基于适应性训练与丢弃机制的神经机器翻译
2023-10-17段仁翀段湘煜
段仁翀,段湘煜
(苏州大学 计算机科学与技术学院,江苏 苏州 215000)
0 概述
字或词可以被认为是组成语言的基本单位,然而,人们经常使用短语来表达具体的含义。例如,考虑“Machine translation is a branch of computational linguistics”这句英语译文,如果将句子分割为:“[Machine translation][is][a branch of] [computational linguistics]”,则会变得更容易理解,其中每个括号中的词组成一个短语。如果这些短语没有被准确翻译,则在很大程度上影响译文质量。
传统的基于短语的统计机器翻译(Statistical Machine Translation,SMT)方法已被证明优于基于单词的方法[1-3]。然而,在现代神经机器翻译(Neural Machine Translation,NMT)方法[4-6]中关于短语的工作主要利用外部工具生成的短语来为神经网络模型提供额外的信息[7]。例如,文献[8]使用SMT 模型生成的短语来扩展波束搜索,文献[9]使用SWAN[10]方法来获得短语结构并进行建模。然而,除了外部短语信息外,即使是在训练集中出现过的短语,模型也不能准确翻译。经过测试,在WMT14 英德数据集中,对于训练集中4 个词组成的短语,标准的NMT模型的翻译准确率只有27.5%,表明大量短语没有被准确翻译。因为NMT 模型最小化每个词的损失,这导致无显式的约束来记忆短语,所以即使是训练集中的短语也会被误译。
使用基于词级别的适应性训练来约束模型记忆短语,这类方法通过为每个词分配不一样的权重来鼓励模型专注于特定词的翻译。例如,因为标准的Transformer[11]对于低频单词 翻译准确率较低,文献[12]约束模型关注低频并且有意义的词,该方法缓解了模型过度拟合高频词而忽视那些低频词的问题。文献[13]旨在使用双语互信息(Bilingual Mutual Information,BMI)来衡量词的学习难度,对于容易学习的词分配较大的权重,不容易学习的词分配较小的权重。
本文提出一种短语感知适应性训练(Phrase Awareness Adaptive Training,PAT)方法,旨在鼓励模型记忆短语。该方法将NMT 产生的目标句子中词级别损失周期性变化的片段提取为短语,基于模型产生的短语,根据每个词在短语中的相对位置调整其权重,短语中靠后的词分配较大的权重。此外,神经机器翻译系统在解码时采用自回归机制,导致误译的短语对后续的译文造成负面影响,为此,提出短语丢弃(Phrase Drop,PD)机制,即在训练中随机丢弃目标端的短语,鼓励模型从源端和已经生成译文中发掘更多信息,增加模型对误译短语的鲁棒性。
1 相关工作
1.1 适应性训练
由于传统的神经网络模型在训练中为每个单词都分配一样的权重的方案,没有考虑到每个单词具有不同的重要程度[14],因此产生了通过考虑某些附加信息为目标端词分配不同的训练权重的方法,被称为适应性训练。文献[12]认为低频词在训练中难以训练,应当具有更高的训练权重,所以提出了两个启发式目标函数,为不同频率的目标词分配不同的权重。对于Exponential 目标,权重随着频率的降低而单调增加;对于Chi-Square 目标,只有那些有意义但相对低频的词可以分配更大的权重。文献[13]认为对于那些一词多义的单词应当在训练中有更高的宽容度,适当降低一词多义单词的训练权重,因此提出了词级别的训练目标BMI,从双语的角度衡量每个词的学习难度,并动态调整单词权重。之前的研究仅使用词级的辅助信息,而本文方法使用短语级辅助信息,目的是为了通过改变权重来约束模型记忆短语。
1.2 基于短语的方法
基于短语的方法广泛用于传统的SMT 方法,并已被证明优于基于单词的方法[15-16],但在当前NMT方法中,以往大多数的工作都集中在利用外部工具生成的短语上,文献[8]引入一种基于注意力的混合搜索算法,该算法通过SMT 的短语翻译扩展了NMT的波束搜索。文献[17]通过将短语存储器中的目标短语集成到NMT 中来翻译短语,其中短语存储器由SMT 模型提供,然后NMT 解码器从短语存储器中选择一个短语或从概率最高的词汇中选择一个单词来生成。文献[9]提出使用SWAN[10]对目标语言中的短语结构进行建模。本文方法利用模型本身的性质来查找短语并改善翻译质量,而无须额外的参数或信息。
1.3 知识迁移
知识迁移是利用数据或特征更丰富的老师模型来提升数据或特征相对较匮乏的学生模型的性能,它可以用不同的形式实现,例如,文献[18-20]使用的知识蒸馏,文献[21-23]通过在大量的无监督数据上训练一个超大的预训练模型,然后在此模型基础上只需要极小的有监督数据进行微调,就可以取得比大量有监督数据从零开始训练模型更好的效果,如在机器翻译领域上的应用[24-25]。本文主要使用适应性训练将短语知识从教师模型迁移到学生模型。
2 神经机器翻译模型
2.1 基本框架
本文采用由编码器与解码器构成的自注意力Transformer 模型作为主干模型,模型的学习目标是通过给定一个源句子x={x1,x2,…,xN},NMT 模型逐字预测目标句子y={y1,y2,…,yT} 的概率P(y|x),计算公式如下:
其中:y<t={y1,y2,…,yt-1}是时间步t之前的部分翻译。NMT 的训练目标是最小化负对数似然Lce,NMT,也称为交叉熵损失函数,计算公式如下:
每个时间步t的单词损失Lt的计算公式如下:
为了鼓励模型更多地关注目标句子中特定的词,文献[12]将词级适应性目标纳入NMT 模型训练,损失函数如下:
其中:wt是分配给目标词yt的权重。在理想情况下,每个目标词的权重应该不同,因为它们在翻译中具有不同的难度和重要性,但是在传统的机器翻译模型中所有词的权重都相同,无法体现出个别单词的重要性。文献[12]通过使用词频信息来调整,文献[13]使用包含源语言和目标语言的互信息来计算调整wt,然而仅仅考虑每个词的重要性还不够,还需要进一步考虑词在短语中的重要性。本文通过分配适当的wt来约束模型记忆训练集中的短语,提高模型的翻译质量。
2.2 短语感知适应性训练
短语感知适应性训练方法的目的是通过引入显式约束来增强模型对于短语的记忆能力,短语感知适应性训练框架如图1 所示。

图1 短语感知适应性训练框架Fig.1 Framework of phrase perception adaptive training
该方法分为以下2 个步骤:
1)基于一个训练好的NMT 模型预先从训练集中分割短语,得到短语表。
2)基于短语表加权适应性目标并训练模型。
2.2.1 基于损失的短语分割
为了增强模型的短语知识,将训练集中的句子分割成短语,获得短语表。
给定一个句子对{x,y},其中,x是由N个单词xi组成的源序 列(x1,x2,…,xN),y是由T个单词yi组成的目标序列(y1,y2,…,yT),N和T分别是x和y的长度。通过式(3)得到目标句子y的标记级损失L=(l1,l2,…,lT),其中li是yi的损失。
对于目标句中的每个单词yi,都有一个值pi来确定yi在某个短语中的相对位置。例如,考虑句子“他说他喜欢苹果”,即Y=(He,said,he,likes,apples)。假设[He say]和[he likes apples]是Y中的2 个短语,那么对于yi,即“He”,设置它的位置p1=1,因为yi是第1 个短语的开始。通过类比,得到p=(1,2,1,2,3)。本文通过NMT 模型本身学习的短语知识来得到p。pi的计算依赖于前一个词的损失li-1。如果li-1大于当前损失li,这意味着单词yi和yi-1在同一个短语中,那么将yi附加到yi-1所在的短语中,即pi=pi-1+1;否则,将当前词yi为新短语的开始,即pi=1。根据上述描述,有:
其中:超参数α控制构成短语的宽容度。α允许那些损失不严格小于前一个单词损失的单词合并到前一个短语中。将P=(p1,p2,…,pn)称为短 语表,n是训练集上所有的句子数。
2.2.2 短语感知适应性训练目标
基于第2.2.1 节的方法,从训练集中得到了每个目标句子的词级别损失L=(l1,l2,…,lT)和短语表P=(p1,p2,…,pn),其中n是训练集大小。为了缓解短语遗忘问题,设计短语感知训练目标来约束NMT模型记忆短语,遵循2 个步骤:1)缩放不同单词的权重和;2)适应性训练目标。
基于L 和P,计算每个词在其短语中的相对位置k的平均损失ak:
其中:p∈P,l∈L 表示遍历所有句子。如果pi=k,指示函数Ipi=k值为1,否则为0。然后,得到第k位置的权重:
其中:a1表示短语中第1 个单词的平均损失。在导出短语中每个相对位置pj的值s(pj)后,计算式(4)中每个词级别权重:
每个词的默认权重为1,根据其位置添加额外的权重A·s(pj),超参数A控制s(pj)变化的幅度。
上述公式会对同一短语中靠后的词分配较大的权重。直观地说,较大的权重约束模型提高后续词的预测概率,从而鼓励模型找到更多的语法语义信息来记忆短语。
2.2.3 短语分割分析
本节首先通过实验证明第2.2.1 节短语分割的合理性,然后通过示例来说明损失进行短语分割的含义。
理想的短语产生方式是:对于同一种语言,不同的模型可以产生一致的短语表,而不是各自不同的短语表。
所以,通过计算不同模型的损失之间的皮尔森系数,来量化地证明上文方法可以用作分割短语的合理性。从原始NIST 中英训练集中随机抽取10、50和125 万数据作为训练集,分别训练标准的Transformer 模型,并计算两两之间在验证集上生成的词级损失的皮尔森系数,值越高,表示不同模型生成的短语越相似。计算公式如下:
其中:lx和ly分别表示相同句子下x和y这2 个模型的词级别损失;ρ(·,·)表示皮尔森相关系数函数;AVG(·)表示求训练集中所有句子的皮尔森相关系数的平均值。
任意2 个模型之间较高的皮尔森系数揭示了不同模型间的词级别损失走势存在统计学上显著的相关性,这表明不同的模型会产生较为一致的短语。结果如表1 所示。
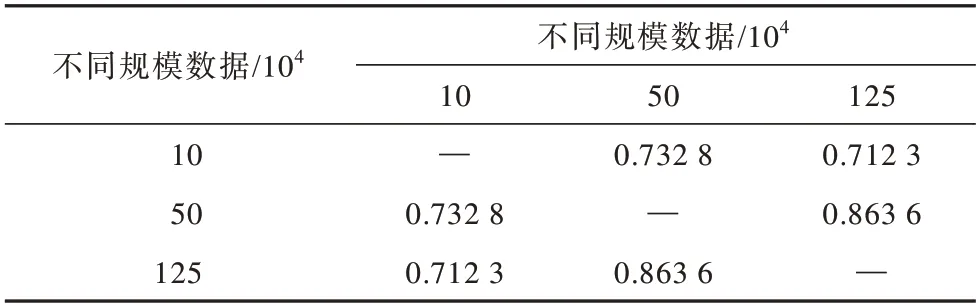
表1 不同规模数据下模型的皮尔逊系数Table 1 Pearson coefficient of model under different scale datas
下文使用一个例子阐述损失分割短语的含义,其中不同下划线区间表示不同短语。标准的神经网络模型在推理中会对目标句中的每个词计算损失l=-loga p,其中,p表示模型对于每个单词的预测概率,概率越大,那么对应的损失也就越小。
目标端句子:
The objective is to allow the patient to become pregnant with a baby using the new uterus.
对应的词级别损失值:
1.61 2.48 1.59 1.56 2.08 1.79 1.60 1.44 4.03 2.66 1.98 1.89 1.71 4.01 1.58 1.56 1.51 1.49
上述示例展示了模型对于某个目标句子y 的词级别损失。可以看到,损失的变化趋势有一个清晰的模式,即它在某一个词中跳到峰值,然后慢慢减少,波动在整个句子中持续存在。这种模式揭示了翻译模型在推断过程中会突然遇到某个难以生成的单词,然后后续的单词生成难度会逐渐降低直到等到下一个特别难生成的单词。
以上述示例中的一个小片段为例,考虑记为Φ的段[become pregnant with a baby],损失在Φ 的开头上升到一个峰值(“become”),即生成它的概率最小,这是因为在这个位置有许多可行的单词翻译,例如(“get”,“to”,“be”)等。
第1 个单词(“become”)确定下来后,Φ 中后续词的搜索空间由于语法或语义约束而变小,在表达相同意思下翻译出(“pregnant”)的概率大幅增加。
与人讲话类似,人们往往可以非常流利地讲完一个短语,然后在讲下一个短语之前停顿思考。受此启发,本文将模型翻译越来越流利(损失逐渐减小)的片段视作短语。
2.3 短语丢弃机制
丢弃机制可用于增加噪声或者屏蔽无关信息。标准的丢弃机制通过以一定的概率将输入神经元设置为零来防止过拟合[26],预训练模型通过还原被丢弃的词来训练模型,以及在自回归生成任务中对解码端采用丢弃机制来增强模型的鲁棒性。
神经机器翻译模型在解码时采用自回归机制,当前词的生成需要依赖以前词,这就导致如果一个短语翻译错误会影响后续短语的翻译。为了解决这个问题,本文结合传统的丢弃机制提出短语丢弃机制。该方法在训练中随机丢弃目标句子中的短语,来模拟推断过程中短语翻译错误的情况,如图2 所示,将词V3到词V5组成的短语使用UNK 标签替换,用来模仿在推理过程中有些短语没有被准确翻译的情况,以此鼓励模型从源端或已经生成的文本中发掘更多语法或语义信息。
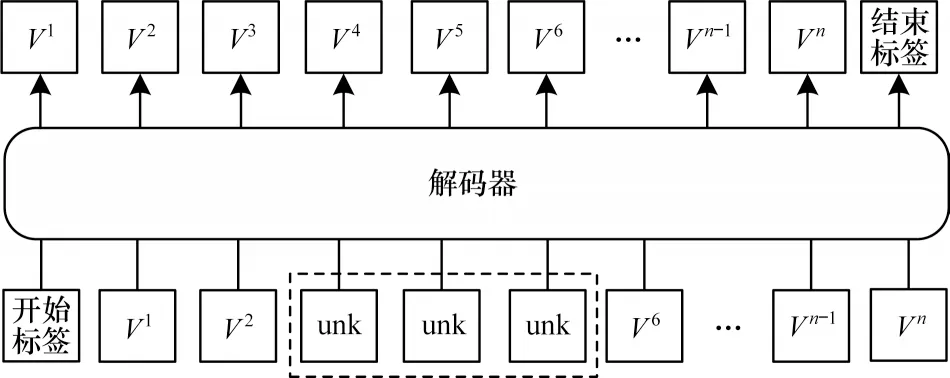
图2 短语丢弃机制示意图Fig.2 Schematic drawing of phrase drop mechanism
具体来说,使用第2.2.1 节的方法将句子分割为短语,并以一定概率随机丢弃短语片段,其中每个短语的丢弃概率设置为15%,这个概率在预训练模型中被广泛使用,能够取得较好的性能。
3 实验准备
本文在广泛使用的WMT14 英语到德语、NIST汉语到英语任务上进行实验。这两个任务使用multi-bleu.perl 测量区分大小写的BLEU值[27]。
3.1 实验设置
3.1.1 数据准备
数据准备主要有以下2 种:
1)汉语到英语。使用LDC 语料库作为训练集,它由125 万个句子对组成,分别有2 790 万个中文词和3 450 万个英文词。采用MT06 作为验证集,MT02、MT03、MT04、MT05 和MT08 数据集作为测试集。使用Moses 脚本对英语句子进行去噪,并根据Stanford Segmentor 脚本对中文句子进行分词,采用字节对编码(BPE)和32 000 次合并操作。
2)英语到德语。训练数据包含从WMT2014 英德数据集收集的450 万句子对,分别有1.18 亿个英语单词和1.11 亿个德语单词。将newstest2013 作为验证集,并在newstest2014 上测试模型。语料库中的每个单词都使用字节对编码(BPE)[28]分割子词单元,使用源端目标端共享词表。
3.1.2 训练设置
通过使用名为Fairseq[29]的开源工具来实现Transformer 系统。特别是对于中英,dropout 设置为0.3,在目标嵌入层和输出层之间共享相同的权矩阵。使用8 个GPU,每个GPU 的批次大小为4 096。其他超参数与Vaswani等[11]中的默认配置相同,即使用6 层的编码器与6 层的解码器,隐状态维度为512,标签平滑设置为0.1,并使用Adam 优化器,学习率设置为0.000 7。
本文提出方法中有2 个重要的超参数,即α和A。为了减少搜索空间,首先将A设置为1,并通过搜索调整验证集上的超参数α,即α∈ {0.00,0.15,0.30,0.45,0.60}。对于2 个语言对,α的最佳值为0.15。在验证数据集上调整超参数A,结果如表2 所示。最后,使用在验证数据集上找到的最佳超参数来最终评估测试数据集,中英为A=1.4、α=0.15,英德为A=1.5、α=0.15。

表2 超参数A 与不同语言对的BLEU值Table 2 Hyperparameter A and BLEU values for different language pairs
3.2 实验基线
本文重新实现以下基线,并将其与提出方法进行比较:
Transformer:基线系统严格按照Vaswani等[11]的基础模型配置来实现。
Exponential:该系统使用适应性训练目标[12]。权重由指数形式产生,对于低频词会获得更高的权重,对于高频词会获得更低的权重。
Chi-Square:该方法使用卡方分布作为权重函数来增加低频词目标词的训练权重[12]。
BMI:与前2 种方法类似,这种方法通过计算互信息来估计源端词和目标端词之间的学习难度,然后为容易学习的词添加额外的训练权重[13]。
Hybrid:该方法使用统计机器翻译模型生成短语,然后使用短语对扩展波束搜索[8]。
NPMT:该方法对输出序列中的短语结构进行建模,并且引入了一个新的层来对输入进行局部重新排序[9]。
4 实验结果
4.1 结果分析
表3 所示为基线模型和提出方法在NIST 中英和WMT2014 英德翻译任务上的性能,Δ为与标准Transformer 相比的改进。从表3 可以看出,提出方法在几乎不需要任何额外的计算或存储消耗就能带来比Transformer 更加稳定的改进。与标准的Transformer 相比,在NIST 中英翻译任务和WMT2014 英德翻译任务的7 个测试集中,其中有5 个测试集取得了最优的性能,BLEU 值分别提高了1.64 和0.96。

表3 中英和英德翻译任务上的BLEU值Table 3 BLEU values on Chinese-English and English-German translation tasks
实验结果证明了本文提出方法的有效性。增加模型对短语的记忆能力及对误译的短语的鲁棒性,可以帮助神经机器翻译模型取得更好的翻译质量。
4.2 消融实验
消融实验如表4 所示,分别移除短语感知适应性训练目标和短语丢弃机制以测试其对模型的影响。移除短语感知适应性训练目标会显著降低模型的BLEU值,相比之下,移除短语丢弃机制也会导致BLEU 值明显下降,但是下降幅度较小。其中,移除短语分割表示不使用本文提出的短语分割方法,而使用文献[13]提出的短语分割方法。实验结果证明了本文方法的有效性。
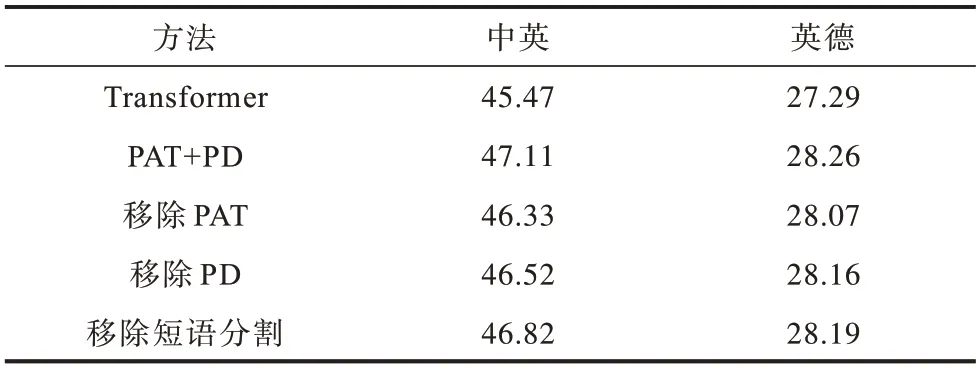
表4 消融实验结果Table 4 Results of ablation experiment
4.3 短语感知适应性训练对于模型记忆短语的影响
为了验证PAT 方法对记忆短语的有效性,首先对于中英翻译任务,将MT02到MT08测试集相连接作为一个大测试集。对于英德翻译任务,使用原始测试集。同时,本文定义一个比率为目标句子评分,公式如下:
如图3 所示,PAT 方法在中英和英德的Familiar子集上的BLEU 值分别比基线提高了1.39 和1.14,表明加强模型的短语记忆可以在具有更熟悉短语的翻译中获得更出色的性能,并且不会在包含更多不熟悉短语的任务上牺牲翻译质量。标准的NMT 系统对训练集中的N-gram 短语的翻译准确率较低,部分原因是缺乏约束来记忆短语。

图3 不同中英和英德测试子集上的BLEU值Fig.3 BLEU values on different Chinese-English and English-German test subsets
将训练集分别按照1-gram 到4-gram 的短语粒度划分出所有短语,并在所有基线模型与PAT 方法上测试不同短语粒度的翻译准确率,如表5所示。
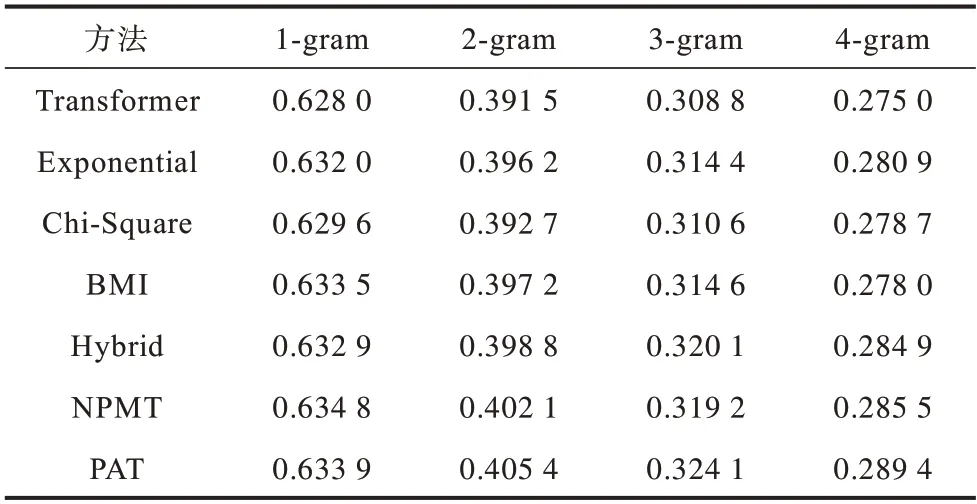
表5 英德任务上训练集中n-grams 短语的翻译准确率Table 5 Translation accuracy of n-grams phrases in the training set on English-German tasks
从表5 可以看出,本文方法在提高n-gram 的翻译准确率方面优于其他方法。同时也可以看出,相比1 个单词的1-gram 短语,4 个单词的4-gram 短语明显准确率更低,这显示了模型对于长短语很差的记忆能力。
4.4 短语知识迁移
表1 的实验显示(见第2.2.3 节),对于同一种语言,本文的短语感知适应性训练会产生一致短语,意味可以将短语知识从教师模型转移到学生模型。
从原始NIST 中英训练集中随机抽取3 万、10 万、25 万和50 万数据作为训练集。从WMT2014英德任务的训练集中随机抽取10 万和25 万作为训练集,并在所有上述6 个训练子集上训练标准Transformer 模型和PAT模型(使 用PAT 方法的Transformer 模型)。
在相同的配置下训练基于老师模型短语表的PAT(PAT+Teacher)模型,验证翻译质量是否比使用学生模型短语表的PAT 模型更高。老师模型在原始的125 万中英任务上训练。
表6 所示为各个模型在测试集上的结果。首先与标准Transformer 相比,PAT 在不同大小的训练集下的BLEU 值都表现出明显提升,并且随着训练集大小的增加变得更加明显。这主要是因为NMT 模型由于训练集太小而造成模型的过度拟合,导致生成的短语表质量很差。将PAT 与PAT+Teacher 进行比较,发现PAT+Teacher 的翻译性能优于PAT,证明短语知识可以从老师模型迁移到学生模型来进一步提升翻译质量。

表6 不同规模训练集上NMT 模型的BLEU值Table 6 BLEU values of NMT models on training sets of different sizes
5 结束语
标准Transformer 模型对训练集中的短语具有较低的翻译准确率。为了解决模型对于短语记忆能力差的问题,本文提出短语感知适应性训练,训练一个基本的神经机器翻译模型,根据模型对每个词产生的损失来分割短语,并对每个词在短语中的相对位置分配不同的权重。此外,为了缓解误译的短语对后续译文的影响,提出短语丢弃机制,增加模型对于误译的短语的鲁棒性。实验结果表明,提出方法提高了训练集中短语的翻译准确率,此外将老师模型的短语知识迁移到学生模型可以获得更高的翻译质量提升。下一步将研究基于短语知识的干预翻译,通过将干预词限制在短语的第1 个位置来提高翻译的保真度,另外利用外部短语知识增加模型的短语知识,如通过大量的单语语料来训练一个大的老师模型,将老师模型的短语知识迁移到学生模型上。
