基于森林的实体关系联合抽取模型
2023-09-27王炫力靳小龙侯中妮廖华明
王炫力,靳小龙*,侯中妮,廖华明,张 瑾
(1.中国科学院网络数据科学与技术重点实验室(中国科学院计算技术研究所),北京 100190;2.中国科学院大学,北京 100049)
0 引言
从非结构化文本中抽取实体、关系信息是自动化构建知识图谱的必要步骤。传统流水线方法采用分离的两个模型提取实体,然后对候选实体对的关系类型进行分类;但这类模型忽略了两个任务间的交互信息,容易发生级联误差。近年来,研究者们开始探索建立实体关系联合抽取模型。实体关系联合抽取模型可以有效利用实体、关系间的交互信息来预测出文本存在的三元组,从而取得更好的表现;但是,嵌套实体识别仍是实体关系联合抽取的一个重要问题。
嵌套实体是实体内部存在其他实体的场景。而在三元组中,则存在两种情况:嵌套实体间三元组和嵌套实体内三元组,具体如表1 所示。
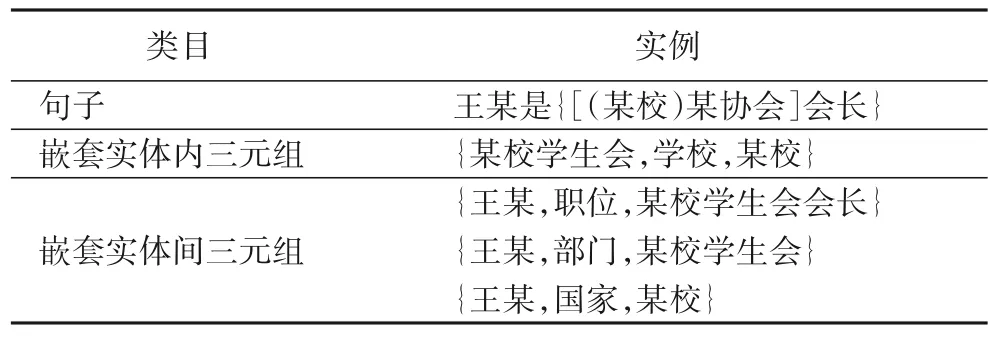
表1 嵌套实体Tab.1 Nested entities
早期的实体关系联合抽取方法采用序列标注方法[1],但该类方法无法识别嵌套实体。而现在的实体关系联合抽取模型常使用基于序列标注的方法[2]和基于跨度的方法[3-5]处理嵌套实体。基于序列标注的方法[2]对原始的序列标注方法[1]进行改进,通过对序列到序列的矩阵进行多次序列标注判断对应的两个词间是否组成实体、是否存在某种关系。基于跨度的方法[3-5]通过枚举所有可能的跨度并对其分类,得到实体,再枚举所有可能的实体对并进行关系分类,获得关系三元组。前者以更高的复杂度为代价识别嵌套实体,而后者则通过枚举所有可能的跨度识别嵌套实体,需要通过大量的负采样学习识别嵌套实体的能力,两者均无法在不增加时间或空间复杂度的前提下识别嵌套实体。此外,这两类方法均未考虑嵌套实体对三元组预测的干扰。
针对上述问题,本文提出了基于森林的实体关系联合抽取模型——EF2LTF(Entity Forest to Layering Triple Forest)。采用两阶段单步的联合训练框架,分别处理实体抽取和三元组生成。在实体抽取部分,EF2LTF 先识别实体头部,即实体森林中每棵实体树的根节点;再从每个根节点出发依次判断之后的词是否会分支出新的嵌套实体,该树是否依然继续,直至该实体树中所有实体均已抵达实体尾部,形成实体树。多棵实体树组成实体森林。在预测时,EF2LTF 可从实体森林中解析出句中所有实体。在三元组生成部分,EF2LTF 则通过实体树交互获得多个实体树的信息,再由该信息分层地生成三元组森林。依次选择包含头实体的实体树,再在实体树内部选择头实体,由头实体判断其所参与的关系类别,依据头实体和对应的关系,再分层地选择尾实体。一方面,这种森林的方式可以高效地识别嵌套实体,无需进行过多的负采样,也没有额外增加时间、空间复杂度;另一方面,EF2LTF在实体抽取和三元组生成部分均采用分层预测的方式,即在嵌套实体内部区分嵌套实体,这增强了对嵌套实体的识别能力,也使得模型免于嵌套实体对三元组预测的干扰。
本文还在四个公开数据集:网络自然语言生成(Web Natural Language Generation,WebNLG)数据集[6]、纽约时报(New York Times,NYT)数据集[7]、科技类实体关系共指簇(Scientific Entities,their Relations,and Coreference clusters,SciERC)数据集[8]和2005 自动内容提取(2005 Automatic Content Extraction,ACE2005)数据集[9]上评估了EF2LTF。实验结果表明,EF2LTF 优于对比工作,并且在标准数据集上取得了较好的效果。进一步的分析表明,EF2LTF 能够更好地在实体关系联合抽取中识别嵌套实体。
1 相关研究
传统流水线处理实体关系抽取的方法将实体抽取和关系抽取两个相关的任务完全分离,未考虑实体、关系间的交互信息[10]。为此,研究者们提出了实体关系联合抽取的方法[1],它的效果显著优于多数流水线的工作,但却完全忽略了嵌套实体。基于跨度预测的方法,如基于集合预测网络的SPN(Set Prediction Network)[11]模型,在预测实体关系三元组时,分别预测实体头部所在位置、实体尾部所在位置,在结构上可以无障碍地预测嵌套实体,但在三元组预测时处理嵌套实体的能力尚有待探讨。
多数数据集中普遍存在嵌套实体。NYT[7]、WebNLG[6]、SciERC[8]和ACE2005[9]数据集的所有实体中存在嵌套实体比率如表2 所示,因此嵌套实体是实体关系联合抽取任务中需要考虑的重要问题。而多数嵌套实体关系联合抽取的方法来自于嵌套实体抽取。因此,本文首先对嵌套实体抽取和嵌套实体关系联合抽取两个任务进行介绍。
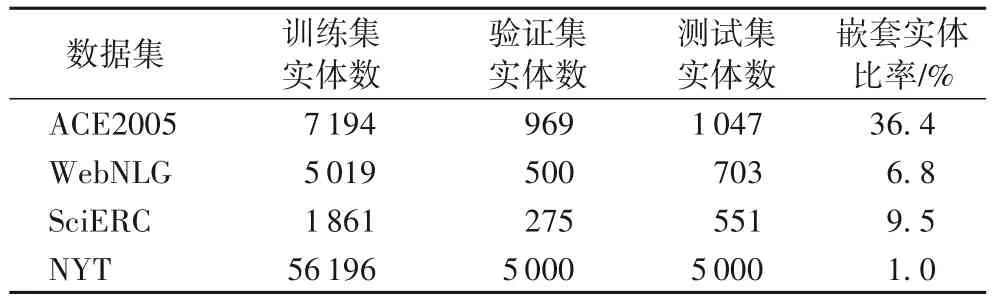
表2 数据集统计信息Tab.2 Statistics of datasets
1.1 嵌套实体抽取
嵌套实体抽取是能够处理嵌套实体的实体抽取方法。主要分为修改序列标注框架和探索新的框架两种解决方案。
修改标注方式的方法包括扩充标签[12]和拼接标签[13]两类。扩充标签的方法[12]将序列标注的标签为BIO(Begin,Inside,Outside)的标签体系新增BH(Begin Head)、BI(Begin Inside)等标签,以求标注嵌套实体;但这种标注体系的扩充严重依赖于数据集,不仅泛化性较低,而且还存在歧义。拼接标签的方法[13]则将原有的标签拼接组合成新的标签,从而达成在同一位置标注嵌套实体的目的;但该方法导致标签数成指数增加,单个标签标注稀疏,难以训练。
分层序列标注[14]从嵌套实体最内层实体到最外层实体依次使用不同的序列标注预测,利用了嵌套实体内的信息传递。嵌套实体抽取模型NNE(Nested Named Entity recognition)[15]先序列标注嵌套实体的外层实体,再标注内层,解码时通过维特比算法,同时考虑最优解码路线与次优路线上的实体,从而避免最大实体数量或长度的限制;但次优路线并不一定能够解码出下一层实体,它与最优路线重叠度较高,仍受到影响。LogSumExpDecoder[16]在每一层的序列标注中使用不同的势函数,以此屏蔽其他层的最优路线的影响。分层序列标注的模型预测的实体会受到错误信息传递的影响;并且,不同数据集中嵌套实体的层数不同,也会限制模型的泛化性能。
序列标注框架天然无法处理嵌套实体,需要以牺牲时间、空间复杂度为代价解决嵌套实体问题;因此学者们开始探索新的框架,主要包括基于跨度的框架和生成式的框架。
基于跨度的框架包括枚举跨度的模型和跨度预测的模型。枚举跨度的模型[17]枚举所有可能的跨度,进行实体类别预测:预测若为无实体则过滤,预测若为实体类别则输出该实体。这类模型通常需要进行大量的负采样以支撑训练。跨度预测的模型是对每种实体类型单独标记出实体的首尾位置信息,即跨度。阅读理解式嵌套实体抽取模型MRC4NNE(Machine Reading Comprehension for Nested Named Entity recognition)[18]以阅读理解的形式对实体类型提问,回答对应的实体跨度。使用头尾连接器的嵌套实体识别模 型HTLinker(Head-to-Tail Linker for nested named entity recognition)[19]先预测出实体头部,再依据实体头部和实体类型分别预测实体尾部,从而获得嵌套实体。
生成式的框架主要包括序列生成实体序列、序列生成实体集合和超图的模型。序列生成实体序列的模型[20]通过拷贝机制依次生成实体1 的头部、实体1 的尾部、实体2 的头部等。该模型认为实体之间存在次序,先预测的实体可以辅助后预测的实体的生成,但也因此造成了严重的误差传递。序列生成实体集合的模型[21]和SPN[11]一样,通过去除位置编码和引入二部图匹配的方式,生成实体集合,但仍受限于固定的生成实体数。超图的模型[22]则将前述分层序列标注的多层序列标注中相同的标签合并,形成一张超图,并通过循环神经网络(Recurrent Neural Network,RNN)的状态转移从输入文本序列起始位置依次预测各词的实体类别标签,如果预测结果有多个则分支,遇到无实体(O)标签则合并,最终预测得到所有嵌套实体。该模型不受生成序列长度、嵌套层数的限制,但在实体前后均存在标记为O 的节点与严重的传递误差。
这些嵌套实体模型通常需要以时间、空间复杂度为代价或需要大量负采样的支撑来处理嵌套实体。超图的模型[22]相比而言负例少、时间空间复杂度低,但存在严重的传递误差。EF2LTF 基于超图的模型[22],将超图拆解为实体森林,进一步削弱传递误差,高效地识别嵌套实体,辅助实体关系联合抽取。
1.2 嵌套实体关系联合抽取
目前考虑嵌套实体的实体关系联合抽取的模型较少,主要通过引入嵌套实体抽取模型处理联合抽取中的嵌套实体。主要引入的嵌套实体抽取模型包括序列标注的模型和基于跨度的模型。
序列标注的模型主要是分层序列标注和修改标注方式。双向长短期记忆网络结合条件随机场的实体关系联合抽取模 型2-Bi-LSTM-CRF(Bidirection Long Short-Term Memory with Conditional Random Field)[23]采用多任务框架,先序列标注最外层实体,然后通过引入实体类型的子概念的信息,再次进行序列标注,标记其内层实体。而在关系预测方面,2-Bi-LSTM-CRF[23]使用支持向量机(Support Vector Machine,SVM)预测。使用令牌对链接的一阶段实体关系联合抽取(single-stage joint extraction of entities and relations through Token Pair Linking,TPLinker)模型[2]进一步扩充序列标注,使用矩阵标注。该矩阵为文本到文本的词间关系矩阵。若矩阵中第i行第j列为1,则代表句中第i个词到第j个词存在链接。通过这种方式,标记实体头部到实体尾部的链接和头实体到尾实体的链接,但该标记方式不仅空间复杂度高,而且标注稀疏、负例过多,难以训练。
基于跨度的模型主要是枚举跨度的模型。基于跨度的实体关系联合抽取模型SpERT(Span-based Entity and Relation Transformer)[5]先枚举所有可能的跨度,在对它们进行实体分类的同时过滤非实体跨度,再枚举所有可能实体对,并预测候选实体对间的关系。基于语法树的模型[24]则在此基础上进一步融合了语法树信息。动态图信息抽取(Dynamic Graph Information Extraction,DyGIE)[3]介绍了一个多任务的通用框架,以动态构造的跨度图共享跨度表示,进而预测实体、关系信息。动态图增强信息抽取(Dynamic Graph Information Extraction ++,DyGIE++)[4]在此基础上构建了一个统一的多任务框架用于三个信息抽取任务:命名实体识别、关系抽取和事件抽取。它通过枚举、提炼和对文本跨度评分来获取句内局部上下文和句间全局上下文信息,从而解决每个任务。在实体关系联合抽取中,这些模型需要更多的负采样以同时支撑对嵌套实体和关系三元组的处理。
EF2LTF 在基于跨度预测的模型(SPN[11])基础上通过引入实体森林增强对嵌套实体的识别能力。与序列标注的模型相比,EF2LTF 无需多次序列标注,仅以一次树的生成即可获得嵌套的实体和包含嵌套实体的三元组。而与基于枚举跨度的模型相比,EF2LTF 无需枚举所有可能的跨度和实体对,而是自动生成实体,组合成实体对。因此,EF2LTF 能在不增加时间、空间复杂度和产生大量负例的前提下识别嵌套实体;此外,EF2LTF 能在相互嵌套的实体中区分嵌套实体,从相似的嵌套实体中选择实体对生成三元组,具有更强的嵌套实体识别能力和构建三元组时对嵌套实体的分辨能力。
2 基于森林的实体关系联合抽取
为处理嵌套实体,本文提出了EF2LTF。EF2LTF 结构如图1 所示,由编码器、实体森林、实体树交互和分层三元组森林四个部分组成。采用多阶段单步的联合训练框架,原始文本由编码器编码成分布式上下文表示,经由实体森林预测嵌套实体,再由实体树交互部分获得交互信息,最后通过分层三元组森林在识别的嵌套实体中选择头实体、尾实体,预测关系,生成分层的三元组森林。
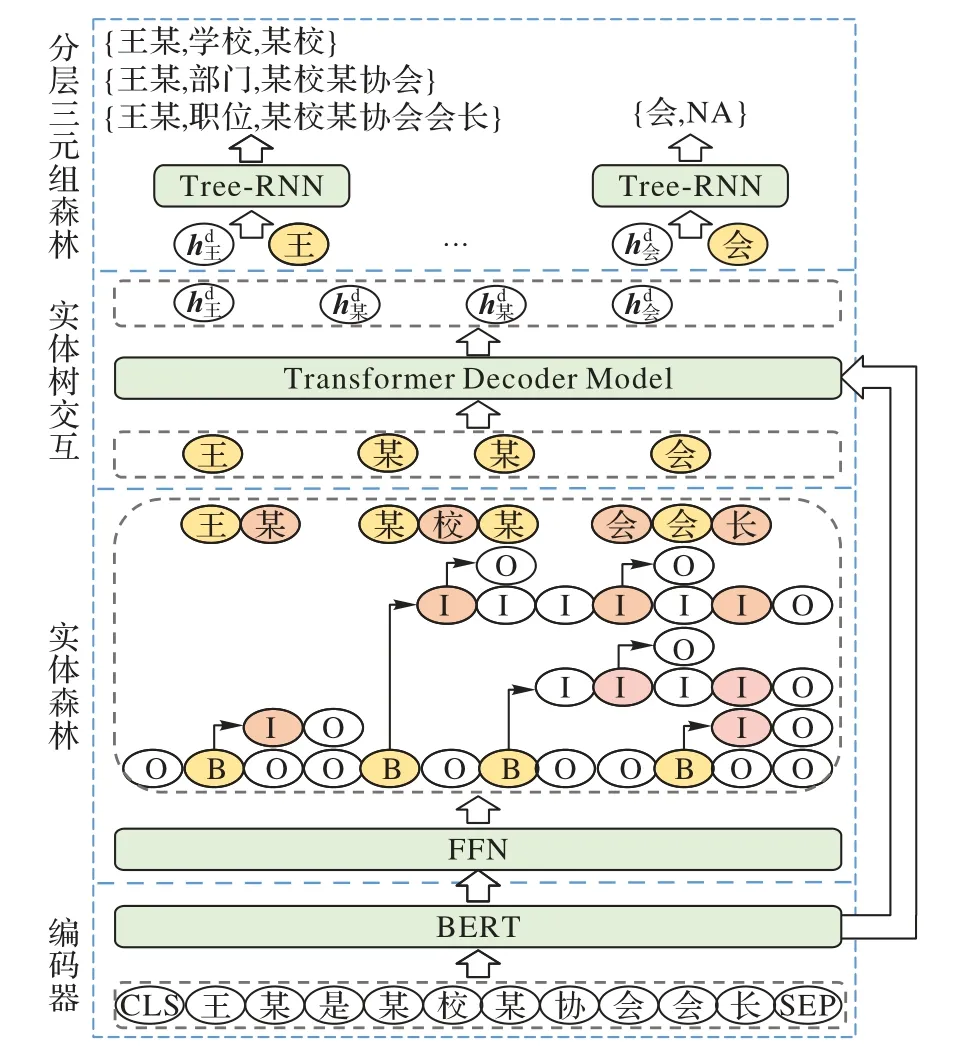
图1 EF2LTF的结构Fig.1 Structure of EF2LTF
2.1 编码器
鉴于Transformer 相关预训练模型的有效性,EF2LTF 模型采用预训练的BERT(Bidirectional Encoder Representation from Transformers)[25]作为编码器,获得输入文本的分布式上下文表示。如式(1)所示:
其中:Tw、Tp、Ts为输入文本的独热码向量、位置索引、分段标志;Wt是词嵌入矩阵;Wp是位置嵌入矩阵;Ws是分段嵌入矩阵;BERT(x)代表BERT模型;输出He为输入文本的上下文表示矩阵,行向量代表句中第i个词的包含上下文信息的向量表示。
2.2 实体森林
为辅助联合抽取高效识别嵌套实体,本文提出实体森林。实体森林存在数据结构与模型结构两个概念。它的数据结构如图2 所示,将嵌套实体前缀相同的实体合并成嵌套实体树的集合。实体森林的模型结构则如图2 实体森林部分所示,分为序列标注模块和多棵嵌套实体树模块。编码器所得输入文本的分布式表示He,首先经过一个序列标注模块,标注嵌套实体树的根节点,再从每一个根节点出发形成嵌套实体树,预测嵌套实体。这种分层地嵌套实体树内部识别嵌套实体的方式,能增强模型对嵌套实体的识别能力。
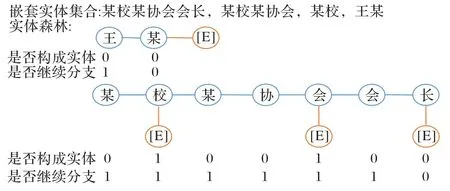
图2 实体森林的数据结构Fig.2 Data structure of entity forest
实体森林下半部分标注出对应文本的实体头部(Begin,B)、无实体(Other,O)标签,即标注出嵌套实体树的根节点(每个嵌套实体的头部)。具体如式(2)所示。
其中:输入文本的上下文表示He经过dropout 和线性层获得文本中每个词属于B、O 标签的概率;Wner、bner是线性层的权重和偏置,概率P∈Rl×c2
通过交叉熵损失函数训练,如式(3)所示。
其中:c2=2 是类别数;l为输入文本长度;yic是真实标签,代表第i个词是否存在第c个标签;Pic为P中对应位置的概率。
预测时如式(4)所示,概率最大的标签即所预测的标签yB*。如当前词标签预测为B,则为预测所得嵌套实体树的根节点,记作
实体森林的上半部分每一棵嵌套实体树从根节点出发,使用长短期记忆(Long Short-Term Memory,LSTM)网络依次判断根节点之后的词是否是某个嵌套实体的尾部(构成实体),是否继续分支(该树是否还有其他嵌套实体),从而形成一棵嵌套实体树。具体实现步骤如下:
2.3 实体树交互
实体树交互模块由去除Position Encoding 的Transformer的Decoder 部分组成,利用注意力机制(Attention Mechanism)获得无序的实体树间交互和实体树与输入文本的交互。该部分计算如式(9)所示,输入为输入文本的分布式表示He和实体树表示HS,输出为融合实体树信息和输入文本信息的隐层
2.4 分层三元组森林
使用如图3 所示的树形循环神经网络(Tree Recurrent Neural Network,Tree-RNN),对每一个实体树生成一棵三元组树。第1 个时间步输入对应实体树的根节点,依据隐层信息,选择可以作为头实体的实体树分支(实体的尾部),然后输入头实体,预测关系,输入关系,选择尾实体所在实体树,再在实体树内部选择实体。每一步的预测中如果存在多个结果,则分别输入LSTM 单元,分别计算,形成分支,从而形成三元组树。其中,三元组树的每一个分支对应一个三元组。
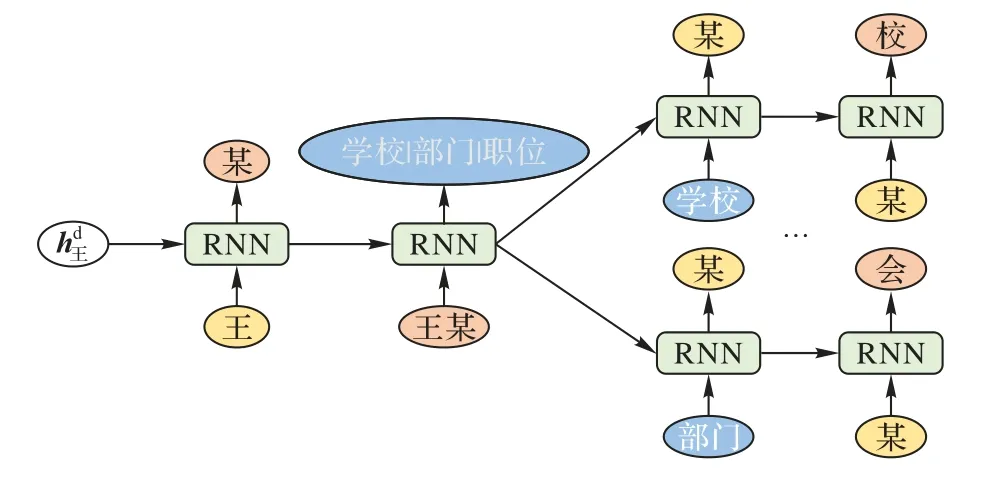
图3 Tree-RNN模型的结构Fig.3 Structure of Tree-RNN model
如果预测实体,则需要融合输入文本信息后,再通过线性层计算选择实体树或实体的概率,计算如式(12)所示。
其中:thresholdes、thresholdee为分类阈值;下标es和ee代表单个实体的头部和尾部,是gold label,真实存在的实体。
为进一步降低嵌套实体的识别难度,通过root_mask 和leaf_mask 将非可选项置零。此外,为削弱传递误差,引入纠错机制。纠错机制在训练时考虑了预测上一步预测错误的情况,从而使得预测阶段和训练阶段一致,以此降低传递误差,提升联合抽取的性能。具体表现为,在训练时,可选项包括真实的实体树根节点或实体尾部(实体树的叶子)和依据相应概率负采样所得负例。负采样考虑了预测时出错的情况,并在推断时通过预测为无标签(Not Available,NA)纠正。在预测时,则依据实体森林部分预测的实体遮掩不可选选项。具体如式(13)所示,预测所得实体树为,实体尾部为
最后,将各阶段的损失函数加权组合,联合训练,如式(15)所示。
其中,wB、wEF和wLTF分别代表序列标注损失、实体森林损失和分层三元组森林损失的权重。
3 实验与结果分析
本文通过实验评估上述模型在嵌套实体关系联合抽取中的有效性。首先介绍数据集和实验设置;随后介绍实验中的对比模型,并阐述实验结果的分析;最后进行消融实验。
3.1 实验数据集
为验证模型有效性,本文选择近年来嵌套实体关系联合抽取模型所用的通用数据集,包括WebNLG[6]、NYT[7]、SciERC[8]和ACE2005[9]数据集。WebNLG 和NYT 采取标注出完整实体的实际标注版本(Exact)[26];SciERC 数据集使用官方版本;ACE2005[9]保留了和之前工作[2,6,27]相同的划分,但在处理时,为体现EF2LTF 对嵌套实体的有效性,保留全部嵌套实体。这与嵌套实体抽取的模型一致[28]。具体统计数据如表2 所示。
3.2 实验超参数设置
遵循之前的工作[4],本文在SciERC 数据集的实验中采用SciBERT(uncased)[8],在其他数据集中采用BERT。学习率初始化BERT 和SciBERT 为10-5,而Transformer Decoder 为2 × 10-5。实体树交互部分使用3 层Transformer Decoder。dropout 用于BERT 输出部分和LSTM 输出部分,比率设为0.1。优化器为AdamW[29]。训练时,各损失权重比例wB∶wEF∶wLTF=1∶1∶10。本文所有的实验均使用NVIDIA TESLA V100。这些参数的设置大多与SPN[11]一致。
3.3 对比实验结果
实验结果如表3 所示,主要采用精确率(Precision,Prec)、召回率(Recall,Rec)和F1 值(Function 1,F1)评估。
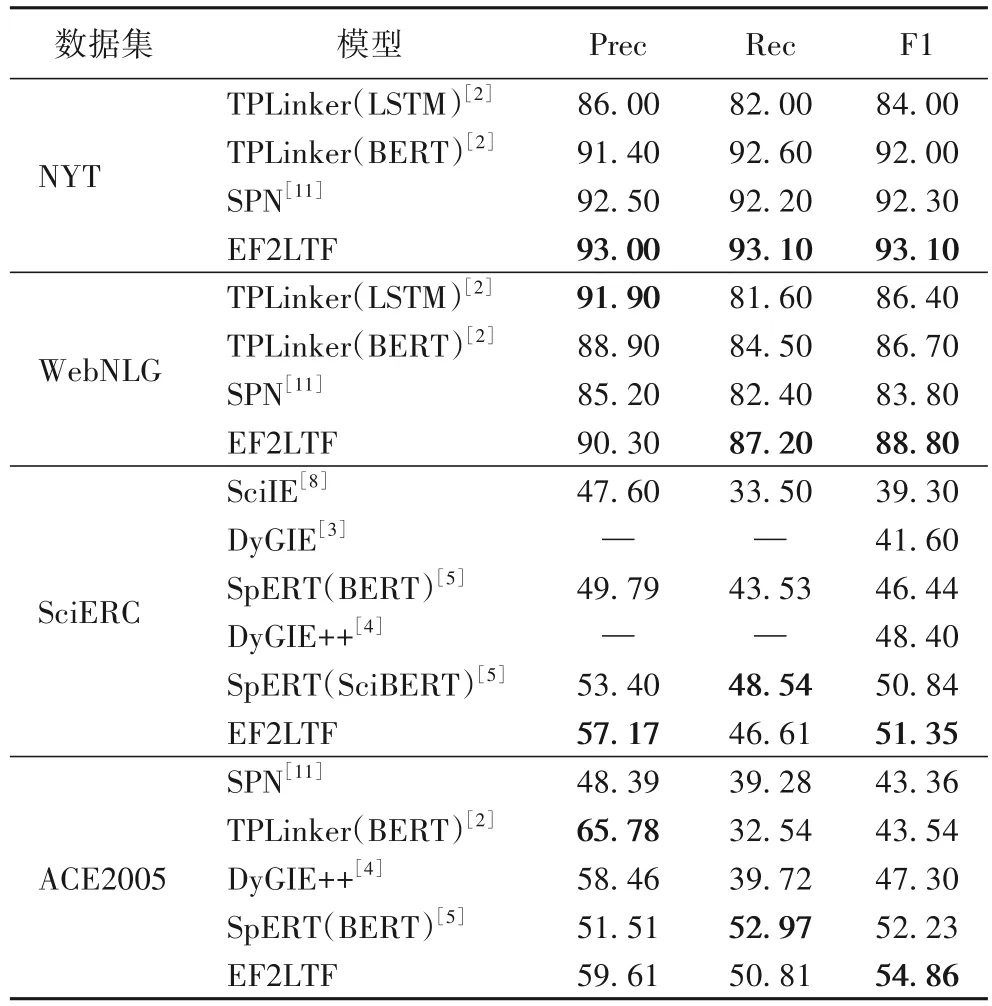
表3 不同数据集上的实验结果 单位:%Tab.3 Experimental results on different datasets unit:%
与基于跨度预测的SPN[11]相比,包括EF2LTF 在内大多嵌套实体关系联合抽取模型F1 值均高于SPN[11],且主要优势体现在召回率上。从1.0%嵌套实体的NYT 数据集到36.4%的ACE2005 数据集,随着包含嵌套实体的句子在所有句子中占比的提升,SPN 模型从略优于TPLinker 到和嵌套实体关系联合抽取模型差距越来越大,与EF2LTF 的F1 值差距也从0.8 到5.0 再到11.5 个百分点,主要体现在召回率的差距上。由此可见,基于跨度预测的模型虽然理论上可以预测嵌套实体,但对嵌套实体的识别能力比嵌套实体关系抽取的模型差。
与嵌套实体关系联合抽取模型相比,在各个数据集上,EF2LTF 的F1 也取得了最好的效果。从NYT、WebNLG 到ACE2005 数据集,随着嵌套实体数量的增加,EF2LTF 和TPLinker(BERT)的F1 值差距越来越大,从1.1、2.1 到11.3个百分点,主要体现在召回率上。这一方面因为TPLinker 的标注模式过于稀疏,存在大量负例难以训练;另一方面则是与其他多阶段的嵌套实体关系联合抽取模型相比,一阶段的TPLinker 难以处理嵌套实体更多情况更复杂的ACE2005 数据集,因此效果较差。与SpERT、DyGIE 和DyGIE++相比,TPLinker 没有通过负采样学习嵌套实体与普通实体的区别,效果较差,而EF2LTF 仅需采样少数负例即可训练过分层预测在嵌套实体内部识别嵌套实体,具有更好的识别能力,且通过负采样、分层预测和森林的结构考虑了嵌套实体对三元组预测过程的影响,因此效果更好,F1 值取得了最优值。
综上所述,EF2LTF 的分层预测、基于负采样的纠错机制和森林有效,且随着嵌套实体占比的增加,与其他模型的差距逐渐增大,因此,EF2LTF 更适合嵌套实体关系联合抽取。
3.4 消融实验
为了测试EF2LTF 中的有效模块,本文在ACE2005 数据集上进行消融实验。实验中,参数不变,逐个删除实体树交互(Entity Tree Interaction,ETI)模块、分层三元组森林(Layering Triple Forest,LTF)模块和实体森林(Entity Forest,EF)模块,实验结果如表4 所示。
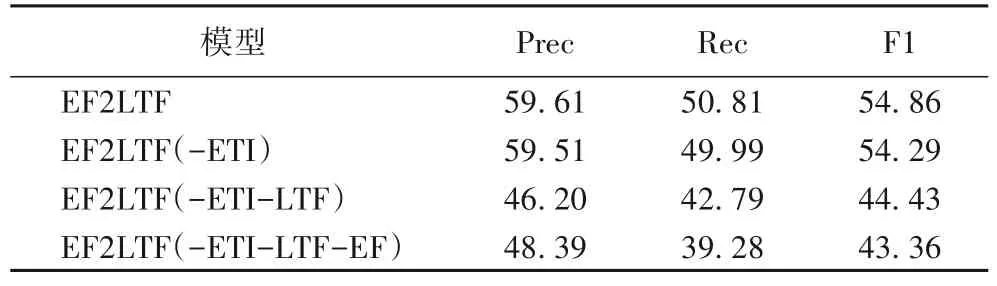
表4 消融实验结果 单位:%Tab.4 Ablation experimental results unit:%
首先删除ETI 模块,该模块主要用于为下一步的分层三元组森林提供信息支撑,将Transformer Decoder 的输入改为随机初始化的可训练向量,F1 值下降0.57 个百分点。
其次删除LTF 模块。将分层三元组森林中Tree RNN 删除,同时预测头实体、关系、尾实体,这与SPN[11]中的生成三元组方式一致。可以看到,F1 值下降了9.86 个百分点,下降最为明显。因此该模块起主要作用。这验证了本文中三元组森林和分层预测的有效性。
最后删除EF 模块。在删除LTF 后,实体森林不再参与到模型预测,此时该模型仅通过共享编码为三元组生成提供嵌套实体信息,并依赖生成三元组模块预测实体、关系,F1值下降了1.07 个百分点。验证了嵌套实体信息的交互能够提升嵌套实体关系联合抽取性能。
综上所述,起主要作用的是LTF 模块,主要为模型提供三元组生成时对嵌套实体的分辨能力;其次是EF 模块,提供嵌套实体的识别能力,并为三元组生成提供嵌套实体信息;最后是ETI 模块,主要为模型提供实体树之间、实体树和文本之间的关联信息。
4 结语
本文提出了基于森林的实体关系联合抽取模型——EF2LTF。该模型一方面将嵌套的实体聚集成树,进而组成森林,借助树的结构在嵌套的实体中识别嵌套实体,具有更强更高效的识别能力;另一方面则在三元组生成时,将三元组森林和分层预测结合,在生成三元组时在嵌套实体中区分嵌套实体,具有更强的分辨能力,使得模型免于嵌套实体对三元组预测过程的干扰,最终取得了更好的实体关系联合抽取性能。
但在ACE2005 中存在大量未参与到三元组中的实体,这是目前实体关系联合抽取难以处理的问题之一,阻碍了其性能的提升。因此,下一步考虑将分层预测和森林的模型用于未参与到三元组中的实体上,以求进一步提升实体关系联合抽取性能。
