基于数据驱动与物理模型的主动配电网双时间尺度协调优化
2023-10-31崔明建姚潇毅何怡刚
张 剑,崔明建,姚潇毅,何怡刚
(1.合肥工业大学电气与自动化工程学院,安徽省合肥市 230009;2.天津大学电气自动化与信息工程学院,天津市 300072;3.国网安徽省电力有限公司蚌埠供电公司,安徽省蚌埠市 233000;4.武汉大学电气与自动化学院,湖北省武汉市 430072)
0 引言
计及源荷不确定性,传统基于物理模型的配电网多时段有功无功协调优化属于大规模混合整数非凸非线性随机或鲁棒优化,求解复杂度随配电网拓扑规模与可调设备数量增加呈指数增长,属于非确定 性 多 项 式(non-deterministic polynomial,NP)难题。同时,分布式电源(distributed generator,DG)逆变器、有载调压变压器(on-load tap changer,OLTC)分接头、可投切电容电抗器(switchable capacitor reactor,SCR)、储 能 系 统(energy storage system,ESS)、静 止 无 功 补 偿 器(static var compensator,SVC)等可调设备动作速度与调控方式差异很大,使得配电网有功无功协调优化面临维数高、建模困难、求解慢等难题[1-3]。
基于数据驱动的方法不依赖于精确的配电网模型,易于处理非凸非线性约束、离散变量与源荷不确定性,能够保证解的(近似)最优性,计算速度满足大规模配电网在线实时优化快速性需求[4-5]。深度强化学习(deep reinforcement learning,DRL)基于深度学习强大的感知能力提取复杂、高维环境特征,结合强化学习与环境交互,完成序贯决策过程,在改进学习性能方面表现出优越性。近年来,基于DRL 的配电网无功优化受到了众多专家与学者的关注[6-8]。
文献[9]利用Q 表格强化学习算法在满足操作约束的同时学习一组控制动作进行无功优化,但该算法在处理具有大量状态或动作的任务时效率不高。文献[10]采用批量强化学习设定OLTC 变比调节电压,但这种方法需要人工设计特征。文献[11]采用基于蒙特卡洛搜索树的强化学习算法协调调度ESS 充放电功率,解决大量光伏接入配电网导致的过电压问题。上述3 种方法均未利用神经网络强大的感知与函数逼近能力。文献[12]采用深度Q学习网络(deep Q-learning network,DQN)算法优化电容器的投切,但DQN 算法只能处理离散动作控制问题。文献[13]提出了一种OLTC、电容器无功功率-电压优化的安全异轨DRL 算法,但未利用DG逆变器参与调节。文献[14]采用多智能体深度确定性 策 略 梯 度(deep deterministic policy gradient,DDPG)算法协调控制光伏逆变器无功调节电压。
离散与连续可调设备动作速度不同,适用于不同时间尺度电压问题,如何在不确定性源荷下协调是难点问题。文献[15]构建了离散与连续可调设备长、短时间尺度在线运行方案。长时间尺度马尔可夫决策过程(Markov decision process,MDP)采用DQN 算法求解,短时间尺度MDP 采用优势执行器-评价器(advantage actor-critic,A2C)算法求解。目前,DQN 算法广泛应用于配电网长时间尺度无功优化。然而,当离散可调设备数量较多时,DQN 算法存在离散动作空间维数灾。针对此问题,文献[16]构建了不平衡配电网无功优化多智能体MDP,采用多智能体DQN 算法求解。尽管多智能体DRL 能够克服离散动作空间维数灾,但多智能体训练过程收敛速度远慢于单智能体[17-18]。该方法将连续动作变量,即DG 无功功率离散化,不同类型可调设备动作时间间隔设定为相同,极大增加了离散动作数量,降低了灵活性、最优性与经济效益,难以有效处理短时间尺度电压越限问题。
本文提出了一种配电网双时间尺度有功无功协调优化策略。针对单智能体连续-离散动作空间维数灾问题,采用一种改进DDPG 算法求解。在给定长时间尺度MDP 离散可调设备与ESS 动作值后,求解长时间尺度(小时级)内每个短时间尺度(分钟级或秒级)凸优化物理模型得到的最优目标函数值累加后作为MDP 的代价。因此,数据驱动与物理建模方法融为一体,保证解的(近似)最优性。
1 双时间尺度有功与无功协调优化的模型
1.1 系统模型
如附录A 图A1 所示,将每天划分为个时段,记为τ=1,2,…,。将每个时段τ再细分为NT个时隙,记为t=1,2,…,NT。每个时段τ的持续时间为1 h。每个时隙t的持续时间为几分钟或几秒钟。为应对长时间尺度源荷功率缓慢变化导致的网损增加、电压越限问题,OLTC 变比、SCR 挡位、ESS 充放电功率设定在时段τ-1 的末尾至时段τ的开始前完成调整,此后保持不变,直到时段τ末尾再重新调 整。本 文 假 定OLTC 变 比、SCR 挡 位、ESS 充 放电功率在时段τ内的每个时隙t的值相同,但是从时段τ-1 至τ的值可变。本文将ESS 充放电功率设置为长时间尺度动作变量是因为,若设置为短时间尺度优化变量将会造成处于不同时隙t的优化变量耦合,使得基于物理模型的优化问题规模急剧增加,求解速度难以满足实时控制需求。
为应对高比例风电、光伏与快充电动汽车(electric vehicle,EV)接入配电网导致的短时间尺度功率、电压频繁、快速、剧烈波动问题,SVC、DG 逆变器无功功率设定在每个时隙t的起始时刻进行调节。此外,为降低模型复杂度,本文假定节点k的有功 功 率、无 功 功 率与DG 有 功 出 力在 每 个 时 隙t内 恒 定,但 从 时 隙t到t+1可变。
1.2 双时间尺度有功无功协调优化
不同类型可调设备动作速度差异很大,针对此问题,本文提出的双时间尺度有功无功协调优化控制策略需要求解以下随机优化问题:

针对上述问题,本文设计了一种算法,通过不断观察当前时隙t的负荷有功功率向量pd(τ,t)、无功功率向量qd(τ,t)与DG 有功功率向量pg(τ,t),得到式(1)的(近似)最优值。尽管上述功率随机过程分布函数未知,但其在当前时隙t的具体实现值可精确预测[19]。因此,本文将结合配电网物理模型与数据驱动方法实时求解式(1)。具体而言,在时段τ-1 的末尾,OLTC 变比、SCR 挡位与ESS 充放电功率长时间尺度(近似)最优设定值采用DRL 算法根据时段τ-1 的配电网状态数据学习得到;在时段τ内每个时隙t的起始时刻,SVC、DG 逆变器无功最优设定值在给定OLTC 变比、SCR 挡位与ESS 充放电功率的情况下,通过构建与求解单一时隙凸规划物理模型给出。时段τ内各个时隙t的物理模型目标函数优化结果累加值为该时段τ的MDP 代价。短、长时间尺度模型的具体构建与协调、融合方法见附录B 与第2 章。
2 长时间尺度ESS 与离散可调设备设置
长时间尺度有功无功协调优化模型以OLTC变比、SCR 挡位、ESS 充放电功率为动作变量。现有方法主要基于启发式、半定规划、二阶锥规划(second-order cone programming,SOCP)凸松弛技术构建多时段混合整数非凸非线性模型。求解结果不能保证最优性,计算复杂度高,要求计算机具有较大内存空间。本文基于人工智能领域的最新进展,采用基于数据驱动的方法构建MDP,从负荷与间歇性DG 功率未知动态分布中求出(近似)最优解,克服了传统优化方法计算复杂度高的弊端,能够满足在线实时控制要求。
2.1 基于数据驱动的建模方法
由附录B 式(B3)、式(B4)、式(B6)、式(B17)、式(B18)、式(B28)与附录A 图A1 可以看出,时段τ-1 末尾的OLTC 变比、SCR 挡位、ESS 充放电功率设定值(长时间尺度学习)对时段τ内每个时隙t的起始时刻SVC、DG 逆变器无功设定值(短时间尺度凸优化)均具有重大影响。反之,时段τ内每个时隙t的起始时刻SVC、DG 逆变器无功设定值经由奖励 对 后 续 时 段OLTC 变 比、SCR 挡 位、ESS 充 放 电功率设定值产生影响。这种双向作用十分适合采用强化学习方法求解。


式中:c0为常数。
6)长期回报集合J:MDP 的目标是采用最优策略使得长期回报最大。
2.2 基于松弛-预报-校正的DDPG 算法
DDPG 算法适用于连续动作的场景,配电网中OLTC 变比和SCR 挡位只能取离散值。因此,不能直接应用DDPG 算法,DQN 算法不适用于连续动作的场景。ESS 充放电功率一般为连续值,DQN 算法难以适用。针对此问题,本文将文献[20]中的方法推广至一般情形,即连续-离散动作空间。首先,将离散动作分量松弛为连续动作分量(称为松弛过程);然后,针对执行器输出的原型动作中对应于OLTC 变比和SCR 挡位的分量,在(嵌入)离散动作空间中搜索出Knn个最临近点(称为预报过程);最后,每个最邻近点与执行器输出的原型动作中对应于连续动作分量(ESS 充放电功率)组成一个完整动作,并依次输入评价器得到动作价值,选取动作价值最大的动作与环境交互(称为校正过程)。在已知数据集中找出给定点的Knn个最临近点能够在对数时间复杂度内完成[21]。目前,已有大量文献报导该算法。本文采用的基于松弛-预报-校正的改进DDPG 算法不会大幅增加计算时间,具有很好的可扩展性。
基于松弛-预报-校正的改进DDPG 算法示意图如附录C 图C1(b)所示。本文提出的主动配电网双时间尺度有功无功协调优化程序流程见附录D 图D1。
虽然基于gumble-softmax 重参数化技巧的DDPG 算法也可以处理离散动作,但是本文方法动作维度等于OLTC、SCR、ESS 的数量之和,基于gumble-softmax 重参数化技巧的DDPG 算法动作维度等于离散动作数量与连续动作数量之和。例如,假设三相平衡配电网含5 台OLTC、4 台SCR、2 台ESS,每台OLTC 有10 个挡位,每 台SCR 有4 个挡位,则本文方法动作维度为5+4+2=11。基于gumble-softmax 重参数化技巧的DDPG 算法动作维度为105×44+2=25 600 002。因此,本文方法动作维度远远低于基于gumble-softmax 重参数化技巧的DDPG 算法。虽然后者也可以处理离散动作,但其只适用于离散动作数量较少的情形。当离散动作数量很多时,会产生维数灾问题。本文方法的优势之一是不会产生维数灾问题。
为了限制短路电流及便于继电保护的整定与配合,配电网一般采用辐射状运行结构。本文设置OLTC 与SCR 动作时间间隔为1 h,未计及OLTC、SCR 的动作次数与辐射状网络结构约束,文献[10,12,15,16,22-25]亦未计及。
本文为实现SVC 与DG 逆变器的(毫秒级)快速决策,将ESS 充放电功率放在长时间尺度进行优化,在一定程度上牺牲了ESS 的灵活调节能力,但降低了循环次数,提高了寿命。文献[1]也是将ESS 充放电功率调整时间间隔设置为1 h,而SVC和DG 无功功率设置为实时调节。
3 仿真算例
3.1 仿真算例1
IEEE 33 节点配电系统仿真条件如附录E 所示。算例中,共有17×11×11=2 057 个离散动作分量。为了验证本文方法的有效性,首先设置OLTC 变 比、SCR 挡位、ESS 充放电功率在每个时段τ分别为随机值与固定值。当设为固定值时,OLTC 变 比 为1,2 台SCR 无 功 补 偿 均 为0,ESS 充放电功率为0,只优化求解每个时隙t的SOCP 模型。平均每小时代价的优化结果如附录F 图F1 所示。可以看出,每天平均每小时的代价均远大于0.1 p.u.,意味着每天电压越限均十分严重。第1 阶段变量取随机值比取固定值导致的电压越限问题更加严重。2 种方法计算时间分别为1 511 s 和1 530 s。
本文根据仿真结果代价是否大于0.1 p.u.作为判断电压是否越限的标准,原因如下:由于潮流计算的三相功率基准值选取为配电网额定容量(对于IEEE 33 节点、IEEE 123 节点配电系统分别为10 MV·A、5 MV·A),从式(5)至式(9)可知,若电压未越限,则代价为每个时段的平均网损(有功损耗),其值必远小于0.1 p.u.。若大于0.1 p.u.,则表明网损率远大于10%,这在实际配电网中是不可能的。每天平均每小时的代价均远大于0.1 p.u.,意味着每天的电压越限均十分严重,这是由于代价计及了电压越限惩罚。
将OLTC 变比设置为连续变量,并设定OLTC变比、SCR 挡位、ESS 充放电功率在每个时隙t均可调节,构建288 个时隙单一短时间尺度传统日前混合整数SOCP模型。基于MATLAB平台采用Mosek 9.1.4 软件包求解,为提高计算速度,设置相对对偶间隙为+∞,平均每小时最优代价为0.009 p.u.,如图1 中绿色点线所示。
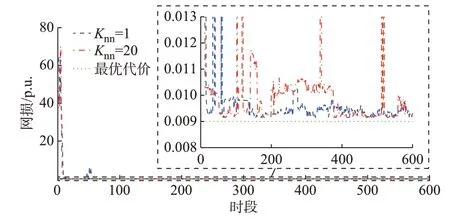
图1 算例1 中IEEE 33 节点配电网平均每小时的代价曲线Fig.1 Curves of average cost per hour of IEEE 33-bus distribution network in case 1
采用本文方法,针对执行器输出的动作,在离散动作分量空间搜索出Knn=1 与Knn=20 时最邻近的动作分量,优化结果分别如图1 中蓝色虚线与红色点划线所示。可以看出,采用本文方法,起始阶段平均每小时代价很高,这是因为DDPG 算法在起始阶段执行器采用的是随机动作策略。在第60 d 后(训练了60×24步=1 440 步),网损开始变得很低,接近最优值0.009 p.u.。
Knn=1 与Knn=20 时的总优化计算时间分别为1 307 s 和1 487 s,对应每日数据的平均优化计算时间分别为2.178 s 和2.478 s。求解传统288 个时隙日前规划混合整数SOCP 计算时间为114 s。当Knn=20 时,本文方法的计算速度约为传统方法的46 倍,每个时隙t的平均计算时间为0.008 6 s。因此,即使每个时隙t持续时间设置为1 s,本文所提方法仍满足实时控制需求。
3.2 仿真算例2
设置每个DG 最大功率和容量分别为1 MW 和1 MV·A,c0为0.005 p.u.。其他仿真条件与算例1相同。训练过程中的平均每小时代价优化结果如图2 所示。可以看出,采用本文方法,当Knn=20 时,在第70 d 后(训练了70×24 步=1 680 步),平均每小时代价十分接近传统288 个时隙单一短时间尺度混合整数SOCP 模型优化结果的最优网损0.003 8 p.u.。Knn=20 时,前100 个时段电压频繁越限的原因是DDPG 算法在起始阶段执行器采用的是随机动作策略。当任务较困难时,改进DDPG 智能体需要训练足够长的步数才能学习到最优策略。然而,当Knn=1 时,训练过程很不平稳,电压越限问题频繁发生。这是因为风电比例很高(风电比例是算例1 的10 倍),部分支路存在反向潮流,电压分布范围较宽。为避免电压与电流越限,OLTC 变比、SCR 挡位与ESS 充放电功率必须精准设定。然而,在离散动作空间取1 个最临近点不能保证解的可行性。因此,任务很困难时,选取Knn=1 是不合适的。
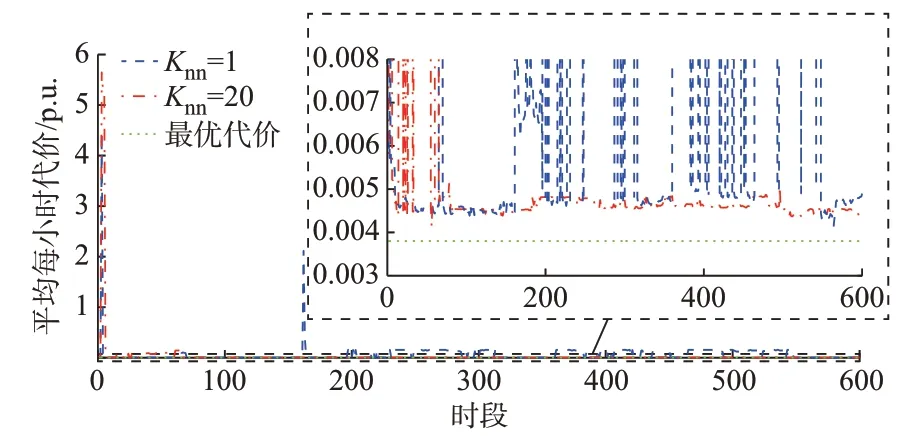
图2 算例2 中IEEE 33 节点配电网平均每小时的代价曲线Fig.2 Curves of average cost per hour of IEEE 33-bus distribution network in case 2
3.3 仿真算例3
设置OLTC 最大、最小变比分别为1.1 与0.9。其他仿真条件与算例1 相同。此算例中共有33×11×11=3 993 个离散动作分量。若OLTC 变比不在区间[0.95,1.05]内,则OLTC 二次侧电压越限。相比于算例1,此算例中DDPG 智能体找到(近似)最优解要困难得多,平均每小时代价优化结果如图3 所示。可以看出,采用本文方法,当Knn=40时,在第250 d 后(训练了250×24 步=6 000 步),平均每小时代价十分接近传统288 个时隙单一短时间尺度混合整数SOCP 模型优化结果的最优网损0.008 8 p.u.。然而,当Knn=400 时,训练过程中的平均每小时代价一直很高,算法不收敛。这是因为最临近点选取得太多导致DDPG 智能体没有得到有效训练,神经网络参数未进化,一直找不到可行解。因此,当任务很困难时,Knn选取得过大也是不合适的。此外,当Knn=1 时,训练过程很不平稳,电压越限问题频繁发生。这是因为在离散动作空间取1 个最临近点不能保证解的可行性。这再次证明,任务很困难时,选取Knn=1 是不合适的。
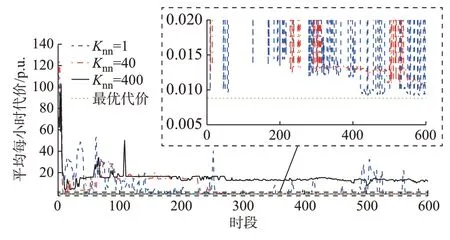
图3 算例3 中IEEE 33 节点配电网平均每小时的代价曲线Fig.3 Curvs of average cost per hour of IEEE 33-bus distribution network in case 3
3.4 仿真算例4
IEEE 123 节点配电系统仿真条件如附录E 所示。假设根节点电压固定为1.05 p.u.。此时,离散动作分量数量为53×26个=8 000 个。设置OLTC变比、电容器是否投入、ESS 充放电功率在每个时段τ分别为随机值与固定值。当设为固定值时,电容器均不投入,ESS 充放电功率为0,位于支路9-14、25-26、119-67 的OLTC 变 比 分 别 为1.000、1.000、1.025,只优化求解每个时隙t的二次规划模型,平均每小时代价优化结果如附录F 图F2 所示。可以看出,每天平均每小时的代价均远大于0.1 p.u.,意味着电压越限均十分严重。而且,第1 阶段变量取固定值比取随机值导致的电压越限问题更加严重。
采用本文所提方法,当Knn为1 与20 时,平均每小时代价优化结果分别如图4 中蓝色虚线与红色点划线所示。在第20 d 后(训练了20×24 步=480 步),当Knn=20 时,平均每小时代价接近最优值0.018 8 p.u.。
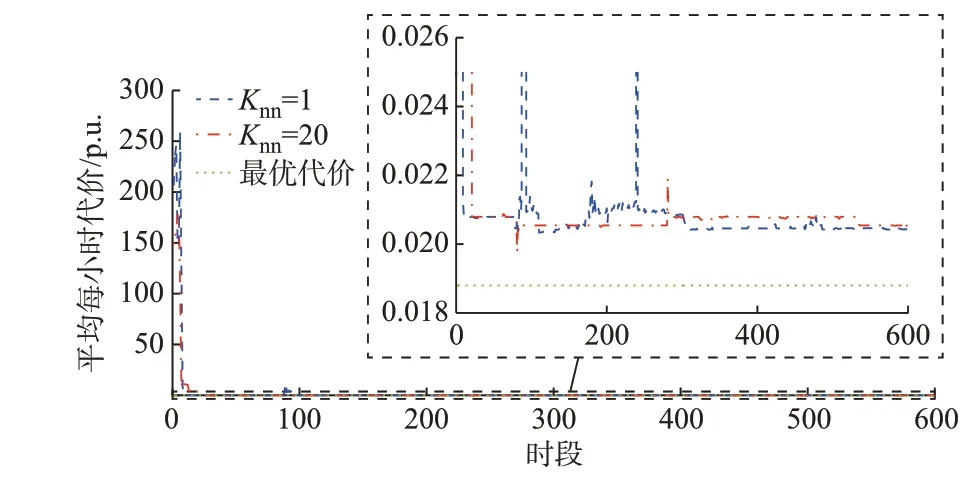
图4 算例4 中IEEE 123 节点配电网平均每小时的代价曲线Fig.4 Curvs of average cost per hour of IEEE 123-bus distribution network in case 4
3.5 仿真算例5
假设根节点接入一台三相OLTC,最大、最小变比分别为1.05 与0.95,步长为0.025。其他仿真条件与算例4 相同。此算例中共有54×26个=40 000 个离散动作分量。当第10 阶段变量取随机值或固定值当设定为固定值时,电容器均不投入,ESS 充放电功率为0,位于支路123-1、9-14、25-26、119-67 的OLTC 变比分别为1.000、1.050、0.950、1.050。平均每小时代价优化结果如附录F 图F3 所示。可以看出,相比于附录F 图F2,电压越限问题更加严重。而且,第10 阶段变量取随机值比取固定值导致的电压越限问题更加恶化。这是因为根节点OLTC 变比对电压越限的影响最大。2 种方法优化计算总时间分别为7 231 s 与7 270 s。
采用本文所提方法,平均每小时代价优化结果如图5 所示。可以看出,在第238 d 后(训练了238×24 步=5 712 步),当Knn=20 时,平均每小时代价接近最优值0.017 9 p.u.,训练过程平稳度与收敛速度远高于Knn=1 时。
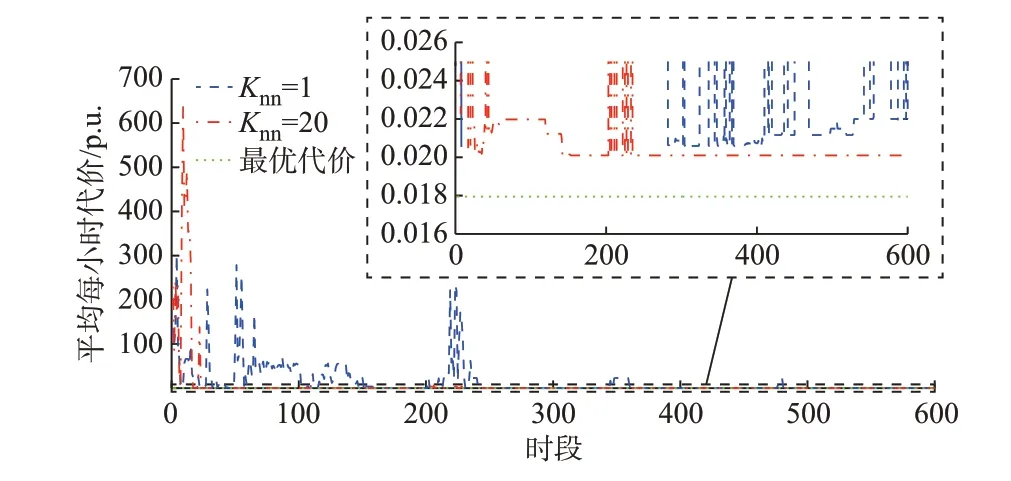
图5 算例5 中IEEE 123 节点配电网平均每小时的代价曲线Fig.5 Curvs of average cost per hour of IEEE 123-bus distribution network in case 5
当Knn为1 与20 时,总优化计算时间分别为629 4 s 和6 547 s,每日数据的平均优化计算时间分别为10.490 0 s 和10.911 7 s。将相对对偶间隙设置为无穷大,求解传统144 个时隙单一短时间尺度日前规划混合整数SOCP 计算时间为199 s。当Knn=20 时,本文方法计算速度约为传统方法的18.237 倍,每个时隙t的平均计算时间为0.075 8 s。因此,即使时隙t设置为1 s,本文所提方法仍满足实时控制的需求。
3.6 与现有多智能体DQN 算法比较
对比图5 与文献[16]可以看出,采用本文方法训练过程收敛速度与平稳度远高于文献[16]中的多智能体DQN 算法。这是因为多智能体协调探索与利用比单智能体复杂与困难得多。文献[16]将连续变量离散化,离散动作数量呈指数增长,而且构建的单一长时间尺度MDP 未计及不同类型可调设备动作速度差异性,降低了调度灵活性与最优性。
4 结语
本文方法的突出优点是非常容易在实际配电网中实现。基于IEEE 33 节点与IEEE 123 节点配电系统仿真结果表明,针对执行器输出的原型动作,在离散动作分量空间选取的最临近点数量Knn对训练过程收敛速度与平稳度具有较大影响。当任务较困难时,Knn太大或太小,如Knn为1 或400,可能导致训练过程很不平稳或不收敛。Knn的取值适中,如20或40,即可使得训练过程较平稳。本文方法优化结果十分接近于OLTC、SCR 与ESS 参与短时间尺度调节的多时隙单一短时间尺度日前混合整数SOCP或二次规划优化结果。然而,当Knn=20 时,本文方法计算速度是其18~42 倍。而且,本文方法DRL 训练过程收敛速度与平稳度远高于现有单一慢时间尺度多智能体DQN 算法。
本文未计及电动汽车的充放电功率约束与调节作用,未采用测试集验证基于松弛-预报-校正的DDPG 算法泛化能力。进一步研究的工作重点是在短时间尺度优化模型中计及电动汽车充放电功率约束与调节作用,以及采用测试集验证基于松弛-预报-校正的DDPG 算法泛化能力。
附录见本刊网络版(http://www.aeps-info.com/aeps/ch/index.aspx),扫英文摘要后二维码可以阅读网络全文。
