基于T-HDGN 模型的对话摘要生成方法
2023-10-17高玮军刘健毛文静
高玮军,刘健,毛文静
(兰州理工大学 计算机与通信学院,兰州 730050)
0 概述
对话摘要旨在将会话浓缩成一段包含重要信息的简短文本,使人们不用回顾历史对话就可以快速捕捉到半结构化和多参与者对话的重点。近年来,随着移动电话、电子邮件和社交软件的普及,人们越来越多地使用对话形式分享信息,特别是新冠肺炎疫情在全球大范围的传播,在线多人聊天或会议已成为人们日常工作的重要部分。因此,利用文本摘要技术快速准确地将大量的对话类数据组织成简短、自然和信息丰富的文本成为研究热点。
目前,对话摘要的研究方法通常分为抽取式摘要和生成式摘要。抽取式摘要方法是从给定的源对话中抽取若干重要的话语,并将它们重新组合排序形成摘要[1-2]。这种方法形成的摘要只是重要语句的机械拼接,语义不连贯,不符合人类的摘要习惯。而生成式摘要方法是对原文内容进行语义理解和重构,并用新的语句表达原文信息,从而使生成的结果更像是人类编写的摘要[3]。随着深度学习的发展,生成式摘要方法已经成为目前研究的主流。
现有的文本摘要研究大多都集中在单一参与者的文档上,如新闻以及科学论文摘要等,这些文档通常以第三人称的角度阐述内容,通过段落或章节使得信息流更清晰。与这些结构化文本不同,对话是一种动态的信息流交换过程,通常是非正式的、冗长的和重复的,并伴随着错误的开始、主题漂移和参与者打断[4]。为了总结非结构化和复杂的对话,文献[5]直接将文档摘要方法应用于对话总结中。尽管指针生成网络、强化学习、预训练语言模型等在结构化文档上取得了重大的进展,但是文档和对话类数据存在固有差异,直接应用文档摘要模型来总结对话面临诸多挑战。
为解决上述问题,研究人员采用图结构对会话进行建模,以打破对话的顺序位置,直接将相关的远距离话语相连接,解决远距离依赖问题,并且建模额外的知识。为此,本文提出一种基于T-HDGN(Topic-word guided Heterogeneous Dialogue Graph Network)模型的对话摘要生成方法,基于图到序列的框架通过图神经网络挖掘话语内和话语间的语义关系,在解码阶段融入主题词引导摘要生成。本文利用从会话中显式提取的行动三元组(Who,Doing,What)构建对话图以融入说话人与其动作之间正确的对应关系。将行动三元组和话语作为异质数据进行建模,从而得到异质对话图。异质图网络可以更有效地融合信息并捕获句间丰富的语义关系,从而更好地对会话进行编码[6]。此外,在异质对话图网络中使用信息融合模块和节点位置嵌入2 个特殊模块。信息融合模块旨在帮助话语节点更好地聚合说话人和行动三元组的信息,而位置嵌入模块使话语节点能感知其位置信息。
1 相关工作
1.1 文档摘要
与抽取式摘要方法相比,生成式摘要方法被认为更具挑战性。为此,研究人员设计各种方法生成文档摘要。文献[7]提出将序列到序列模型用于生成式文本摘要。文献[8]提出指针生成器网络,允许从源文本复制单词,在解决 OOV(Out Of Vocabulary)问题的同时又可以避免生成重复内容。文献[9]利用强化学习选择摘要所需的正确内容,该方法被证明可以有效提升生成效果。文献[10]使用大规模预训练语言模型BERT 作为文本上下文编码器以获取更多的语义信息,进一步提高摘要的生成质量。随着图变得越来越普遍,信息更丰富,图神经网络受到越来越多的关注,特别是它非常适用于在自然语言处理,如序列标注[11]、文本分类[12]、文本生成[13]等任务中表示图结构。对于摘要任务,最近也有研究基于图模型的方法探索文档摘要,如抽取实体类型[14],利用知识图[15]以及额外的事实[16]校正模块。此外,文献[17]通过Transformer 编码器创建1个完全连接图,学习成对句子之间的关系。然而,如何构建有效的图结构以获取丰富的语义表示来生成摘要仍然面临挑战。
1.2 对话摘要
对话摘要研究主要集中在会议、闲聊、客户服务、医疗对话等领域。然而,由于缺乏公开可用的资源,因此在各领域只是进行了一些初步工作。早期的研究人员基于模板或使用多句压缩的方法来抽取对话摘要[18],但这些方法很难生成简洁自然的摘要,尤其是面对会话这种特殊的文本结构。而生成式对话摘要方法能够有效解决这些问题。文献[19]根据会议数据集AMI 构建1 个新的对话摘要数据集,并通过句子门控机制来联合建模交互行为和摘要之间的显式关系。文献[5]提出1 个新的生成式对话摘要数据集,并且基于序列的模型验证其性能。由于参与者的多重性和频繁出现的共指现象,因此模型生成的对话摘要存在事实不一致的问题。为此,文献[20]通过说话人感知的自注意力机制来处理参与者和他们的相关人称代词之间的复杂关系。一些研究还利用对话分析生成对话摘要,如利用主题段[21]、会话阶段[22]或关键点序列[23]。
综上所述,现有的对话摘要模型主要基于循环神经网络(Recurrent Neural Network,RNN)的序列到序列模型进行优化改进。尽管相关的研究已经取得了一定成果,但是对话具有多参与者以及突出信息分散在整个会话中的特点,使得摘要模型难以集中在许多信息性的话语上。此外,当前模型对识别不同说话者的行为以及他们如何相互作用或相互引用的关注较少,难以将说话者及其对应的动作联系起来,从而产生错误的推理。为了缓解这些问题,受基于图方法的启发,本文基于图模型的方法进一步探索对话摘要。
2 异质对话图构建
2.1 图符号定义
对于给定的会话C={u0,u1,…,un},将异质对话图定义为1 个有向图G=(V,E,A,R),其中,V是节点集合,包含3 种节点V=Vu∪Va∪Vs,E是边集合。不同类型的节点和边分别有各自的类型映射函数,节点类型的映射函数为τ(v):V→A,边类型的映射函数为φ(e):E→R。
2.2 话语-行动图构建
完全依赖神经模型很难从对话中获得具体的事实特征,为了帮助模型更好地理解会话中说话人与其行为之间正确的联系,本文从会话中提取行动三元组(Who,Doing,What),将其作为先验知识构建对话图。
首先,基于以下规则将第一人称的话语转换为第三人称观点的形式:1)用当前说话人或周围说话人的名字替换第一或第二人称代词;2)根据斯坦福CoreNLP 检索会话中的共指簇以替换第三人称代词,例如,Amanda 对Jerry 说:“I'll bring it to you tomorrow”被转换为“Amanda'll bring cakes to Jerry tomorrow”。
然后,使用开源信息抽取系统OpenIE 对转换后的对话提取行动三元组(Who,Doing,What),即主谓宾信息。行动三元组如图1 所示。

图1 行动三元组Fig.1 Action triplets
话语-行动图如图2 所示,通过将话语和各行动三元组视为不同类型的节点以构建话语-行动图。本文考虑到出现具体事实特征的话语以及其周围话语往往是重要话语,将抽取出的各行动三元组作为行动节点,并且将它与出现该具体动作的话语以及下一位说话人的话语相连接,使得模型关注重要话语并理解说话人与其对应动作的正确联系。此外,本文将话语和行动节点之间的边定义为action边。
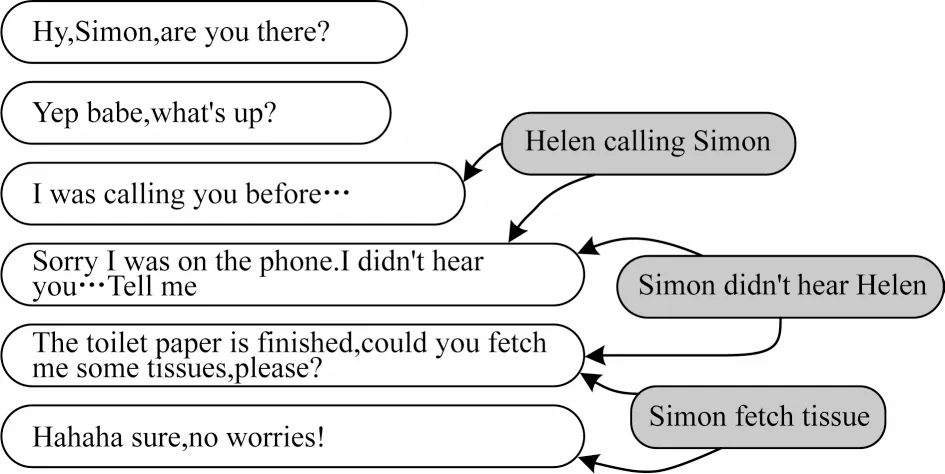
图2 话语-行动图Fig.2 Utterance-action graph
2.3 话语-对话者图构建
由于会话包含多个对话者以及各自对应的话语,因此将对话者和话语视为不同类型的节点。将说话人与其对应的话语通过talk 边进行连接。话语-对话者图如图3 所示。
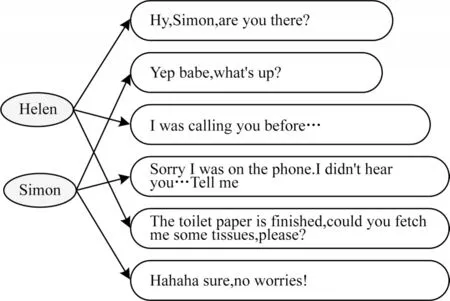
图3 话语-对话者图Fig.3 Utterance-speaker graph
本文综合上述话语-行动图以及话语-对话者图,构建最终的异质对话图。此外,为了促进信息流在整个图上的传播,本文添加2 种反向边rev-action 和rev-talk。异质对话图具有对话者、话语和行动节点3种,以及action、talk、rev-action 和rev-talk 4 种类型的边。异质对话图如图4 所示。
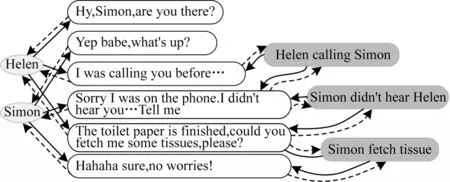
图4 异质对话图Fig.4 Heterogeneous dialogue graph
3 T-HDGN 模型
主题词引导的异质对话图网络(T-HDGN)结构如图5 所示。T-HDGN 主要由节点编码器、图编码器以及主题词引导的解码器3 部分组成。节点编码器旨在初始化每个图节点;图编码器用来捕获会话结构信息并得到更高级的节点表示;主题词引导的解码器在指针机制和覆盖机制中融入主题词特征以辅助摘要的生成。
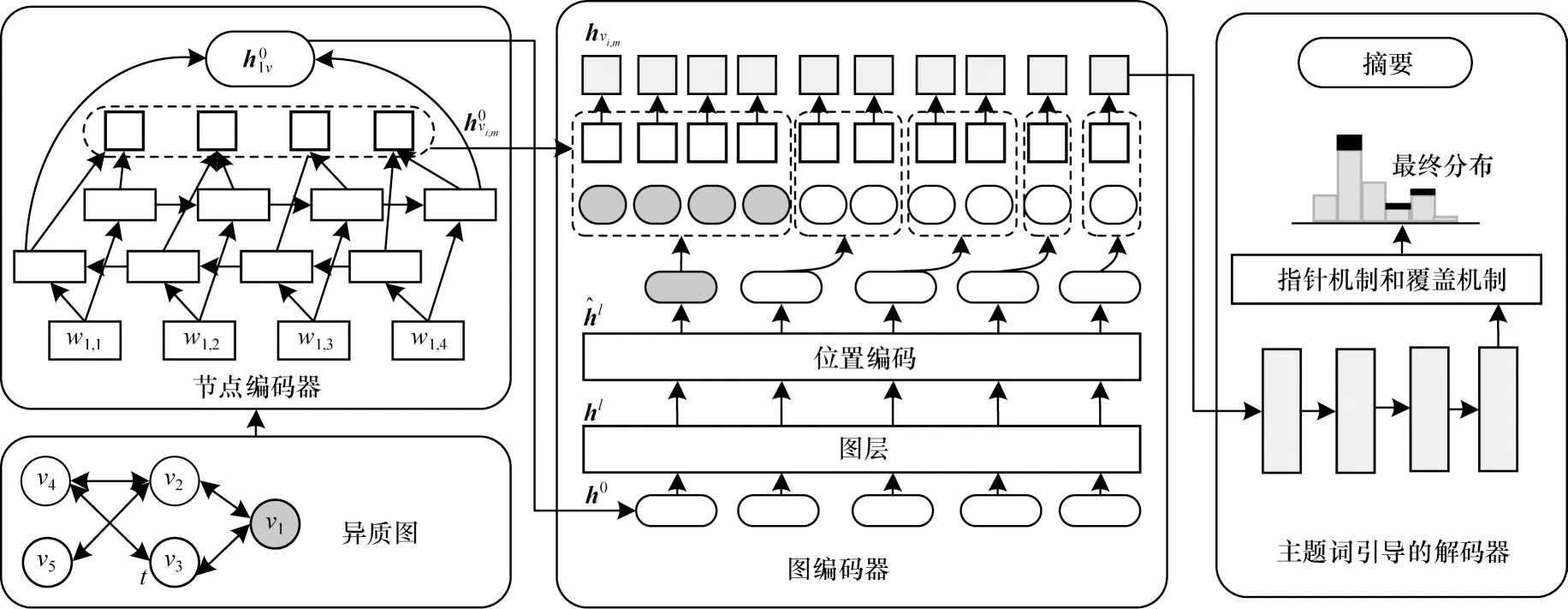
图5 T-HDGN 模型结构Fig.5 Structure of T-HDGN model
3.1 节点编码器
3.2 图编码器
在得到各节点的初始表示后将它们输入到1 个图编码器中,利用图编码器捕获会话结构信息并得到更高级的节点表示。本文使用文献[24]提出的Heterogeneous Graph Transformer 作为图编码器,针对异质性问题,采用与类型相关的参数进行建模。异质图Transformer 层结构如图6 所示。

图6 异质图Transformer层Fig.6 Transformer layer of heterogeneous graph
Heterogeneous Graph Transformer 主要包括3 个模块:1)异质相互注意力用来计算源节点和目标节点的注意力得分Attention(s,e,t);2)异质消息传递为每个源节点生成消息向量MMsg(s,e,t),并传播特定类型的信息;3)特定目标的信息聚合使用注意力分数作为权重来聚合从源节点到目标节点的信息。本文通过1 个消息融合过程和节点位置编码使异质图上的学习过程更有效。
3.2.1 异质相互注意力
3.2.2 异质消息传递
3.2.3 特定目标的聚合
基于目标节点的类型,该过程分为2 种情况:1)当目标节点不是话语节点时,首先使用注意力得分加权求和消息向量2)当目标节点是话语节点时,本文通过消息融合过程将信息更有效地聚合到话语节点中。在消息融合过程中,由于注意力是1 个归一化的分布,因此当目标为话语类型的节点聚合来自行动和对话者类型的源节点信息时,话语节点可能会更倾向于对话者节点而忽视行动节点。为此,本文使用行动节点的注意力权重加权对应的消息向量并添加对话者信息。其计算式如下:
最终,在得到聚合后的消息向量后,根据目标节点类型,本文通过1 个线性映射把它映射回目标节点类型,并采用残差连接得到更新后的节点表示
3.2.4 位置编码
由于对话本质上是连续序列,因此部分上下文信息也将沿着这个顺序流动,而原始异质图不能直接建模话语之间的时间顺序。为了节点能够感知其位置信息,本文添加节点位置信息。对于对话者和行动节点其位置都置为0。对于话语节点vi,将其位置pvi与源对话中的话语顺序相关联。最终本文为每个节点添加位置信息表示1个可学习的位置参数矩阵。
在得到添加位置信息的节点表示之后,将其与对应的初始词语表示拼接,并进一步映射得到最终的词语表示
3.3 主题词引导的解码器
主题关键词是主题信息常见的表示形式,体现了文档的关键内容。因此,本文在解码过程中使用主题关键词引导摘要的生成。
传统的编码器-解码器模型只使用源文本作为输入,导致生成的摘要中缺乏主题词信息。为此,本文在指针机制和覆盖机制中注入主题词以增强摘要中的主题关键词信息。
本文将1 次会话中所有行动三元组的Who、Doing 和What 作为主题关键词K={k1,k2,…,km},并且将所有主题关键词表示ki的均值作为主题信息表示。此外,本文用图中所有节点词语表示hvi,n的均值作为解码器的初始状态s0。具体计算式如下:
3.3.1 覆盖机制
由于注意力机制会反复关注输入序列中的某些单词,因此会出现摘要自我重复的现象,尤其是对话者的名字和重要动作。因此,本文引入覆盖机制来解决这个问题,通过历史注意力来影响当前注意力计算,首先将注意力分布at之和作为覆盖向量ct,ct表示单词从注意力机制受到的覆盖程度。传统的覆盖机制只涉及解码器状态st和编码器隐藏状态hvi,n,难以关注到主题词信息。因此,本文修改了注意力的构成部分,将主题词添加到覆盖机制中,计算式如式(9)和式(10)所示:
其中:v、Wh、Ws、Wc、Wk和bAttention是可学习参数。通过注意力得分加权编码器隐藏状态,得到上下文向量
在解码步骤t时刻,解码器状态st、上下文向量和主题向量通过2 个线性层产生词汇分布Pvocab,计算式如式(12)所示:
其中:V′、V、b和b′是可学习参数。
3.3.2 指针机制
受固定词汇表的限制,在生成摘要时可能会丢失一些主题词信息。因此需要引入指针机制来扩展目标词汇表使其包含主题词,通过指针网络决定从固定词汇表生成1 个单词还是根据注意力分布at直接从输入序列复制1 个单词。为此,本文将主题词添加到开关的计算中,使解码器根据状态st、主题向量、上下文向量和解码器输入xt共同计算指针开关pgen。具体计算式如式(13)所示:
其中:σ为Sigmoid 激活函数;均为可学习参数;bptr为偏置项。最终,在扩展词汇上的概率分布如式(14)所示:
4 实验
4.1 数据集
为验证所提模型的可行性和有效性,本文在SAMSum 数据集上进行相关实验。SAMSum 数据集是1 个关于现实生活中各种场景下的英文对话数据集,包括闲聊、安排会议、讨论事件以及与同学讨论大学作业等话题。
数据集中源对话的平均对话长度为126.7(Token 数),平均话语数为11.1。每句话语均包含对话者的名字,大多数对话只有2 个对话人(约占所有对话的75%),其余是3 个或更多人之间的对话。表1 所示为SAMSum 数据集的相关信息,包括每次会话中对话者数、话语数以及行动三元组这三者的平均数,“#”表示对应的统计总数,长度是指Token数。
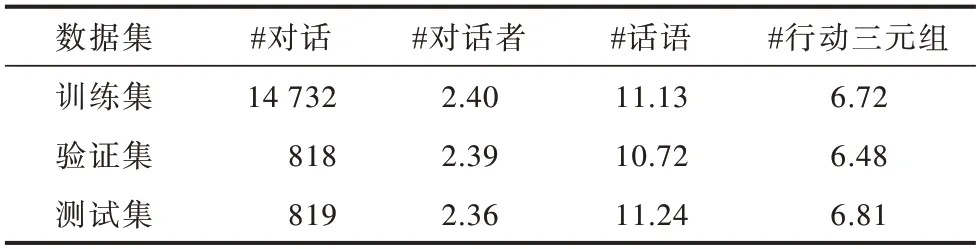
表1 SAMSum 数据集相关信息Table 1 Related information of SAMSum dataset 单位:个
4.2 实验环境与参数设置
本文实验平台使用开源的深度学习框架PyTorch,编译语言为Python3.6 版本。由于深度学习模型对计算资源的要求相对较高,因此采用GPU 进行训练来提高效率。
在训练阶段,使用Adam 优化器对模型进行优化,并使用最大梯度范数为2 的梯度裁剪。节点编码器和指针解码器的维度都设为300。在测试过程中,使用集束搜索(Beam Search)方法生成最终的结果。集束搜索衡量了搜索空间和得到最优解概率的双重因素,每步会根据集束宽度K保留概率最大的K个结果并继续按照词表搜索,直到生成过程结束。在模型测试阶段,本文设置Beam Search 的束宽为5。具体实验参数如表2 所示。

表2 实验参数设置Table 2 Experimental parameter settings
4.3 评价标准
本文实验采用自动文本摘要领域常用的评价工具ROUGE 中的ROUGE-1、ROUGE-2 以及ROUGE-L这3 类评价指标的F1 值来评估摘要质量。其中,ROUGE-1 代表了自动文本摘要的信息量,ROUGE-2侧重于评估对话摘要的流畅性,而ROUGE-L 则基于最长公共子序列,可以认为是摘要对原文信息的覆盖量。ROUGE 值度量了生成的摘要与目标摘要的接近程度。
4.4 结果分析
4.4.1 基准实验对比分析
为验证所提方法在生成式对话摘要任务中的效果,本文选取了7 种基线模型进行对比实验。
1)Longest-3 是一种提取式摘要方法,选取最长的三句话语按长度排序作为摘要。
2)Seq2Seq+Attention 是由RUSH等[7]提出,使用基于Attention 机制的编码器来学习输入文本的潜在软对齐,以提供摘要信息。
3)PGN[8]是指针生成网络,使用指针机制和覆盖机制解决了生成式文本摘要中的OOV 和摘要重复问题。
4)Transformer是由VASWANI等[25]提出,是一种利用Self-Attention 机制实现快速并行的序列到序列模型。
5)Fast Abs RL[9]是一种基于两阶段式的摘要模型,首先由抽取器选择重要句子,然后生成器对抽取出的句子重写得到最终摘要。
6)Fast Abs RL Enhanced 是Fast Abs RL 的变形,由于原模型可能会选择1 个人的话语而没有关于其他对话者的信息,因此它将所有其他对话者的名字添加到话语的结尾。
7)T-GAT 是本文模型的变形,将异质图层替换为同质图层的图注意力网络(Graph Attention Network,GAT)[26]。
考虑到计算资源有限,本文没有使用预训练语言模型(如BERT)。因此,为了公平起见,本文只和未使用预训练语言模型的方法进行比较。不同模型的实验结果对比如表3 所示,Separator 是人为添加的1 个标记来分隔话语。

表3 不同模型的实验结果对比Table 3 Experiment results comparison among different models %
从表3 可以看出,与原模型相比,使用了分隔符(Separator)使得对应模型的性能有所增加,这是因为通过人工添加特殊标记改善了语篇结构。与传统的抽取式方法Longest-3 相比,T-HDGN 在ROUGE评价指标上获得了较大的提高,说明生成式方法具有明显的优势。与表现较优的Fast Abs RL Enhanced模型相比,在不需要使用强化学习策略和简化训练过程的情况下,T-HDGN 模型在ROUGE 得分上依然具有优势。与同质网络T-GAT 相比,基于异质图网络的T-HDGN 模型在ROUGE-1、ROUGE-2、ROUGE-L上分别提升了0.70、0.98 和0.61 个百分点,表明异质性建模具有一定的有效性。此外,T-HDGN 模型的性能均优于其他生成式方法Seq2Seq+Attention、PGN 和Transformer,说明通过图结构对会话进行建模时,异质图网络可以有效地融合信息并捕获语句间丰富的语义关系,解决了对会话上下文理解不充分的问题。此外,使用行动三元组有助于模型理解说话人与其对应动作之间的正确关系,提高摘要的生成质量。
4.4.2 消融实验
为验证该模型中主要模块对生成对话摘要的有效性,本文进行消融实验,验证对话图中行动节点和对话者节点这2 种不同类型节点的有效性。消融实验结果如表4 所示,T-HDGN w/o action 表示移除对话图中的行动三元组节点,T-HDGN w/o speaker 表示移除对话图中的对话者节点。

表4 消融实验结果Table 4 Ablation experimental results %
缺失行动三元组节点和对话者节点均降低了模型生成摘要的效果。其中,移除行动三元组节点使得ROUGE-1、ROUGE-2、ROUGE-L 评分分别降低了0.48、0.67 和0.71 个百分点,这表明加入行动三元组(Who,Doing,What)有助于模型更充分地对会话上下文建模。此外,如果直接移除图中的对话者节点,将造成话语没有对应的说话人。因此,本文首先在话语前面加上说话人,然后移除对话者节点。实验结果表明,移除对话者节点也导致了模型性能下降,说明异质性建模对话者节点能够更充分地学习到会话的上下文表示,有利于最终摘要的生成。
此外,为了验证在指针机制和覆盖机制中融入主题词对生成摘要的有效性,同样进行消融实验,结果如表5所示。T-HDGN w/o TP表示移除主题词的指针机制,T-HDGN w/o TC 表示移除主题词的覆盖机制。

表5 消融实验对比结果Table 5 Comparison results of ablation experiments %
从表5 可以看出,在移除了覆盖机制和指针机制中的主题词后,模型性能都不如完整的T-HDGN 模型,说明对于关键信息分散在不同话语中的会话,主题关键词有利于模型生成信息丰富且真实的对话摘要。
4.4.3 对话者数和转换数对模型的影响
为了探究会话中对话人数和转换数对ROUGH指标的影响,本文在表现最佳的T-HDGN 模型上进行实验分析,其可视化结果如图7 所示。实验结果表明,随着对话人数和转换数的增加,ROUGH 指标呈逐渐下降趋势,表明在生成式对话摘要任务中随着会话参与人数和话语数的增加,总结对话的难度就越大。

图7 参与者数和转换数对模型性能之间的影响Fig.7 The impact of the number of participants and conversions on model performance
4.4.4 泛化性实验
为验证模型是否具有较优的泛化能力,本文直接在由人类编写的辩论对话摘要数据集ADSC 上进行泛化性实验测试,结果如表6 所示。

表6 在ADSC 数据集上不同模型的ROUGE 结果Table 6 ROUGE results among different models on the ADSC dataset %
从表6 可以看出,T-HDGN 模型在ADSC 数据集上的表现均优于其他基线模型,说明本文模型可以更充分理解新领域中的对话,在生成式对话摘要任务中具有较优的应用价值。其原因为在生成摘要时,一方面通过显式建模“Who,Doing,What”信息以帮助模型更好地理解说话者和话语内行动之间的关系;另一方面,通过1 个异质图网络来建模不同类型的数据,合理地编码会话结构。同时,基于T-HDGN 模型的对话摘要生成模型也可以应用于其他领域,如在线医疗问诊的总结以及人机对话的下游任务。
4.4.5 摘要实例对比分析
不同模型针对如下对话生成的摘要示例对比如表7 所示。

表7 不同模型生成的摘要示例Table 7 An example of summary generated by different models
Lilly:sorry,I'm gonna be late.
Lilly:don't wait for me and order the food.
Gabriel:no problem,shall we also order something for you?
Gabriel:so that you get it as soon as you get to us?
Lilly:good idea!
Lilly:pasta with salmon and basil is always very tasty there.
从表7 可以看出,传统的抽取式摘要模型Longest-3 与生成式摘要模型的效果差距明显,这主要是因为与新闻等文本不同,对话类数据的信息比较分散,前几句很少涉及关键信息,导致抽取的摘要效果不佳。对于Fast Abs RL Enhanced 模型,由于事先在每句话语之后添加了其他对话者的名字,因此模型在生成摘要时能正确包含说话人的名字。然而,Fast Abs RL Enhanced 模型在决定动作由谁做出时出现错误,这可能与该模型的两阶段式生成过程有关,再加上对话的特殊文本结构,导致对话的上下文范围缩小,从而生成不正确的内容。与其他的序列到序列模型相比,T-HDGN 模型能正确决定动作由谁做出。这是因为本文明确建模“Who,Doing,What”信息有助于模型更好地理解说话者和话语内行动之间的关系。此外,在译码阶段还使用主题词来引导解码器生成摘要,使得摘要中包含更多的关键信息。
5 结束语
本文建立一种主题词引导的异质对话图网络(T-HDGN)模型,以图到序列的框架自动生成对话摘要。利用从话语中抽取的“Who,Doing,What”信息构建对话图,将图中的话语、对话者和行动节点作为异质节点,通过1 个异质图网络对会话图进行编码。此外,在生成阶段融入主题信息以辅助摘要生成。实验结果表明,与传统的文档摘要模型相比,T-HDGN 模型可以正确地将对话者与其对应动作相关联,并且生成的摘要中包含更多的关键信息,更接近目标摘要。后续将使用预训练语言模型更好地编码会话表示,还将针对具体的应用领域改进对话总结模型以适用于各个领域,如医疗对话、客服对话、辩论以及可能涉及更长话语和更多非同步参与者的对话。
