基于情节记忆的高效短文本流聚类算法
2023-10-17刘子健王勇刘媛妮周由胜
刘子健,王勇,刘媛妮,周由胜,
(1.重庆邮电大学 计算机科学与技术学院,重庆 400065;2.大唐微电子技术有限公司,北京 100094;3.重庆邮电大学 网络空间安全与信息法学院,重庆 400065)
0 概述
随着互联网技术的快速发展,社交媒体平台上每天都涌现出海量的短文本数据,例如微博、Twitter、新闻网站等。随着时间推移这些源源不断产生的短文本数据形成了短文本流。近年来,短文本流聚类受到较多的关注,广泛应用于热点话题检测[1]、事件检测与追踪[2]、新闻推荐[3]等任务。但由于短文本流具有无限长、特征稀疏、多歧义、主题演化等特性,对其进行聚类仍是一个很大的挑战。
与K-means[4]、高斯混合模型[5]、谱聚类[6]等传统聚类算法不同,流聚类算法根据所采用的技术可分为基于相似度的流聚类算法和基于模型的流聚类算法。基于相似度的短文本流聚类算法大多使用向量空间模型来表示文档,通过相似度度量计算文档和聚类之间的相似度,再根据相似度阈值将文档分配给现有聚类或新的聚类。CluStream[7]是经典的短文本流聚类算法,包括在线微聚类阶段和离线宏聚类阶段,使用金字塔时间框架存储不同时刻的历史微集群,使用改进的K-means 算法在微集群上进行聚类,获得用户指定数量为K的宏集群。之后提出的很多流聚类算法都借鉴了这个框架。DenStream[8]将微聚类与用于流聚类的密度估计过程相结合,能够在线对离群值和真实数据进行区分,形成任何形状的数据聚类。SHOU等[9]建立一个持久摘要模型Sumblr,在Twitter文本流中将Tweet压缩成Tweet 特征向量(TCVs)并进行在线维护,模型根据TCVs 的统计信息将未来的Tweet 分配到聚类。MStream[10]计算文档属于现有集群和新集群的概率,并根据这些概率将文档分配给现有集群或新集群,无须设置相似度阈值,能更自然地检测新集群并处理概念漂移问题。RAKIB等[11]提出一种利用文本中高频的biterm 项对每批文本中的小部分文本进行聚类的方法,然后利用获得的聚类分配填充MStream 算法的聚类模型,使用基于统计度量的相似度阈值进行文本分配,在缓解概念漂移问题的同时提升了聚类效率。基于相似度的流聚类算法大多运行速度较快、实时性较好,局限性在于需要手动设置阈值以确定在线文档的主题分配以及难以处理文本稀疏问题。
近几年,越来越多的研究人员对基于模型的短文本流聚类算法进行研究。MStream[10]是一种基于狄利克雷多项式混合模型的短文本流聚类算法,该算法使用了两个狄利克雷先验α和β,其中,α是指文本选择新集群的先验概率,β对应于文本选择与共享比其他集群更相似内容集群的先验概率,该算法的变体为MStreamF(删除旧群体)。DP-BMM[12]是一种基于比特数的短文本流聚类混合算法,与MStreamF 类似,该算法的变体为DP-BMM-FP(删除以前批次中获得的聚类)。OSDM[13]是一种基于语义增强狄利克雷模型的短文本流聚类算法,它扩展了MStream 算法,整合了文本和集群之间的常用词,从中获得单词的语义信息,并使用该语义信息计算文本和集群之间的相似性。DCT-L[14]是一种基于狄利克雷多项式混合模型的短文本流动态聚类算法,它在一个特定的时间戳内为每个短文本分配一个主题(即集群),并使用产生的主题分布作为推断后续文档主题的优先级。OSGM[15]在计算文本分配概率中引入词共现语义信息,在线地在词汇变化的子空间中动态维护不断变化的活动主题,并且无须通过外部资源来处理术语歧义问题。LAST[16]是一个终身学习增强短文本流聚类算法,在基于模型的流聚类算法上增加了情节记忆模块,使得聚类算法同时保持基于批处理和基于单遍处理的优点。基于模型的短文本流聚类算法假设文档是由一个混合模型生成的,这个混合模型通过选择一定概率的主题,再从这个主题中选择一定概率的单词生成文档,通常使用吉布斯采样[17]或EM 算法[18]来估计混合模型的参数,局限性在于需要预先指定主题数量,不能处理短文本流中不断发展的未知数量的主题。
本文提出一种带情节记忆的短文本流聚类算法。该算法由两个阶段组成:在线聚类和离线聚类。在线聚类阶段将情节记忆思想[19]融入聚类算法,通过稀疏经验重放增强聚类的特征表示,使得未来文本以更大的概率选择最近的聚类,并采用反向索引计算文本和选定聚类的相似度并分配文档到现有聚类或新的聚类,通过动态阈值处理概念漂移问题。离线聚类阶段采用目前最优的聚类增强算法进行优化,并通过语义再分配算法处理歧义问题,同时根据聚类id 对过时聚类进行删减。
1 基础知识
1.1 情景记忆模块与稀疏经验重放
情景记忆模块[19]用于在内存中存储一些之前处理过的文本。由于内存有限,选择在一定更新间隔内将新文本写入内存。算法在内存中维护一个情节记忆模块,如图1 所示,当连续到达的文档数量达到存储间隔时,就把当前文本添加到情节记忆模块。由于文本流中的文本是按顺序到达的,最开始存入的文本具有更高的过时性,因此当情节记忆模块的大小超过了设置的最大值时,则从后往前删除文本,以保持记忆模块中存储最近的一些文本数据。
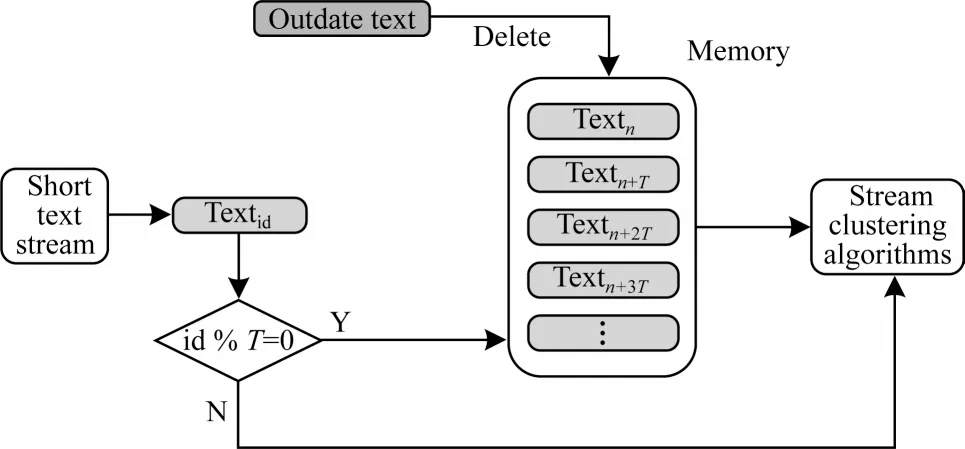
图1 情节记忆模块结构Fig.1 Structure of episodic memory module
在聚类过程中,每经过一定的更新间隔从情节记忆模块中选择文本进行经验重放。经验重放将有助于利用过去的文本信息更新这些主题的特征向量,增大这些主题在聚类过程中被选中的概率。但将记忆模块中的文本全部用来经验重放,一方面增加了时间和空间的开销,另一方面太多不相关的文本也会影响聚类结果,因此随机抽取记忆模块中的部分文本进行稀疏经验重放。当到达重放间隔时,在情节记忆模块中随机抽取数量为E的文本,并对其进行一次扫描聚类。对这些过去已经处理的文本都只选择一个已经存在的聚类而不是产生一个新聚类。在确定聚类后需要更新聚类对应的词汇特征和语义表示。重放文本用t表示,更新聚类词汇特征过程如式(1)~式(3)所示,更新聚类语义表示过程如式(4)和式(5)所示。
其中:nz,f是聚类z中的特征f对应的频率;Nt,f是重放文本t中的特征f对应的频率;nz是聚类z的特征数量;Nt是文本t的特征数量;mz是聚类z的文本数量;Sz是聚类z的聚类向量;St是文本t的语义向量;Sz,m是聚类z的聚类中心向量。
1.2 反向索引
在线聚类阶段先在内存中生成聚类id-特征正向索引,再通过正向索引创建反向索引,如图2 所示。算法通过反向索引能够找到包括同一特征的聚类id。反向索引由向量I={lf,id}表示,其中,lf,id是聚类特征中包括特征f的聚类id 集合。通过计算当前文本和选定具有共同特征聚类的相似度进行聚类。使用反向索引减少文本相似度计算次数,提高算法运行效率。
2 基于情节记忆的短文本流聚类算法
所提算法主要包括在线聚类和离线聚类两个阶段。整个算法流程如图3 所示,其中,T表示当前模型的运行时间,UI 表示离线聚类算法运行的更新间隔,通过取余在UI 内执行离线聚类算法。在线聚类阶段包括特征提取、相似度计算、构建聚类模型以及情节记忆模块;离线聚类阶段包括增强聚类、语义再分配和删除过时聚类。
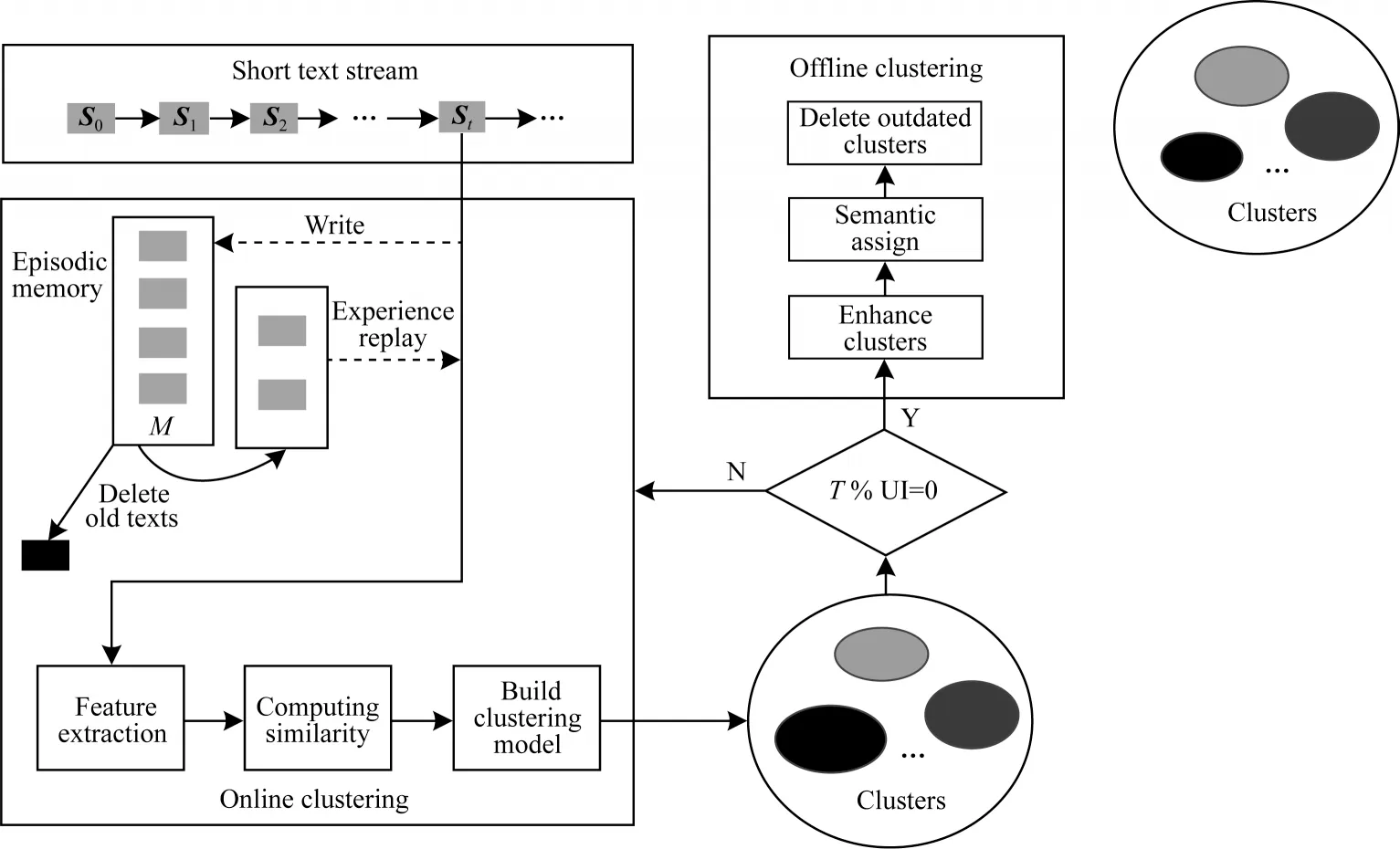
图3 算法整体流程Fig.3 Overall procedure of the algorithm
从词汇特征和语义两个层面进行文本特征提取。使用biterm[20]对文本进行词汇层面特征提取。与biterm 类似的还有unigram 和bigram。unigram 将单个单词作为一个特征,而bigram 是将连续的两个单词作为一个特征。biterm 对文本预处理后的文本进行分词,然后计算单词列表的笛卡尔积,能够更加全面地提取文本中的词汇特征,提取出的特征数量比其他方法更多。对于单词数量为k的句子,特征数量为(k×(k-1))/2。特征提取过程如式(6)所示:
通过词平均法构建文档向量表示文本语义信息,其中词向量可以通过GloVe 模型[21]获得。每个聚类的词汇特征通过一个向量F表示,F={nz,f,nz,mz,iid,z},其中,nz,f是聚类z中的特征f对应的频率,nz是聚类z的特征数量,mz是聚类z的文本数量,iid,z是聚类z的唯一id。每个聚类的语义表示由聚类向量Sz和聚类中心向量Sz,m组成。Sz为聚类z中文本的文档向量求和。Sz,m由聚类向量除以聚类大小(通过聚类中的文本数量mz表示)计算得到。
2.1 在线聚类阶段
在线聚类阶段基于单遍处理的方法。先对当前文本进行预处理和特征提取,如果已处理的文本数量达到了经验重放间隔R,则随机选取数量为E的文本进行稀疏经验重放更新聚类特征,再对当前文本进行聚类。聚类过程根据反向索引选择现有包含该文本特征的聚类,计算文本和选取聚类的相似度,基于统计度量的动态相似度阈值将文本分配到新的聚类或者是现有聚类中。如果处理文本数量达到了存储间隔T,则将当前文本加入情节记忆模块,并且根据设置的内存大小判断是否删除旧文本。
2.1.1 文本与聚类相似度计算
采取基于共同特征的相似度计算公式计算文本和聚类之间的相似度,计算公式如式(7)所示:
其中:Nt,f为文本t的特征f对应的频率;Nt为文本t的特征总数。
首先对文本t和聚类z之间共同的特征f对应的频率求和,然后再乘上一个类似于逆文档频率(Inverse Document Frequency,IDF)的权重Df,计算公式如式(8)所示:
其中:|z|为存在的聚类总数;|f∈z|为包含特征f的聚类数量;Df的大小能够反映特征f的重要性。
如果特征f在聚类中越多出现,那么该特征的重要性越低。
2.1.2 聚类模型构建
当文本t被分配到聚类z时更新聚类z的F向量,构建过程如式(1)~式(5)所示。如果当前文本没有被分配到一个新的聚类,那么iid,z保持不变,否则iid,z自增1,因此最近创建的聚类拥有最高的聚类id。同时,更新反向索引I,对于文本中的每个特征添加聚类id 到相应的F特征向量中。语义向量更新和文本分配过程如式(9)所示:
算法1在线聚类算法
输入文本流、重放间隔R、重放文本数量E、写入模块更新间隔T
输出每个文本的聚类标签ZSt
1.for t=1 to ∞ do//从短文本流开始
2.if t % R=0 then//执行稀疏经验重放
3.从M 中随机选取文本集E
4.通过式(1)和式(2)执行稀疏经验重放
5.通过式(1)~式(5)更新聚类模型M
6.end if
7.通过式(6)提取文本特征
8.通过反向索引I 得到与St有相同特征的聚类集L
9.通过式(7)计算St和L 中聚类的相似度Siml
10.计算Siml中的最大相似度maxl、相似度均值μl和方差σl
11.if maxl> μl+σlthen
12.j=cluster index for maxl//获取maxl对应的聚类标签
13.ZSt=jth//分配文本聚类标签
14.else
15.分配该文本到一个新聚类
16.end if
17.通过式(1)~式(5)更新聚类模型M
18.if t % T=0 then
19.把当前文本St写入情节记忆模块M
20.end if
21.return ZSt
2.2 离线聚类阶段
在每个更新间隔内进行离线聚类。离线聚类阶段主要包括聚类增强、语义再分配、过时聚类删除3步。
2.2.1 聚类增强
在每个更新间隔内选择一组在线聚类模块获得的聚类,对这些聚类的分布进行增强。聚类的大小对应聚类中文本的数量,选择聚类大小大于μ+σ的聚类,μ和σ分别为在线聚类结果中所有聚类大小的平均值和方差。文本数量较大的聚类具有更多的异常值,这可能导致未来文本的不正确分配。通过增强较大聚类中的文本分布,将未来文本分配到合适的聚类。采用目前较优的聚类增强算法[22],该算法通过迭代分类进行聚类增强,每次迭代生成分别包含非异常值和异常值的训练集和测试集,使用训练集训练分类算法,再使用训练好的模型对测试集进行分类,重复迭代直到每个聚类中文本分布趋于稳定或者达到预设的最大迭代次数。另外,该聚类增强算法的质量在很大程度上取决于初始聚类质量(对应所提算法在线聚类阶段的结果),具体算法过程参考文献[22]。
2.2.2 语义再分配
单文本聚类(只包含一个文本的聚类)中的文本与其他聚类没用共享的词汇特征,但这些聚类可能在语义上与其他现有聚类类似,选择这些文本重新分配至其他现有的聚类。通过余弦相似度计算文本和聚类中心的语义相似度,再分别计算相似度的均值μ和方差σ,如果最大的相似度值大于μ+σ,则将该文本分配到对应的聚类,否则仍然在原来通过在线聚类阶段得到的聚类中。在进行语义分配后,需要同时更新聚类的词汇特征表示以及语义表示。
算法2语义再分配算法
输入聚类大小为1 的聚类文本集合T、词向量字典D、聚类的语义特征集合字典{Sz,Sz,m}、文本语义特征向量和SSUM(初始化为0 向量)
输出聚类模型M
1.for t in T do
2.对文本t 进行预处理得到单词列表Wt
3.for w in Wtdo
4.SSUM=SSUM+D(w)
8.计算Simt中的最大相似度maxt、相似度均值μt和方差σt
9.if maxt> μt+σtthen
10.获取maxt对应的聚类标签j
11.ZSt=j//修改当前文本聚类标签为j
12.通过式(1)~式(5)更新聚类模型并删除原始聚类中的文本t
13.else
14.文本t 保留在原始聚类中
15.end for
2.2.3 过时聚类删除
根据聚类编号iid,z以及聚类大小来删除过时聚类,根据在线聚类算法最近创建的聚类拥有更高的iid,z,分别计算聚类编号和聚类大小的均值μz、μm和方差σz、σm,删除聚类编号idz小于μz-σz并且聚类大小小于μm-σm的聚类对应的F向量和反向索引I中该聚类的信息。
算法3过时聚类删除算法
输入聚类id 集合{iid,z,z∈Z}、聚类大小集合{mz,z∈Z}
输出聚类模型M
1.计算iid,z和mz的均值μz、μm和方差σz、σm
2.for z in F do
3.if iid,z<μz-σzand mz<μm-σmthen
4.Delete Fidzand reverse index lf,idz//删除过时聚类的特//征向量以及反向索引中该聚类信息
3 实验与结果分析
3.1 实验环境与数据集
实验环境为Windows 10 64 位操作系统,处理器为AMD Ryzen 7 4800H CPU,内存为16.00 GB。使用PyCharm 2021 实现所提算法,调用Python 的Sklearn 包进行指标统计。在实验中使用3 个公开的短文本数据集。News-T[23]和Tweets-T[10]数据集分别包含11 109 个新闻标题和30 322 篇推文,它们分别有152 和269 个类别。NT[11]数据集是News-T 数据集和Tweets-T 数据集的结合,包括41 429 篇文本和416 个类别,文档的平均长度为7.97。文本预处理包括将所有字母转化成小写字母、删除停用词以及词干提取。表1 显示了这些短文本数据集预处理之后的统计数据,从平均单词数可以看出这3 个数据集适用于短文本流聚类。在实验时对数据集进行混乱处理,以检验不同算法在处理顺序随机且不同主题的文本到达时的算法质量。

表1 实验数据集基本统计信息Table 1 Basic statistical information of experimental data sets 单位:个
3.2 评价指标
使用4 种广泛使用的度量指标来评估聚类性能:归一化互信息(Normalized Mutual Information,NMI),准确率(A),同质性(h)和V-Measure(V)[24]。
NMI 用于评价整体聚类质量,代表聚类分配和文档实际分配组的随机变量共享的统计信息数量。NMI 定义如下:
其中:nc是类别c中文档的数量;nk是聚类k中文档的数量;nc,k是既在类别c又在聚类k中的文档数 量;N是数据集中文档的数量。NMI 越接近1,意味着聚类质量越高。
准确率用于将聚类结果与数据的实际类别进行比较,测量了所有聚类中正确分配的文档所占的比率。准确率定义如下:
其中:ki和ci分别表示xi对应的聚类结果和真实标签;δ表示指示函数;map 函数表示最佳类别标记的重现分配,以保证统计结果的正确。一般通过匈牙利算法[25]实现最佳重分配,从而在多项式时间内求解标签分配问题。准确率越高,意味着聚类效果越好。
同质性表示算法从真值组的同一类中获得的聚类成员所占的比例,定义如下:
其中:H(C|K)是给定集群划分条件下类别划分的条件熵;H(C)是类别划分的熵;n表示实例总数;nc表示类别c下的实例数;nk表示集群k下的实例数;nc,k表示类别c中被划分到集群k的实例数。
V-Measure 基于两个类别之间的条件熵,也就是求已知某一个类别划分后,另外一个类别划分的不确定性程度。不确定性越小,意味着两个类别划分越接近,相应h值或c值越大。完整性衡量了属于同一个真实类别的样本都被分配到同一个簇中的比例的加权平均值。V-Measure 是同质性和完整性的调和平均值,定义如下:
3.3 结果分析
将所提算法与以下基准算法进行比较:
1)MStream,基于狄利克雷多项式混合模型的短文本流聚类算法有基于批处理和基于单遍处理的两种变体。基于批处理的方法对每一批短文本进行聚类,存储一段时间内产生的所有聚类。通过对同一批文本多次进行吉布斯采样,提高初始聚类结果。基于单遍处理的方法只对文本进行一次聚类。
2)MStreamF,是MStream 的一个带有遗忘规则的变体,只保留有限时间范围内的最新文本,删除以前批次的过时聚类。本文采用基于批处理模式的MStream 和MStreamF 算法进行实验,并采用原始论文中MStream 和MStreamF 算法的参数(α=0.03、β=0.03)。
3)OSDM,基于单遍处理的短文本流聚类算法,将词形语义信息集成到MStream 算法,以消除短文本流聚类中的术语歧义问题。本文采用原始论文中的参数进行实验(α=2×10-3、β=4×10-5、γ=6×10-6)。
4)DP-BMM,采用与MStream 算法类似的方法,利用每个文档构造的词来增强短文本中的单词共现模式。与MStream 算法的区别在于,DP-BMM 采用基于biterm 的聚类方法。本文采用原论文中的DPBMM 算法参数进行实验(α=0.03、β=0.03)。
5)EStream,采用在线和离线两个阶段进行短文本流聚类,并且通过反向索引计算文本和选定聚类相似度。EStream 算法的参数只有一个UI,实验中UI 设置为500。
将所提算法和以上基准算法进行比较。为了减少误差,对每个数据集取10 次实验结果的平均值作为最终结果。表2 给出了所提算法与其他算法在3 个数据集上的实验结果,其中部分实验结果来源于文献[11],不同数据集的最优结果用加粗字体标示。从实验结果来看,所提算法相比于其他算法具有一定的性能优势,在3 个数据集上多项评价指标都高于EStream,证明了改进后的流聚类算法结合情节记忆模块的有效性。值得注意的是,所提算法在News-T 数据集上的归一化互信息指标没达到最优,可能的原因是该数据集的数据量偏小,导致在进行经验重放时能够增强的聚类表示较少。相比之下,DP-BMM 和MStreamF 进行了超参数调优,更好地实现了将文本分配到不同聚类。但是在NT 数据集上,所提算法的归一化互信息、同质性、准确率指标明显高于其他算法,可能的原因是其他算法并没有在NT数据集上进行超参数调优,而所提算法使用经验重放缓解文本流稀疏性问题,并且通过参数影响实验得到最佳的重放间隔和重放数量。
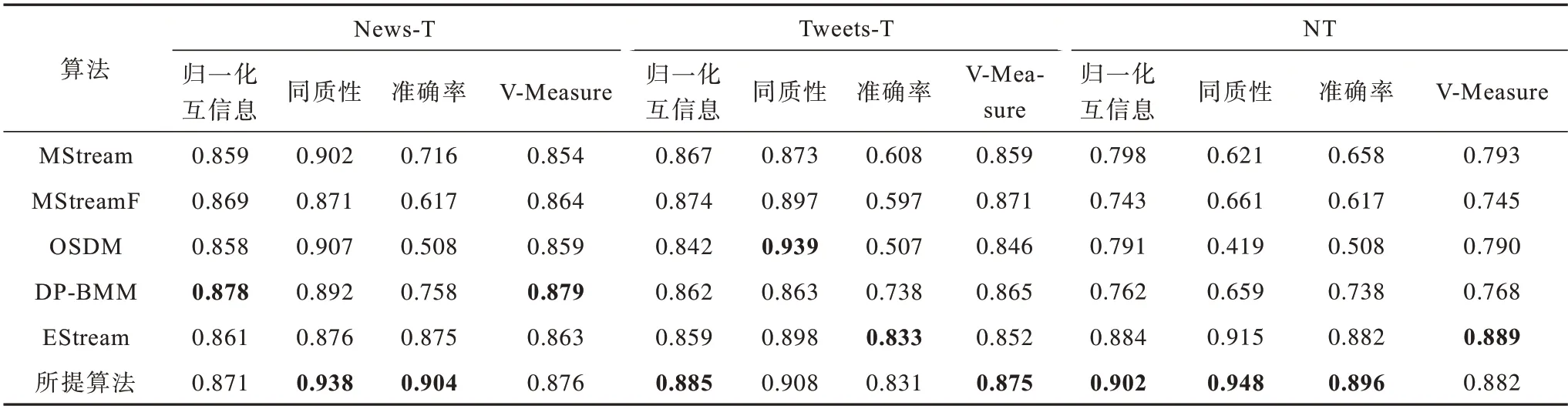
表2 各算法在3 个数据集上的实验结果Table 2 Experimental results of each algorithm on three data sets
另外,对比所提算法和其他算法的平均运行时间,实验结果如表3 所示。由表3 可知,所提算法比MStream、MStreamF、DP-BMM、OSDM 算法的运行时间更短,证明了所提算法通过反向索引优化聚类运行效率的有效性。DP-BMM 算法的运行时间最长,可能的原因是该算法在每个聚类中存储了该聚类所有文本的biterm项,使用吉布斯采样选取聚类,而对同一文本多次执行吉布斯采样是一项很耗时的操作。假设文本数量为M,聚类数量为K,每个文本的单词个数为L,执行吉布斯采样的次数为I,那么DP-BMM 算法的时间复杂度为O(IKML)。由于所提算法包括情节记忆模块和稀疏经验重放,整体聚类次数得到了增加,因此运行时间比EStream 算法略长。在线聚类阶段计算的是当前文本和选定聚类的相似度,假设每次运行需要挑选聚类个数为c,稀疏经验重放的数量为E,因为在线聚类对当前文本只须执行一次,只有产生重放才会再次执行聚类,所以所提算法的时间复杂度为O((M+E)×cLL)。本文忽略了离线聚类阶段的运行时间,因为离线聚类阶段只会对一小部分文本进行再次聚类。

表3 不同算法的平均运行时间Table 3 Average running time of different algorithms 单位:s
3.4 消融实验
本节主要分析内存大小M、重放间隔R和重放文本数量E对算法性能的影响。参照EStream 算法设置在线阶段和离线阶段的更新间隔为500。采用控制变量法进行实验。
3.4.1 内存大小对算法性能的影响
内存大小是指情节记忆模块中存储的文本数量。图4 显示了在News-T、Tweets-T、NT 数据集上不同的内存大小对NMI 的影响。由图4 可以看出,随着内存大小的不断增大,NMI 数值总体而言也不断增大。因为情节记忆模块中存放着较多的最近文本,更有助于利用过去的文本信息更新主题的特征向量,但内存大小并不是越大越好,可通过验证集来设置一个适合的数值。

图4 内存大小对归一化互信息指标的影响Fig.4 Influence of the memory size on the normalized mutual information index
3.4.2 重放间隔对算法性能的影响
重放间隔是指稀疏经验重放的文本数量间隔。图5 显示了在News-T、Tweets-T、NT 数据集上不同的重放间隔对NMI 的影响。由图5 可以看出,随着重放间隔的增加,NMI 大体呈现下降趋势,可能的原因是一些聚类的特征会随着时间慢慢减少。过小的重放间隔会使得聚类时间变长,而过大的重放间隔会使得算法的性能降低。
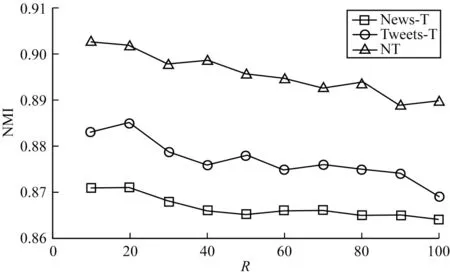
图5 重放间隔对归一化互信息指标的影响Fig.5 Influence of the replay interval on the normalized mutual information index
3.4.3 重放文本数量对算法性能的影响
重放文本是指在每个重放间隔内进行经验重放的文本。图6 显示了在News-T、Tweets-T、NT 数据集上不同的重放文本数量对NMI 的影响。由图6 可以看出,随着重放文本数量增加,NMI 呈现上升趋势。可能的原因是重放文本数量越多,就会有更多的采样文本被用来更新聚类特征向量。如图7 所示,过少的重放文本会减少聚类的特征数量降低算法的性能,但过多的重放文本会导致算法运行时间变长。

图6 重放文本数量对归一化互信息指标的影响Fig.6 Influence of the number of replay texts on the normalized mutual information index

图7 重放文本数量对算法运行时间的影响Fig.7 Influence of the number of replay texts on the running time of the algorithm
4 结束语
本文将情节记忆思想融入短文本流聚类算法,提出一种带情节记忆的高效短文本流聚类算法。采用在线-离线阶段对短文本流进行聚类:在线阶段融入情节记忆思想缓解短文本流的稀疏性问题,通过反向索引减少聚类运行时间;离线阶段通过聚类增强、语义再分配以及删除过时聚类来提高聚类性能。通过在3 个公开数据集上与6 个基准算法进行实验对比,结果表明所提算法的多项评价指标都取得了较好的结果,并且在运行时间上比多数算法减少1~3 个数量级。通过消融实验可知,不同的记忆内存大小、重放间隔以及重放文本数量对算法性能均有一定的影响。后续可将深度学习模型和词共现矩阵引入短文本流聚类算法,对文本进行深度顺序编码,以提高聚类精度,并将其应用于针对短文本流的新闻推荐等场景进一步拓宽使用范围。
