集中正负样本分布极不均衡(异常流量与普通流量数量比例接近1∶40),模型不可避免地产生偏向性,对正向样本的预测准确率天然较高。因此相较于精确率和准确率,对恶意流量的识别率(即召回率)更具参考价值。

F1-score的表现上,Feature_RF也明显优于其他两者,RF_RF算法F1-socre值为99.6%,GBDT_RF算法F1-socre值为99.6%,相较于Feature_RF算法的87.6%和传统RF算法的86.7%,分别提升了12.0个百分点和11.1个百分点。在精确率相近的前提下,Feature_RF的高召回率自然伴随着更高的F1-score得分,说明它拥有更好的鲁棒性。

图3 四种学习模型的训练结果
对于DDoS攻击检测模型而言,训练成本是不可忽视的重要参照,Fusion_RF(即GBDT_RF和RF_RF)相较于Feature_RF,特征选择操作次数更多,因此具有更高的时间复杂度。如图4所示,Feature_RF因为提前剔除部分冗余特征,减少了训练量,整体训练时间最短,训练成本最低。而RF和Fusion_RF差距较小,这是因为Fusion_RF虽然增加了特征选择环节,但也降低了模型训练量,两者互相抵消,保证了算法的实时性。

图4 四种模型的训练时长对比
5 结语
本文提出了一种融合特征选择的随机森林DDoS攻击检测方法,以限制随机森林第二次Bootstrap范围的方式,将特征选择细化到单棵决策树。实验结果表明,相较于常规的特征选择与RF的结合方法,本文方法在模型精度、收敛速度、鲁棒性上均表现更优,同时也因它的高收敛速度特性,兼顾了DDoS攻击检测对实时性的需求。后续我们将进一步验证模型在真实环境下的可用性,并从实时性的角度进一步优化模型。
[1] DOSHI R, APTHORPE N, FEAMSTER N. Machine learning DDoS detection for consumer internet of things devices[C]// Proceedings of the 2018 IEEE Security and Privacy Workshops. Piscataway: IEEE, 2018: 29-35.
[2] 腾讯云T-Sec DDoS防护团队,绿盟科技威胁情报团队. 2021年全球DDoS威胁报告[R/OL]. [2022-09-14].https://www.renrendoc.com/paper/227656572.html.(Tencent Cloud T-Sec DDoS Protection Group, NSFOCUS Threat Intelligence Group. Global DDoS threat report 2021[R/OL]. [2022-09-14].https://www.renrendoc.com/paper/227656572.html.)
[3] PRIYA S S, SIVARAM M, YUVARAJ D, et al. Machine learning based DDoS detection[C]// Proceedings of the 2020 International Conference on Emerging Smart Computing and Informatics. Piscataway: IEEE, 2020: 234-237.
[4] SUTHAHARAN S. Decision tree learning[M]// Machine Learning Models and Algorithms for Big Data Classification: Thinking with Examples for Effective Learning, ISIS 36. Cham: Springer, 2016:237-269.
[5] JIA B, HUANG X, LIU R, et al. A DDoS attack detection method based on hybrid heterogeneous multiclassifier ensemble learning[J]. Journal of Electrical and Computer Engineering, 2017, 2017: No.4975343.
[6] NAJAFIMEHR M, ZARIFZADEH S, MOSTAFAVI S. A hybrid machine learning approach for detecting unprecedented DDoS attacks[J]. The Journal of Supercomputing, 2022, 78(6): 8106-8136.
[7] 孟曈. 基于机器学习与可逆Sketch的DDoS攻击检测[D]. 西安:西安电子科技大学, 2020:92-92.(MENG T. DDoS intrusion detection based on machine learning and reversible sketch[D]. Xi’an: Xidian University, 2020: 92-92.)
[8] OSANAIYE O, CAI H, CHOO K K R, et al. Ensemble-based multi-filter feature selection method for DDoS detection in cloud computing[J]. EURASIP Journal on Wireless Communications and Networking, 2016, 2016: No.130.
[9] GU Y, LI K, GUO Z, et al. Semi-supervised k-means DDoS detection method using hybrid feature selection algorithm[J]. IEEE Access, 2019, 7: 64351-64365.
[10] PANDE S, KHAMPARIA A, GUPTA D, et al. DDOS detection using machine learning technique[M]// KHANNA A, SINGH A K, SWAROOP A. Recent Studies on Computational Intelligence: Doctoral Symposium on Computational Intelligence (DoSCI 2020), SCI 921. Singapore: Springer, 2021: 59-68.
[11] CHENG J, LI M, TANG X, et al. Flow correlation degree optimization driven random forest for detecting DDoS attacks in cloud computing[J]. Security and Communication Networks, 2018, 2018: No.6459326.
[12] LOURENÇO P, GODINHO S, SOUSA A, et al. Estimating tree aboveground biomass using multispectral satellite-based data in Mediterranean agroforestry system using random forest algorithm[J]. Remote Sensing Applications: Society and Environment, 2021, 23: No.100560.
[13] RIGATTI S J. Random forest[J]. Journal of Insurance Medicine, 2017, 47(1): 31-39.
[14] HESTERBERG T. Bootstrap[J]. WIREs: Computational Statistics, 2011, 3(6): 497-526.
[15] BREIMAN L, FRIEDMAN J H, OLSHEN R A, et al. Classification And Regression Trees (CART) [M]// Biometrics. [S.l]: Wadsworth, 1984: 358.
[16] BREIMAN L. Bagging predictors[J]. Machine Learning, 1996, 24(2): 123-140.
[17] 李郅琴,杜建强,聂斌,等. 特征选择方法综述[J]. 计算机工程与应用, 2019, 55(24):10-19.(LI Z Q, DU J Q, NIE B, et al. Summary of feature selection methods[J]. Computer Engineering and Applications, 2019, 55(24): 10-19.)
[18] KIRA K, RENDELL L A. The feature selection problem: traditional methods and a new algorithm[C]// Proceedings of the 10th AAAI Conference on Artificial intelligence. Menlo Park, CA: AAAI Press, 1992: 129-134.
[19] MIKA S, RATSCH G, WESTON J, et al. Fisher discriminant analysis with kernels[C]// Neural Networks for Signal Processing IX: Proceedings of the 1999 IEEE Signal Processing Society Workshop. Piscataway: IEEE, 1999: 41-48.
[20] VERLEYSEN M, FRANÇOIS D. The curse of dimensionality in data mining and time series prediction[C]// Proceedings of the 2005 International Work-Conference on Artificial Neural Networks, LNCS 3512. Berlin: Springer, 2005: 758-770.
[21] TANGIRALA S. Evaluating the impact of GINI index and information gain on classification using decision tree classifier algorithm[J]. International Journal of Advanced Computer Science and Applications, 2020, 11(2): 612-619.
[22] RAO H, SHI X, RODRIGUE A K, et al. Feature selection based on artificial bee colony and gradient boosting decision tree[J]. Applied Soft Computing, 2019, 74: 634-642.
DDoS attack detection by random forest fused with feature selection
XU Jingcheng1,2,3, CHEN Xuebin1,2,3*, DONG Yanling1,2,3, YANG Jia1
(1,,063210,;2(),063210,;3,,063210,)
Exsiting machine learning-based methods for Distributed Denial-of-Service (DDoS) attack detection continue to increase in detection difficulty and cost when facing more and more complex network traffic and constantly increased data structures. To address these issues, a random forest DDoS attack detection method that integrates feature selection was proposed. In this method, the mean impurity algorithm based on Gini coefficient was used as the feature selection algorithm to reduce the dimensionality of DDoS abnormal traffic samples, thereby reducing training cost and improving training accuracy. Meanwhile, the feature selection algorithm was embedded into the single base learner of random forest, and the feature subset search range was reduced from all features to the features corresponding to a single base learner, which improved the coupling of the two algorithms and improved the model accuracy. Experimental results show that the model trained by the random forest DDoS attack detection method that integrates feature selection has a recall increased by 21.8 percentage points and an F1-score increased by 12.0 percentage points compared to the model before improvement under the premise of limiting decision tree number and training sample size, and both of them are also better than those of the traditional random forest detection scheme.
Distributed Denial-of-Service (DDoS); feature selection; Gini coefficient; mean impurity algorithm; random forest algorithm
1001-9081(2023)11-3497-07
10.11772/j.issn.1001-9081.2022111792
2022⁃12⁃06;
2023⁃03⁃02;
国家自然科学基金资助项目(U20A20179)。
徐精诚(1996—),男,江苏常州人,硕士研究生,CCF会员,主要研究方向:数据安全、隐私保护; 陈学斌(1970—),男,河北唐山人,教授,博士,CCF杰出会员,主要研究方向:大数据安全、物联网安全、网络安全; 董燕灵(1998—),女,浙江宁波人,硕士研究生,CCF会员,主要研究方向:数据安全、隐私保护; 杨佳(1996—),男,河北唐山人,硕士研究生,主要研究方向:数据挖掘、网络安全。
TP393.08
A
2023⁃03⁃03。
This work is partially supported by National Natural Science Foundation of China (U20A20179).
XU Jingcheng, born in 1996, M. S. candidate. His research interests include data security, privacy protection.
CHEN Xuebin, born in 1970, Ph. D., professor. His research interests include big data security, internet of things security, network security.
DONG Yanling, born in 1998, M. S. candidate. Her research interests include data security, privacy protection.
YANG Jia, born in 1996, M. S. candidate. His research interests include data mining, network security.
