丢弃冗余块的语音识别Transformer 解码加速方法
2023-10-17赵德春舒洋李玲陈欢张子豪
赵德春,舒洋,李玲,陈欢,张子豪
(1.重庆邮电大学 生物信息学院,重庆 400065;2.重庆邮电大学 自动化学院,重庆 400065)
0 概述
自动语音识别是最便捷的人机交互技术之一,目的是让机器自动将人类语音信号转变为对应的文本信息。当前,主流的语音识别方法是单一神经网络结构组成的端到端模型,主要有3类,分别为连接时序分类器(Connectionist Temporal Classification,CTC)[1-2]、循环神经网络换能器(RNN-Transducer,RNN-T)[3-4]以及基于注意力机制的编解码模型(Attention-based Encoder-Decoder,AED)[5-7]。端 到端模型将传统语音识别系统中的声学、发音和语言模型整合到一个网络结构中,使得它们可以只针对一个目标函数进行优化,识别准确率更高[8]。
CTC 通过引入空白符来实现语音序列与文本序列的对齐表达,使用动态规划策略高效地寻找所有潜在的对齐路径,结合前馈网络层使得模型能快速得到帧级别的分类输出。然而,模型因未考虑字与字、语句关系的独立性假设,严重限制了模型的性能。RNN-T 在解码时以语音编码结果和之前的输出序列共同作为输入,同时结合额外的预测网络实现了对声学模型与语言模型的共同优化。RNN-T 在流式识别任务中相比其他结构更有优势,但是模型不容易训练,即使使用预训练的方法,其训练过程也很繁琐[9]。AED 模型通过注意力机制实现声学特征帧与文本信息的软对齐,这种方式使得输入序列与输出序列可以不严格对齐,因此,模型具有更强的上下文建模能力。但是,对于强对齐特性的语音识别任务,容易导致模型的训练因盲目对齐而耗费大量时间。为此,CTC/Attention 混合模型[6,10]将CTC引入AED 模型的编码器网络中,利用CTC 损失函数计算时的严格单调性加强模型对编码器的对齐约束。这种多任务学习方式既能加快模型的收敛速度,又能提高模型的鲁棒性。
另一种基于自注意力机制的编解码器模型Transformer[11]因具有强大的上下文建模能力和高效的训练方式,在语音识别任务中也取得了巨大成功。语 音Transformer模型[9,12-13]由编码器与解码器2 个部分构成,它们均由自注意力层与前馈网络层组成的网络块加残差的连接方式堆叠而成。Transformer解码器的工作方式与其他AED 模型一样,解码当前时刻时需要之前解码结果与全部编码器的声学特征,这导致解码时间较长,限制了模型的应用[13]。为此,文献[14]通过池化CTC 尖峰序列生成具有分段表示能力的编码器输出掩码序列,使用更多置零的掩码在Transformer 交叉注意力层实现编码特征的压缩表达,加快该层的计算过程,提高解码速度。虽然置零掩码加速了部分解码计算过程,但是并没有真正减少解码器的计算量。针对编码声学特征的紧凑型表达,文献[15]使用自动编码器来产生分段的紧凑型语音表示,但是这显著增加了语音识别任务的建模难度与训练成本。
为了进一步加快语音识别Transformer 解码过程,本文提出一种丢弃冗余块(Discarding Redundant Blocks,DRB)的Transformer 解码加速方法。该方法利用CTC 分类器产生的尖峰序列去除编码器输出特征中连续冗余的空白帧,减小解码器所需的特征序列长度。在CTC/AED 模型结构中为避免盲目对齐所产生的额外训练开销,DRB 使用微调的方式单独训练Transformer 解码器,以解决训练与识别不匹配的问题。同时,为了减小CTC 对编码特征冗余帧判断的误差,引入Intermediate CTC 结构提高模型训练时对编码器的约束能力。
1 相关理论基础
1.1 语音Transformer 解码器
语音Transformer 模型[12]是基于自注意力机制的编解码网络,模型结构由多头自注意力层、前馈网络层、提供序列位置信息的位置编码模块组成,每层之间使用层归一化与残差连接的方式来增强训练时的稳定性。Transformer 解码器与编码器在网络结构上相似,不同之处在于解码器中有一个自注意力层查询矩阵是文本序列,而对应的键与值都是编码器输出的声学特征序列,这也被称为交叉注意力层,它使得解码器中的语言信息可以与声学信息相互融合,模型在解码时不仅能够看到之前解码的上文语言信息,还能参考声学上下文信息,从而更准确地预测下一个词。解码器中主要的网络堆叠块计算如下:
其中:Zj、Zj+1分别为第j层的输入与输出;Xe是编码器输出的声学特征;FFN 表示前馈网络层;MHSAself与MHSAcross都是多头注意力层,输入参数依次为自注意力查询、键、值矩阵。
解码器以编码器输出的编码特征与之前解码结果作为输入,进行反复迭代计算,直到识别出特殊的停止字符。解码计算过程如下:
其中:Yt是长度为T的目标文本序列YT在t时刻的解码输出;Decoder(·)表示解码器;Xe表示编码器输出的语音特征序列。
1.2 两阶段重打分的非自回归解码方式
Transformer 模型在解码时通过引入之前时刻的解码结果[见式(2)],为解码过程引入了充足的语言信息,从而有效提高了识别准确率。但是,这种迭代计算的解码方式无法并行化,给模型解码带来了较高延时。为实现快速解码同时避免Transformer 解码器的自回归解码过程,文献[9]提出两阶段重打分的非自回归解码方式。该方式在CTC/Attention 混合模型中使用Transformer 解码器为CTC 解码的N个概率中最高的结果重新评分,根据2 次评分权重取最终结果。对于每个需要重打分的结果,Transformer 解码器只需进行一次前向计算而无须迭代计算,因此,这种非自回归解码方式的解码速度更快。在WeNet[16]中,第一阶段解码使用CTC 前缀波束搜索方式来获得N个结果,在AISHELL-1 数据集[17]中取得了较先进的识别结果。
1.3 Intermediate CTC
CTC 利用高效的动态规划算法,通过计算所有可能存在的对齐序列概率来求取给定目标序列的最大后验概率。将CTC 作为神经网络的损失函数,可以使模型无须帧级别的标注即可得到帧级别的分类预测输出,这将大幅简化语音识别任务中的声学建模过程。给定帧数为T的语音输入特征XT,模型输出正确标签序列YL的后验概率为P(YL|XT),计算如下:
其中:QT表示YL的某一个有效对齐序列(指通过合并重复字与删除空白符能得到的目标序列);B-1(YL)是YL有效序列的集合。
在模型训练时,最小化给定标签序列的后验概率负对数值即可,损失函数如下:
CTC 简单有效,成为最早也是最广泛应用的端到端语音识别技术。最近有研究表明,CTC 损失函数不仅能作为ASR 端到端模型的优化目标,还能将其扩展到编码器网络的底层,用来加强对编码器前端网络的约束,提高模型的收敛速度与鲁棒性,达到正则化的目的[18-19],这种方法被称为Intermediate CTC。在模型训练时取编码器的中间层输出作为额外的CTC 损失值,与编码器最后层的损失共同优化模型,计算方式如下:
其中:ω为超参数;Xl、Xl/2分别表示堆叠块数为l的编码器中第l层与第l/2 层的输出序列。
2 DRB 方法
2.1 DRB 方法流程
CTC 模型的尖峰现象如图1 所示,横轴表示语音特征序列,纵轴表示每帧对应每个字符(建模单元为字)的概率,不同曲线表示不同的字符(类别),其中,[空白帧]表示CTC 引入的空白字符。图1 中语音特征共61帧,对应的文本信息为“加速识别解码”。
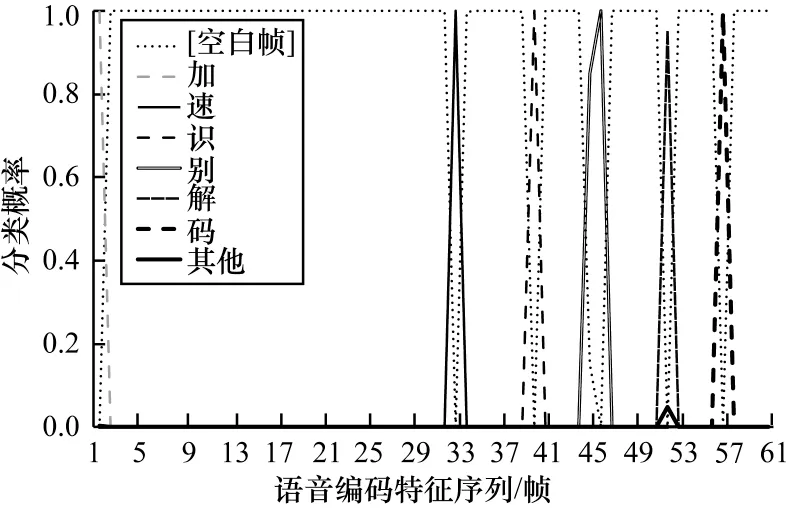
图1 CTC 尖峰现象示意图Fig.1 Schematic diagram of the CTC spike phenomenon
CTC 尖峰现象是指模型输出的后验概率序列中某一帧的后验概率集中在某一个词(类)上,而不是分散在几个词中。根据CTC 模型最大化给定序列对应后验概率的优化准则,可以将其理解为模型对尖峰帧比其他帧有更确定的判断。如果空白帧的概率越大,就表明这一帧的声学特征包含的文本信息越不丰富,仅为空白信息,即编码器输出特征中的连续空白帧是不重要的声学特征,而非空白帧中会包含相邻区域中更显著、有用的文本信息。因此,通过去除这些连续空白冗余帧,可以实现对编码器输出声学特征序列的有效压缩,即编码特征的紧凑型表达。然而,并不是所有空白帧都是毫无意义的,根据CTC的建模假设,它可以作为词音频信息片段解码时的重要分界标志。因此,在去除冗余帧时应适当保留部分空白帧。
本文提出编码特征的紧凑型表达处理方式——DRB。DRB 作用于模型的编码器输出端,依靠CTC尖峰序列去除编码输出特征中的冗余部分,实现对解码声学特征的紧凑型表达,进而减小解码器的计算量,提高解码效率。DRB 方法流程如图2 所示。
2.2 模型结构
为了确保模型拥有较好的识别性能以及较快的收敛速度,本文网络模型主体使用CTC/AED 多任务学习结构的Conformer[16]。使用DRB 方法的模型结构如图3所示,由Conformer 编码器[20]、CTC模块、DRB 处理层和Transformer 解码器等4 个部分组成。
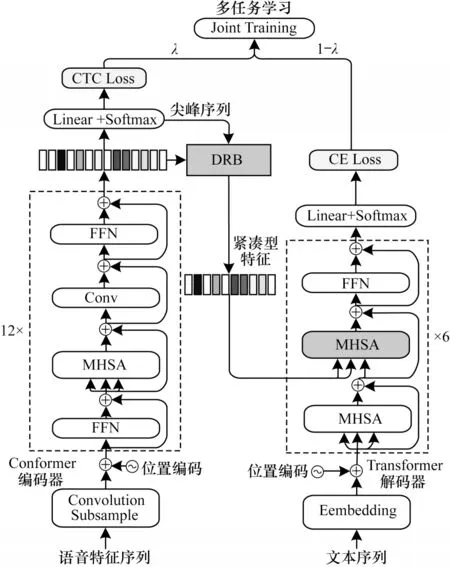
图3 使用DRB 方法的Conformer 模型结构Fig.3 Conformer model structure using DRB method
Conformer 编码器通过添加卷积层增强Transformer 编码器捕获语音序列局部信息的能力,使它能更适合语音与音频建模[21]。CTC 模块主要由全连接层和Softmax 函数组成的分类器构成,它与CTC Loss 函数组合,用于在训练时计算编码器的CTC 损失值,该值以多任务学习的形式辅助模型训练。在模型预测时,通过分类器得到编码器输出的尖峰序列,用于DRB 层实现对编码器输出的紧凑型表达,或进行模型的CTC 解码。DRB 方法的计算过程如图2 所示,根据CTC 分类器剔除不包含丰富文本信息的冗余声学帧,实现对编码器输出特征序列去冗余的目的。因为DRB 中涉及的神经网络层运算只是复用CTC 模块中的全连接层进行分类,所以该方法并没有为模型增加额外的可学习参数。DRB没有改变模型参数的复杂度,用于CTC/AED 结构时仅需微调训练即可使用。使用Transformer 解码器,它由文本词嵌入层、相对位置编码模块、Transformer解码块(见第1.1 节)、Softmax 分类器组成。
2.3 模型训练
因为DRB 方法依赖于CTC 产生的尖峰序列来实现编码器声学特征的紧凑型表达,所以尖峰序列中空白帧判断是否准确对模型最终的识别结果至关重要。为此,通过预训练加微调的方式来训练使用DRB 方法的Conformer 模型,减少模型的盲目对齐训练,加快模型收敛速度。同时,为了减小错误删除部分声学特征帧带来的模型识别精度损失,使用Intermediate CTC 来增强网络对模型编码器的约束,提高CTC 尖峰序列的准确度。模型训练过程如下:
1)预训练。首先不 添加DRB层,Conformer 模型与普通多任务模型(CTC/Attention)训练方式一样,损失函数计算如下:
其中:λ是超参数;Lctc是编码器的CTC 损失值;Latt是解码器的CE 损失值。
如果使用Intermediate CTC 来增强模型对编码器的约束,则模型训练损失函数Lctc应改为LCTC_loss[见式(5)],网络结构无须更改。
2)微调。冻结网络中编码器与CTC 分类器模块的模型参数,使其不参与模型参数的更新训练。添加DRB 处理层,使用处理后的编码声学特征参与解码器的计算。在预训练模型的基础上再次训练解码器,使解码器适应DRB 处理后编码器输出的改变,避免出现模型训练不匹配的问题。因此,微调模型只需要使用交叉熵损失函数来优化解码器参数,即将式(6)中的λ参数赋值为0,即可得到微调训练的模型损失函数。
3 实验结果与分析
3.1 实验数据集
实验开源数据集包括中文语音数据集AISHELL-1[17]与英文数据集LibriSpeech。前者由150 h 的训练集、10 h 的验证集以及5 h 的测试集数据构成,字表由训练集中得到的4 230 个汉字组成;后者包括960 h 的训练集,验证集与测试集均是5.4 h,词表是使用字节对编码算法在训练文本中提取的5 000 个词。
3.2 实验环境
硬件配置:中央处理器AMD®R6930K,运行内存64 GB;显卡型号NVIDIA GeForce GTX 2080。
软件环境:操作系统64 位Ubuntu18.04,深度学习框架PyTorch1.10。
软件工具包 采用WeNet[16],与Kaldi[22]和ESPnet[23]相比,WeNet 完全基于PyTorch 生态,拥有更简洁的语音识别模型框架,并且对AED 模型有更好的优化效果,有利于开展模型的对比实验。
3.3 实验设置
对于所有实验,语音输入特征使用80 维的FBank 信号,帧长为25 ms,帧移为10 ms。在训练过程中使用2 种常用的数据扩充手段,即随机速度扰动和SpecAugment[24],分别是在[0.9,1.1]中随机选取速度扰动值做时域信号处理,以及对每个FBank信号在时域与频率方向都做2 个随机掩码,最大掩码宽度时域T=50,频域F=10。语音特征进入编码器之前,进行倒谱均值方差归一化(CMVN)处理,并通过由2 层2D 卷积组成的下采样层降低模型计算量,卷积核大小为3×3,步长为2。训练时使用Adam 优化器,学习率调整器的预热训练步为25 000。模型的最优参数使用训练收敛后验证集中损失值最低的20 个轮次的平均值。
Conformer 编码器堆叠块个数为12,解码器堆叠块个数为6,多头自注意力层头个数为4,注意力编码维度为256,前馈网络隐藏层单元个数为2 048,多任务学习的权重系数λ=0.3,μ=0.7,Intermediate CTC 共2层,其间隔为4,这2层的权重分别为0.3、0.7。
实验使用2 种不同的解码方式来验证所提DRB方法对Transformer 解码的加速效果,一种是结合波束搜索的传统自回归解码方式,另一种是两阶段重打分的非自回归解码方式。
3.4 结果分析
在测试集上对模型进行性能评估,中文与英文分别使用字错率(Character Error Rate,CER)、词错率(Word Error Rate,WER)作为识别准确率的评价指标,结果保留2 位小数。使用Batch_size=1时,将模型推理时的实时率RTF 作为解码速度的衡量指标,结果保留4 位小数。S-D-I 为计算CER 的编辑距离时产生的错误字个数,错误类型分别是替换、删除、插入。CERR、RTFR 分别是DRB 方法对模型CER 与RTF 改善的相对百分比值。实验解码器的波束搜索参数Beam_size 默认为10。
为了更好地探究DRB 对Transformer 自回归解码的改善效果,在CPU 与GPU 上分别进行测试,实验结果如表1 所示。

表1 AISHELL-1 中DRB 对Transformer 自回归解码的改善效果Table 1 Improvement effect of DRB on Transformer autoregressive decoding in AISHELL-1
从表1 可以得出:
1)观察RTFR 指标可以看出在CPU 上DRB 方法能将解码速度平均提高20%左右,但是DRB 方法在GPU 设备上却没有提升效果,RTF 反而有轻微的下降,最差的RTFR 为-1.2%。导致这种结果的原因可能是DRB 方法通过压缩编码特征序列的长度,减小解码器交叉注意力层的矩阵运算量,从而加快解码计算过程,这对没有矩阵加速运算的CPU 或其他微处理器设备而言,能在反复迭代计算的过程中提升解码速度,但是对于擅长矩阵运算的GPU 而言却没有改善效果,反而会因为DRB 方法导致额外的计算开销,从而使得RTF 轻微变大。
2)观察使用DRB 方法后的CER 指标可以看出,DRB 方法对2 组Conformer 模型的CER 值分别提升3.9%与1.8%,模型识别准确率有轻微下降。这表明DRB 在提高解码速度的同时对模型识别精度有一定损失。通过S-D-I 结果可以看出,“删除错误”为错误增加的主要类型,分析其原因可能是:DRB 是下采样处理,在剔除缺乏文本信息的冗余帧的同时也剔除了其中部分带有文本信息的帧或不正确剔除了有用帧(尖峰序列不准确),使Transformer 解码器在解码时缺失部分声学特征帧信息从而产生额外的删除错误,又因为自回归解码的性质导致模型在后续解码过程中增加了一些其他类型的错误。
3)从实验结果中还可以看出,使用Intermediate CTC 加强模型对编码器的约束,不仅显著提高了模型的鲁棒性,还降低了DRB 给模型精度带来的损失,精度损失减小一半。这是因为DRB 方法依赖模型CTC 尖峰序列来判断是否去除冗余帧,当使用Intermediate CTC 增强对编码器的约束后,CTC 尖峰序列准确性得到提升,DRB 就能更准确地去除冗余帧,减少识别精度损失。
由于两阶段重打分的非自回归解码方法在推理时只进行一次Transformer 解码器的前向计算,因此只在解码器交叉注意力层中使用DRB,并不会给模型带来较好的解码加速收益。因此,在两阶段重打分解码方式的第一个解码步骤中,也使用DRB 处理后得到的压缩特征作为前缀波束解码的输入,在GPU 上的实验结果如表2~表4 所示,表4 中Conf 指Conformer+Inter CTC 模型。

表2 AISHELL-1 中DRB 对Transformer 非自回归解码的改善效果Table 2 Improvement effect of DRB on Transformer non-autoregressive decoding in AISHELL-1

表3 LibriSpeech 中DRB 对Transformer 非自回归解码的改善效果Table 3 Improvement effect of DRB on Transformer non-autoregressive decoding in LibriSpeech
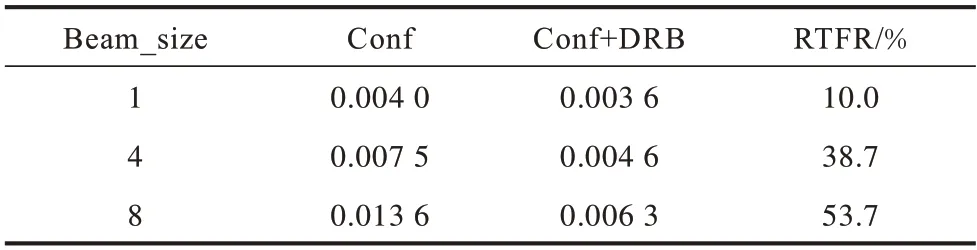
表4 AISHELL-1 中DRB 在不同Beam_size 下非自回归解码的RTFTable 4 RTF of DRB for non-autoregressive decoding at different Beam_size in AISHELL-1
结合表2~表4 的实验结果可以看出:
1)与DRB 对自回归解码方式的改善结果不同,将DRB 用于重打分非自回归解码方式上时,模型在GPU 上的推理速度也能得到显著提升,2 个数据集中RTF 均提高58%左右。结合表4 可以看到,这种提升幅度随着参数Beam_size 的大小而有所改变,但是整体上是有明显的解码加速效果。两阶段重打分的非自回归方法因为Transformer 解码器只运行一遍,所以解码的大部分时间开销在第一阶段的CTC 前缀波束搜索解码过程中产生。将DRB 处理后的特征序列用于第一阶段解码时,波束法的搜索路径变短,缩短了这一过程的耗时,进而加快了整个解码过程。Beam_size 越大,解码搜索的路径越宽,识别精度得到改善的同时解码耗时会显著增加,此时DRB 的改善效果就会越显著。
2)非自回归解码方式上的识别准确率与自回归解码中结果相似,因为DRB 使得特征序列中某部分特征帧被删除,导致重打分的第一阶段解码时缺少了部分有用帧,模型删除错误随之增加。然而,DRB删除部分冗余特征帧后,使得重打分阶段Transformer 的注意力层能更好地关注有用帧信息,这在一定程度上降低了模型替换类型错误的产生,使得模型识别精度得到改善。
为进一步验证DRB 对Transformer 解码性能的提升效果,将其与其他端到端模型进行对比,实验结果如表5、表6 所示。
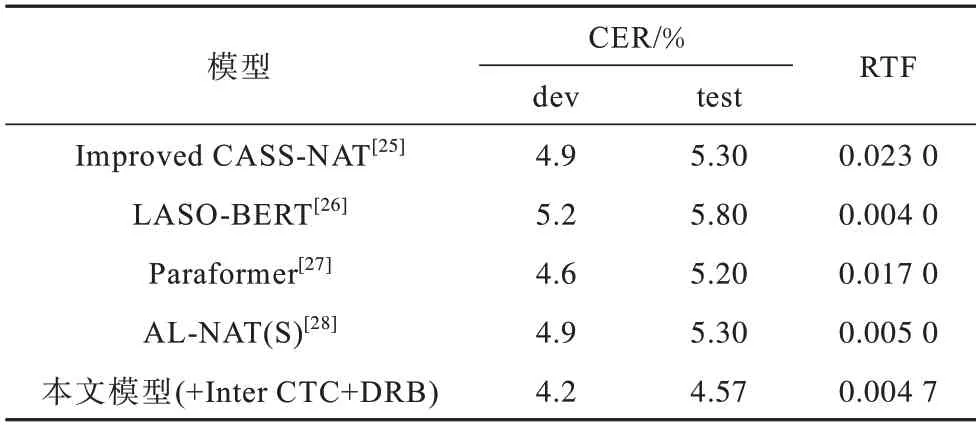
表5 AISHELL-1 上不同Transformer 解码模型的对比实验结果Table 5 Comparative experimental results of different Transformer decoding models on AISHELL-1

表6 LibriSpeech 上不同Transformer 解码模型的对比实验结果Table 6 Comparative experimental results of different Transformer decoding models on LibriSpeech
表5、表6 是使用DRB 的重打分解码模型与其他Transformer 解码模型的对比实验结果。本文使用的NVIDIA GeForce GTX 2080 硬件推理性能略高于Paraformer 与Improved CASS-NAT 模型使用的NVIDIA Tesla V100设备,低于LASO-BERT使用 的NVIDIA GeForce GTX 2080TI,但是本文使用的方法能取得更优的性能。AL-NAT(S)使用NVIDIA Tesla P4 设备,与本文模型取得的RTF 结果相近,但是CER 值却明显提高。因此,与对比Transformer 模型相比,使用DRB 加速后的两阶段重打分解码方法具有更快、更好的识别性能。
4 结束语
本文提出一种丢弃冗余空白块的Transformer 解码加速方法,以CTC/AED 结构为基础,利用CTC 分类器的尖峰序列去除编码器特征中冗余的空白帧,减小解码器的计算量,仅通过微调训练就可以有效地提高解码效率。在AISHELL-1 与LibriSpeech 数据集上进行实验,结果验证了所提方法在高信噪比数据集上的有效性。下一步将针对额外噪声环境下CTC 性能下降导致DRB 方法误差变大的问题进行研究,在不损失识别精度的前提下提高解码效率。
