基于YOLOv5的无人车自主目标识别优化算法
2023-10-07赵晓冬张洵颖
赵晓冬, 张洵颖
(西北工业大学 电子信息学院, 陕西 西安 710072)
0 引言
随着科学技术的发展,无人系统装备越来越多地出现在现代战场环境中,并深刻影响及颠覆了战争规则。作为智能无人系统的典型代表,无人车通过搭载各类光电传感器、导航定位系统等,可自主执行复杂战场环境下的目标侦查与战场态势感知、避障、导航以及火力打击等任务。例如,美军在伊拉克战争中投入约8 000辆地面无人车,用于执行扫雷、侦察监视以及攻击任务。复杂地面战场环境下的军事目标实时自主识别与跟踪技术是影响无人车目标侦查与战场态势感知、精确火力打击等任务的关键技术。因此开展无人车实时自主目标识别技术对于提升无人车的智能化水平、增强无人车作战效能有着重要意义。
在自主目标识别研究领域,基于深度学习的目标检测识别算法能够自主提取特征信息并进行学习,其结果已被证实大幅优于传统目标识别算法,可为无人车复杂高精度地面自主目标识别提供新的技术实现途径[1-4]。但是无人车作为典型的移动嵌入式“边缘”计算平台,其车载嵌入式计算、存储资源严重受限且对功耗有严格的要求;另外无人车作为作战平台,其目标识别与跟踪精度及实时性要求较高。从目标识别角度,深层神经网络对复杂背景下的小目标检测识别精度较高,然而神经网络层数越深,模型参数规模越大,计算、存储硬件资源要求越高。在无人车车载处理平台功耗、体积等资源约束条件下,如何将基于深度学习的自主目标识别算法进行资源受限情况下的嵌入式计算平台部署应用,是目前地面无人车系统亟待解决的关键问题。
目前工程应用较为成熟且能够满足实时处理要求的深度学习算法,主要包括YOLO系列算法,其经典网络包括YOLO网络[5]、YOLO9000网络[6]、YOLOv3网络[7]、YOLOv4网络[8]、YOLOv5网络、YOLOX网络[9]、YOLOv7网络[10]等。其中YOLOv5网络在YOLOv4网络基础上进一步丰富了网络子结构,同时采用了新的损失函数。针对YOLOv5及其相关改进算法的车辆目标识别研究成果[11-16]表明,YOLOv5网络针对复杂地面环境下的目标识别可以获得良好的识别效果。文献[11]通过改变YOLOv5网络结构中的宽度和深度实现轻量化网络模型,并针对GPU嵌入式平台采用工具链方式进行应用部署,缺点是其基于特定工具链的部署实现方式,针对其他硬件平台不具备可移植性。文献[12]针对YOLOv5网络进行了改进,提出了基于感知计算的网络模型,但其并未对网络进行轻量化优化,其硬件可实现性无法预估。文献[13-16]针对参数量较小的YOLOv5s网络,分别提出了多尺度特征融合改进型网络、融入注意力机制的改进型网络、多特征融合改进型网络以及结合级联注意力机制的改进型网络,提升了网络的检测性能。但均未讨论其方法对于其他3种复杂网络的适用性,并且其硬件可实现性同样无法预估。
YOLOv5网络的参数量和计算量统计情况如表1 所示,按照顺序网络权重、硬件计算资源量和识别精度递增,计算量采用浮点运算次数(FLOPs)表示。由表1可以看出,虽然YOLOv5x网络可以获得较好的识别精度,但是其参数量大、计算复杂度高,与嵌入式硬件的受限资源特点相矛盾。如何将YOLOv5x网络进行算法级压缩优化并进行嵌入式平台应用部署,是当前亟待解决的问题。
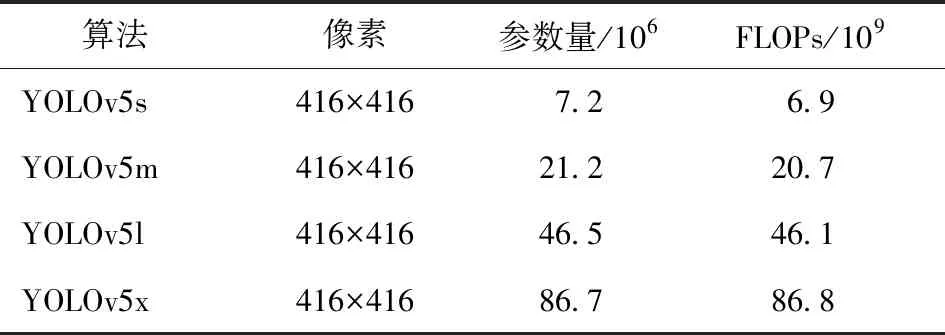
表1 YOLOv5网络参数量和计算量
深度神经网络压缩优化可以有效降低算法复杂度,从而解决受限资源下的嵌入式平台应用部署问题。主流的网络压缩优化方法包括网络模型裁剪[17-19]、网络模型量化[20-21]、低比特位量化、轻量化网络设计等。其中,低比特位量化和轻量化网络设计对网络识别精度的损失影响较大,而网络模型裁剪和量化可以在保持识别精度的同时减少参数量及计算量。
针对网络裁剪,文献[17]提出了基于稀疏训练的裁剪算法,通过正则化项学习深度神经网络的有限数量的固定稀疏模式,使用这些固定的稀疏模式表示滤波器,获得具有更高稀疏性的紧凑模型,但有限数量的固定稀疏模式也影响了裁剪后网络的精度。文献[18]提出了神经元重要性分数传播裁剪算法,通过将重要性分数传播到网络中的神经元,裁剪掉最不重要的神经元,但其最优参数的寻找过程较为复杂。文献[19]提出了一种基于稀疏化尺度因子的通道自适应选择裁剪算法,在正则化框架下,通过批处理归一化(BatchNorm)层中的缩放因子自适应地裁剪掉不重要的通道,其缺点是正则项仅包括L1范数的BatchNorm层,对于网络结构的局部稀疏性效果不均匀。针对网络量化,文献[20]提出了一种渐进式量化方法,先按一定比率分组并进行量化,随后冻结已经量化的部分并且同时训练未量化的部分。重复此步骤,直到权重全部被量化,其缺点是训练过程较为复杂,并且仅针对权重进行量化,因此带来的压缩力度和加速效果一般。文献[21]提出了一种整数算法用于逼近神经网络中的浮点运算,通过模拟量化效果的训练,有助于将模型精度恢复到与原始模型相近的水平,但仅针对小型网络给出了ARM平台的量化测试结果,并未给出其他平台的测试结果。
本文针对上述问题,以复杂战场环境下的无人车地面自主目标识别为应用背景,以YOLOv5x深度神经网络为对象进行压缩优化算法研究。首先分析了用于目标识别的YOLOv5网络结构;然后针对YOLOv5x网络提出一种基于改进型注意力模块[22]和BatchNorm层的多正则项自适应网络裁剪算法,在裁剪与训练的协同过程中实现了网络结构的最优化裁剪;在此基础上设计了一种对权重实施不饱和映射,以及对激活值实施饱和映射的组合式训练后INT8量化算法。将压缩优化后的YOLOv5x网络在基于Zynq UltraScale+MPSoC架构的XCZU7EV器件上进行了应用部署,采用红外和可见光2种数据集,完成了压缩优化后算法的验证与分析。验证结果表明,本文提出的目标识别深度网络压缩优化算法可以在识别精度损失较低的同时有效提升识别实时性,性能优于现有研究成果[19-20]。
1 YOLOv5网络结构
YOLOv5的网络结构如图1所示,分为输入端、Backbone、Neck和预测4部分,包含卷积归一化激活(CBL)、残差单元(RES Unit)、集中切片结构(Focus)、空间金字塔池化(SPP)、跨阶段局部结构[23](CSPX)5种基本组件。

图1 YOLOv5网络结构图
输入端采用Mosaic数据增强方法扩充数据集,采用自适应锚框计算寻找初始最优锚框,同时采用自适应图片缩放减少计算量。Backbone采用CSPX组件作为网络主体,将梯度变化集成到特征图中,减少模型参数量,保证推理速度与准确率。Focus结构将输入图像进行切片,增加特征通道数,减少特征尺寸。
SPP组件用于Backbone特征提取网络中,通过不同尺度的池化进行特征提取,核尺度包括1×1、5×5、9×9和13×13,可有效提高网络感受野。SPP组件的网络结构图如图2所示,SPP组件的处理结果提升了输入图像的尺度不变性。
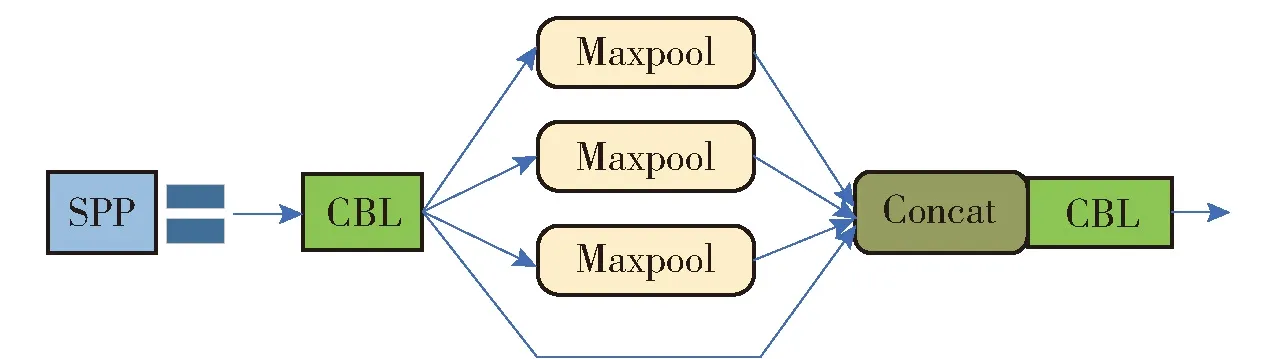
图2 SPP组件网络结构图
YOLOv5不同版本的网络主结构一致,区别在于基于CSPX组件实现网络不同程度的加深,同时利用CBL组件中卷积核数量的不同,实现网络不同程度的加宽,CSPX组件网络结构如图3所示。
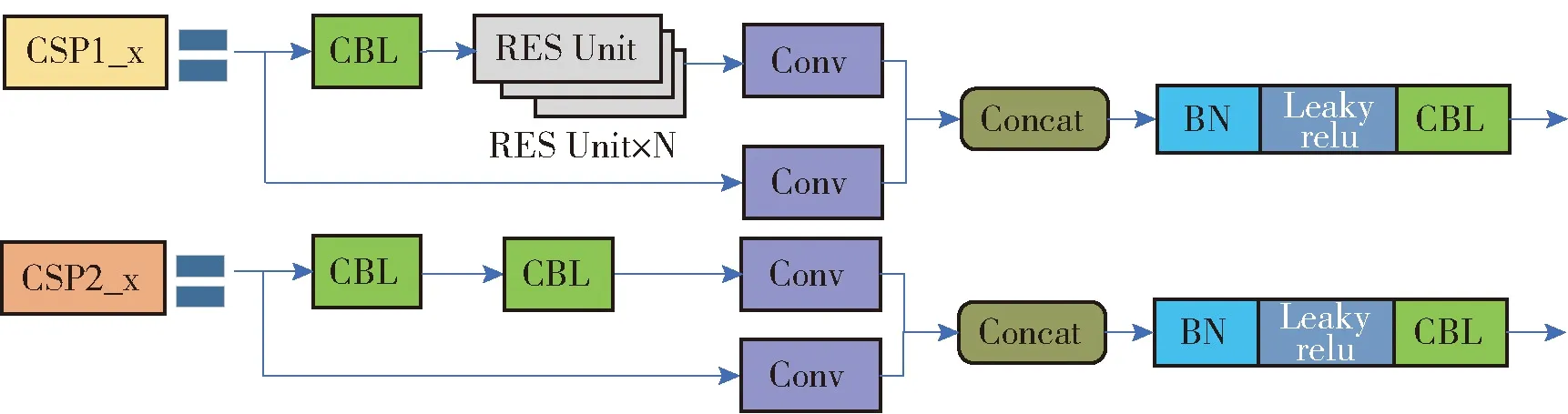
图3 CSPX组件网络结构图
表2描述了YOLOv5网络不同版本CSPX组件中所使用的残差组件数量,随着网络加深,网络的特征提取和融合能力不断提升。

表2 CSPX组件中残差单元数量
Neck模块同时采用特征金字塔网络[24](FPN)和路径聚合网络[25](PAN)聚合特征,加强信息传播。FPN自顶向下传播语义特征,PAN自底向上传播定位特征。PAN结构特征图的聚合采用并置操作,特征图尺寸改变。
YOLOv5网络输出特征向量,分别用于检测较大型的目标、较中型的目标以及较小型的目标。预测部分采用GIOU_Loss作为目标边界框的损失函数,最终预测的目标中心点偏移量计算公式表示为
bx=(2·σ(tx)-0.5)+cx
by=(2·σ(ty)-0.5)+cy
σ(x)=1/(1+e-x)
(1)
式中:bx为预测目标中心点的x轴方向偏移量;by为预测目标中心点的y轴方向偏移量;σ(·)为Sigmoid激活函数;tx和ty分别为网络预测的相对于网格左上角的目标中心坐标偏移量;cx和cy分别为对应网格左上角的坐标;2σ(·)-0.5用于将预测偏移量缩放到(-0.5,1.5),确保预测偏移量可以达到0和1。
最终预测边框的宽bw和高bh计算公式表示为
bw=pw·(2·σ(tw))2
bh=ph·(2·σ(th))2
(2)
式中:pw和ph分别为预设的边界框宽和高;tw和th分别为尺度缩放因子;(2σ(·))2用于将缩放因子限制在(0,4)之间,有效解决梯度爆炸和训练不稳定问题。
YOLOv5网络边界框预测图如图4所示,通过不断学习参数(tx,ty,tw,th),预测时使用式(1)和式(2) 求取(bx,by,bw,bh),获得最终预测边框的坐标偏移量和宽高信息。
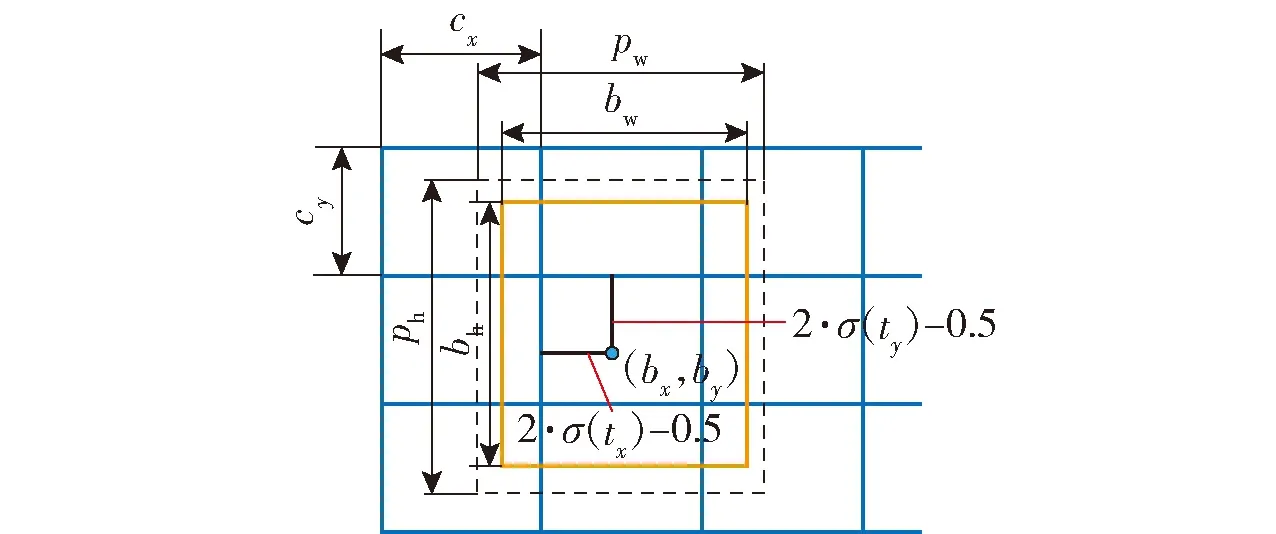
图4 边界框预测图
2 基于多正则项的自适应裁剪算法
正则化可以有效降低神经网络的模型复杂度,提高网络的稳定性。为了保持网络裁剪后的识别精度,本文在文献[19]基础上提出了一种基于改进型注意力模块[22]和BatchNorm层的多正则项自适应网络裁剪算法,通过将Mish激活函数[26]引入注意力模块中,以提升注意力模块的特征提取能力。
Mish激活函数的曲线如图5所示,与ReLU中的硬零边界不同,Mish激活函数在负值时并非完全截断,平滑的激活函数可以使得更多的信息传入神经网络,提升网络的准确性和泛化性。Mish激活函数的正值可以达到任何高度,这种无边界的特性避免了由于封顶所导致的饱和现象。
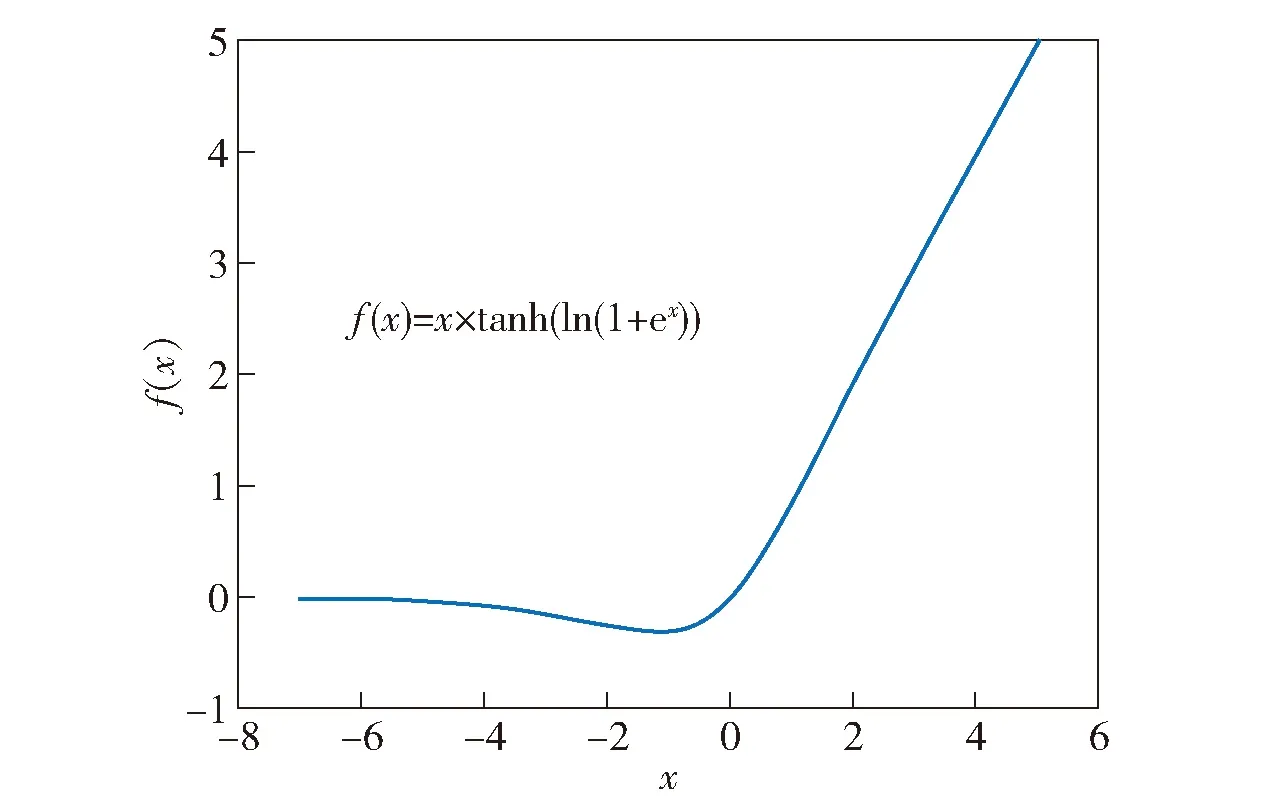
图5 Mish激活函数曲线
本文提出的改进型注意力模块结构如图6所示,改进型注意力模块被用于卷积层和激活函数之间,由全局池化层、2个全连接层和激活函数(Mish和Sigmoid)组成。当输入通道数为M时,经过全局池化层可以获得包含M个元素的特征向量,经过2层全连接层的学习获得M个输出值。输出值经过Sigmoid激活函数,将投影至(0,1)区间中,此值即为通道注意力因子。通道注意力因子反映了网络对特征通道的选择,其值大小表征了通道重要与否。

图6 改进型注意力模块结构图
改进型注意力模块变换过程表示为
F(X〈n,W,H,M〉)=
Sigmoid(FC2(Mish(FC1(AP(X〈n,W,H,M〉)))))
(3)
式中:X〈n,W,H,M〉表示第n个样本所产生的包含M个通道的输入向量;AP表示全局池化层;FC1和FC2表示全连接层;Mish(·)和Sigmoid(·)表示激活函数。
本文提出基于改进型注意力模块和BatchNorm层的多正则项自适应裁剪算法步骤为:
1)计算通道平均注意力因子θ,避免个别样本造成的数据偏差,因子值越大,代表通道越重要,计算方法表示为
(4)
式中:N表示用于计算平均注意力因子的样本数量;θ表示通道在样本数据集下的平均注意力因子。
2)在正则化框架下,将改进型通道平均注意力因子和BatchNorm层缩放因子共同作为优化约束项归入目标函数,进行网络稀疏化训练。混合范数正则项的引入可以有效提升网络结构局部稀疏度的均匀性。网络优化目标函数表示为
(5)
式中:第1项是网络损失函数,其中W表示训练权重,(x,y)表示训练输入和目标;第2项是通道平均注意力因子正则项,Φ表示θ的取值空间;第3项和第4项是BatchNorm层缩放因子正则项,γ表示BatchNorm层的缩放因子,Γ表示γ的取值空间,α、β和χ分别表示正则项在优化过程中的正则系数,通过最优正则系数的设置可以获得最优的裁剪效果。
3)通过迭代进行裁剪与训练的协同计算,获得针对具体数据集的最优正则系数,在裁剪与训练的协同计算过程中实现网络结构的最优裁剪,获得压缩比较高的最优网络。
3 基于组合式映射的训练后量化算法
网络模型量化是指将32位或64位浮点数据映射成低bit位数值,进行数据存储和推理计算。网络模型量化可以在推理精度损失较小的情况下,减小模型尺寸、降低存储及计算需求、降低功耗与加快推理速度。目前研究较多的量化方法为8位定点(INT8)量化。网络模型量化包括量化感知训练和训练后量化两种思路。量化感知训练将量化操作嵌入到网络训练中,在训练的同时计算量化比例因子。训练后量化直接量化,不需要反复训练。
按照映射方式的不同,量化可以分为饱和映射和不饱和映射,如图7所示。在INT8量化方式下,饱和映射通过计算获得最优阈值|T|,将±|T|内的张量数据映射到[-127,127]区间内,使得分布散乱的较大值被舍弃掉,降低精度损失;不饱和映射直接将±|Dmax|内的张量数据映射到[-127,127]区间内。在深度学习网络中,推理计算涉及激活值和权重2部分,其中激活值数量远大于权重数量。权重在训练过程中,通过正则化技术趋于(-1,1)分布,但是经过激活后的输出值,分布不均,量化激活值对于网络精度的影响较大。本文基于二者对于网络精度的影响重要程度,对权重实施不饱和映射,对激活值实施饱和映射,形成了一种基于组合式映射的训练后量化算法。

图7 饱和映射和不饱和映射示意图
浮点实数和定点整数间的换算公式表示为
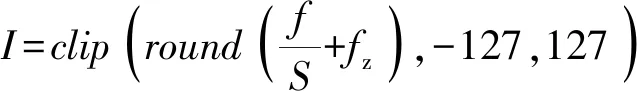
(6)
式中:f表示量化前的浮点实数;S表示浮点实数和定点整数的比例步长;I表示量化后的定点整数;fz表示浮点实数中的0经量化操作后所对应的定点整数零点;clip(·)表示限制函数,数组中元素值小于-127或大于127的值将被限制在最小和最大值上。
对于目标识别神经网络,通过统计每层权重值和特征值的最小最大区间,计算步长和零点,便可以使用定点数据进行网络推理计算。步长S和零点fz的计算公式表示为
S=(fmax-fmin)/(Imax-Imin)
fz=clip(round(Imax-fmax/S),-127,127)
(7)
式中:fmax、fmin分别为f的最大值和最小值;Imax、Imin分别为I的最大值和最小值。
以卷积层量化为例,假设输入为x,统计的步长和零点为Sx和fzx;权重为w,统计的步长和零点为Sw和fzw;输出的特征激活值为a,统计的步长和零点分别为Sa和fza。则卷积过程表示为
(8)
式中:i、j、k为与矩阵运算相关的位置索引;ai,k为第i行和第k列上的浮点特征激活输出值;xi,j为第i行和第j列上的浮点特征输入值;wj,k为第j行和第k列上的浮点权重值。
量化公式表示为
(9)
M=2-nM0,M0∈(0.5,1]
(10)
式中:M0为小数,但可以用定点数进行表示。
针对全连接层等基于矩阵运算的层类型,可统一依据式(9)进行量化计算。针对激活函数和池化函数等层类型,沿用上一层输出的最小最大区间,无需额外统计。在张量级量化和通道级量化方式的选择上,由于每一个通道代表一类特征,不同通道间可能存在数据分布相关较大的情况;为在保证精度的同时减少计算量,针对权重采用通道级量化,针对激活值采用张量级量化。在推理时先把输入量化成定点数据,根据式(9)量化计算卷积输出,可继续计算激活函数输出、全连接层输出等,并根据步长和零点,通过式(6)推算回浮点实数。在此流程中除了输入输出的量化和反量化操作,其余流程均可使用定点数在硬件上进行加速计算。针对激活层确定最小最大区间的具体过程是在具有代表性的输入数据上执行训练后的网络,统计激活值分布情况,基于统计结果估计最小最大区间,步骤如下:
步骤1从红外和可见光数据验证集中,分别选取数据子集作为校准集,用于校准INT8量化所引起的精度损失,根据校准集确定数值区间,将此数据区间分为1 024份,即离散化为1 024个bin的直方图。
步骤2在校准集上进行32位浮点推理计算,对于网络的每一层,通过遍历收集该层的激活值,以第1组128个bin为基准,逐步向后以128个bin为一组,扩增式进行搜索,每次获得新的数值范围,并将此范围重新划分为128个bin的直方图,利用不同的量化阈值形成量化分布。
步骤3将剩余未搜索到的数值压缩到搜索到的bin上,获得基本未损失直方图并与搜索得到的直方图进行比较,通过KL散度最小化获得最优阈值,确保按最优阈值量化后的分布与基本未损失分布无限接近。
步骤4重复步骤2和步骤3,直到搜索遍历全部完成,KL散度最小的搜索范围即为信息损失最小的最小最大区间。
4 仿真与验证
为了验证本文提出的多正则项自适应裁剪算法和组合式映射训练后量化算法在嵌入式硬件平台上的有效性和加速能力,选用基于Zynq UltraScale+MPSoC架构的XCZU7EV器件作为无人车载嵌入式计算平台,实现基于YOLOv5x网络的加速器硬件设计和应用部署。嵌入式计算平台结构如图8所示,PS端是指处理器系统端,PL端是指可编程逻辑端。控制程序运行在片内PS端的Cortex-A53处理器上,目标识别神经网络利用片内PL端实现,嵌入式计算平台实物如图9所示。
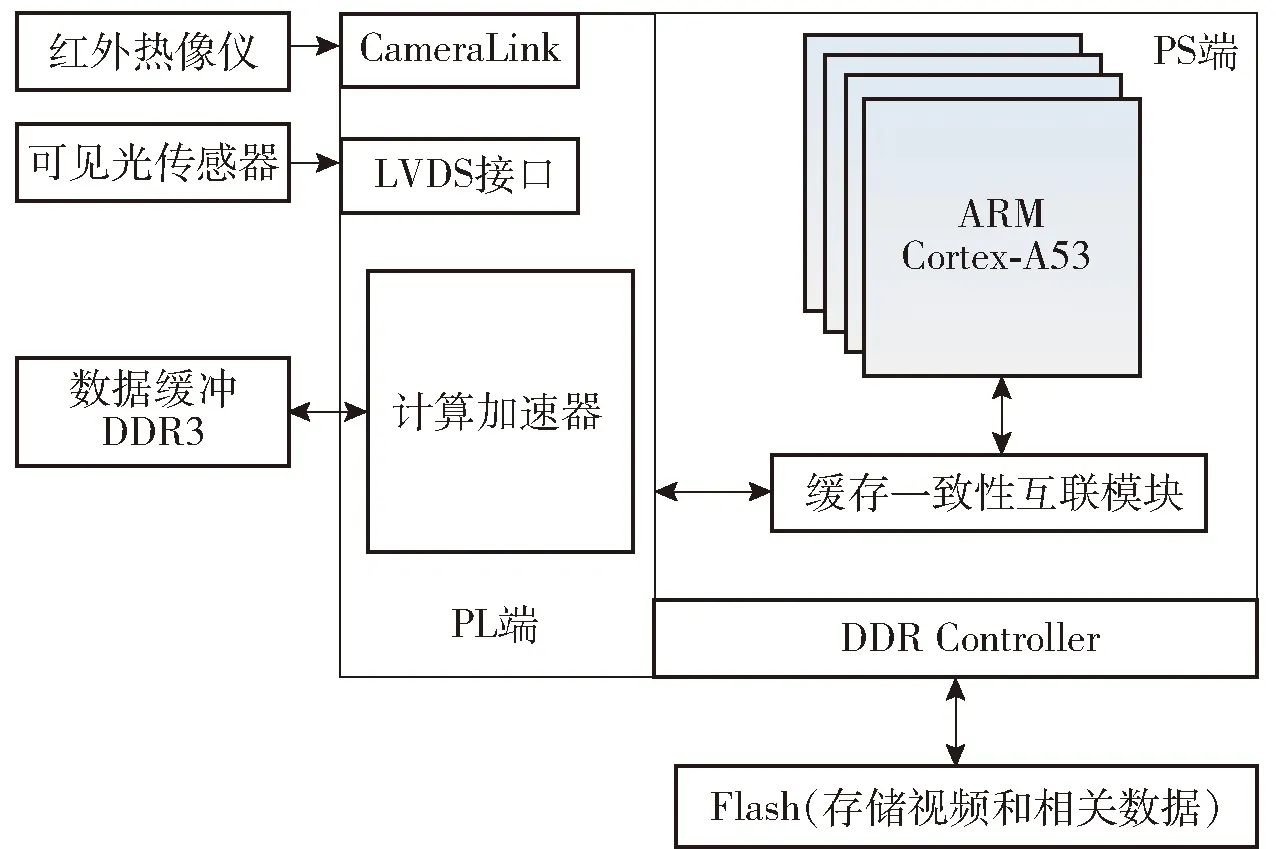
图8 嵌入式计算平台结构图

图9 嵌入式计算平台
针对复杂地面战场环境下无人车自主目标识别的应用需求,选取红外图像和可见光图像数据集作为训练及测试数据集。红外数据集包含3 178张训练集图像和312张测试集图像;可见光图像数据集包含5 105张训练集图像和515张测试集图像。两种类型的数据集均包含坦克、卡车、汽车、装甲车和越野车5种车辆类型。
在输入图像像素为416×416时,YOLOv5x网络裁剪前后在红外数据集和可见光数据集上的识别精度对比结果如表3所示,参数量和计算量对比结果如表4所示,其中裁剪比率表示从稀疏训练的模型中裁剪通道的比率。红外图像识别结果基于经多次训练测试所得出的最优正则系数α=0.021、β=0.016、χ=0.01,可见光图像识别结果基于经多次训练测试所得出的最优正则系数α=0.018、β=0.012、χ=0.004。

表3 YOLOv5x网络裁剪前后识别精度对比

表4 YOLOv5x网络裁剪前后参数量和计算量对比
由表3和表4可以看出,相比文献[19]中的算法,多正则项自适应裁剪算法在裁剪比率相同的前提下,识别精度、参数量和计算量的裁剪率均优于前者。相比ReLU激活函数,Mish激活函数的引入提升了网络的特征提取能力,从而有效提升了识别精度。针对红外和可见光数据集,当裁剪比率为40%时参数量裁剪率可分别达到36.7%和36.1%,计算量裁剪率可分别达到32.6%和32.3%。
YOLOv5x网络压缩优化前后针对红外和可见光数据集的识别精度及延时等对比结果如表5和表6 所示。图像输入大小为416×416,正则系数配置情况与表3一致,裁剪算法采用基于ReLU+Sigmoid和Mish+Sigmoid的两种组合式激活函数,量化算法统一采用INT8量化进行对比。嵌入式计算平台中神经网络处理单元工作频率配置为200 MHz,分别在单线程和双线程模式下统计延时和帧频。参数量和硬件算力对比结果如表7所示,其中,GOPs/s代表硬件算力,即每秒内硬件进行多少个GB的计算次数,由神经网络模型的操作次数除以延时计算可得。

表7 参数量和硬件算力对比
由表5和表6可以看出,针对红外和可见光数据集,在仅进行组合式映射INT8量化时,精度均略微有所提升,表明神经网络本身具备冗余性,可以通过数据位数压缩减少冗余。INQ算法[20]量化后的网络精度低于组合式映射。
针对红外数据集,基于本文提出的裁剪和量化算法,当裁剪比率分别为20%、30%和40%,与INT8量化算法同时优化时,精度变化分别为+0.192%、-0.162%和-0.374%。针对可见光数据集,基于本文提出的裁剪和量化算法,当裁剪比率分别为20%、30%和40%,与INT8量化算法同时优化时,精度变化分别为+0.347%、+0.38%和+0.065%。表明针对两类数据集,YOLOv5x网络经过裁剪和量化算法优化,依然保持了较高的识别精度。红外数据集相比可见光数据集,优化后网络的识别精度损失相对较高,这归因于红外图像的成像特点导致其特征信息相对平滑。
针对红外和可见光数据集,YOLOv5x网络在上述嵌入式硬件平台应用部署时,未经压缩的网络单线程执行时约为0.8帧/s,双线程时约为1.3帧/s。基于本文提出的裁剪和量化算法,在不同网络裁剪比率下,目标识别实时性在单线程模式下可分别达到约7帧/s、10帧/s和12帧/s,在双线程模式下可分别达到约14帧/s、20帧/s和25帧/s。改进型注意力模块中Mish激活函数的引入,相比ReLU激活函数提升了识别精度、缩短了延时。基于文献[19]裁剪算法和文献[20]量化算法的优化后网络,精度和帧频均低于本文的多正则项裁剪和组合式映射优化后网络。
由表7可以看出,针对红外和可见光数据集,本文算法优化后的参数量最小,经应用部署后在相同工作频率的计算平台上,获得了最高的硬件算力。
基于红外数据集和可见光数据集中典型场景目标识别效果如图10~图15所示。其中,图10和图13 分别为YOLOv5x网络压缩前的典型红外和可见光目标识别结果,图11(a)、图12(a)、图14(a)、图15(a)为基于多正则项裁剪40%(Mish+Sigmoid)和组合式映射INT8量化优化后的目标识别结果,图11(b)、图12(b)、图14(b)、图15(b)为裁剪40%[19]和INT8量化[20]优化后的目标识别结果。从验证结果可以看出,本文提出的基于多正则项裁剪和组合式映射INT8量化优化后的网络地面目标识别效果较好,而经文献[19]和文献[20]算法优化后的网络,一方面出现了部分漏检现象,另一方面其计算获得的位置框部分结果包含了较为明显的非目标信息。

图10 YOLOv5x网络压缩前典型红外目标识别结果(左为场景1,右为场景2)

图11 压缩后红外目标识别结果
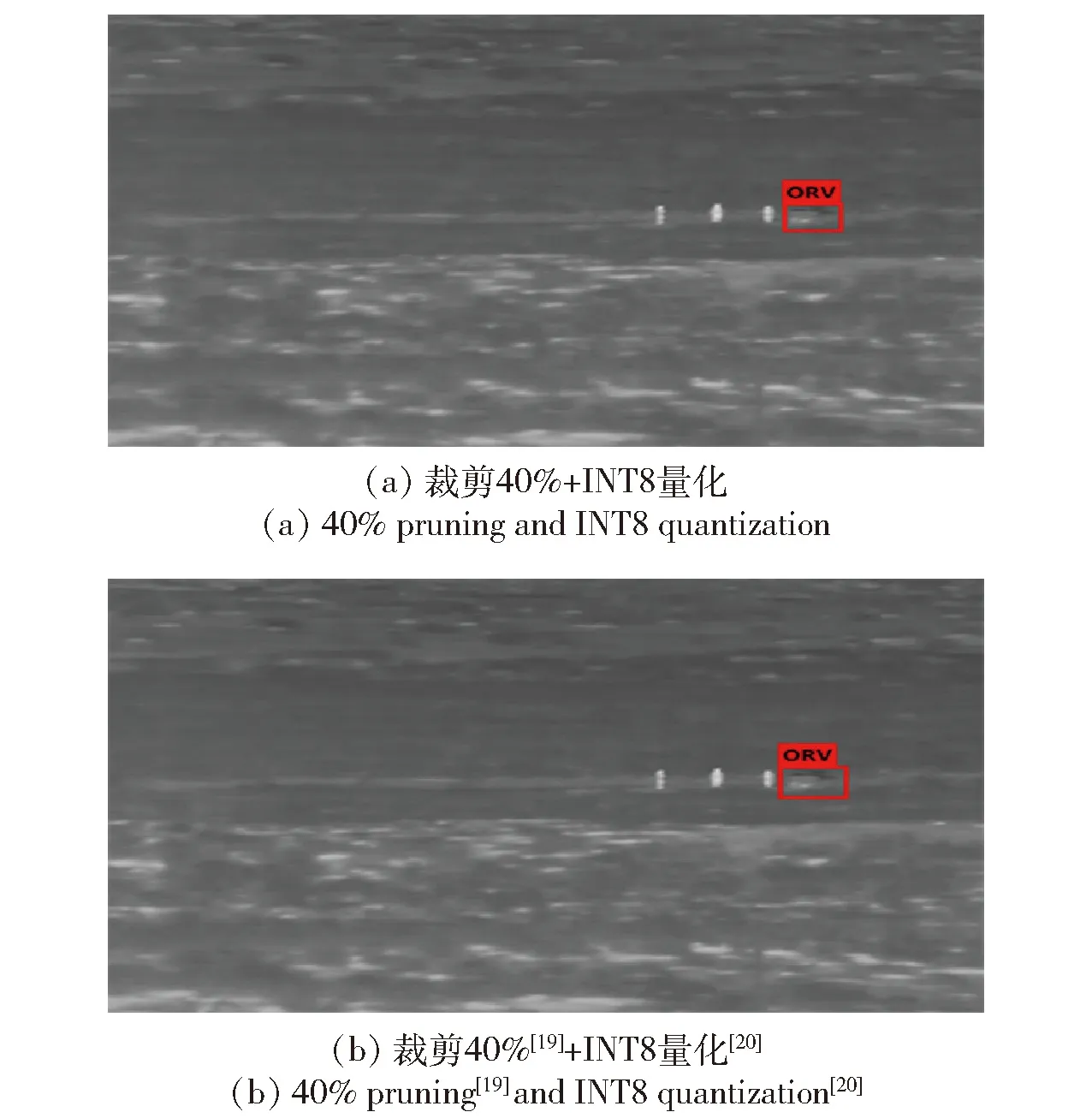
图12 压缩后红外目标识别结果

图13 YOLOv5x网络压缩前典型可见光目标识别结果(左为场景1,右为场景2)

图14 压缩后可见光目标识别结果
5 结论
本文针对自主目标识别深度神经网络复杂度高,计算、存储硬件资源要求高,难以在无人车等嵌入式计算平台部署应用的问题,开展了深度神经网络压缩优化技术研究。针对目标识别YOLOv5x网络,提出了一种基于改进型注意力模块和BatchNorm层的多正则项自适应网络裁剪算法,以及一种对权重实施不饱和映射、对激活值实施饱和映射的组合式训练后INT8量化算法,并基于红外和可见光两种数据集,完成了压缩优化算法的验证与分析。得出主要结论如下:
1)本文提出的网络压缩优化算法可有效降低网络参数量和计算量。针对红外数据集,当通道裁剪比率为40%时,参数量和计算量裁剪率可分别达到36.7%和32.6%;针对可见光数据集,当通道裁剪比率为40%时,裁剪率可分别达到36.1%和32.3%。
2)本文提出的网络压缩优化算法可有效提高网络计算效率。针对红外数据集和可见光数据集,通道裁剪40%和INT8量化时,在200 MHz工作频率的计算平台上,可以获得的最高硬件算力分别达到1 500.0 GOPs/s和1 507.7 GOPs/s。
3)本文提出的网络压缩优化算法可在满足识别精度前提下有效减小网络复杂度,满足嵌入式平台部署需求。在通道裁剪40%和INT8量化时,红外目标识别精度达到0.984 5,可见光目标识别精度达到0.922 1,识别帧频达到25帧/s,可满足无人车战场自主目标识别的准确度及实时性应用需求。
本文提出的自主目标识别神经网络压缩优化算法,可部署应用至其他嵌入式硬件平台,也可以扩展应用于无人机、精确制导武器等其他作战平台,为基于深度学习的自主目标识别技术的军事应用提供切实可行的技术的思路。本文下一步工作重点一方面是基于更真实的地面战场目标数据集、更广泛的空中和海上目标数据集,同时结合最新的YOLOv7网络,验证本文提出的压缩优化算法的有效性;另一方面针对自主任务决策、视觉导航等泛化的智能计算深度神经网络,验证本文提出的压缩优化算法的有效性。
